通用技术 Graylog——日志聚合工具中的后起之秀
日志管理工具总览
先看看 推荐!国外程序员整理的系统管理员资源大全 中,国外程序员整理的日志聚合工具的列表:
日志管理工具:收集,解析,可视化
- Elasticsearch - 一个基于 Lucene 的文档存储,主要用于日志索引、存储和分析。
- Fluentd - 日志收集和发出
- Flume -分布式日志收集和聚合系统
- Graylog2 -具有报警选项的可插入日志和事件分析服务器
- Heka -流处理系统,可用于日志聚合
- Kibana - 可视化日志和时间戳数据
- Logstash -管理事件和日志的工具
- Octopussy -日志管理解决方案(可视化/报警/报告)
Graylog 与 ELK 方案的对比
- ELK: Logstash -> Elasticsearch -> Kibana
- Graylog: Graylog Collector -> Graylog Server(封装 Elasticsearch) -> Graylog Web
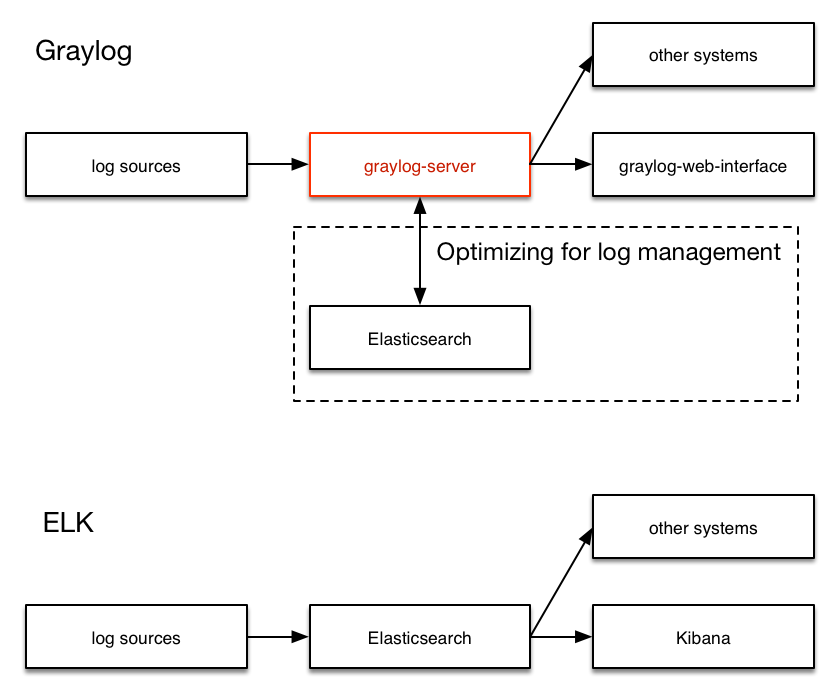
之前试过 Flunted + Elasticsearch + Kibana 的方案,发现有几个缺点:
- 不能处理多行日志,比如 Mysql 慢查询,Tomcat/Jetty 应用的 Java 异常打印
- 不能保留原始日志,只能把原始日志分字段保存,这样搜索日志结果是一堆 Json 格式文本,无法阅读。
- 不符合正则表达式匹配的日志行,被全部丢弃。
本着解决以上 3 个缺点的原则,再次寻找替代方案。
首先找到了商业日志工具 Splunk,号称日志界的 Google,意思是全文搜索日志的能力,不光能解决以上 3 个缺点,还提供搜索单词高亮显示,不同错误级别日志标色等吸引人的特性,但是免费版有 500M 限制,付费版据说要 3 万美刀,只能放弃,继续寻找。
最后找到了 Graylog,第一眼看到 Graylog,只是系统日志 syslog 的采集工具,一点也没吸引到我。但后来深入了解后,才发现 Graylog 简直就是开源版的 Splunk。
我自己总结的 Graylog 吸引人的地方:
- 一体化方案,安装方便,不像 ELK 有 3 个独立系统间的集成问题。
- 采集原始日志,并可以事后再添加字段,比如 http_status_code,response_time 等等。
- 自己开发采集日志的脚本,并用 curl/nc 发送到 Graylog Server,发送格式是自定义的 GELF,Flunted 和 Logstash 都有相应的输出 GELF 消息的插件。自己开发带来很大的自由度。实际上只需要用 inotifywait 监控日志的 modify 事件,并把日志的新增行用 curl/netcat 发送到 Graylog Server 就可。
- 搜索结果高亮显示,就像 google 一样。
- 搜索语法简单,比如:
source:mongo AND reponse_time_ms:>5000,避免直接输入 elasticsearch 搜索 json 语法 - 搜索条件可以导出为 elasticsearch 的搜索 json 文本,方便直接开发调用 elasticsearch rest api 的搜索脚本。
Graylog 图解
Graylog 开源版官网: https://www.graylog.org/
来几张官网的截图:
1.架构图

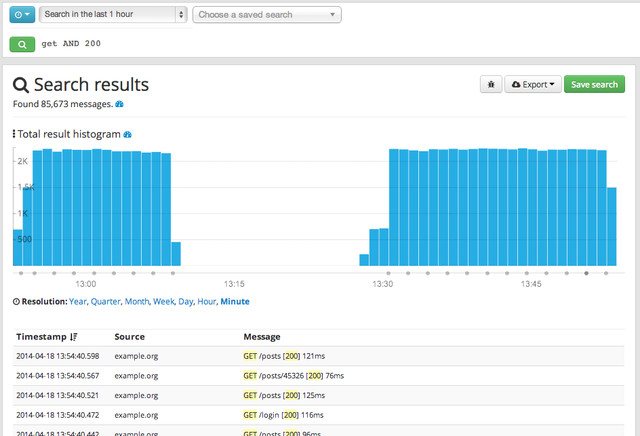
2.屏幕截图
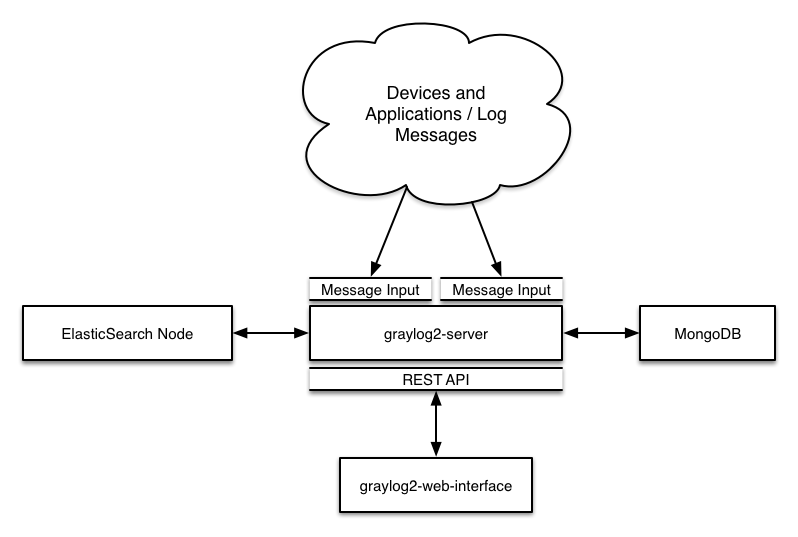
