接口测试 【测试平台开发】云筑网 “天眼” 质量平台系列(三)--- 如何实现接口自动化
前言
前两篇文章已主要介绍了系统概览及如何从 0 到 1 搭建一个测试平台,本文主要介绍测试平台的核心功能如何实现接口自动化,文章较长,文字较多,请各位看官收藏后再仔细阅读。如有不足或建议,请积极留言。ღ( ´・ᴗ・· )比心。
一、用例的解耦
一个完整的接口自动化 case,需要包含以下 3 部分信息:
1.关联接口对应系统的域名,相关登陆信息,部分系统还需要请求参数的对应加密算法。
2.关联接口的协议,api,header 等基本信息。
3.case 自身的请求报文,响应断言和前后置操作等信息。
因此天眼平台提取共性抽象出了环境配置,接口管理功能。用户只需录入一次项目组环境信息和接口基本信息后,就只需专注编写对应自动化 case 本身信息不用在关心系统和接口基本信息。简化了用例编写步骤实现了用例和系统接口的解耦。
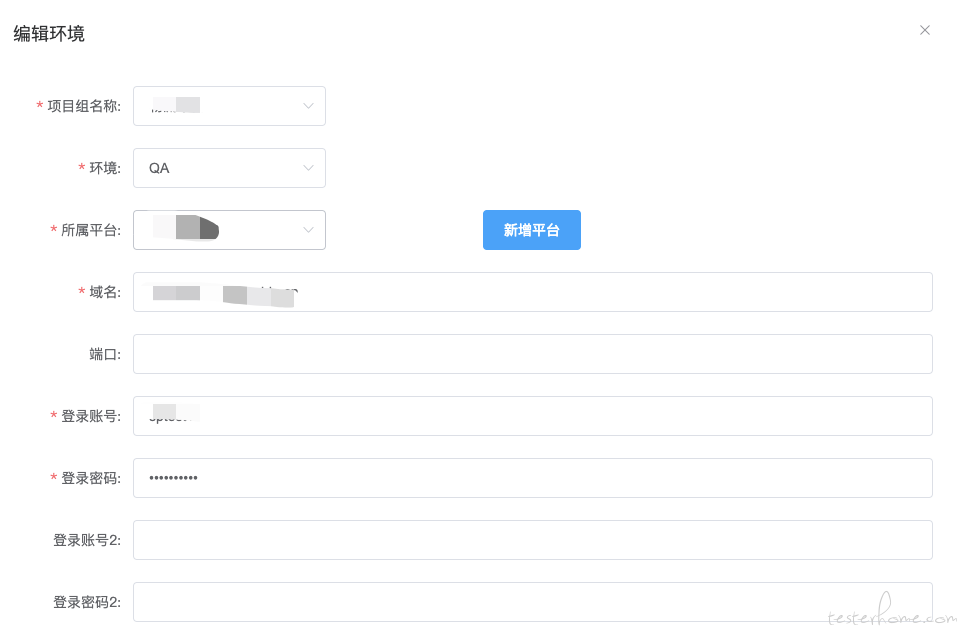
1.环境配置信息
具体的环境配置如下图所示,项目组就是业务线的概念,而所属平台指的就是具体系统。例如一个电商业务线下面会有采购商系统,供应商系统,运营后台三个系统。环境则指的 qa,预发布,线上环境。而每个所属平台则会绑定多个登录账号。而接口管理功能中,接口都会绑定一个所属平台。
2.用例多环境多账号的免登录的实现
执行用例集时,会选择用例运行的环境和不同系统对应的登录账号。执行某个用例时通过该用例关联的接口所属平台加上运行环境,既可以唯一确定当前用例执行的具体环境信息。此时通过运行环境+登录账号+域名作为 key 从 redis 获取对应的 cookie 信息,放入请求 header。如果通过 key 获取不到 cookie,就会使用域名 + 登录账号 + 所属平台调取对应的登录服务,登录成功则将对应的 cookie 放入用例请求 header 同时也会存入 Redis。为了防止系统登录过期,Redis 里的 key 都会设置过期时间。天眼平台通过这种对不同系统登录的内部封装,让平台使用者编写接口自动化用例时,完全不用关心用例如何登录不同环境不同账号,同时引入 Redis 也避免了每次执行用例都需要调用登录服务,节省了用例的执行时间。
public Map<String, String> getTokenMap(EnvironmentPO environmentPO) throws NoSuchAlgorithmException, KeyStoreException, KeyManagementException {
Map<String, String> headerMap = new HashMap<>();
//判断redis是否启用
if (redisEnable){
String redisKey = redissonService.getRedisKeyForCookie(environmentPO);
String value = redissonService.getValue(redisKey);
