背景
很久以前基于Robotframework + flask + reactjs开发了一套 Web UI 自动化系统,用于网站自动化测试和日常巡检。但是随着其应用覆盖的范围越来越广,发现存在一些设计上的短板,如:只能单一节点部署运行上限较低、交互上有些卡顿、系统账号体系独立未与公司统一认证打通、原有的库表设计和前端组件不支持图像识别功能的扩展等等。
出于以上的种种因素,结合部门测试工具链建设的需求,于是在我们新的综合自动化管理平台的基础上,进行了 WEB UI 自动化系统的开发。
由于本文较长,不该浪费大家太久时间阅读,建议先看下平台简介。
平台简介
这是我们的一个自动化综合管理平台,而本文介绍只是其中 WEB UI 自动化测试管理系统这一个模块。如下图:
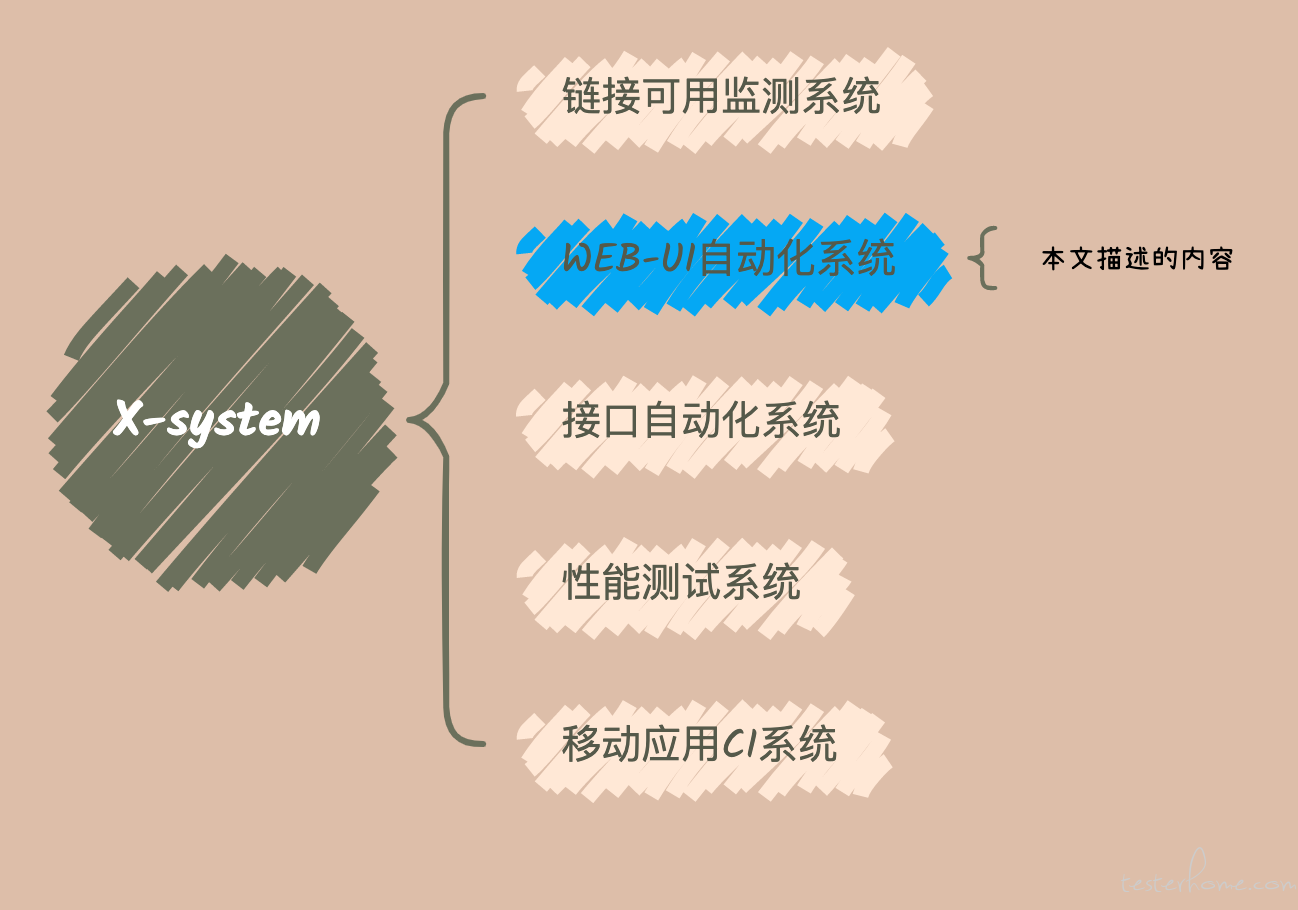
简要介绍下这系统是干啥的吧,这是个集成了自动化用例管理,测试任务管理,报告管理与一体的网页版工具。让测试人员可以在类似于 excel 的在线表单上维护 robotframework 语法的测试用例,并提供了搜索联想、元素定位插件辅助等提高用例编写效率的辅助功能。同时对于任务及报告,可以进行简单明了、可视化、灵活的配置管理。用例编辑部分可以理解为,类似于简化版在线版本 Ride,而分布式执行部分的设计,可以理解为简化后的 jenkins 的分布式执行和任务管理系统,结合 selenium-grid 的多 session 运行和 pabot 多进程特点进行调优,使我们自动化运行效率更高。让零散的系统归总为一,降低使用成本,测试人员只需要关注用例内容设计本身,并且可以更快更直观的看到测试结果。
实现效果
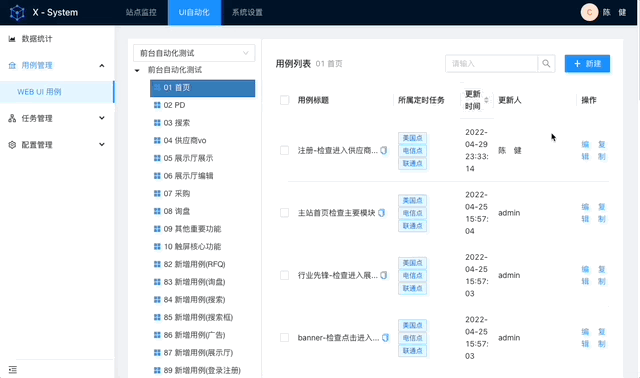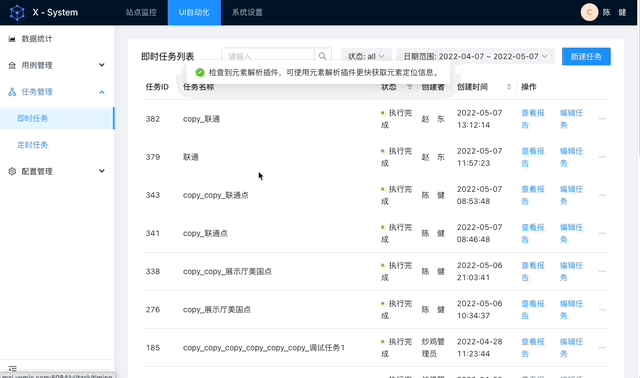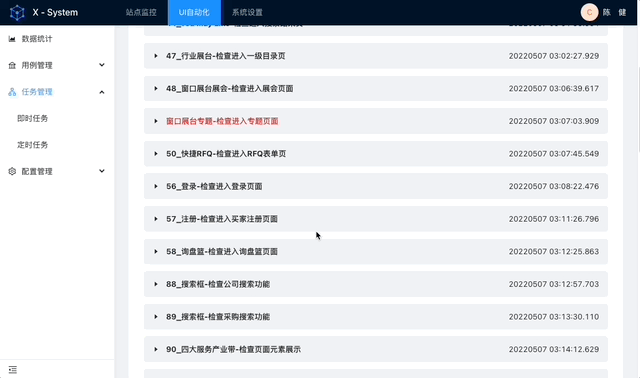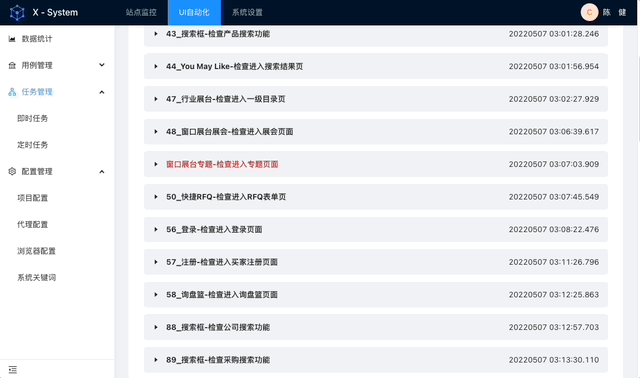
架构设计
系统整体采用的 B/S 架构,前后分离的开发模式,本章主要介绍综合自动化管理系统中的 WEB UI 自动化子系统,其结合 python celery 库进行分布式设计。
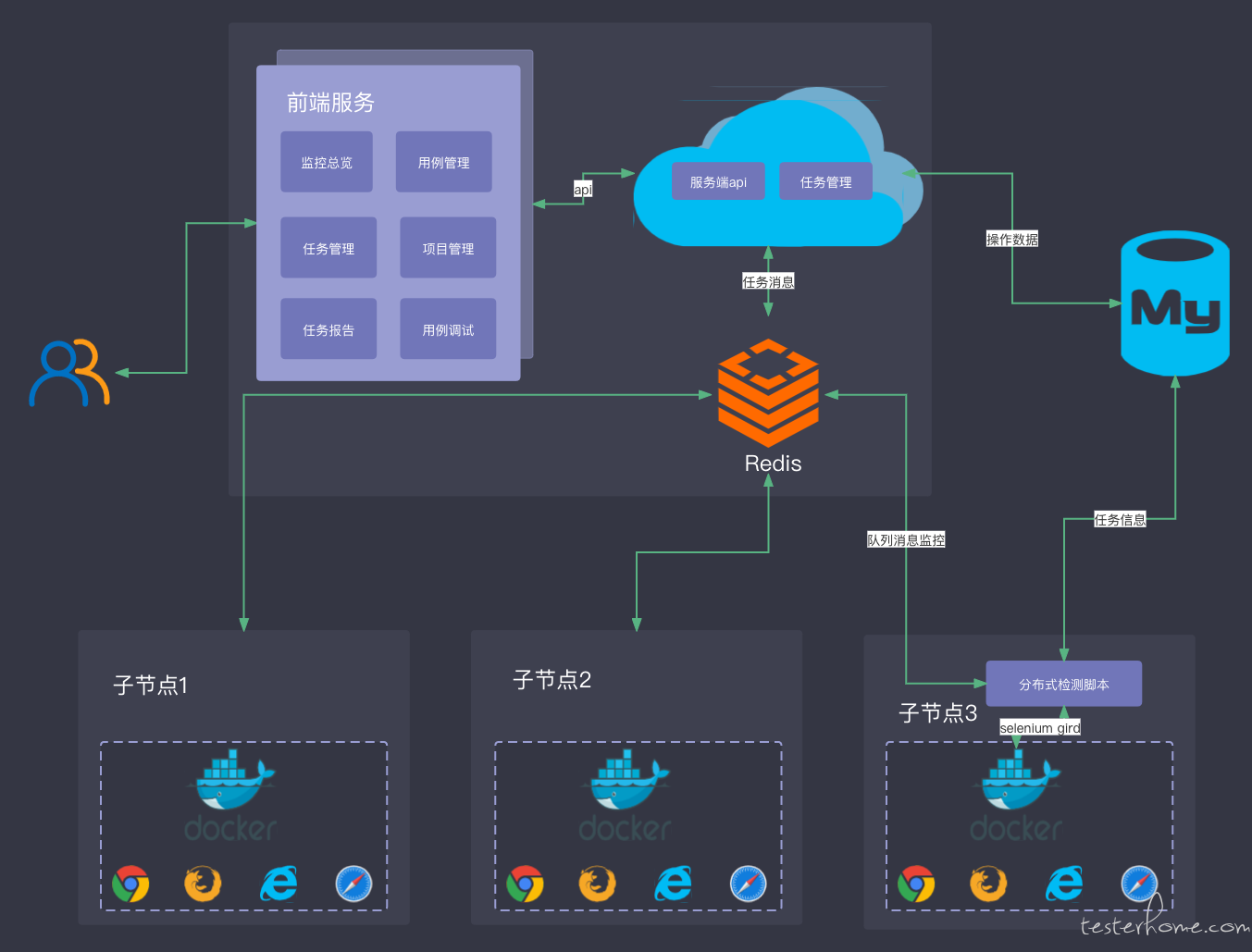
整体架构,后期功能调整的灵活性,和性能的扩展性都能很强,也是为以后结合 CI 系统进行大批量运行提供支撑。
功能设计
- [x] 公司的统一认证接入
- [x] 多维度首页数据统计
- [x] 用例管理
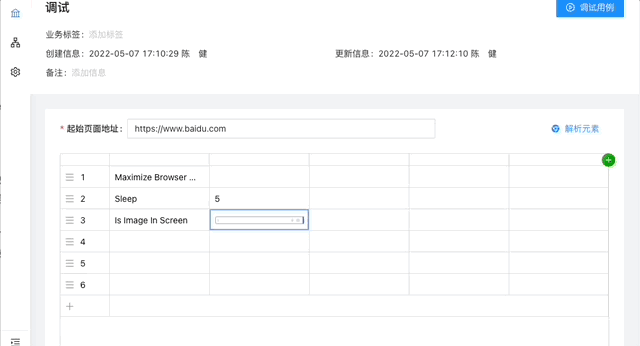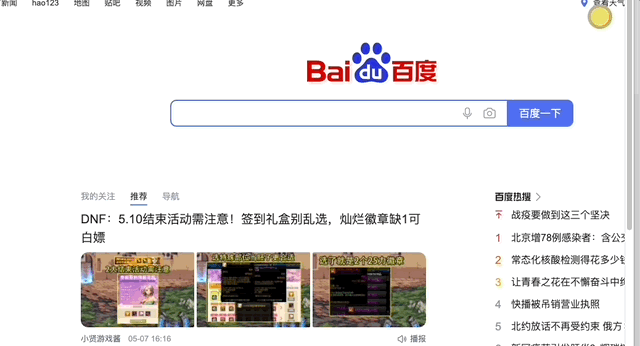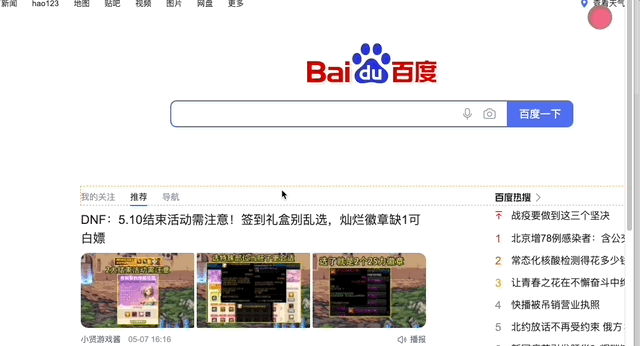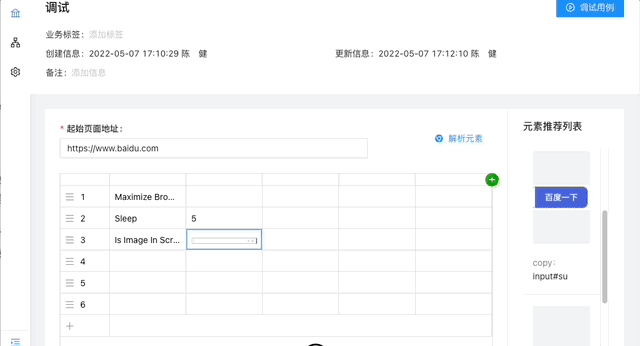
- [x] 用例实时调试
- [x] 图像元素识别支持
- [x] 自定义关键词管理
- [x] 全局参数管理
- [x] 项目管理
- [x] 浏览器管理
- [x] 代理配置管理
- [x] 系统关键词翻译管理
- [x] 即时任务管理
- [x] 定时任务管理
- [x] 网页元素自动解析
- [x] 分布式运行
- [ ] robotframework 用例导出