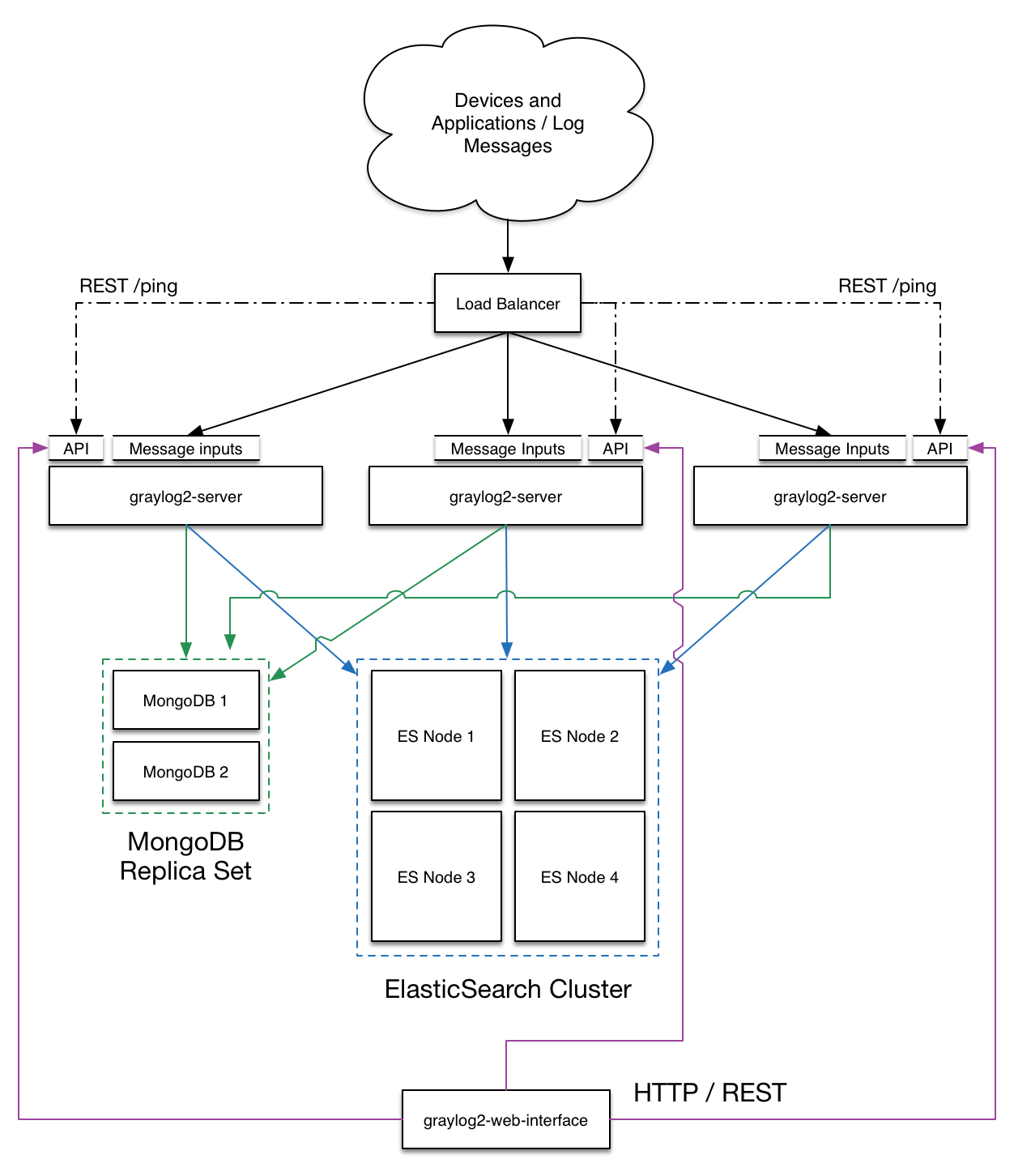
3.部署图
最小安装:
生产环境安装:
Graylog 服务器安装
包括四块内容:
- mongodb
- elasticsearch
- graylog-server
- graylog-web
以下环境是 CentOS 6.6,服务器 ip 是 10.0.0.11,已安装 jre-1.7.0-openjdk
1. mongodb
http://docs.mongodb.org/manual/tutorial/install-mongodb-on-red-hat
[root@logserver yum.repos.d]# vim /etc/yum.repos.d/mongodb-org-3.0.repo
---
[mongodb-org-3.0]
name=MongoDB Repository
baseurl=http://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.0/x86_64/
gpgcheck=0
enabled=1
---
[root@logserver yum.repos.d]# yum install -y mongodb-org
[root@logserver yum.repos.d]# vi /etc/yum.conf
最后一行添加:
---
exclude=mongodb-org,mongodb-org-server,mongodb-org-shell,mongodb-org-mongos,mongodb-org-tools
---
[root@logserver yum.repos.d]# service mongod start
[root@logserver yum.repos.d]# chkconfig mongod on
[root@logserver yum.repos.d]# vi /etc/security/limits.conf
最后一行添加:
---
* soft nproc 65536
* hard nproc 65536
mongod soft nproc 65536
* soft nofile 131072
* hard nofile 131072
---
[root@logserver ~]# vi /etc/init.d/mongod
ulimit -f unlimited 行前插入:
---
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
---
[root@logserver ~]# /etc/init.d/mongod restart
2. elasticsearch
Elasticsearch 的最新版是 1.6.0
https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-repositories.html
[root@logserver ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
[root@logserver ~]# vi /etc/yum.repos.d/elasticsearch.repo
---
[elasticsearch-1.5]
name=Elasticsearch repository for 1.5.x packages
baseurl=http://packages.elastic.co/elasticsearch/1.5/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
