背景
之前写过了,在这里:
目标
- 测试社区下帖子的筛选功能
备注
还是得有需求文档才行,所以我瞎写了一个:
- 默认:展示所有帖子
- 精华帖:只展示精华帖子,精华帖末尾有一个奖牌的图标
- 优质帖子:只展示点赞数大于 5 的帖子
- 无人问津:只展示回复数为 0 的帖子
- 最新回复:展示有回复的帖子,按回复时间排序
- 最新发布:展示所有帖子,按发布时间排序
正文
我只写了"精华帖"的用例,"默认"不知道咋写,可能交给接口测试会好一点。
预期结果是,第一页和最后一页的每个帖子,后面都有一个奖牌的图标。
代码
完整代码太多了,只贴部分。
topics_page.py
from selenium.webdriver.common.by import By
from pages.base_class import BaseClass
from enum import Enum
class TopicsType(Enum):
DEFAULT = 1
EXCELLENT = 2
POPULAR = 3
NO_REPLY = 4
LATEST_REPLY = 5
LAST = 6
class TesterHomeTopicsPage(BaseClass):
# locators
_title_input_loc = (By.ID, "topic_title")
_category_btn_loc = (By.ID, "node-selector-button")
_content_input_loc = (By.ID, "topic_body")
_draft_btn_loc = (By.ID, "save_as_draft")
_save_btn_loc = (By.CSS_SELECTOR, "input.btn.btn-primary")
_title_loc = (By.XPATH, "//h1[@class='media-heading']//span[@class='title']")