- [ ] 文本脚本导入
- [ ] 浏览器插件脚本录制
前端框架介绍
工程结构
前端框架整体参考Ant Design Pro 2的标准工程结构,并结合我们打造综合管理平台的可扩展需求,设计了双导航路由,代码结构上采用组件化分层设计。
基础功能组件基于全局可用性的设计封装,各个系统间业务代码独立,低耦合,便于后续功能的扩展和迁移。
├── assets //全局资源
│ └── logo.svg
├── components //全局组件
│ ├── Authorized
│ ├── GlobalHeader
│ ├── HeaderSearch
│ └── PageLoading
├── layouts //基础布局
│ ├── BasicLayout.jsx
│ ├── BlankLayout.jsx
│ ├── SecurityLayout.jsx
│ └── UserLayout.jsx
├── locales //本地化配置
│ ├── en-US
│ ├── en-US.js
│ ├── zh-CN
│ └── zh-CN.js
├── models //公共models
│ ├── global.js
│ ├── login.js
│ ├── setting.js
│ └── user.js
├── pages //功能页面
│ ├── LinkCheck //外链检查系统
│ ├── System //系统管理功能
│ ├── UAT //UI 自动化系统
│ │ ├── Case //用例管理模块
│ │ │ ├── CaseDetail //具体功能页面
│ │ │ ├── CaseList
│ │ │ ├── ModuleTree
│ │ │ ├── components //模块组件
│ │ │ ├── index.jsx
│ │ │ ├── index.less
│ │ │ ├── model.js //模块models
│ │ │ └── service.js //api管理
│ │ └── Config
│ │ └── Home
│ │ └── Task
│ │ └── assets
│ │ └── tim.svg
│ ├── User
│ └── document.ejs
└── utils
├── Authorized.js
├── authority.js
├── localSave.js
├── request.js
└── utils.js
基础数据流管理
由上述的工程结构可以看出,采用了umijs作为底层前端框架,整合dva做数据流管理。
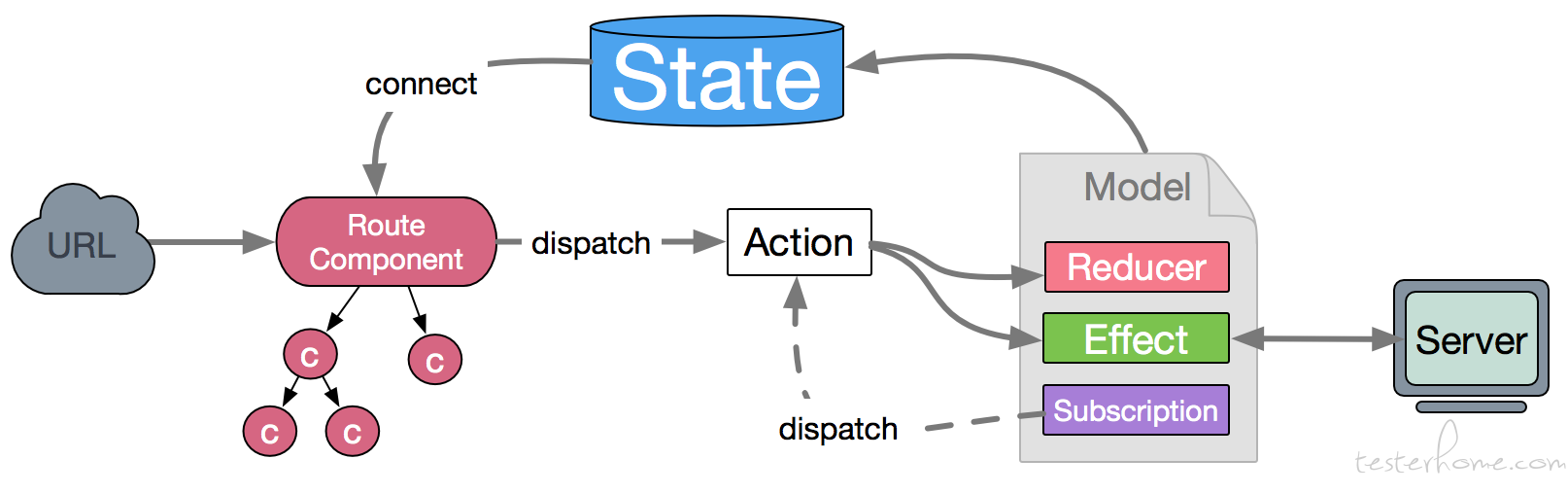
通过自定义封装的reducers可以方便的处理不同业务的返回数据。
// xxxx/model.js
import { queryDebugTaskInfo } from './service';
const Model = {
namespace: 'uatCase',
state: {
debugTaskId: null,
debugTaskInfo: null,
},
effects: {
*queryDebugTaskInfo({ payload }, { call, put }) {
yield put({ type: 'updateState', payload: { debugTaskInfo: null } });