---
[root@logserver ~]# yum install elasticsearch
[root@logserver ~]# chkconfig --add elasticsearch
[root@logserver ~]# vi /etc/elasticsearch/elasticsearch.yml
32 cluster.name: graylog
[root@logserver ~]# /etc/init.d/elasticsearch start
[root@logserver ~]# curl localhost:9200
3. graylog
Graylog 的最新版是 1.1.4 ,下载链接如下:
https://packages.graylog2.org/repo/el/6Server/1.1/x86_64/graylog-server-1.1.4-1.noarch.rpm
https://packages.graylog2.org/repo/el/6Server/1.1/x86_64/graylog-web-1.1.4-1.noarch.rpm
[root@logserver ~]# wget https://packages.graylog2.org/repo/el/6Server/1.0/x86_64/graylog-server-1.0.2-1.noarch.rpm
[root@logserver ~]# wget https://packages.graylog2.org/repo/el/6Server/1.0/x86_64/graylog-web-1.0.2-1.noarch.rpm
[root@logserver ~]# rpm -ivh graylog-server-1.0.2-1.noarch.rpm
[root@logserver ~]# rpm -ivh graylog-web-1.0.2-1.noarch.rpm
[root@logserver ~]# /etc/init.d/graylog-server start
Starting graylog-server: [确定]
启动失败!
[root@logserver ~]# cat /var/log/graylog-server/server.log
2015-05-22T15:53:14.962+08:00 INFO [CmdLineTool] Loaded plugins: []
2015-05-22T15:53:15.032+08:00 ERROR [Server] No password secret set. Please define password_secret in your graylog2.conf.
2015-05-22T15:53:15.033+08:00 ERROR [CmdLineTool] Validating configuration file failed - exiting.
[root@logserver ~]# yum install pwgen
[root@logserver ~]# pwgen -N 1 -s 96
zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
[root@logserver ~]# echo -n 123456 | sha256sum
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx -
[root@logserver ~]# vi /etc/graylog/server/server.conf
