已删除
自动化测试框架用的是 testNG,写用例管理用例用的是 MTM。嗯是的,都用了现成的,没时间自己造
目前有点迷茫,感觉辛苦写框架,还不如直接学 httprunner
我倒觉得你有这些思考,这个写框架的辛苦就很值得了,不要那么快放弃。你迷茫只是因为你还没想好自己框架的核心目标是什么,是要让没有太多编程知识的人也能用(易用性),还是让有编程知识的人用得更高效(灵活性),这块得想好。
建议可以先研究下这类问题 httprunner 怎么解决,然后再看看放到实际项目里 httprunner 是否满足,还需要扩展什么。
我们之前接口自动化框架基本就是用 testng + 各类调用库(如 http 的用 rest-assured)+ 报告生成库(extent report),主要编写是用 java 代码来编写的。相比易用性,更偏向灵活性。会要求有一定的编程基础,不过因为从整体团队角度,也希望借助这个让大家熟悉 java(至少会仿照别人的写法写)便于后面看开发代码,所以这个也没太大问题。
在平安的时候,碰到过类似框架,希望写用例的人维护 用例(excel)就行,实际是代码部分就要处理很多,并且碰到不规范的接口,你都不知道写个用例能奇葩的什么程度,整体来说,思路是对的,但要后续持续维护的东西会很多,但这就是学习进步的过程。
ps:大公司你基本很难搞这么套东西,因为出东西涉及到 kpi,都用你的,其他人的 kpi 咋办,某团的时候就这样

extract:提取响应参数,但参数类型有可能是不同的,暂时没想到处理方法 , 这个可以试试你的自定义函数处理下数据类型,我刚试了下 自己写的类似工具 中是可行的
编写比较麻烦,而且在 yaml 中,关于变量的关联暂时没有想到什么好的解决方法, 这里的话一样的在读取 yaml 文件内容之后,进行参数替换且完成后 再 yaml.load 成 json /dict 应该是能实现你说的 变量关联吧

大致的代码是这么实现的,然后就有个小问题
import re
class Global:
id = 3
pwd = 123456
# 这个字符串是读取yaml得到的
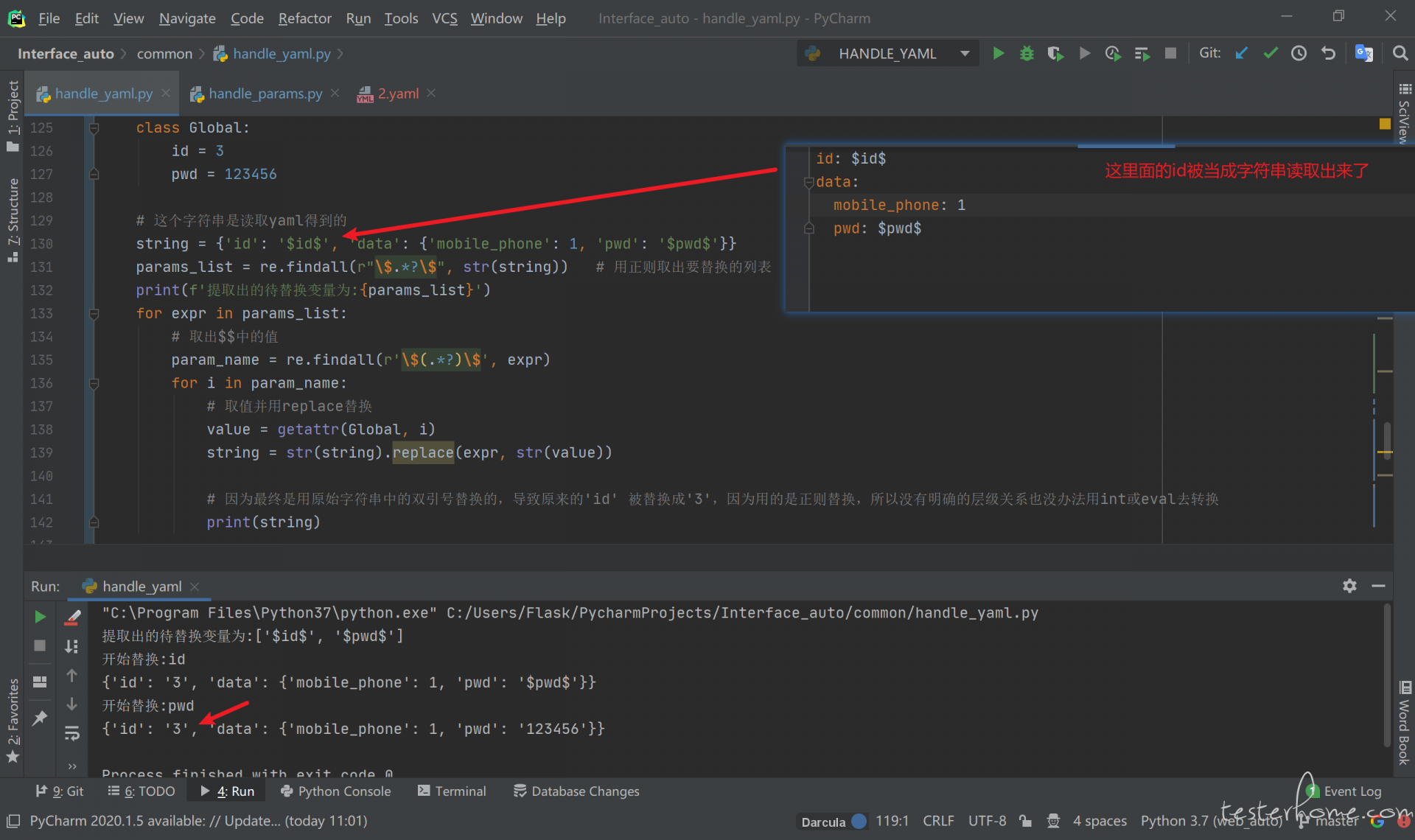
string = {'id': '$id$', 'data': {'mobile_phone': 1, 'pwd': '$pwd$'}}
params_list = re.findall(r"\$.*?\$", str(string)) # 用正则取出要替换的列表
print(f'提取出的待替换变量为:{params_list}')
for expr in params_list:
# 取出$$中的值
param_name = re.findall(r'\$(.*?)\$', expr)
for i in param_name:
# 取值并用replace替换
value = getattr(Global, i)
string = str(string).replace(expr, str(value))
# 因为最终是用原始字符串中的双引号替换的,导致原来的'id' 被替换成'3',因为用的是正则替换,所以没有明确的层级关系也没办法用int或eval去转换
print(string)
因为从 yaml 文件读取出来就是字典格式的,如果是从 excel 读取出来的话,用正则提取倒是没这个问题,我写成:{'id':$id$},读取出来会变成"{'id':$id$}",外面自动加括号;遍历字典的话,我暂时还没想到咋深层遍历
可以使用
name: 测试接口
path: /test
header:
num: 奥里给
metod: post
type: json
# 用例列表
cases:
-
name: 测试结果正常
header:
${get_header()}
data:
username: haha
password: ${password}
extra:
userId: $.code
assert:
-
$.code: 200
# 已有的参数池
from ruamel import yaml
from string import Template
pool = {
"password": 123456
}
with open('api.yaml', 'r', encoding='utf-8') as f:
# 替换响应字典
f = Template(f.read()).safe_substitute(pool)
# print(f)
data = yaml.load(f, Loader=yaml.SafeLoader)