const response = yield call(queryDebugTaskInfo, payload);
if (response && response.code === 0) {
yield put({ type: 'updateState', payload: { debugTaskInfo: response.content } });
}
},
*queryDebugCase({ payload }, { call, put }) {
yield put({ type: 'updateState', payload: { debugTaskId: null } });
const response = yield call(queryDebugCase, payload);
if (response && response.code === 0) {
yield put({ type: 'updateState', payload: { debugTaskId: response.content.taskId } });
}
},
},
reducers: {
updateState(state, { payload }) {
return { ...state, ...payload };
},
},
};
export default Model;
核心组件
页面组件的设计上,本着可服用、低耦合、高内聚的理念,结合业务本身特点,分为如下几种:
-
入口组件:页面业务组件的汇聚地,公用数据数据及方法的集合,以方便状态管理的
class编程实现。 - 业务模块组件:具体功能的业务组件,以列表入口、页面布局、功能模块为主,看需求采用函数式编程,还是 class 编程。
- 公共组件:以通用类型的数据展示为主,一般是对基础组件的自定义封装,以函数编程为主,所有的数据规则交由父级业务模块组件处理。
- 特殊功能组件:这种组件在系统用的不多,但不可避免的存在,如本系统的用例详情表单、用例 debug 的 VNC 模块等,复用的需求较小,一般以其模块的功能进行代码聚合,方便问题定位与维护。
前端依赖基础组件如下:
{
"antd": "^4.15.0",
"@ant-design/pro-form": "^1.3.0",
"react-contextmenu": "^2.14.0",
"react-data-grid": "^7.0.0-beta.11",
"react-vnc": "^0.4.0",
"@tinymce/tinymce-react": "^4.0.0",
"@antv/l7": "^2.1.9",
"react-dnd": "^15.1.1",
}
自定义组件介绍
本次的针对操作最为集中的表格组件,采用了react-data-grid,但其基础组件远不能满足我们的需求,因此需要进一步的封装。
做改动如下:
1.结合react-dnd实现表单行的拖拽排序:
<DndProvider backend={HTML5Backend}>
<DataGrid components={{...<DraggableRowRenderer ... />...}}/>
<DndProvider/>

2.结合react-contextmenu实现表格右键的扩展功能:
<ContextMenuTrigger
holdToDisplay={-1}
id='data_grid_context_menu'
...