11 password_secret = zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
...
22 root_password_sha2 = xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
...
152 elasticsearch_cluster_name = graylog
[root@logserver ~]# /etc/init.d/graylog-server restart
启动成功!
[root@logserver ~]# /etc/init.d/graylog-web start
Starting graylog-web: [确定]
启动失败!
[root@logserver ~]# cat /var/log/graylog-web/application.log
2015-05-22T15:53:22.960+08:00 - [ERROR] - from lib.Global in main
Please configure application.secret in your conf/graylog-web-interface.conf
2015-05-22T16:25:55.343+08:00 - [ERROR] - from lib.Global in main
Please configure application.secret in your conf/graylog-web-interface.conf
[root@logserver ~]# pwgen -N 1 -s 96
yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy
[root@logserver ~]# vi /etc/graylog/web/web.conf
---
2 graylog2-server.uris="http://127.0.0.1:12900/"
12 application.secret="yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy"
---
注意:/etc/graylog/web/web.conf中的graylog2-server.uris值必须与/etc/graylog/server/server.conf中的rest_listen_uri一致
---
36 rest_listen_uri = http://127.0.0.1:12900/
---
[root@logserver ~]# /etc/init.d/graylog-web start
浏览器中输入 url: http://10.0.0.11:9000/ 可以进入 graylog 登录页,
管理员帐号/密码: admin/123456
4. 添加日志收集器
以 admin 登录http://10.0.0.11:9000/
4.1 进入 System > Inputs > Inputs in Cluster > Raw/Plaintext TCP | Launch new input
取名"tcp 5555" 完成创建
任何安装 nc 的 Linux 机器上执行:
echo `date` | nc 10.0.0.11 5555
浏览器的http://10.0.0.11:9000/登录后首页 ,点击第三行绿色搜索按钮,看到一条新消息:
Timestamp Source Message
2015-05-22 08:49:15.280 10.0.0.157 2015年 05月 22日 星期五 16:48:28 CST
说明安装已成功!!
