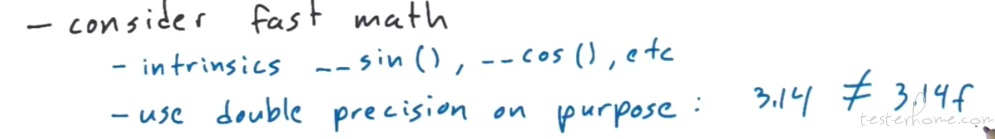专栏文章 Udacity CS344 并行计算入门(五)GPU 代码优化
总纲:

算法需要考虑使用并行算法。
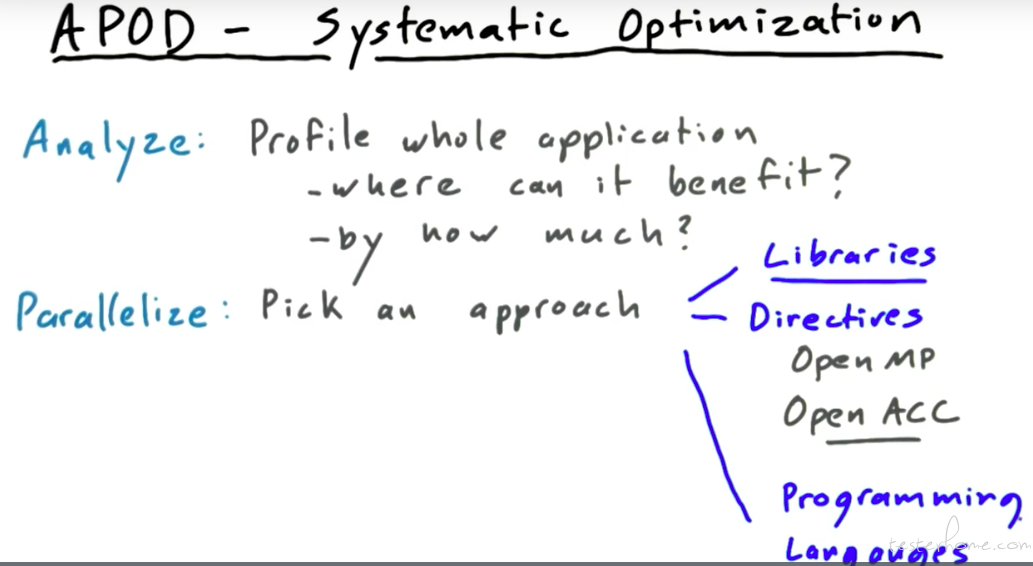
系统分析方法:

下面来具体看一下每一步需要考虑哪些问题:

weak and strong scaling
这里可以参考:
https://blog.csdn.net/csgxy123/article/details/9569201