>
...
</ContextMenuTrigger>
.
.
.
<ContextMenu id='data_grid_context_menu'>
<MenuItem>删除行</MenuItem>
</ContextMenu>

3.自定义动态列头,实现表格范围的可扩展:
caseSteps && caseSteps.stepColumns && caseSteps.stepColumns.forEach((columnKey, index) => {
newColums.push(
{
key: columnKey,
name: this.renderHeader(columnKey),
formatter: (record) => this.renderDataFormatter(record, columnKey),
editor: (record) => this.renderDataEditor(record, columnKey, projectId),
colSpan(args) {
if (args.type === 'ROW') {
if (args.row.rowId === 'default') {
return caseSteps.stepColumns.length;
}
}
return undefined;
},
},
);
});
if (newColums !== this.state.columns) {
this.setState({ columns: newColums });
}

4.结合图片组件,实现图片附件的单元格操作:
renderDataFormatter = (props, dataKey) => {
const { rowData } = props.row;
if (!rowData.hasOwnProperty(dataKey)) {
return TextEditor;
}
switch (rowData[dataKey].dataType) {
case 0:
return <span><MenuOutlined style={{ cursor: 'grab', color: '#999', marginRight: 5 }} /> {rowData[dataKey].value}</span>;
case 1:
return <span>{rowData[dataKey].value}</span>;
case 2:
return (
<div className={styles.wrapperClassname}>
<div className={styles.imageContainer}>
<Image
src={rowData[dataKey].value}
/>
</div>
</div>
);
}
return <span>{rowData[dataKey].value}</span>;
};
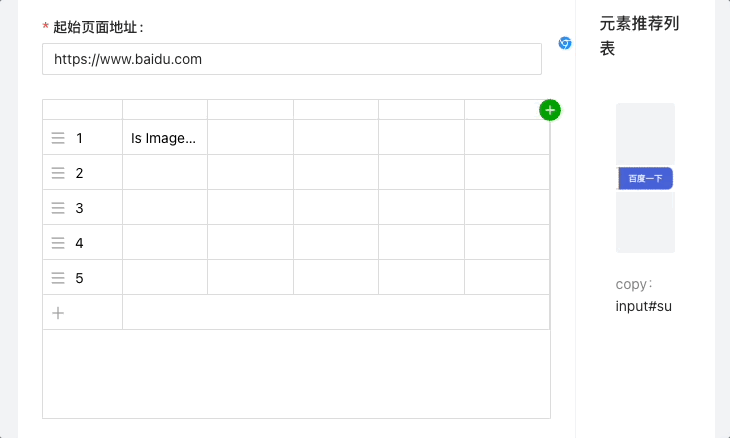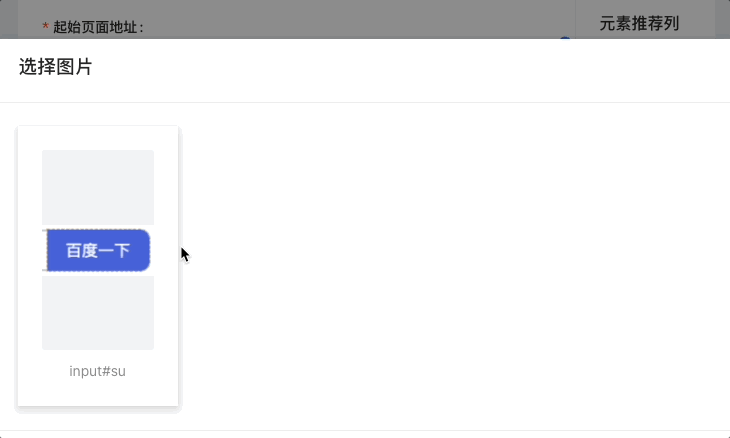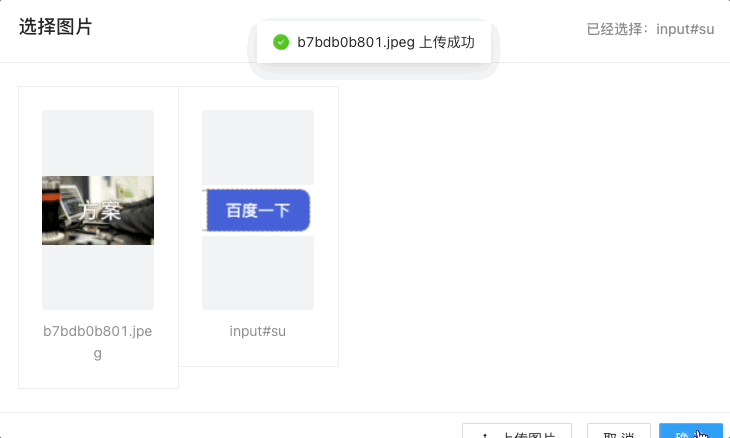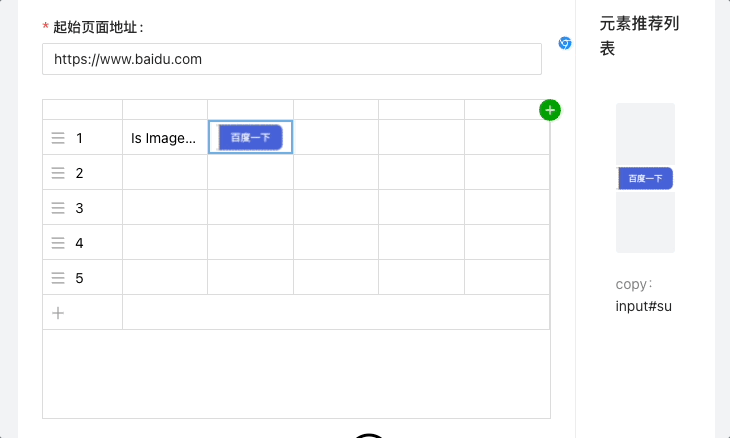
5.结合 VNC+selenium-grid,实现的实时调试功能:
import { VncScreen } from 'react-vnc';
...