4.2 进入 System > Inputs > Inputs in Cluster > GELF HTTP | Launch new input
取名"http 12201" 完成创建
任何安装 curl 的 Linux 机器上执行:
curl -XPOST http://10.0.0.11:12201/gelf -p0 -d '{"short_message":"Hello there", "host":"example.org", "facility":"test", "_foo":"bar"}'
浏览器的http://10.0.0.11:9000/登录后首页 ,点击第三行绿色搜索按钮,看到一条新消息:
Timestamp Source Message
2015-05-22 08:49:15.280 10.0.0.157 Hello there
说明 GELF HTTP Input 设置成功!!
5. 时区和高亮设置
admin 帐号的时区:
[root@logserver ~]# vi /etc/graylog/server/server.conf
---
30 root_timezone = Asia/Shanghai
---
[root@logserver ~]# /etc/init.d/graylog-server restart
其他帐号的默认时区:
[root@logserver ~]# vi /etc/graylog/web/web.conf
---
18 timezone="Asia/Shanghai"
---
[root@logserver ~]# /etc/init.d/graylog-web restart
允许查询结果高亮:
[root@logserver ~]# vi /etc/graylog/server/server.conf
---
147 allow_highlighting = true
---
[root@logserver ~]# /etc/init.d/graylog-server restart
发送日志到 Graylog 服务器
使用 http 协议发送:
http://docs.graylog.org/en/1.1/pages/sending_data.html#gelf-via-http
curl -XPOST http://graylog.example.org:12202/gelf -p0 -d '{"short_message":"Hello there", "host":"example.org", "facility":"test", "_foo":"bar"}'
使用 tcp 协议发送
http://docs.graylog.org/en/1.1/pages/sending_data.html#raw-plaintext-inputs
echo "hello, graylog" | nc graylog.example.org 5555
结合 inotifywait 收集 nginx 日志
gather-nginx-log.sh
#!/bin/bash
app=nginx
node=$HOSTNAME
log_file=/var/log/nginx/nginx.log
graylog_server_ip=10.0.0.11
graylog_server_port=12201
while inotifywait -e modify $log_file; do
last_size=`cat ${app}.size`
curr_size=`stat -c%s $log_file`
echo $curr_size > ${app}.size
count=`echo "$curr_size-$last_size" | bc`
python read_log.py $log_file ${last_size} $count | sed 's/"/\\\\\"/g' > ${app}.new_lines
while read line
do
if echo "$line" | grep "^20[0-9][0-9]-[0-1][0-9]-[0-3][0-9]" > /dev/null; then
seconds=`echo "$line" | cut -d ' ' -f 6`
spend_ms=`echo "${seconds}*1000/1" | bc`
http_status=`echo "$line" | cut -d ' ' -f 2`
echo "http_status -- $http_status"
prefix_number=${http_status:0:1}
if [ "$prefix_number" == "5" ]; then
level=3 #ERROR
elif [ "$prefix_number" == "4" ]; then
level=4 #WARNING
elif [ "$prefix_number" == "3" ]; then
level=5 #NOTICE
elif [ "$prefix_number" == "2" ]; then
level=6 #INFO
elif [ "$prefix_number" == "1" ]; then
level=7 #DEBUG
fi
echo "level -- $level"
curl -XPOST http://${graylog_server_ip}:${graylog_server_port}/gelf -p0 -d "{\"short_mess
sage\":\"$line\", \"host\":\"${app}\", \"level\":${level}, \"_node\":\"${node}\", \"_spend_msecs\":$
{spend_ms}, \"_http_status\":${http_status}}"
echo "gathered -- $line"
fi
done < ${app}.new_lines
done
read_log.py
#!/usr/bin/python
#coding=utf-8
import sys
import os
if len(sys.argv) < 4:
print "Usage: %s /path/of/log/file print_from count" % (sys.argv[0])
print "Example: %s /var/log/syslog 90000 100" % (sys.argv[0])
sys.exit(1)
filename = sys.argv[1]
if (not os.path.isfile(filename)):
print "%s not existing!!!" % (filename)
sys.exit(1)
filesize = os.path.getsize(filename)
position = int(sys.argv[2])
if (filesize < position):
print "log file may cut by logrotate.d, print log from begin!" % (position,filesize)
position = 0
count = int(sys.argv[3])
fo = open(filename, "r")
fo.seek(position, 0)
content = fo.read(count)
print content.strip()
# Close opened file
fo.close()
