简述
使用 pytest 数据驱动进行自动化测试,对一些自动化测试从业人员不会陌生,可能会觉得此方法较为简单,此文仅为个人成长过程中的记录及分享,内容不深,却觉实用。
工作背景
新成立的测试部,一切从零开始构建质量体系及相关测试环境、平台。
在陆续支持了一些功能、安全、报告类的工作后,月度考核谈话时被问到了自动化测试,也就开始探索自动化相关内容。
鉴于当前环境,接口文档欠缺,测试环境为本地虚拟机,暂无需长期运行测试的项目,故选择使用 pytest 数据驱动方式实现,后续在有专用测试资源后再拓展测试平台框架。
实现
思路
- 接口测试中变化的一般是传输的数据体,而请求头不变。
- 可通过识别用例中的方法名称,调用对应封装的接口请求类型的方法。 ## 问题
- 每个接口的请求,数据体字段都有所不同。
- 对于关联性用例,如何将前面用例的结果进行获取并传输到后续用例的数据体中?
- 如何便捷快速生成用例。 ## 解决方案
- 将数据体作为一个用例参数。
- 鉴于当前业务,先实现非关联性用例,后续再关注关联性用例的实现。
- 前期先使用 execl 作为数据源,在其中设置用例的合成公式,将请求类型、状态等作为选择项,对接口的数据体亦使用相同方法进行合成。后续要达到的效果为:通过选择、输入等方式便捷快速生成测试用例,并可转换为 json 、yaml、execl 等格式,可追加到原有的用例文件。
接口 execl 数据源配置
可将请求类型、api、预期返回等作为选择项。
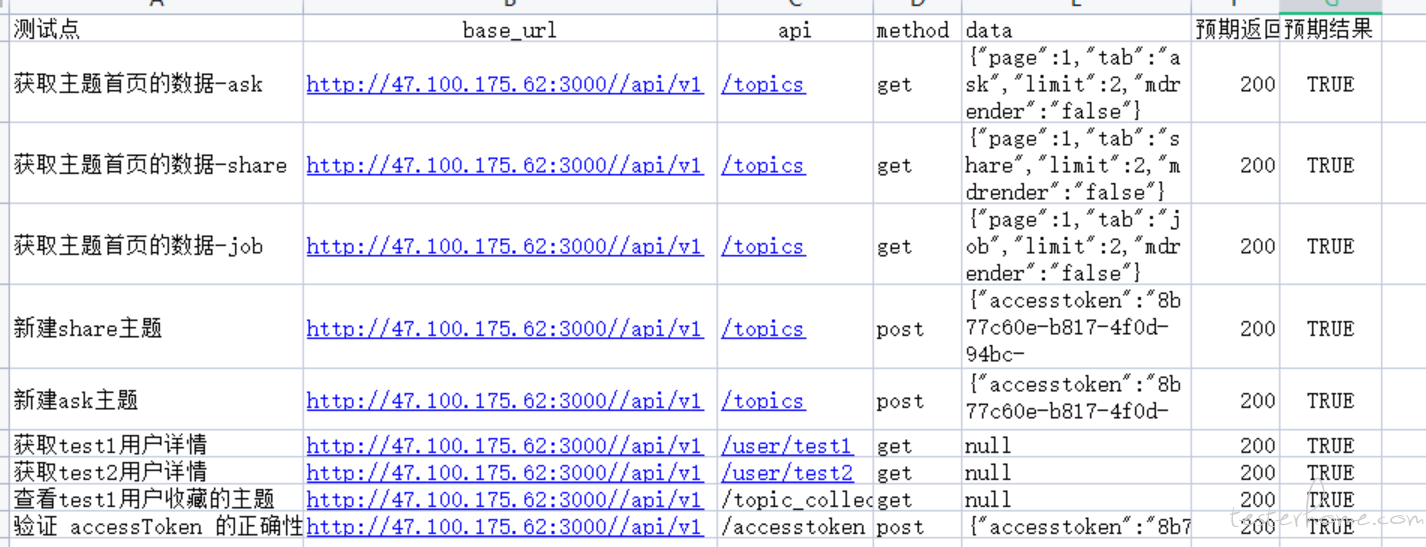
接口测试代码实现
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
"""
--------------
File Name: test_execl
Description:
Author: by_w
date: 2021/12/1 17:34
--------------
Change Activity:
2021/12/1 17:34
--------------
"""
import requests
import pytest
import toolcase.common as common
execl_data = common.get_execl_data('../global_val/test_execl.xlsx',sheetname='Sheet1')
@user1ize('case_name,base_url,api,method,data,code,res',execl_data)
def test_execl_data(case_name,base_url,api,method,data,code,res):
print(case_name)
if method == 'get':
r = requests.get(url=base_url+api,params=json.loads(data))
if method == 'post':
r = requests.post(url=base_url+api,data=json.loads(data))
print('当前用例的接口地址为: ',base_url+api,' 使用的接口方法为: ',method)
print('接口传参数据为: ',data)
print('实际使用接口url ',r.url)
assert r.status_code == code
assert r.json()['success'] == res
print(r.json())
UI execl 数据源配置
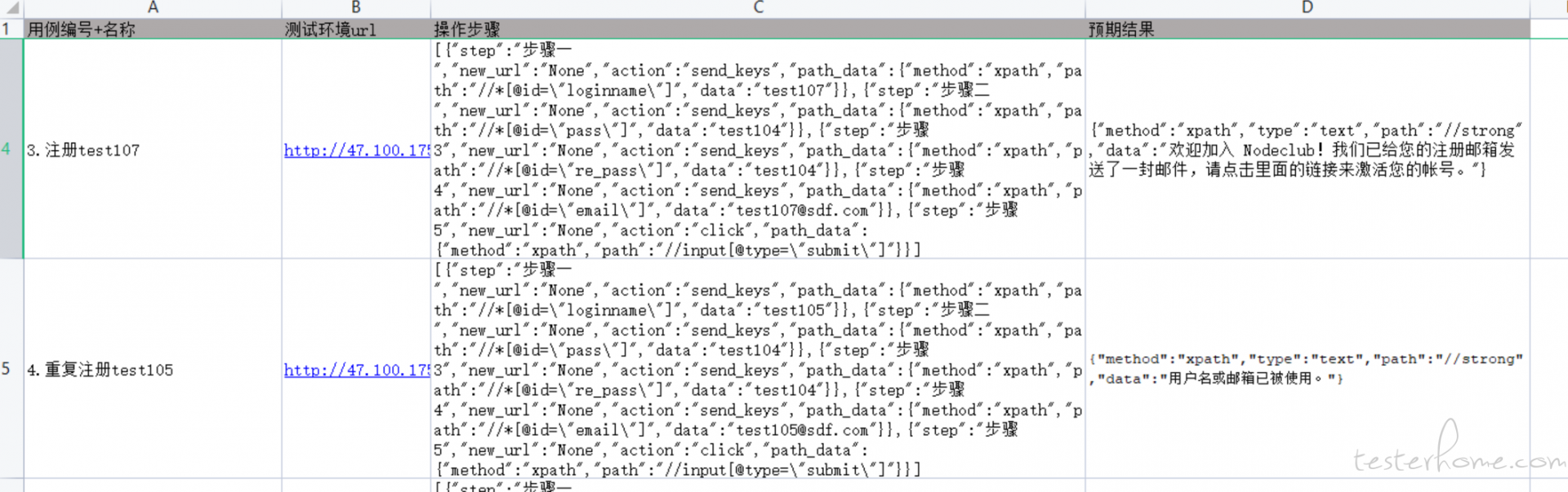
通过分步编写,生成 UI 测试步骤
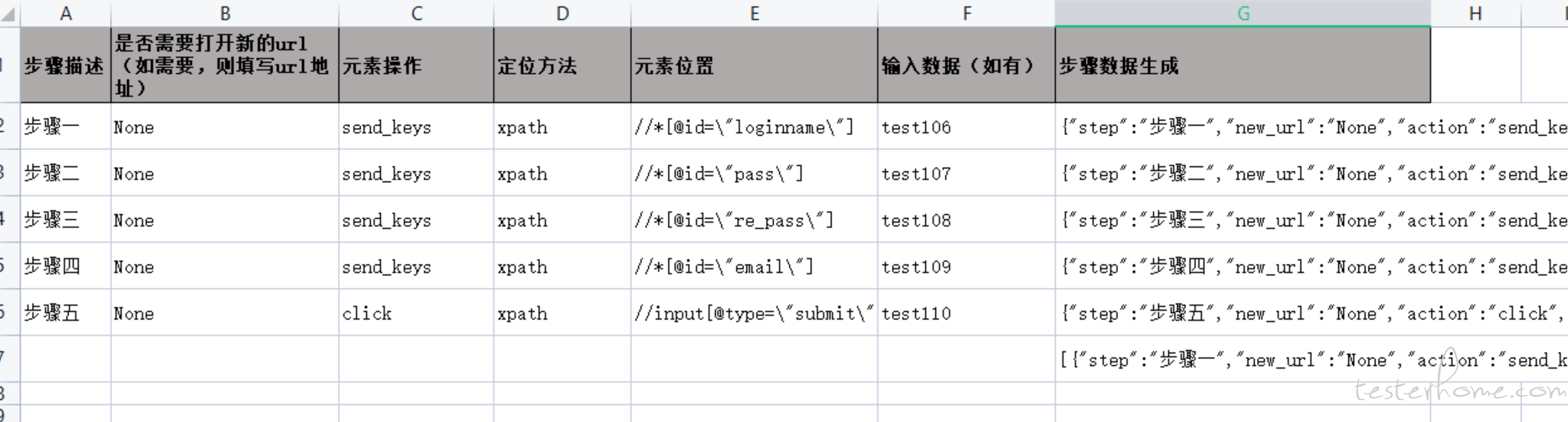
生成预期结果

UI 测试代码实现
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
"""
--------------
File Name: test_ui
Description:
Author: by_w
date: 2021/12/6 15:35
--------------
Change Activity:
2021/12/6 15:35
--------------
"""
import pytest
from selenium import webdriver
from . import common
import json
import time
import sys
class Test_UI:
def setup_class(self):
# 打开 browser
print('s',sys.argv[0])
self.web = common.Web_keys()
self.web.open_browser('f')
# 延时以加载元素,可使用 time.sleep 或 隐式等待 implicitly_wait(),隐式等待在整个driver周期生效,与sleep区分。
# 隐式等待在获取到元素后即进行下一步操作,但可能存在某些元素的size或其他属性未加载完全,需要固定等待以辅助元素获取。
# time.sleep(1)
# 最大化浏览器窗口,以便元素定位
self.web.maxsize()
def teardown_class(self):
time.sleep(3)
self.web.quit()
print('done')
# test_case = common.get_Data.get_json_data('./ui/ui_test_data.json',target1='uitestcase')
test_case = common.get_Data.get_execl_data('./ui/test_uidata.xlsx', sheetname='Sheet1', s_row=2)
print(test_case)
@user2ize('casename,url,test_data,res',test_case)