<VncScreen
url={vncUrl}
loadingUI={....}
scaleViewport
background="#000000"
style={{
width: '80vw',
height: '70vh',
}}
/>
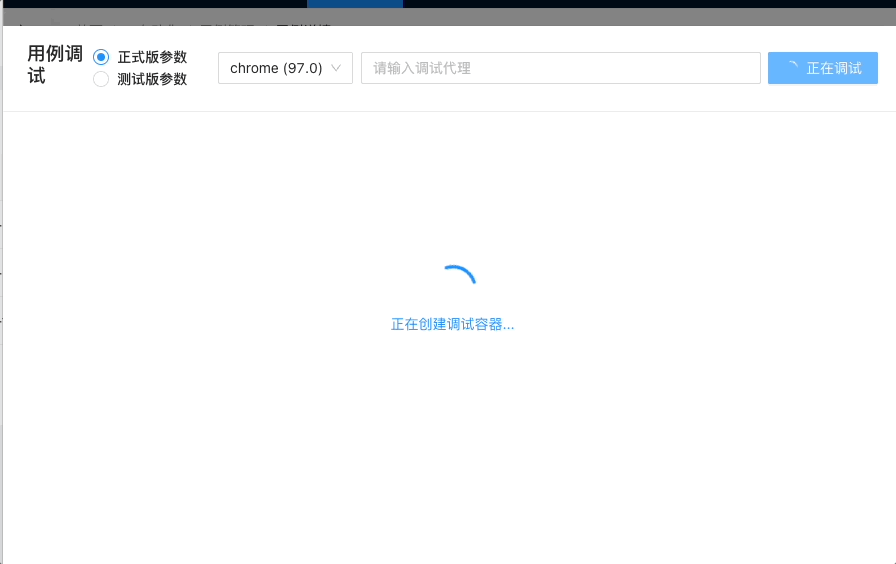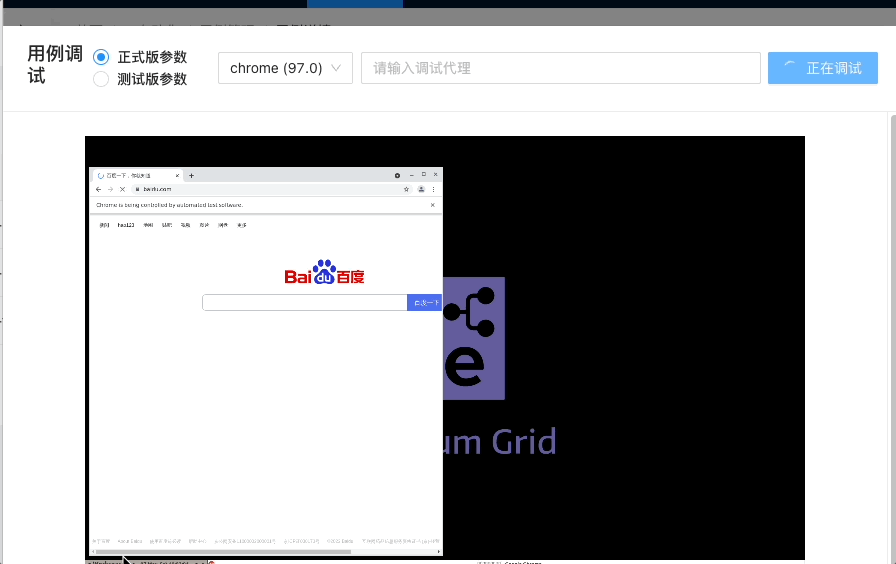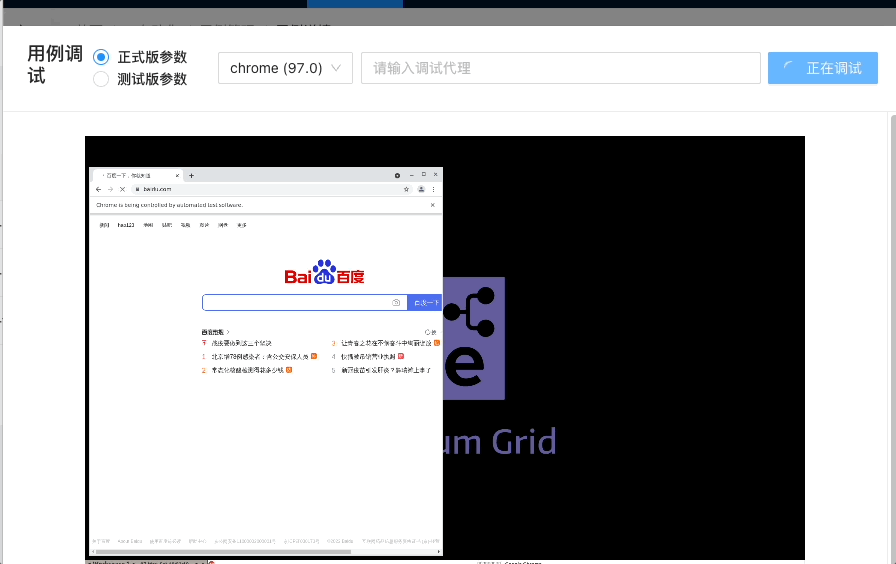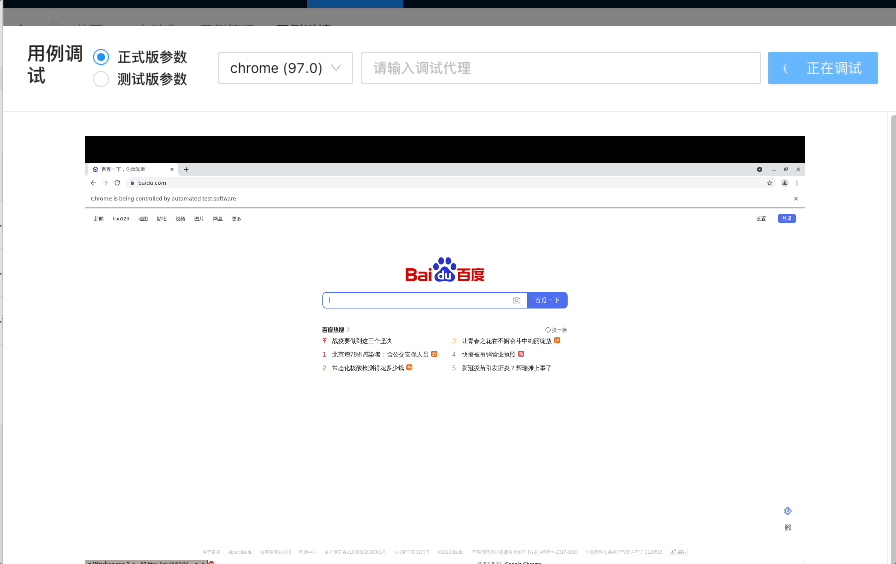
插件介绍
多年前,是撸过个鼠标右键的插件的,但是本打算简单小改接着用时,发现 google 强制升级了协议版本,而且升级后原来的一些写法就要大改,本来内容就不多,干脆一波直接用新 MV3 重做吧。
本插件主要提供的向用例编辑页面回传元素定位推荐值和元素图片截图,这 2 个功能的实现,主要依赖canvas、CSS Selector,其中的 css 定位值获取,依赖 optimal-select。
插件已上架 google 商店,但需要配合本自动化系统才能使用:web 元素捕手
实现效果
插件的工作原理
插件安装后,background.js就已经开始运行了,且只有一个,它能跨窗口、跨域名通信。content.js只有页面加载才会运行,且每个页面都是独立的,互不相通,可以获取当前页面的 DOM,但是能力受限。因此我们以background.js为跳板,实现跨页面通信,所以其核心要点,是要理清楚页面与插件的关系,简单概括为如下流程:
1.工具页面与插件 background 通过插件消息通信
2.background 与目标页面通过标签页面消息通信
3.标签页面消息回传 background,background 此时发送工具页面的 content
4.工具页面 content 发送窗口消息给工具页面
如果不清楚插件与页面的通信方法,理解上还有些吃力的,数据流转情况如下图,三个框分别代表了:工具页面、插件、目标页面。

核心方法
// 获取元素定位信息
function getSelector(element) {
let selector;
try {
selector = OptimalSelect.select(element, {
root: document,
priority: ['id', 'class'],
ignore: {
class(className) {
return className.length < 3;
},
attribute(name, value, defaultPredicate) {
return /data-*/.test(name) || defaultPredicate(name, value);
},
},
});
if (selector) {
const elementPos = element.getBoundingClientRect();
const { width, height } = elementPos;
if (width && height) {
chrome.runtime.sendMessage(
{ type: 'capElement', webPageTabId, elementPos, selector },
function (dataURL) {
getElementImage(dataURL, elementPos, webPageTabId, selector);
},
);
}
}
} catch (e) {
console.log(e);
}
}
// 创建元素截图
function createImage(dataURL, elementPos, webPageTabId, selector) {
// 兼容视网膜屏
const devicePixelRatio = window.devicePixelRatio;
// create a canvas
let canvas = createCanvas(
elementPos.width * devicePixelRatio + 10,
elementPos.height * devicePixelRatio + 10,
);
// get the context of your canvas
let context = canvas.getContext('2d');
// create a new image object
const croppedImage = new Image();
croppedImage.src = dataURL; // screenshot (full image)
croppedImage.onload = function () {
context.drawImage(
croppedImage,
elementPos.x * devicePixelRatio - 5,
elementPos.y * devicePixelRatio - 5,
elementPos.width * devicePixelRatio + 10,