5 秒一次收集 iotop 日志,找出高速读写磁盘的进程
#!/bin/bash
app=iotop
node=$HOSTNAME
graylog_server_ip=10.0.0.11
graylog_server_port=12201
while true; do
sudo /usr/sbin/iotop -b -o -t -k -q -n2 | sed 's/"/\\\\\"/g' > /dev/shm/graylog_client.${app}.new_lines
while read line; do
if echo "$line" | grep "^[0-2][0-9]:[0-5][0-9]:[0-5][0-9]" > /dev/null; then
read -a WORDS <<< $line
epoch_seconds=`date --date="${WORDS[0]}" +%s.%N`
pid=${WORDS[1]}
read_float_kps=${WORDS[4]}
read_int_kps=${read_float_kps%.*}
write_float_kps=${WORDS[6]}
write_int_kps=${write_float_kps%.*}
command=${WORDS[12]}
if [ "$command" == "bash" ] && (( ${#WORDS[*]} > 13 )); then
pname=${WORDS[13]}
elif [ "$command" == "java" ] && (( ${#WORDS[*]} > 13 )); then
arg0=${WORDS[13]}
pname=${arg0#*=}
else
pname=$command
fi
curl --connect-timeout 1 -s -XPOST http://${graylog_server_ip}:${graylog_server_port}/gelf -p0 -d "{\"timestamp\":$epoch_seconds, \"short_message\":\"${line::200}\", \"full_message\":\"$line\", \"host\":\"${app}\", \"_node\":\"${node}\", \"_pid\":${pid}, \"_read_kps\":${read_int_kps}, \"_write_kps\":${write_int_kps}, \"_pname\":\"${pname}\"}"
fi
done < /dev/shm/graylog_client.${app}.new_lines
sleep 4
done
收集 android app 日志
device.env
export device=4b13c85c
export app=com.tencent.mm
export filter="\( I/ServerAsyncTask2(\| W/\| E/\)"
export graylog_server_ip=10.0.0.11
export graylog_server_port=12201
adblog.sh
#!/bin/bash
. ./device.env
adb -s $device logcat -v time *:I | tee -a adb.log
gather-androidapp-log.sh
#!/bin/bash
. ./device.env
log_file=./adb.log
node=$device
if [ ! -f $log_file ]; then
echo $log_file not exist!!
echo 0 > ${app}.size
exit 1
fi
if [ ! -f ${app}.size ]; then
curr_size=`stat -c%s $log_file`
echo $curr_size > ${app}.size
fi
while inotifywait -qe modify $log_file > /dev/null; do
last_size=`cat ${app}.size`
curr_size=`stat -c%s $log_file`
echo $curr_size > ${app}.size
pids=`./getpids.py $app $device`
if [ "$pids" == "" ]; then
continue
fi
count=`echo "$curr_size-$last_size" | bc`
python read_log.py $log_file ${last_size} $count | grep "$pids" | sed 's/"/\\\\\"/g' | sed 's/\t/ /g' > ${app}.new_lines
#echo "${app}.new_lines lines: `wc -l ${app}.new_lines`"
while read line
do
if echo "$line" | grep "$filter" > /dev/null; then
priority=${line:19:1}
if [ "$priority" == "F" ]; then
level=1 #ALERT
elif [ "$priority" == "E" ]; then
level=3 #ERROR
elif [ "$priority" == "W" ]; then
level=4 #WARNING
elif [ "$priority" == "I" ]; then
level=6 #INFO
fi
#echo "level -- $level"
curl -XPOST http://${graylog_server_ip}:${graylog_server_port}/gelf -p0 -d "{\"short_message\":\"$line\", \"host\":\"${app}\", \"level\":${level}, \"_node\":\"${node}\"}"
echo "GATHERED -- $line"
#else
#echo "ignored -- $line"
fi
done < ${app}.new_lines
done
get_pids.py
#!/usr/bin/python
import sys
import os
import commands
if __name__ == "__main__":
if len(sys.argv) != 3:
print sys.argv[0]+" packageName device"
sys.exit()
device = sys.argv[2]
cmd = "adb -s "+device+" shell ps | grep "+sys.argv[1]+" | cut -c11-15"
output = commands.getoutput(cmd)
if output == "":
sys.exit()
originpids = output.split("\n")
strippids = map((lambda pid: int(pid,10)), originpids)
pids = map((lambda pid: "%5d" %pid), strippids)
pattern = "\(("+")\|(".join(pids)+")\)"
print pattern