def test_non_relate_case(self,casename,url,test_data,res):
print('test case start')
print(casename)
print(url)
self.web.open_web(url)
for test in json.loads(test_data):
## 若使用的数据已经是从 json文件中读取,则无需转换
# for test in test_data:
print(test['step'])
if test['action'] != 'click':
self.web.ele_operate(new_url=test['new_url'],action=test['action'],method=test['path_data']['method'],path=test['path_data']['path'],data=test['path_data']['data'])
else:
self.web.ele_operate(new_url=test['new_url'], action=test['action'], method=test['path_data']['method'],
path=test['path_data']['path'])
time.sleep(3)
res = json.loads(res) ## 当res数据从 json文件中获取时,不需要 json.loads 读取
print('assert type is ',res['type'])
if res['type'] == 'text':
self.web.execpt_result(type=res['type'],method=res['method'],path=res['path'],data=res['data'])
if res['type'] == 'url':
self.web.execpt_result(type=res['type'],data=res['data'])
阶段总结
通过数据源的方式可实现对非关联用例的便捷测试,包括接口和 UI,鉴于当前的情况,使用 execl 是较为便捷的,后续会将在 execl 中合成用例的步骤写到程序,以可视化界面的方式实现,这样就可以使用多种数据源了,以此方向进行拓展,最终会形成一个平台框架,当前已经有不少自动化框架可以实现类似需求,不过在这过程中的思考与实践,应能加深对自动化框架的认识。
一些封装方法
接口测试代码中的 common 包
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
"""
--------------
File Name: common
Description:
Author: by_w
date: 2021/11/15 16:46
--------------
Change Activity:
2021/11/15 16:46
--------------
"""
import requests
import time
import json
from openpyxl import load_workbook
def get_str_datetime(strs):
date = time.strftime('%D %H%M%S')
strings = strs + date
return strings
def create_topic(url,data):
r = requests.post(url=url,json=data)
return r
def create_topic_data(token,title,tab,content):
test_data = {
'accesstoken': token,
'title': get_str_datetime(title),
'tab': tab,
'content': get_str_datetime(content)
}
return test_data
def update_topic_data(tab,title,content):
test_data = {
'tab': tab,
'title': get_str_datetime(title),
't_content': get_str_datetime(content)
}
return test_data
def json_display(r):
return json.dumps(r,ensure_ascii=False,indent=4)
def get_json_data(filename,target1=None,target2=None,target3=None,target4=None):
json_data = json.load(open(filename, mode='r', encoding='utf8'))
if target4 is not None:
return json_data[target1][target2][target3][target4]
elif target3 is not None:
return json_data[target1][target2][target3]
elif target2 is not None:
return json_data[target1][target2]
elif target1 is not None:
return json_data[target1]
def get_execl_data(filename,sheetname=None,s_row=None,s_column=None,f_row=None,f_column=None):
# wb = load_workbook('../global_val/test_execl.xlsx')
wb = load_workbook(filename)
if sheetname is None:
return wb.worksheets
else:
ws = wb[sheetname]
test_data = []
