大数据测试需要准备的测试数据跟普通数据测试主要区别是数据量的大小,靠手工写 1G、10G、100G 等体量的数据的难度很大,所以大家都想到用脚本来写一个造数的工具,本文主要介绍基于 hadoop 自带的造数工具来实现自己造数的需求。
造数的代码是 map 阶段:
```java demo
public static class SortDemoMapper extends Mapper {
private Text key = new Text();
private Text value = new Text();
public SortDemoMapper() {
}
public void map(LongWritable row, NullWritable ignored, Mapper.Context context) throws IOException, InterruptedException {
this.key.set("name:");//数据可以改成自己需要的格式
this.value.set("wangyi,age:18,sex:1\r\n");//数据可以改成自己需要的格式,输出结果可以是 Text,Text,还可以改成 Text,NullWritable 等其他格式,
context.write(this.key, this.value);
}
}
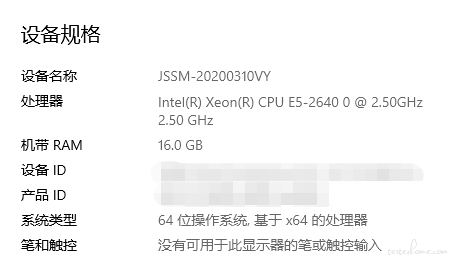
对应的文件的输入也需要进行变化,当然也可以直接使用GenSort自带的InputFormatClass、OutputFormatClass,在图1电脑配置情况下本地运行造数工具,造数 64,424,509,448 字节,运行时间23分钟左右如图2,打成jar包在hadoop集群上的运行时间后期再补充 。---图片详见评论哈
整体代码上传git再来同步呦~