//判断cookie信息是否在Redis中存在,假如不存在则调用登录服务
if (Strings.isBlank(value)){
headerMap = login(environmentPO.getGroupId(), environmentPO);
if (headerMap == null) {
return null;
}
JSONObject headerJSON = new JSONObject();
for (String key : headerMap.keySet()){
headerJSON.put(key, headerMap.get(key));
}
redissonService.setValue(redisKey, headerJSON.toJSONString());
//能够从redis中获取登录信息,直接使用
}else {
JSONObject valueJson = JSONObject.parseObject(value);
for (String key : valueJson.keySet()){
headerMap.put(key, valueJson.getString(key));
}
}
//没有启用redis,直接走登录
} else {
headerMap = this.login(environmentPO.getGroupId(), environmentPO);
}
return headerMap;
}
3.接口 api 管理及调试
什么是接口 api,即需要验证测试的接口,测试同学主要需要维护用例的载体。当前我司平台需要维护的内容如下图:

针对接口信息维护,无外乎就是常规的增删改查,这里不做过多说明。
接口路径:接口具体的相对路径,例如:/api/test/getUser
协议:主要支持 http 和 https 两种(后续可扩展支持其他类型协议接口)
请求方法:支持主流的 get、post、put、delete
header 管理:用户可自定义配置;会根据用户选择的入参类型给一个默认值:form 表单使用 Content-Type = application/x-www-form-urlencoded,json 格式使用 Content-Type = application/json
同时在接口管理中,接口会关联所属平台,将接口和系统绑定。通过接口信息的维护,用户在编写自动化 case 时,被测接口的相关信息全部同步到用例编写页面,用户只需专注于请求报文,响应断言,前后置操作的编写,实现了用例和接口的解耦。
这里特别提一下接口的调试功能,该功能设计的初衷是为了测试同学录入接口之后,使用接口文档提供的默认参数和 qa 环境的配置发起请求(由于接口是维护的是相对路径,这也是为啥需要获取 qa 环境的配置,目的是组装接口 URL 全路径),检验接口录入的正确性。
二、接口用例管理及调试
用例维护分为:基础信息、前置步骤、用例步骤、后置步骤;为了提高录入用例的效率我们还提供了复制用例的功能,针对同一个接口,如果步骤一致的情况下,只需要修改入参即可。