if s_row is None :
if f_row is None:
for rows in range(2, len(tuple(ws.rows))+1):
test_cell = []
if s_column is None:
if f_column is None:
for columns in range(1, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(1, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
print(ws.cell(row=rows, column=columns).value)
elif s_column is not None:
if f_column is None:
for columns in range(s_column, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(s_column, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
test_data.append(test_cell)
elif f_row is not None:
for rows in range(2, f_row+1):
test_cell = []
if s_column is None:
if f_column is None:
for columns in range(1, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(1, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif s_column is not None:
if f_column is None:
for columns in range(s_column, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(s_column, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
test_data.append(test_cell)
elif s_row is not None :
if f_row is None:
for rows in range(s_row, len(tuple(ws.rows)) + 1):
test_cell = []
if s_column is None:
if f_column is None:
for columns in range(1, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(1, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif s_column is not None:
if f_column is None:
for columns in range(s_column, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(s_column, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
test_data.append(test_cell)
elif f_row is not None:
for rows in range(s_row, f_row + 1):
test_cell = []
if s_column is None:
if f_column is None:
for columns in range(1, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(1, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif s_column is not None:
if f_column is None:
for columns in range(s_column, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(s_column, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
test_data.append(test_cell)
return test_data
UI 测试代码中的 common
#!/usr/bin/env python
# _*_ coding: utf-8 _*_
"""
--------------
File Name: common
Description:
Author: by_w
date: 2021/12/13 11:23
--------------
Change Activity:
2021/12/13 11:23
--------------
"""
import json
import openpyxl
from selenium import webdriver
import sys
class Web_keys:
def __init__(self):
self.driver = None
def open_browser(self,browser='g'):
if browser == 'g':
self.driver = webdriver.Chrome()
elif browser == 'f':
self.driver= webdriver.Firefox()
else:
print("当前只支持谷歌与火狐,请修改或增添代码")
def maxsize(self):
self.driver.maximize_window()
def open_web(self,url=None):
self.driver.get(str(url))