_topic_body_loc = (By.XPATH, "//div[@class='card-body item-list']")
_topic_titles_loc = (By.XPATH, "//div[@class='card-body item-list']//div[@class='title media-heading']")
_award_icon_loc = (By.CSS_SELECTOR, ".fa.fa-award")
_pagination_loc = (By.CSS_SELECTOR, "pagination")
_page_loc = (By.XPATH, "//li[@class='page-item']")
# locators of topic filters
_excellent_btn_loc = (By.XPATH, "//a[@href='/topics/excellent']")
''' actions '''
def _get_all_topic_titles(self):
return self._get_elements(self._topic_titles_loc)
''' behaviors '''
def topic_filter(self, condition: TopicsType):
if condition is TopicsType.DEFAULT:
pass
elif condition is TopicsType.EXCELLENT:
self._click_element(self._excellent_btn_loc)
elif condition is TopicsType.POPULAR:
pass
elif condition is TopicsType.NO_REPLY:
pass
elif condition is TopicsType.LATEST_REPLY:
pass
elif condition is TopicsType.LAST:
pass
else:
raise ValueError("请传入TopicsType类型")
return self._get_all_topic_titles()
def is_award_exist(self, titles):
awards = self._get_children(titles, self._award_icon_loc)
return all(self._is_exist(award) for award in awards)
def jump_to_page(self, page):
if page == 'last':
page = self._get_max_page(self._page_loc)
elif page == 'first':
pass
elif page == 'next':
pass
elif page == 'previous':
pass
else:
try:
page = int(page)
except ValueError as e:
print(e, f"无法转换为int类型:{page}")
target_url = self._get_url() + f"?page={page}"
self._open_page(target_url)
return self._get_all_topic_titles()
test_topics.py
import unittest
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from pages.home.topics.testhome_topics_page import TopicsType
from pages.testerhome_signin_page import TesterHomeSignInPage
class TestTopics(unittest.TestCase):
@classmethod
def setUpClass(cls):
service = ChromeService(executable_path=ChromeDriverManager().install())