录入用例信息
基础信息:主要是确定该用例是是调用哪个接口,及用例名称
前置步骤:为测试用例提供前置操作,例如从数据库查查询值并提取作为后续步骤入参;从数据库删除数据;支持配置多条前置步骤。配置方法是先选择对应的数据库(前面已经有讲到数据库配置的相关功能),然后配置 sql 语句;最后如果需要提取参数,再配置提取参数名称及提取表达式(强调:本系统所有的变量提取都使用的是 jsonPath 提取,后文不再赘述);当前仅支持数据库类型的前置操作,后续可支持 redis 相关的前置操作,毕竟部分接口会受缓存影响,不操作 redis 的话无法测到服务内部逻辑;
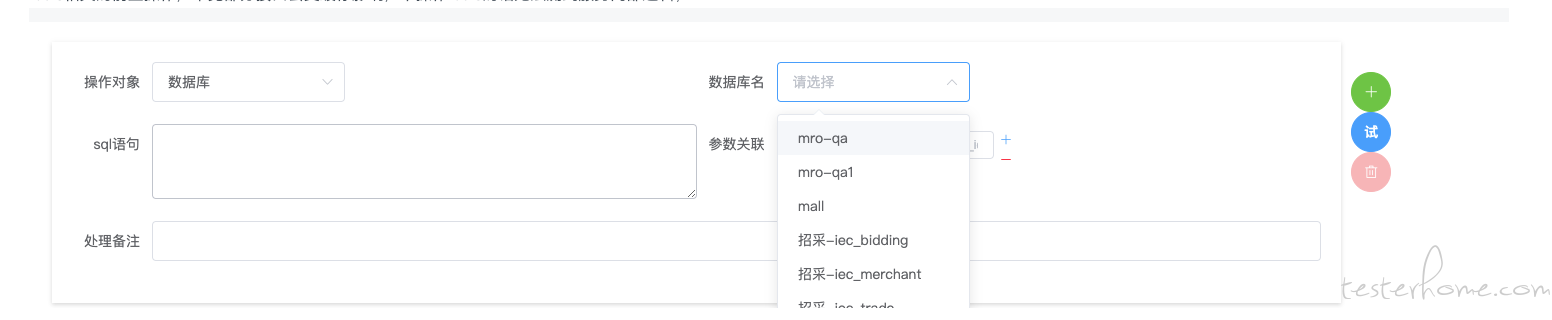
测试步骤:用例主流程,可支持多步骤;添加步骤时默认使用本接口,同时也可以选择其他接口(有同学会问为啥测试本接口为啥还要选择其他接口呢?那就不卖关子了,举个具体的例子吧:比如要测试一个订单取消接口,从哪儿获取有效的可取消的订单呢?除了使用前置步骤从数据库获取之外,我们还可以调用创建订单接口来获取真实订单,保证每次都使用真实的订单。);维护接口入参及 header,该信息都可以直接从选择的接口上获取,测试同学可根据实际步骤修改入参,即可实现不同步骤使用不同参数;接下来是断言,本系统支持两大类断言:返回值断言和数据库断言;最后是后置提取项,非必填,可根据实际场景配置,实现前后步骤的关联。
数据库: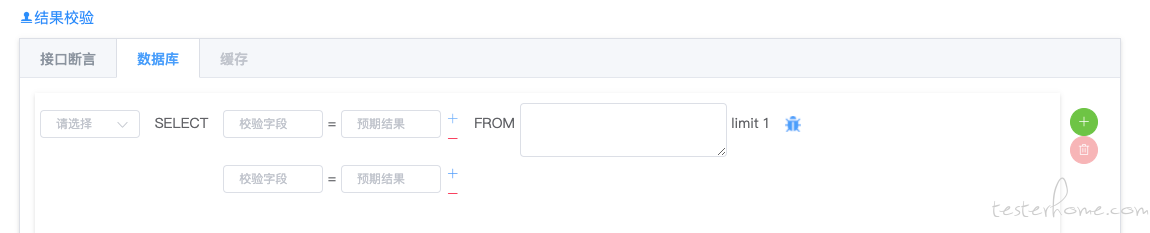
返回值:
为提高录入测试用例的效率,我们还增加了复制步骤的功能。
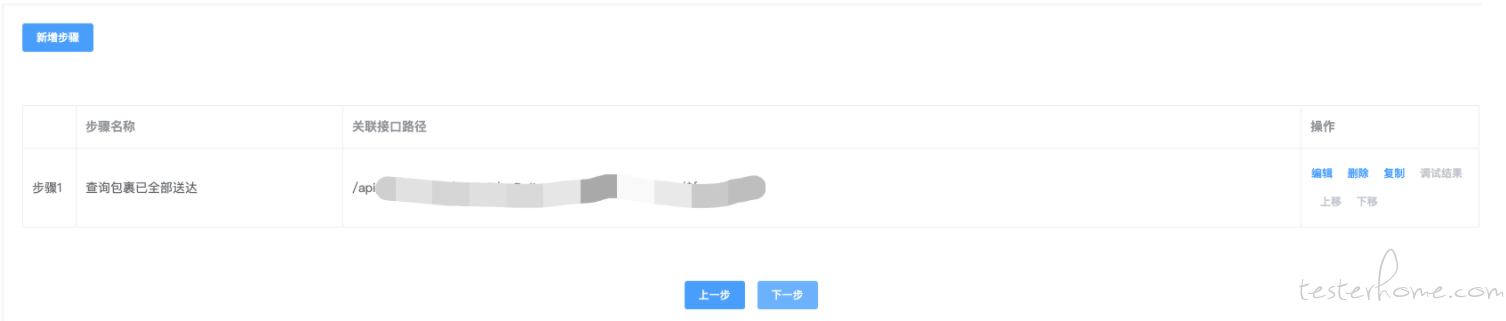
后置步骤与前置步骤一样,不再介绍。
调试
说完了用例的维护,接下来看看用例的调试。从用例维护的信息来说,肯定是需要调试 sql、调试接口请求、调试断言、调试提取。调试的执行必须指定一个测试计划,因为用例上未关联环境信息。因为 sql、请求参数、url 路径、断言预期结果等都有可能包含变量,所以针对每一个步骤的执行,都需要执行替换操作。
if (relateParam != null && sql.contains("${")) {
for (String param : relateParam.keySet()) {
if (!Strings.isBlank(relateParam.get(param))) {
sql = sql.replace("${" + param + "}", relateParam.get(param));
}
}
}
首先来说前置步骤的 sql 提取,代码内部实现一个基于 jdbc 封装的一个 service 类,提供连接 sqlserver 或者 mysql;提供增删改查语句执行及结果返回;然后根据 sql 语句的首个单次判断调用什么 sql 语句。这里需要讲一下我们统一将 sql 语句执行结果返回为字符串(这里有个问题,就是查询语句返回多条数据怎么办呢?)