# 延时以加载元素,可使用 time.sleep 或 隐式等待 implicitly_wait(),隐式等待在整个driver周期生效,与sleep区分。
# 隐式等待在获取到元素后即进行下一步操作,但可能存在某些元素的size或其他属性未加载完全,需要固定等待以辅助元素获取。
# time.sleep(1)
self.driver.implicitly_wait(5)
def find_ele(self,method=None,path=None):
location = self.driver.find_element(method,str(path))
return location
def click(self,path=None,method='xpath',type='element'):
if type == 'element':
self.find_ele(method,str(path)).click()
elif type == 'js':
ele = self.find_ele(method,str(path))
# 避免出现click无效的情况,使用js进行点击。
self.driver.execute_script("$(arguments[0]).click()", ele)
else:
print('type error,please input type like str(element) or str(js)')
print('click')
def input(self,method='xpath',path=None,value=None):
self.find_ele(method,str(path)).send_keys(str(value))
print('input')
def into_iframe(self,method='xpath',path=None):
self.driver.switch_to.frame(self.find_ele(method,str(path)))
def get_url(self):
Current_URL = self.driver.current_url
return Current_URL
def quit(self):
self.driver.quit()
def ele_operate(self,new_url,action,method,path,data=None):
if new_url == 'None':
print('action is ', action, 'method is ', method)
if action == 'send_keys':
print('action is send_keys')
if method == 'xpath':
print('the method is xpath , path is ', path, 'data is ',data)
# self.web.find_element(method, path).send_keys(data)
self.input(method=method,path=path,value=data)
elif action == 'click':
print('action is click')
if method == 'xpath':
print('the method is xpath , path is ', path)
# self.web.find_element_by_xpath(test['path_data']['path']).click()
# ele = self.web.find_element(method,path)
# 避免出现click无效的情况,使用js进行点击。
# self.web.execute_script("$(arguments[0]).click()", ele)
self.click(method=method,path=path)
def execpt_result(self,type=None,method=None,path=None,data=None):
if type == 'text':
res_text = self.find_ele(method,str(path)).get_attribute('innerHTML')
# print(type(data))
print(data)
assert res_text == data , f"校验异常!!!\n当前检测值为: {res_text} \n 预期值为: {data}"
if type == 'url':
handles = self.driver.window_handles
print('当前存在的窗口句柄: ',handles)
current_handle = self.driver.switch_to.window(handles[-1])
print('当前使用的窗口句柄为: ',current_handle)
print('当前句柄名称为: ',self.driver.title)
res_url = self.driver.current_url
print(res_url)
assert res_url == data, f"校验异常!!!\n当前检测值为: {res_url}\n预期值为: {data}"
class get_Data:
def get_json_data(filename, target1=None, target2=None, target3=None, target4=None):
json_data = json.load(open(filename, mode='r', encoding='utf8'))
if target4 is not None:
print("target4")
return json_data[target1][target2][target3][target4]
elif target3 is not None:
print("target3")
return json_data[target1][target2][target3]