elementPos.height * devicePixelRatio + 10,
0,
0,
elementPos.width * devicePixelRatio + 10,
elementPos.height * devicePixelRatio + 10,
);
// canvas.toDataURL() contains your cropped image
const elementCap = canvas.toDataURL();
chrome.runtime.sendMessage({ type: 'sendElement', webPageTabId, elementCap, selector });
};
}
服务端介绍
服务端用的是 python flask,由于是前后端分离,只需提供 api 接口。建议采用 pipenv 管理依赖,保持协作版本的一致性。在工程结构设计上也是考虑到扩展性,采用了蓝图管理路由,不同系统间的业务接口代码相互独立。
工程结构
├── Pipfile // pipenv依赖清单
├── Pipfile.lock
├── app
│ ├── __init__.py
│ ├── common // 工具类
│ │ ├── HTMLBuilder.py
│ │ ├── Notice.py
│ │ ├── __init__.py
│ │ ├── aes_util.py
│ │ ├── des_help.py
│ │ ├── docker_task.py
│ │ ├── emailCommon.py
│ │ ├── sch_task.py
│ │ ├── scheduler_tools.py
│ │ ├── system_common.py
│ │ ├── token.py
│ │ └── util.py
│ ├── htmlReportTemplete // html邮件模版
│ │ ├── link_check_report_templete.html
│ │ └── ui_auto_report_template.html
│ ├── inject.py // 全局拦截器
│ ├── router.py // 路由管理
│ ├── script // 子系统业务脚本
│ │ ├── LinkCheck
│ │ ├── UAT
│ │ └── __init__.py
│ ├── settings.py // 系统配置设置
│ ├── src // 系统业务接口
│ │ ├── UAT
│ │ ├── __init__.py
│ │ ├── auth // 公用鉴权接口
│ │ ├── linkCheck
│ │ └── system
│ └── tables
│ ├── Check // 库表模型
│ ├── System.py
│ ├── UAT
│ ├── User.py
│ └── __init__.py
├── celery_tasks // 分布式任务入口
├── celery_worker.py // celery实例化方法
├── db // 数据库表sql
├── logs
├── requirements.txt
├── run.py //系统启动入口
└── run_celery_app.sh //分布节点启动脚本
服务端框架介绍
最早的一版简洁服务端框架,只是将配置分离,随着需求变化,已经不断优化了多次,结合Flask-Script、Flask-SocketIO、celery、schedule目前的服务端框架支持如下:
- 路由统一管理
- 系统配置分离
- 全局拦截器配置
- 定时任务管理
- socket 接口支持
- 异步脚本支持应用上下文、数据库实例调用
- 依赖库统一管理
当然就目前的框架来说,来有很多可以优化的地方,如日志管理、全局返回处理等等,这也是我们下一步要去做的。
分布式方案
从上面的工程结构不难发现,我们的分布式客户端也在服务端代码中,由于依赖库的耦合度较高,这里就没做分离。实际部署分布式执行节点时,我们只需几步就可以启用一个新的节点:
- 1.拉下来工程
- 2.安装依赖
- 3.修改配置
即可启用节点。此处有几个前提条件:
- 建议 linux 系统、x86、x64 内核,不然 selenium-grid 的镜像运行会异常。
- python 3.8 已安装,高了或者低了都会有问题哦。
- docker-ce 版本 >= 20,低版本没有集成 compose 执行会报错。
关于 celery 原理,这不做详细的讲解。它的工作流程如下图:
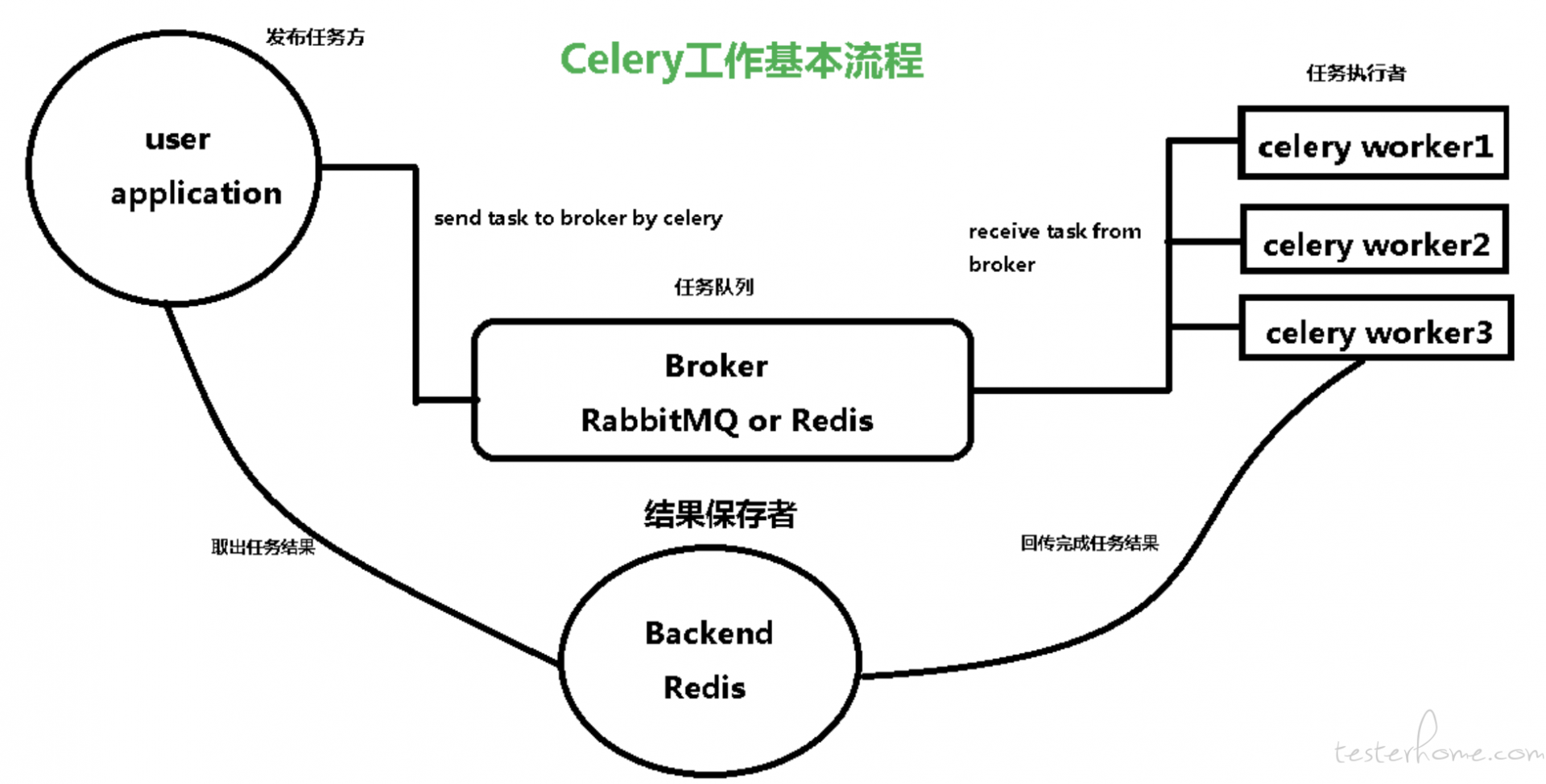
我们用到几个典型角色如下:
Task
任务触发者,可以立即执行、延迟执行。我们系统中已经有基于schedulers的定时任务管理,所以这里只需要用到立即执行功能,如下:
from celery_tasks.UAT.runTask import start
...
@uat_task.route('/exec', methods=['POST'])
def exec():
taskId = request.json.get("taskId")
...
start.delay(taskId)
...