Transpose 举例:
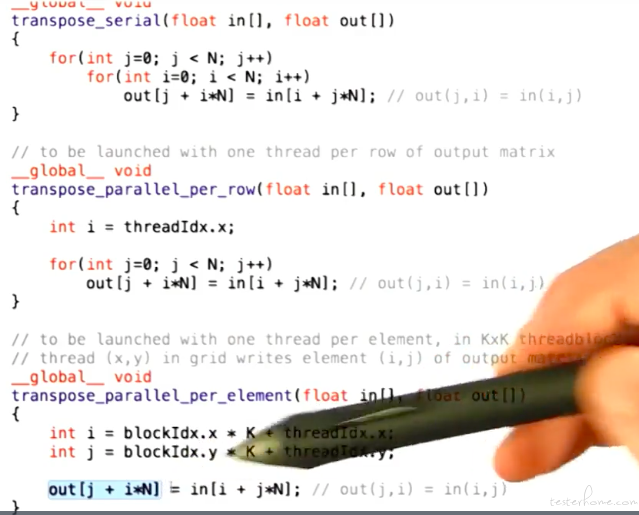
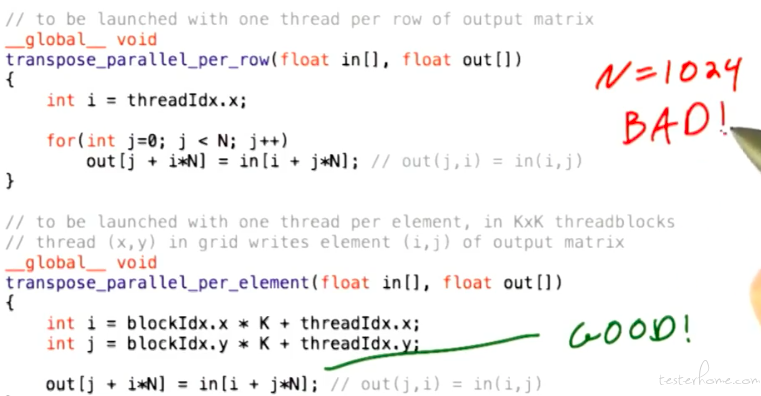
对应的 main:
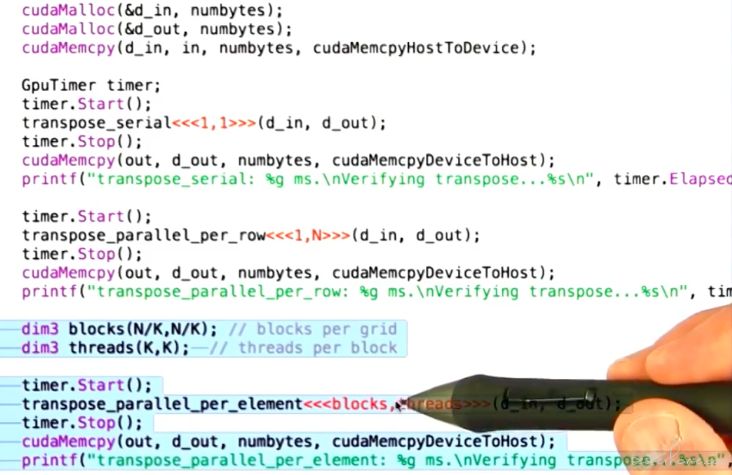
性能对比:

可以通过 deviceQuery 查看 CUDA 的参数:
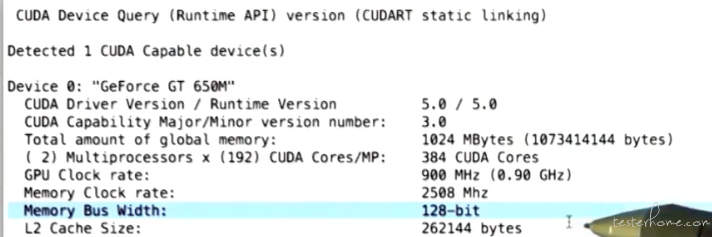
计算内存访问峰值:

接着算 k=16 时优化的结果:

Coalicing:
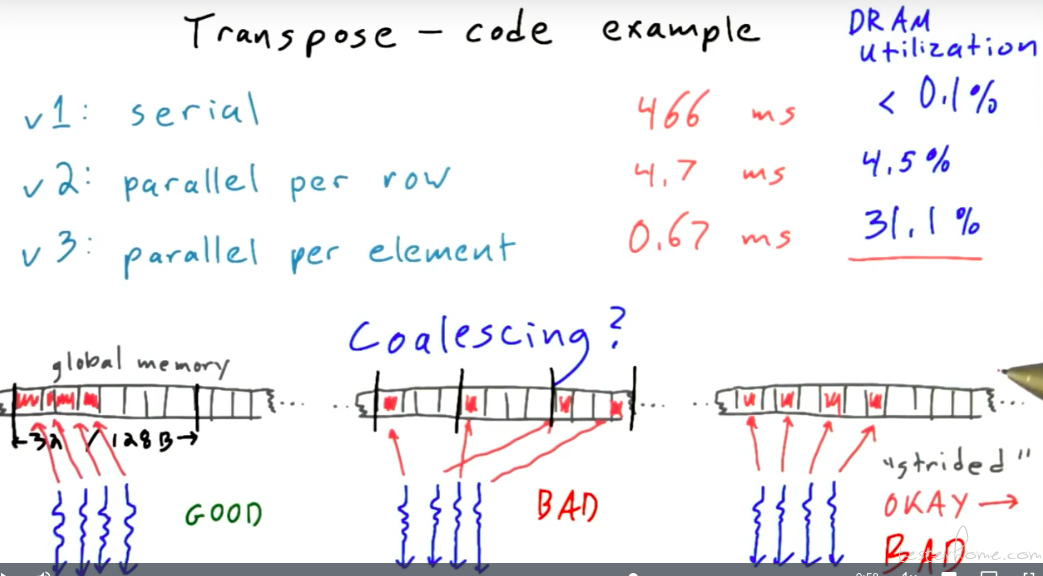

这个地方需要商榷一下,随着深度学习的发展,目前高性能计算会有访存优先和计算优先两种算子。
NVVP

可以通过 NV 提供的官方工具分析 NVCC 编译生成的可执行文件。
以上面的 TRANSPOSE 为例,可以看到写入的占用率不大。
Tilling
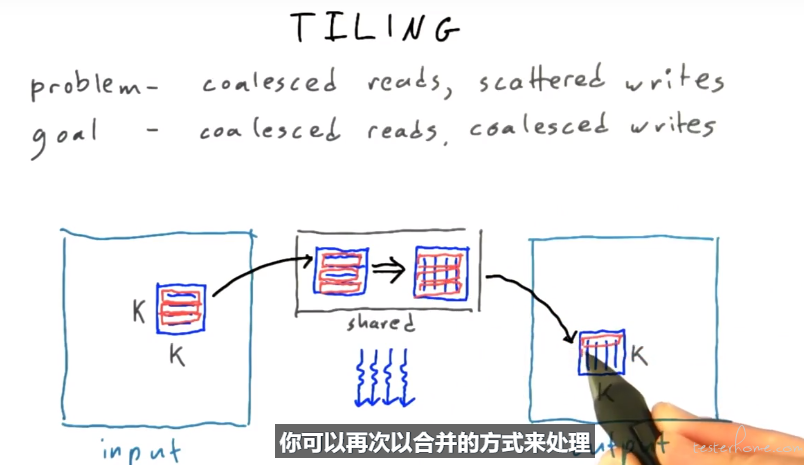
相应的代码实现:
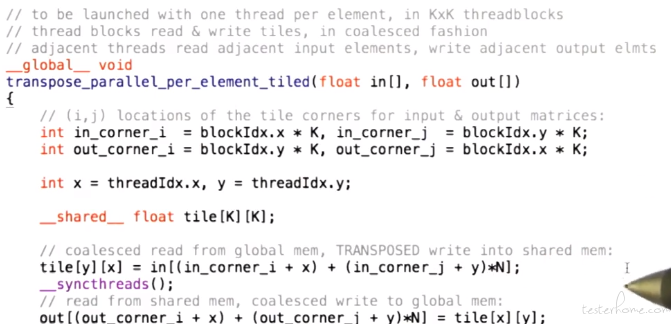
新版本性能:

这里关注:
shared memory replay overhead。瓶颈不在内存读写了,主要在 thread 上面。
这里设置 k=32,k*k=1024,thread 过多了,处理内容也比较少。因此利用率不高。
可以通过 deviceQuery 查询到 block 的限制
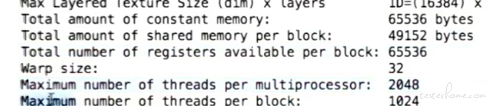
可以看一下 SM 都有哪些主要的约束条件:
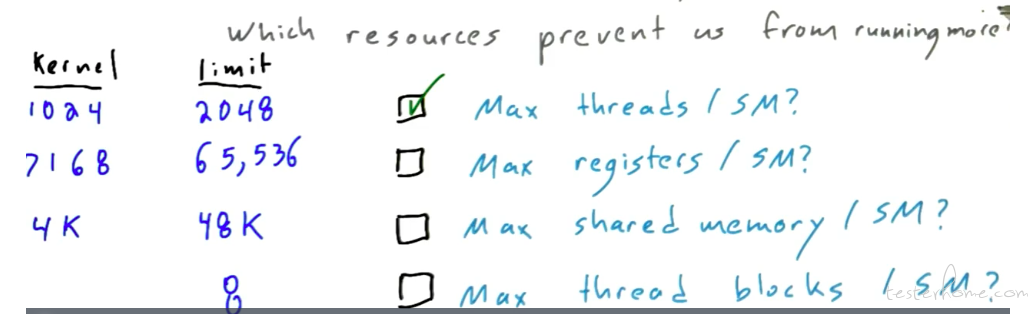
这里也是一种调参,这就是 TVM 要解决的问题么?避免手动调参。
优化方式:

性能总结:

这里提了一下 shared memory 的 bank conflicts,可以看到提升已不足 5%。
计算优化:

前面的 K 变化就是在优化 thread 栅栏的同步等待时间。
Thread divergence
这里就涉及 warp 和 SIMT 两个概念了:

来具体看 thread divergence 的定义:
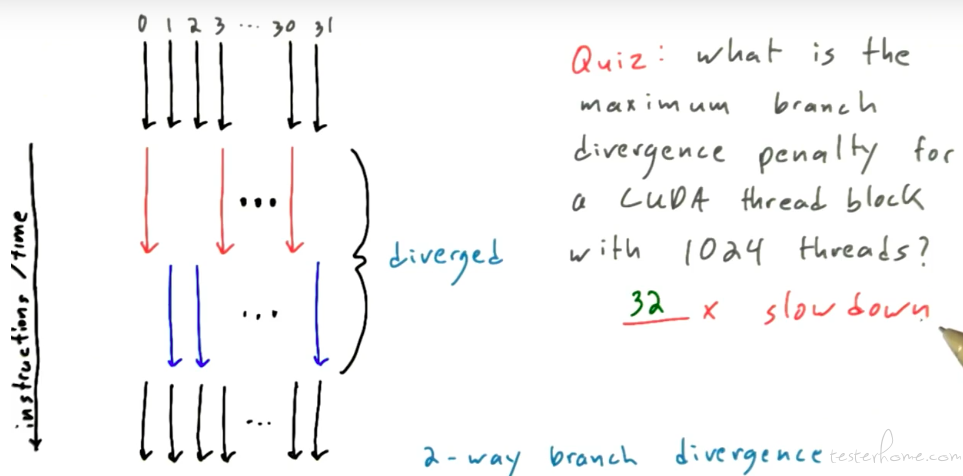
通过这里问答可以更好的理解:

为了加深印象再来一个例子:

具体避免 thread divergence 的方法:

tvm 的 stmt 层有个 pass 用来消除条件分支
数据、指令优化:

host->device 固定申请内存空间会比动态申请速度快:

申请内存是异步操作,也有命令可以等待操作完成。
stream:

请看下面这段 stream 并行的示例代码:
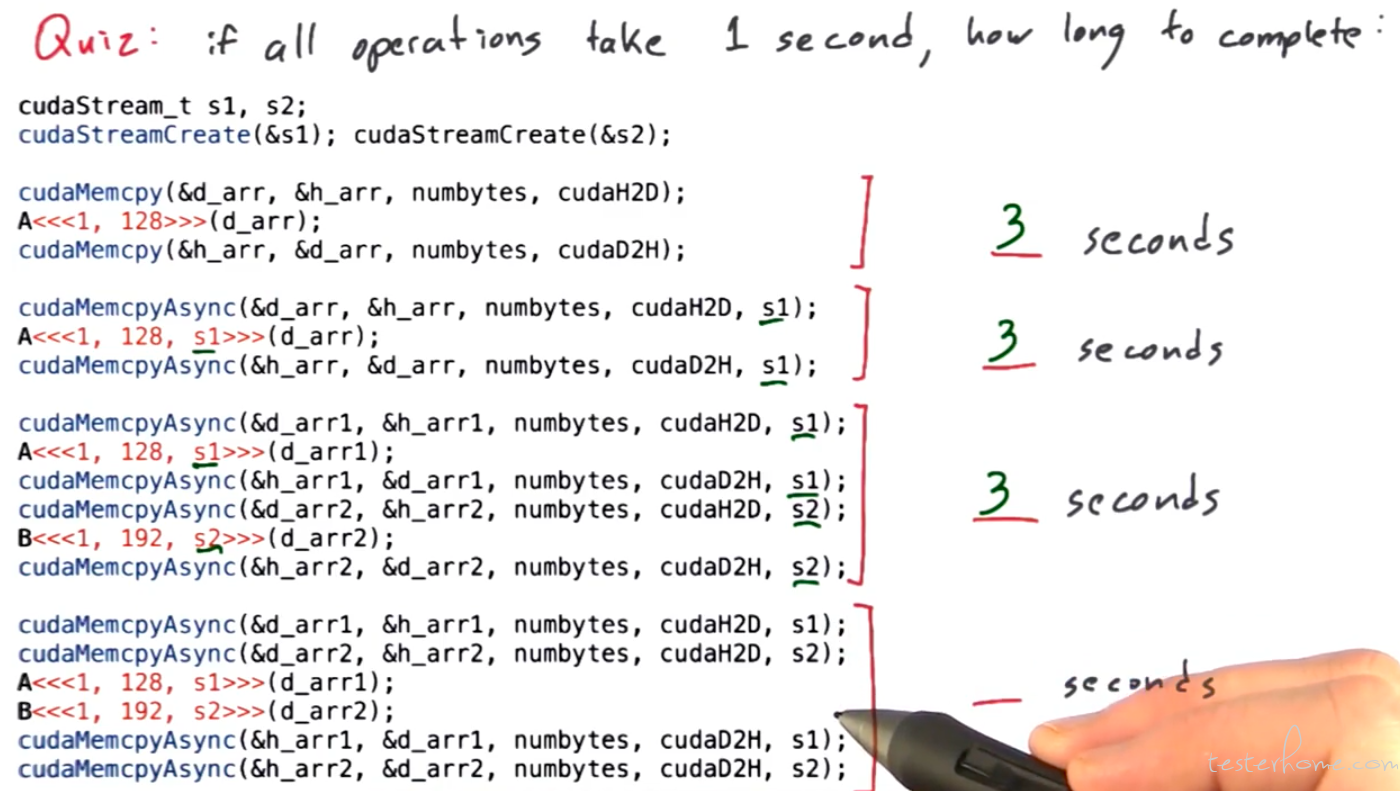
通过上述代码可以实现并行。
编写代码时,如果前后有依赖关系,需要使用同一个 stream。如下的代码会返回错误的结果:
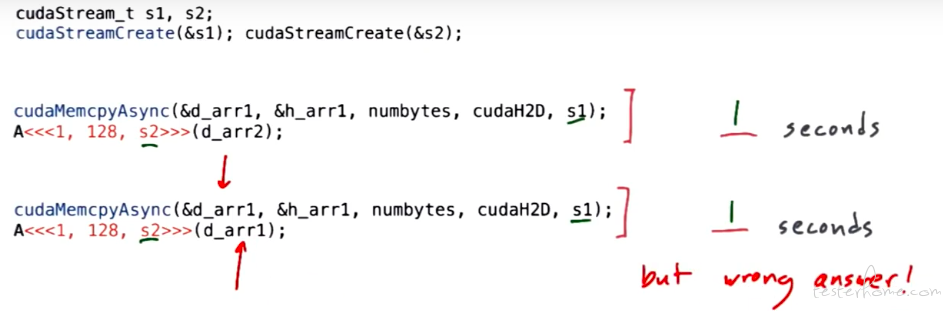
总结