elif target2 is not None:
print("target2")
return json_data[target1][target2]
elif target1 is not None:
print("target1")
return json_data[target1]
def get_execl_data(filename, sheetname=None, s_row=None, s_column=None, f_row=None, f_column=None):
# wb = load_workbook('../global_val/test_execl.xlsx')
print('===========',sys.argv[0])
wb = openpyxl.load_workbook(filename)
if sheetname is None:
return wb.worksheets
else:
ws = wb[sheetname]
test_data = []
if s_row is None:
if f_row is None:
for rows in range(2, len(tuple(ws.rows)) + 1):
test_cell = []
if s_column is None:
if f_column is None:
for columns in range(1, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(1, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
print(ws.cell(row=rows, column=columns).value)
elif s_column is not None:
if f_column is None:
for columns in range(s_column, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(s_column, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
test_data.append(test_cell)
elif f_row is not None:
for rows in range(2, f_row + 1):
test_cell = []
if s_column is None:
if f_column is None:
for columns in range(1, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(1, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif s_column is not None:
if f_column is None:
for columns in range(s_column, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(s_column, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
test_data.append(test_cell)
elif s_row is not None:
if f_row is None:
for rows in range(s_row, len(tuple(ws.rows)) + 1):
test_cell = []
if s_column is None:
if f_column is None:
for columns in range(1, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(1, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif s_column is not None:
if f_column is None:
for columns in range(s_column, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(s_column, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
test_data.append(test_cell)
elif f_row is not None:
for rows in range(s_row, f_row + 1):
test_cell = []
if s_column is None:
if f_column is None:
for columns in range(1, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(1, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif s_column is not None:
if f_column is None:
for columns in range(s_column, len(tuple(ws.columns)) + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
elif f_column is not None:
for columns in range(s_column, f_column + 1):
test_cell.append(ws.cell(row=rows, column=columns).value)
test_data.append(test_cell)
return test_data
文章内容原创,部分代码非本网站首发,但有所更新。
我在【TesterHome 系列征文活动 | 自动化测试实践】等你,一起 day day up!
「原创声明:保留所有权利,禁止转载」