Broker
接收生产者发来的消息即 Task,将任务存入队列。通过Redis、RabbitMQ实现队列服务。当任务执行失败或执行过程中发生连接中断,celery 会自动尝试重新执行任务。如果任务没有消费掉会一直存在于队列中,这里我们可以通过配置合理管理我们的代理人。
app.config['CELERY_TASK_RESULT_EXPIRES'] = 60 * 20 # 任务过期时间,celery任务执行结果的超时时间
app.config['CELERYD_PREFETCH_MULTIPLIER'] = 1 # celery worker 每次预取任务的数量
app.config['CELERYD_CONCURRENCY'] = 10 # celery worker的并发数,默认是服务器的内核数目
Worker
任务的执行节点,它实时监控消息队列,如果有任务就获取任务,并调用自定义的脚本执行它。
同时通过客户端的启动参数-O fair启用 celery 的公平分配策略,让我们的任务量分配更均匀,提高执行效率。启动命令,我们封装到脚本run_celery_app.sh,方便与 python 环境的结合。
#!/usr/bin/env bash
export PYTHONPATH="${PYTHONPATH}:${PWD}"
celery -A celery_worker.celery worker --loglevel=info -P gevent -c 10 -O fair
核心脚本设计
有了上述的分布式结构后,我们的核心脚本主要在是节点 worker 上运行,关键步骤如下图:
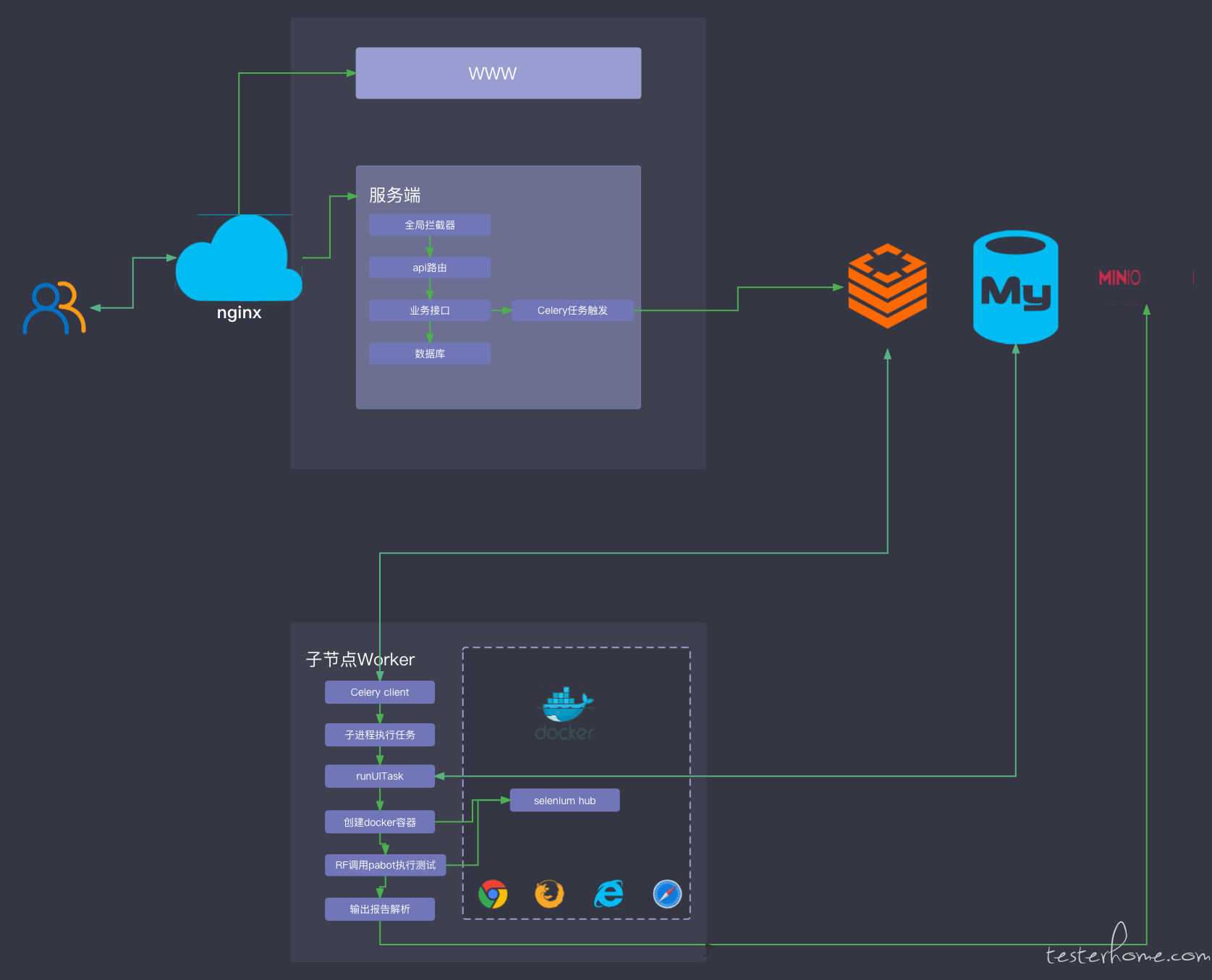
主要脚本步骤
测试运行的关键是:
组织测试数据》创建运行环境〉执行测试》分析执行结果〉清理环境。
def main(self, is_debug):
try:
self.get_task_info() #组织任务数据
self.ip, self.hub_port = self.get_hub_addr() #获取空闲端口,用于容器挂载
if not self.ip or not self.hub_port:
self.set_task_status(4)
logger.error('Get local ip or port error!')
return
self.build_workspace_dir(self.hub_port)
run_result = self.run_task() #执行任务
if not run_result:
self.set_task_status(4)
logger.error('Docker container create failed!')