这样也有个 bug 就是字符串类型的 123456 会被直接转成数字,另外字典迭代我发的帖子中有写过不过比较乱而且在字典嵌套列表再嵌套列表的时候无法替换
也许会有 bug,见谅 递归换值
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
@Project: py-gql-fast-test-api
@File: handle.py
@Author: zy7y
@Time: 2021/3/31 16:48
@Blog: https://www.cnblogs.com/zy7y
@Github: https://gitee.com/zy7y
@Desc: 处理方法
"""
class Handle:
var_pool = {}
@staticmethod
def set_var(key: object, value: object):
"""存变量"""
Handle.var_pool[key] = value
@staticmethod
def get_var(key: object, default: object = None):
"""取变量"""
return Handle.var_pool.get(key, object)
@staticmethod
def handle_var_list(value: list):
"""
处理参数替换~ 类型是list的逻辑
"""
for index, liv in enumerate(value):
if isinstance(liv, str) and liv[:2] == '${' and liv[-1] == '}':
# 获得key部分内容
liv = liv[2:-1]
# 取到key对应的value,复制给当前下标
value[index] = Handle.get_var(liv)
elif isinstance(liv, list):
# 如果 子元素还是 list 就再迭代list
Handle.handle_var_list(liv)
elif isinstance(liv, dict):
# 如果子元素是 dict 就再迭代字典
Handle.handle_var(liv)
@staticmethod
def handle_var(var: dict) -> dict:
"""处理自定义参数类型"""
for key, value in var.items():
# 如果是字典就 迭代字典
if isinstance(value, dict):
Handle.handle_var(value)
# 如果是list 就迭代list, 递归 list处理方法
elif isinstance(value, list):
Handle.handle_var_list(value)
# 如果是str 就替换
elif isinstance(value, str) and value[:2] == '${' and value[-1] == '}':
# 获得key部分内容
value = value[2:-1]
# 取到key对应的value
var[key] = Handle.get_var(value)
return var
if __name__ == '__main__':
Handle.var_pool = {"name": "att", "age": 18, "height": 17.8}
# 需要处理的字典
data = {
# 字典 提取
"name": "${name}",
# 字典嵌套字典提取
"info": {"${name}": ["${age}", "${height}"]},
"lists": ["${name}", ["${age}", "${height}"], {"name": "${name}"}]
}
print(Handle.handle_var(data))
没有用 excel,测试用例就是直接写代码。只有在数据库校验的地方用了 csv 记录断言(要校验数个表共计数十个字段,写代码太累了)。这个断言也是可以自动生成的,一般很少直接编辑。
因为业务流程比较长,各个接口依赖上一个接口数据比较普遍,所以我们大部分是流程类用例。单接口各种不同参数组合的比较少。因为开发这类校验大多直接用 JSR303 注解做得,直接 review 代码 + 调试用例时人工调整下就够了,没有太多长期自动化回归的必要。
建议你趁着现在想法还热乎,抓紧时间看看 httprunner 的设计思路和试用一下吧。消化掉 httprunner 应该能给你带来不少新的想法思路。
很多框架毕竟不方便完整开放,有些设计思路不方便说得太直白,或者不一定通用。既然你已经找到了 httprunner 这个不错的学习对象,而且李隆也有在自己公众号持续分享整个过程中的设计思路和思考,先赶紧学起来吧。
我们现在就这种,以前是 unittest 那套,自己写代码脚本。后来老大让改成 excel 维护用例的方式,原意是减低接口测试门槛。现在只在团队内部用,已经有 5 个项目,800 条左右用例。时不时就会发现一些框架 bug 或者兼容性问题,需要不断优化。