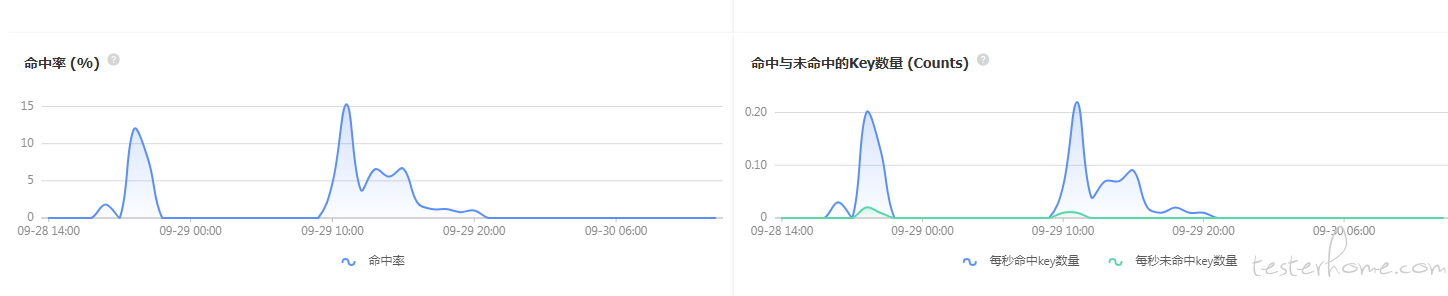
问题:
最近需要做一个长时间的压测,大致需求是每 5s 并发 1w 个请求持续 48h,目前是通过 Python locust 分布式实现的。在压测前 15min 左右,locust 收集的 RPS 和 RT 波动较大并且有较多的 504、502 错误产生,后续基本趋于稳定。

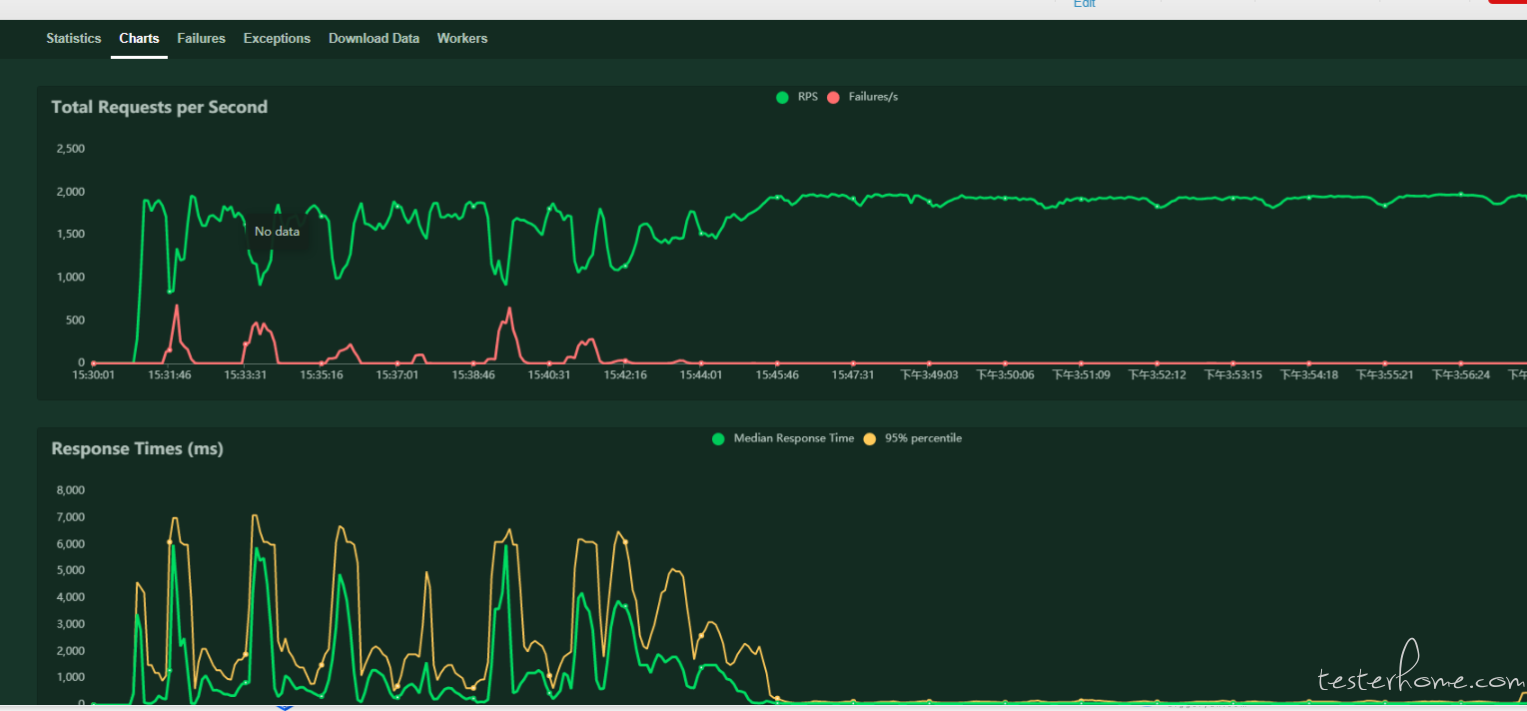
locust 启动时孵化率是 200/s,期间我看了下荷载机的 CPU,每个核心的占用基本上不超过 70%
请问下这种情况的原因一般是什么呢?
环境:
后台:golang+MongoDB
服务配置:5*(4C8G)
荷载机配置:16C 32G