cls.driver = webdriver.Chrome(service=service)
cls.sign_in_page = TesterHomeSignInPage(cls.driver)
cls.home_page = cls.sign_in_page.login_as("abc@foxmail.com", "xxxx")
cls.topics_page = cls.home_page.go_to_topics()
@classmethod
def tearDownClass(cls):
cls.driver.quit()
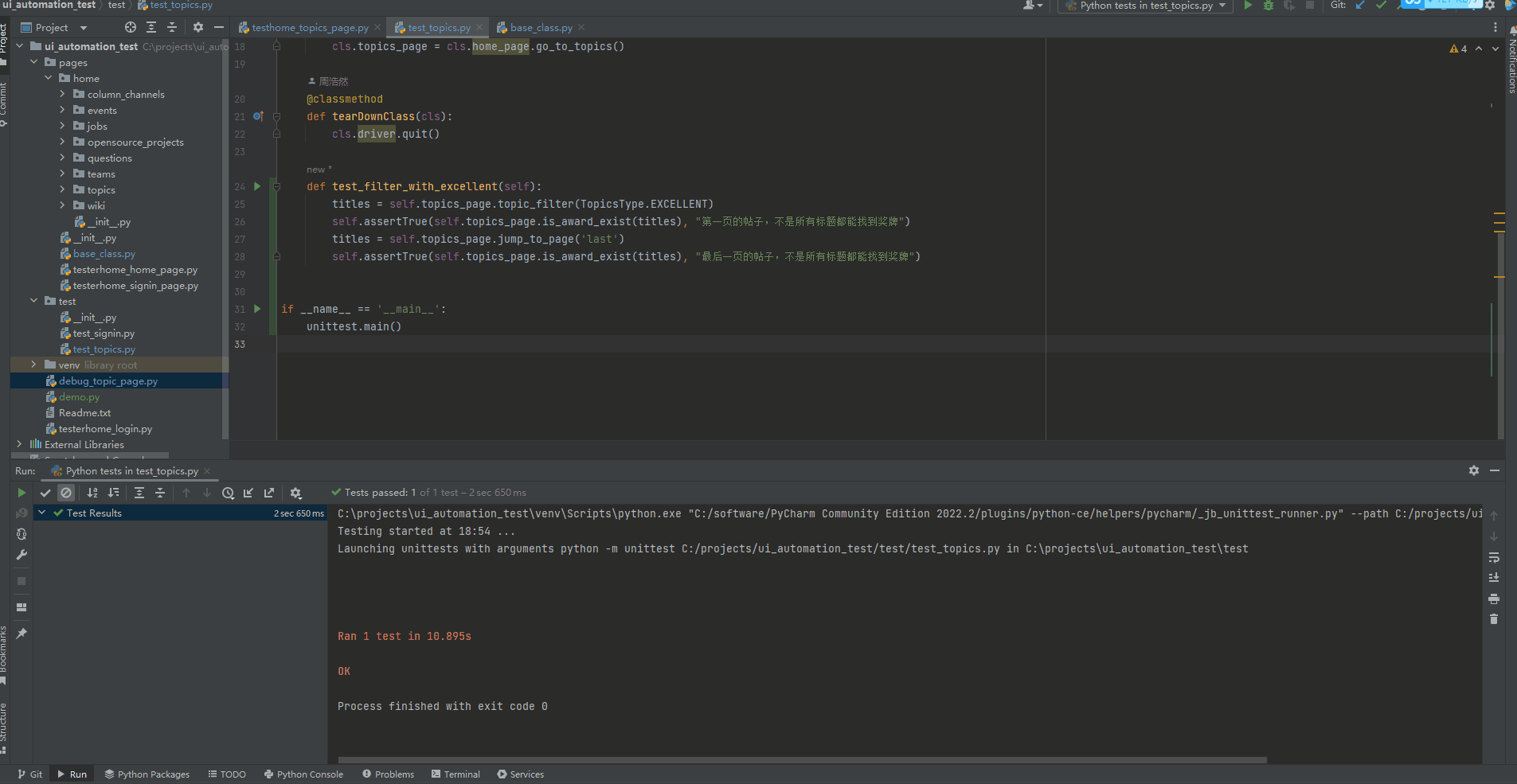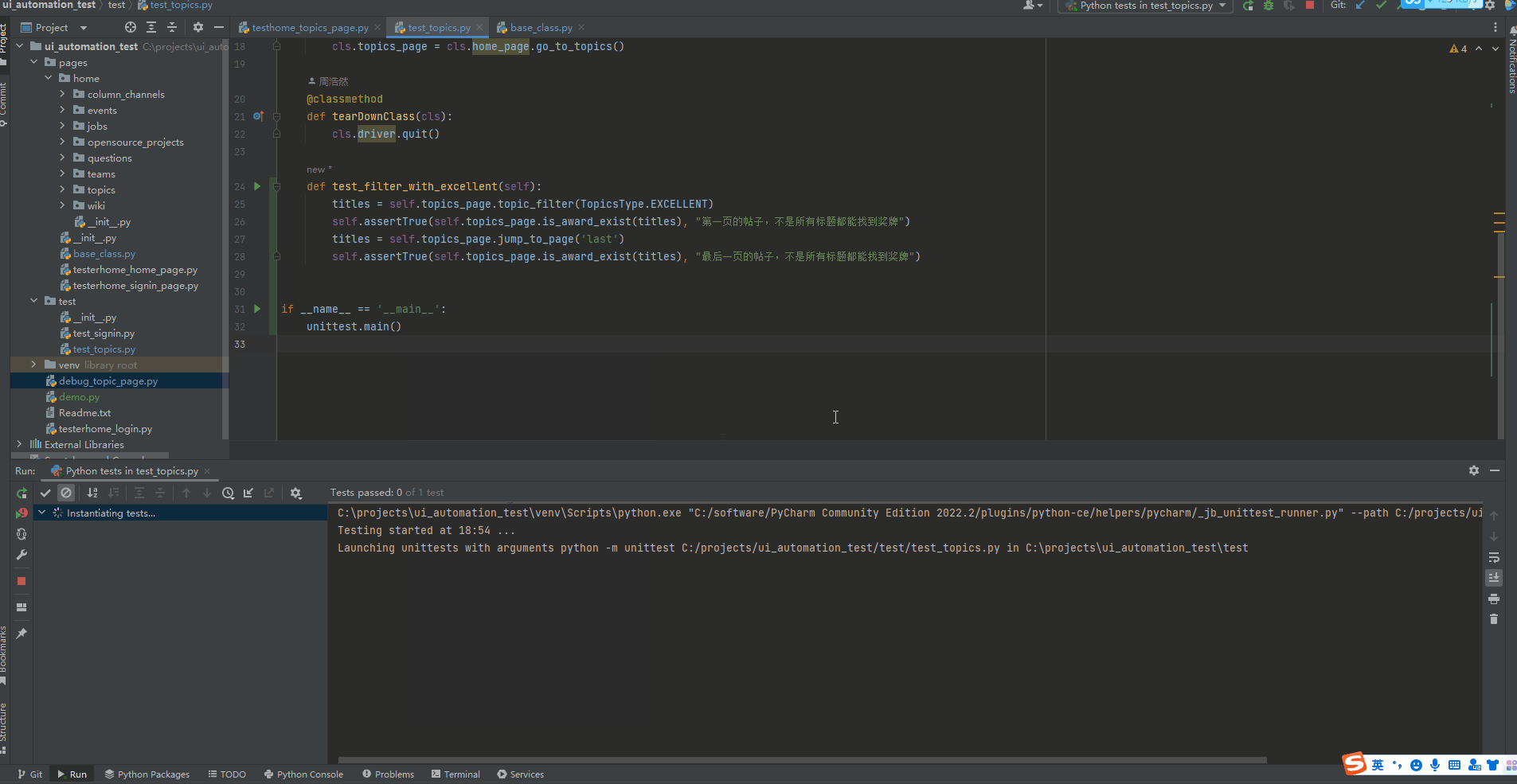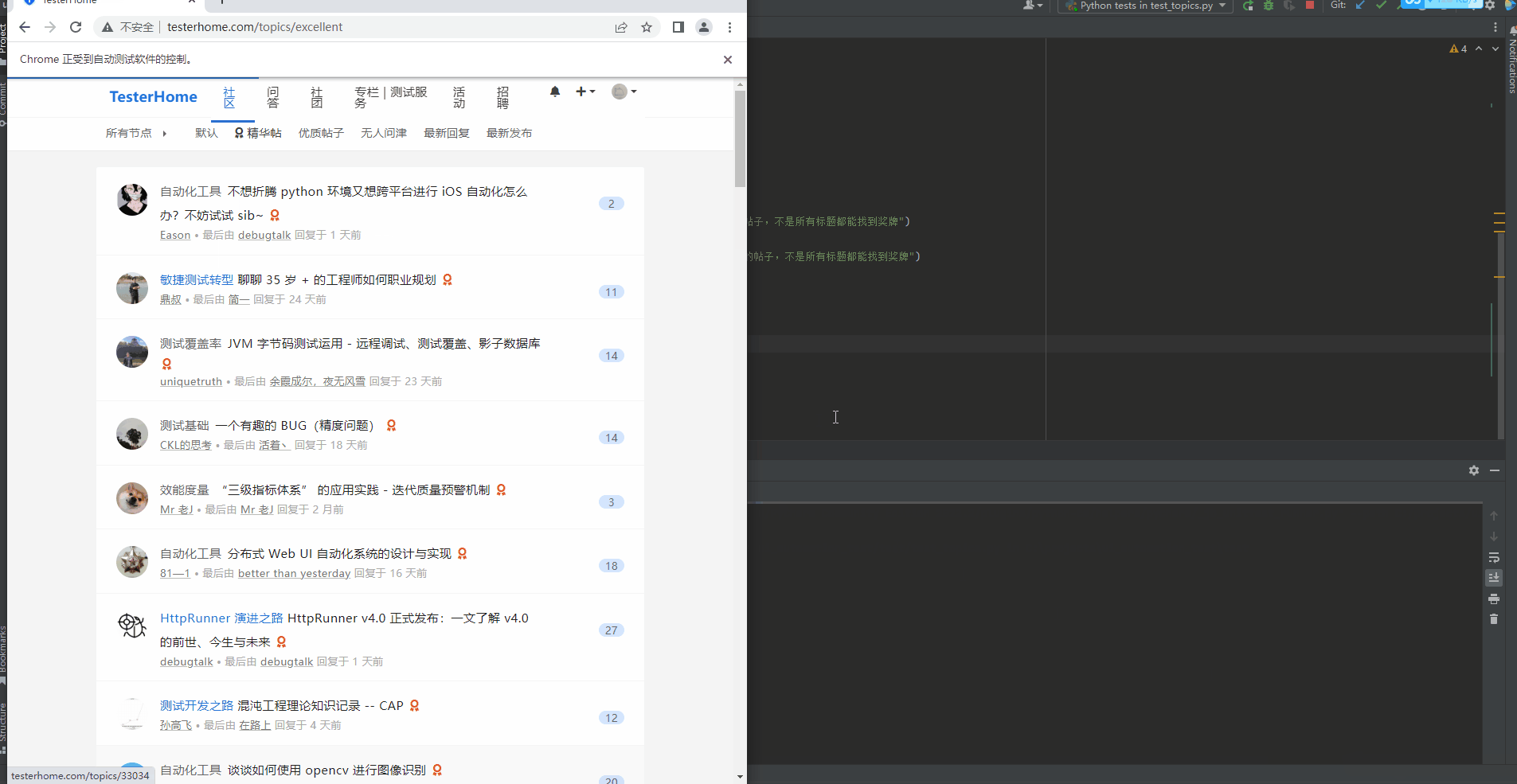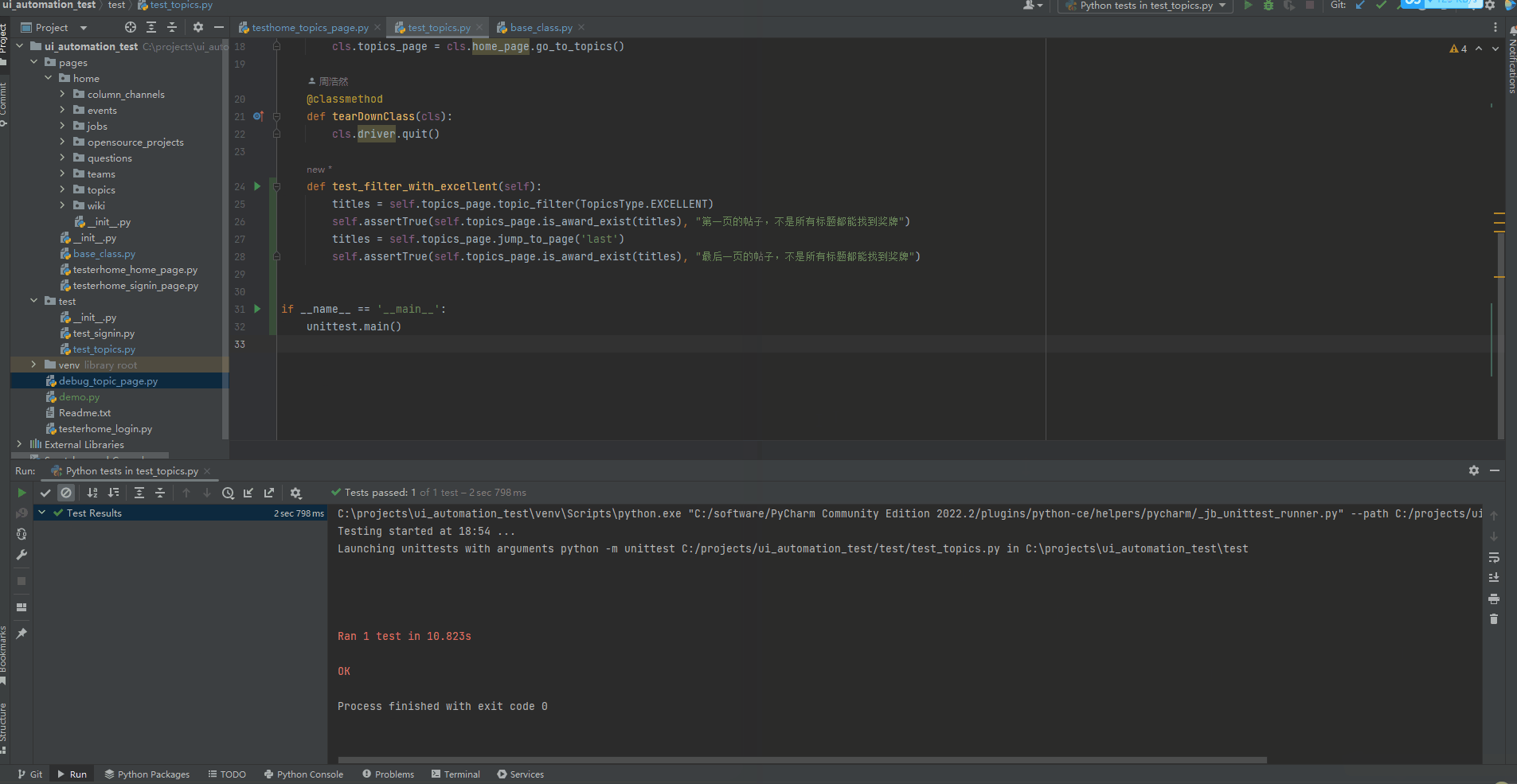
def test_filter_with_excellent(self):
titles = self.topics_page.topic_filter(TopicsType.EXCELLENT)
self.assertTrue(self.topics_page.is_award_exist(titles), "第一页的帖子,不是所有标题都能找到奖牌")
titles = self.topics_page.jump_to_page('last')
self.assertTrue(self.topics_page.is_award_exist(titles), "最后一页的帖子,不是所有标题都能找到奖牌")
if __name__ == '__main__':
unittest.main()
效果图
发现问题
- 写了一大堆 locators,都不知道哪个是哪个了,大家实际开发中也是这样的吗?
- 比如我想拿到帖子的标题,那么我可能会这样写:
# topic_page.py
title= self._get_element(self._title_locator) # _get_element是我封装在base_page.py里的一个方法
假如我想用 title 继续做点什么,比如说继续找 title 下面的奖牌
# topic_page.py
title= self._get_element(self._title_locator) # _get_element是我封装在base_page.py里的一个方法
adward = title._get_element(self._adward_locator)
这样是会报错的,因为 title 没有_get_element 的方法,它是个 WebElement Object,不是我们自己写的 Page Object
当然用回 WebElement Object 自己的方法能解决报错,即:
# topic_page.py
title= self._get_element(self._title_locator) # _get_element是我封装在base_page.py里的一个方法
title.find_element(self._adward_locator)
但又和 Page Object 的继承不符,因为之前的代码,都是只在 base_page.py 里调 WebElement Object 的方法,topic_page.py 用 base_page.py 的方法。
假如现在 topic_page.py 里用 WebElement Object 的方法,显得有点奇怪,不知道大家遇到这种情况是怎么解决的。
3.大家有做过筛选功能的 UI 测试吗?都是怎么写断言的?
我总感觉做接口测试会比较直观,因为筛选更多是校验数据,比如某条数据符合筛选条件,那它有没有展示出来。像回复时间、发布时间这些东西,前端可能不会展示,比较难写断言。
计划
把这两个的用例也写了:
- 优质帖子:只展示点赞数大于 5 的帖子
- 无人问津:只展示回复数为 0 的帖子
「原创声明:保留所有权利,禁止转载」