JSONArray array = new JSONArray();
while (rs.next()) {
JSONObject jsonObject = new JSONObject();
for (int i = 1; i <= columnCount; i++) {
String columnName = md.getColumnLabel(i);
String value = rs.getString(columnName);
jsonObject.put(columnName, value);
}
array.add(jsonObject);
}
最后再将 JSONArray 转成 String。那为什么我们要将返回值处理成 String 呢?前面说提取 sql 结果配置的时候有讲到,我们所有的提取都是以 json path 提取来实现的,所以此时直接再将字符串转成 json 就可以提取对应的值了。再说如果配置多条 sql,后面的 sql 语句使用前面的提取结果,那么则需要进行参数替换。我们再将提取的值放入一个 map 中,该参数 map 的作用域仅限于当前用例。(看官们觉得是只作用于当前用例好,还是作用于测试计划全局好,想听听大家的意见!)
if (extractJSON.keySet().size() > 0) {
for (String key : extractJSON.keySet()) {
// 获取表达式的数组下标
String jsonPathExpression = extractJSON.getString(key);
int start = jsonPathExpression.indexOf("[");
int end = jsonPathExpression.indexOf("]");
String index = jsonPathExpression.substring(start + 1, end);
JSONObject jsonObject = sqlResultJA.getJSONObject(Integer.valueOf(index));
jsonPathExpression = jsonPathExpression.replace("[" + index + "]", "");
String extractValue;
try {
extractValue = JsonUtils.jsonPathStringValue(jsonObject, jsonPathExpression);
relateParam.put(key, extractValue);
}catch (Exception e){
relateParam.put(key, null);
}
}
}
另外前置操作还支持自定义的函数助手,简单来说就是根据表达式来做反射调用代码,目的还是用与替换参数或者为后续操作提供参数。我们在解析的各个步骤的时候,如果解析到存在函数助手表达式,则进行函数助手的处理:逻辑是获取函数方法,然后是获取函数参数,之后是调用反射获取结果,最后再进行替换。
函数助手格式如:${__getRandomString(10)}
public Map<String, List<String>> invoker(Map<String, Object[]> funcMap) throws ClassNotFoundException, IllegalAccessException, InstantiationException, InvocationTargetException {
Map<String, List<String>> resultMap = new HashMap<>();
Class aClass = FunctionsHelper.class;
Object instance = aClass.newInstance();
Method[] methods = getMethods(aClass);
for (String func : funcMap.keySet()){
for (Method method : methods){
if (func.equals(method.getName())){
List<String> list = new ArrayList<>();
list.add(method.getGenericReturnType().toString());
Object[] params = funcMap.get(func);
Object result;
result = method.invoke(instance, params);
list.add(result.toString());
resultMap.put(func, list);
}
}
}
return resultMap;
}
接下来就是调试接口步骤,说白了,就是根据入参和接口发起 http 请求(本公司当前暂时只有 http 协议的接口);我们在设计的时候也考虑到扩展(数据库预留字段),可以支持其他协议类型;对响应结果进行参数提取;发起请求之后再进行断言,包括针对请求响应进行断言、数据库断言(mysql 和 sqlserver 都支持);然后是执行下一步,最后直至测试步骤结束。
最后就是后置步骤,执行顺序及逻辑与前置步骤一致,不做赘述。
三、测试计划
测试计划就是最终串联所有用例执行的地方,可根据实际需要筛选用例组装成各种场景,满足各种用途。我们将计划划分为回归和普通两大类。因为测试计划的执行和调试用例的逻辑差不多,所以具体细节就不多说,主要和大家分享一下测试计划的执行步骤:
1.获取测试计划信息
2.获取测试计划关联的测试用例
3.根据测试用例获取所有的环境信息
4.获取所有环境的登陆信息(文章最开始就讲到了,使用了 redis 缓存了用户 cookie、token 或者其他 header 信息),就这一点多说几句,如果测试计划指定了账号,就是用指定账号的 header,否则使用环境第一个账号的 header 信息(这就引入一个问题,如果想在测试计划内,针对同一环境使用多账号操作该怎么办?)
5.获取全局变量
6.组装可执行的用例信息
7.依次执行测试用例
8.写入测试报告
虽然简单的 8 点就总结了测试计划的执行,但实际开发过程中,这一块是问题最多、逻辑最复杂的;在真实使用中,每个测试同学习惯不一致,系统出现了各种异常;然后就是反复修改、迭代,个中滋味,那简直是 yyds。
以上,希望喜欢的朋友收藏、关注、点赞、评论探讨。
下一期预告:swagger 与天眼平台结合解决接口文档维护痛点