return
total_count, pass_count, fail_count, fail_cases, exec_round_time = self.analysis_log() #分析日志
# 上传日志结果文件
self.save_log(total_count, pass_count, fail_count, fail_cases, exec_round_time)
# 上传任务截图
self.upload_task_screenshot(self.workspace_dir, '.png')
# 发送消息通知
self.task_log_notice(total_count, pass_count, fail_count, exec_round_time)
logger.info(f"Run task {self.task_id} complete")
self.set_task_status(3)
except Exception as e:
logger.error(str(e))
self.set_task_status(4)
if not is_debug:
# 清理hub
logger.info("clear project")
self.clean_hub()
self.clean_project()
动态执行容器
可以看到我们是用 selenium-grid 作为任务的执行容器,它本身也是支持分布式的,但我们之所以没有直接用 selenium-grid 作为分布式框架,一方面出去自身定义的灵活性考虑,另一方面可以看看官方 issues 里,实际实验过程中,其长时间运行的稳定性也很随缘。
不过它的 vnc 支持、容器化封装、浏览器版本丰富,是我们实时调试的必要基件。后续也会考虑,将批量运行与 selenium-grid 剥离,进一步提高执行效率。
目前我们结合节点机器的性能,和自深的任务执行量,优化了docker-compose的动态容器创建方法,如下:
def create_docker_compose(self, hub_port):
#docker_image_hub = 'seleniarm' # mac m1芯片为取 seleniarm 仓库,其它为 selenium
docker_image_hub = app.config['Gird_HUB']
task_browser_id = TaskTable.query.filter(TaskTable.id == self.task_id).first().browser
docker_image_nod = Browsers.query.filter(Browsers.id == task_browser_id).first().docker_image
self.task_browser_name = Browsers.query.filter(Browsers.id == task_browser_id).first().browser_name
self.task_browser_ver = Browsers.query.filter(Browsers.id == task_browser_id).first().version
node_number = self.get_node_number()
env = [
f'SE_EVENT_BUS_HOST=selenium-hub-{hub_port}',
'SE_EVENT_BUS_PUBLISH_PORT=4442',
'SE_EVENT_BUS_SUBSCRIBE_PORT=4443',
'SCREEN_WIDTH=1920',
'SCREEN_HEIGHT=1080',
'SE_NODE_MAX_SESSIONS=5',
'SE_NODE_OVERRIDE_MAX_SESSIONS=true',
'VNC_NO_PASSWORD=1',
'TZ="UT"',
]
if self.task_info['proxy']:
env.append(f"http_proxy={self.task_info['proxy']}")
env.append(f"https_proxy={self.task_info['proxy']}")
compose_data = {
'version': '3',
'services': {
f'selenium-hub-{hub_port}': {
'image': f'{docker_image_hub}',
'container_name': f'selenium-hub-{hub_port}',
'ports': [f'{hub_port}:4444']
}
}
}
for i in range(0, node_number):
compose_data['services'][f'{self.task_browser_name}-{hub_port}-{i}'] = {
'image': f'{docker_image_nod}',
'shm_size': '2gb',
'platform': 'linux/amd64',
'container_name': f'node-{self.task_browser_name}-{hub_port}-{i}',
'depends_on': [f'selenium-hub-{hub_port}'],
'environment': env,
}
generate_yaml_doc_ruamel(f"{self.workspace_dir}/docker-compose.yml", compose_data)
``` python
self.docker = DockerClient(compose_files=[f"{self.workspace_dir}/docker-compose.yml"])
self.docker.compose.up(detach=True)
图像识别库改造
前期调研时,还是乐观的,因为 appium 已经实现了图片元素的定位,想着 RF 实在不行,起个 appium 服务,专门处理图像识别也行啊。后来也找到了RobotEyes,可实际应用起来发现,它一个图片对比,要 2 分钟。还以为是我姿势不对,分析了源码发现,它使用的是Imagemagick的compare,官方也说了,就是这么慢。瞬间就不香了,必须搞它。
fork 了个分支自己改造:RobotEyes,对于图像对比,我换成了convert,效率提高 120 倍:
compare_cmd = f'convert "{self.img1}" "{self.img2}" -metric RMSE -compare -format "%[distortion]" info:'
结合我们断言元素图片是否存在的需求,加了个关键字Is Image In Screen,后续也会参考 appium 增加更多图片处理关键字。
一开始只是简单的用的 opencv.matchTemplate,效率倒是挺快,但是准确堪忧,特别元素图片来源不同,大小比例不确定,基本玩不转了。
不过经过多方实验后,采用了多例缩放对比的方法,算是解决了,详见代码。还有优化空间,有空研究下特征识别在自动化中的应用。
...
# 读取测试图片并将其转化为灰度图片
gray = cv2.cvtColor(raw_screen, cv2.COLOR_BGR2GRAY)
found = None
# 循环遍历不同的尺度
for scale in np.linspace(max_scale, min_scale, step)[::-1]:
# 根据尺度大小对输入图片进行裁剪
resized = imutils.resize(gray, width=int(gray.shape[1] * scale))
r = gray.shape[1] / float(resized.shape[1])
# 如果裁剪之后的图片小于模板的大小直接退出
if resized.shape[0] < tH or resized.shape[1] < tW:
continue
# 首先进行边缘检测,然后执行模板检测,接着获取最小外接矩形
edged = cv2.Canny(resized, 50, 200)
# plt.imshow(edged)
result = cv2.matchTemplate(template, edged, cv2.TM_CCOEFF_NORMED)
(_, maxVal, _, maxLoc) = cv2.minMaxLoc(result)
...
灰化后的元素图片:
模版图的比例是被放大后截取的,同样可以定位识别到:
----2022/05/31 更新----
关于图像识别,上面的模版匹配对与模版数据的要求较高,且精度较低。
因此目前我们采用了特征匹配方案:
实现效果如下:
定时任务执行器
第一版的定时任务执行方法,是手撸的时间字符串匹配。性能开销大,灵活性差。这次结合scheduler进行了改造。对接了 cron 表达式,可以更灵活的配置我们的定时任务。
def execute_uat_time_task(task_id, task_cron):
cron_dict = get_cron_info(task_cron)
if cron_dict:
logger.info('创建定时执行任务:{}'.format(json.dumps(cron_dict)))
scheduler.add_job(
start_uat_time_job,
'cron',
minute=cron_dict['minute'],
hour=cron_dict['hour'],
day=cron_dict['day'],
month=cron_dict['month'],
day_of_week=cron_dict['day_of_week'],
id='uat'+str(task_id),
args=[task_id],
max_instances=4
)
# scheduler.start()
else:
print("run UI timing task {0} error".format(task_id))
结合 flask 框架,我们在应用启动时把scheduler实例化,与业务接口接合,可以更灵活的管理我们的在运行任务。
# app/__init__.py
'''
定时任务管理器
'''
from apscheduler.schedulers.background import BackgroundScheduler
scheduler=BackgroundScheduler()
scheduler.start()
...
# task.py
from app import db, scheduler
...
@uat_task.route('/stop', methods=['POST'])
def stop():
taskId = request.json.get("taskId")
...
scheduler.remove_job('uat'+str(taskId))
...
获取 debug 实时画面
这里有个小技巧,本次采用的 selenium-grid 本身是支持 vnc 展示的,但是要容器的 5900 端口挂载出来,意味着有一个 node 要多占用一个端口,这个开销也不小。
分析了它的源码后,发现不需要知道具体执行 node 的端口和 ip,可以通过 sessionid,拼接成一个 vnc 访问地址,hub 中已经帮忙我们做好转发了。
我们在创建容器时需要设置VNC_NO_PASSWORD=1,然后根据 hub 的 session 列表获取 id 即可,因为我们自身的需求是只有用例调试时才需要看 vnc 实时画面,而且此时只会有一个 session,所以直接返回第一条即可:
def get_hub_sessions(hub_ip, hub_port):
session_ids = []
url = f"http://{hub_ip}:{hub_port}/graphql"
data = {
"query": "{ sessionsInfo { sessions { id } } }"
}
try:
res = requests.post(url, data=json.dumps(data), headers={"Content-Type": "application/json"}, timeout=5)
resp = res.json()
for session in resp['data']['sessionsInfo']['sessions']:
session_ids.append(session['id'])
except Exception as e:
logger.error(str(e))
return session_ids
后面就是前端处理了:
queryDebugTaskSession = (taskId) => {
const { dispatch } = this.props;
dispatch({
type: 'uatCase/queryDebugTaskSession',
payload: { taskId },
}).then(() => {
const { debugSessionIds } = this.props.uatCase;
if (debugSessionIds && debugSessionIds.length > 0) {
const { debugTaskInfo } = this.state;
this.setState({
debugSessionIds,
vncUrl: `ws://${debugTaskInfo.hub_ip}:${debugTaskInfo.hub_port}/session/${debugSessionIds[0]}/se/vnc`,
});
}
});
};
结语
以上仅是综合自动化平台中,WEB UI 自动化系统部分的开发介绍。道阻且长,然而坚持就是胜利,多思考、多搜索,就没有爬不出去坑。
 给大佬点赞 大佬的接口平台非常不错 这个也看看
给大佬点赞 大佬的接口平台非常不错 这个也看看 可能我不是很理解将 robotframework 脚本编写 Web 化优势是什么,投入产出比到底如何。实际上使用 git 和 gitlab 的方式足以管理测试脚本了,使用 jenkins 作为持续集成的工具,本来就带了任务调度,任务分发的功能。
可能我不是很理解将 robotframework 脚本编写 Web 化优势是什么,投入产出比到底如何。实际上使用 git 和 gitlab 的方式足以管理测试脚本了,使用 jenkins 作为持续集成的工具,本来就带了任务调度,任务分发的功能。