前言
今天是一个特别的节日,1946 年情人节,世界上第一台计算机 ENIAC 在米国的宾夕法尼亚大学被 new 了,标志着新的时代到来。
计算机陪伴人类已经走过了 75 个年头,所以今天,没啥特别的事情,请多去陪一陪自己家的电脑,手动狗头,手动狗头。
网络编程会是一个比较庞大的知识体系,第三篇会开始讲如何 encode 和 decode。
第一篇的数据结构是提供给第三篇使用的,然后通过第二篇的通道进行传输。
第一篇地址
第二篇地址
Tcp pickle
Tcp 网络流,加工过程也可以理解成是字节流到二进制流,字节就是第一篇提到的 bytes。
encode 压包就是把字节流转换到二进制流,那么 Python 是通过怎么做到的呢。
主要分为二种,pickle(python 独有序列化字节数组),struct(从 C 那边继承来的序列化字节数组的)库。
我们看看 pickle 是如何序列化数据的。
def encode_pickle(packet:bytes):
"""
压入pickle
:param packet:
:return:
"""
return pickle.pack(">i",len(packet))+packet
注意这里并没有发包出去,回顾前面的,需要先建立 socket 链接,确认地址,才能进行发包。
pickle.pack(fmt,*args) 的第一个参数 fmt 是个很重要的知识点。
先来了解下最重要的概念之一 fmt,众所周知,Python 是不需要先声明内存宽度,才能编程的。
内存宽度是指内存里面占位的长度,在声明对象前会标注数据类型(动态语言没这个,静态语言很多有自动推断声明的 比如 golang var 和:=)
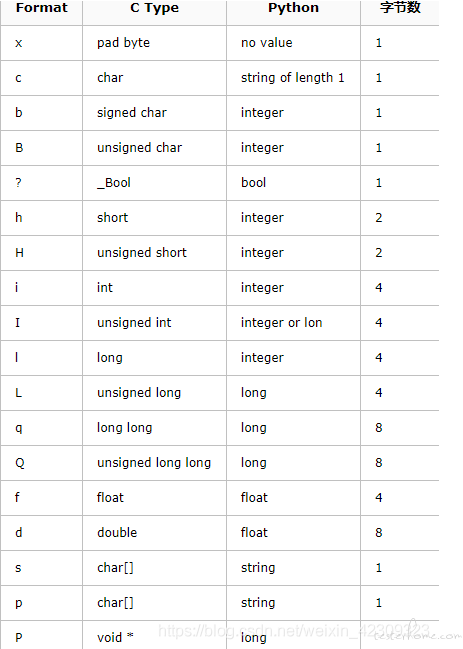
网络编程需要学习这块,是因为操作二进制,细致的话会标记为有符号和无符号。有符号和无符号做一些原子计算,做减法的时候,部分语言需要做一些特殊处理,还好 Python 不用担心这些,有符号一般是指包含负数。
short 是有符号的 2 个字节的,unsigned short 是无符号的 2 个字节,负数这个上面图需要背下来。
网络自定义字节和字节序
上面代码里面是 int 和 unsigned int,fmt 前面是主机字节序,">i"代表大端有符号的 4 个字节,"<"代表小端,"!"代表不用匹配。
暂时不考虑具体学字节序转换的问题,目前网络编程是模拟客户端往服务器发。
字节序分别有大端(big endian)和小端(little endian),程序的内容都是以字节为单位的,一个字节 8 位,每个地址对应一个字节。
大端模式就是将数据的高位放在低位地址,低位地址就是左侧。转 16 进制只是给人读的,int 类型 4 个字节,ff 6c 5a 4s。
小端就是大端反过来,是 4s 5a 6c ff。从这里可以发现大小端只是对内存寻址的顺序有关,但是内存地址里面的 6c,5a 是不会变成 c6 和 a5 的
这块问题,前期不熟悉的话,可以通过问需求来确认如何写。
数据类型后面数字除以 8 就是字节数,数字是 bit。
拿 JS 举个例子:buffer 做视图处理的,比如 Uint32Array,U 代表无符号,。int32 是 4 个字节,Array 可以理解为数组。
字节数组就是多个字节,Python 数据结构就是 bytes 或者 bytearray(这个和前者差别是内存不可变)
Uint64Array 那就是 8 个字节?这个是不合法的。这里有个定长和变长的概念,int 属于定长,int 是不能超过宽度 4 个字节的,所以不会有 Uint64Array,但是可以有 Uint16Array,16/8=2,在内存里面占位 2 个字节。
定长在具体实例内阐述,不定长是比较核心的部分,看下下面 2 个问题:
问题 1:引用类型,比如指针指向一个对象,如果操作这个对象,这个对象宽度是不会改变的。
问题 2:long 类型,网络编程也是为了模拟客户端向服务器进行发包,long 类型也是不定长的,比如不是 8 的倍数,是 9 个字节。
看 9 个字节是怎么写的。
def encode_pack(packet:str or bytes,size:int,endian:str="big"):
"""
压包
:param packet:
:param size:定长
:param endian:
:return:
"""
return int(packet).to_bytes(length=size, byteorder=endian)
print(encode_pack("1256478912".encode("utf-8"),9))
当然这个模式并不是推荐的,更合适用 fmt 里面去拼接,比如大端 9 个字节- -,直接用>9s 就行了。
struct 和 pickle 本质是一样的,本质一样就好比 Json 和 bjson 和其他 json 一样,方法都是一样的。现在可以把前面的给串起来。
def encode_9_buffer(packet: bytes):
"""
压入9个字节的缓存区
:param packet:
:return:
"""
return struct.pack(">9s", len(packet).to_bytes(length=9, byteorder="big")) + packet
pg = "hello world".encode()
print(struct.calcsize(">9s")) #长度9
print(encode_9_buffer(pg)) #b'\x00\x00\x00\x00\x00\x00\x00\x00\x0bhello world'
pickle 和 struct 混合
前面 9s 是一整个包的例子,这里预告下,后面不定长,也是游戏产业最常用的,第 4 篇会提到。当前章节其实可以满足互联网的一些 TCP 前置的网络编程了。
使用 pickle 压入缓存区 4 个字节大端 hello world,然后使用 struct 去解包还原,来验证正反序列化可兼容。
所以 python 写的后端如果是用 pickle 的,用 struct 也是可以的。
def encode_pickle(packet: bytes):
"""
压入pickle
:param packet:
:return:
"""
return pickle.pack(">i", len(packet)) + packet
def decode_unpack(packet: bytes):
"""
unpack包 这里不包含struct.unpack
:param packet:
:return:
"""
# 因为包头是4个字节,合法性验证是先切出4个字节。
if len(packet) >= 4:
return packet[4:].decode()
if __name__ == '__main__':
pg = "hello world".encode()
packet = encode_pickle(pg)
print(decode_unpack(packet))
回顾之前说的知识点。一个数据包由包头和包体组成,包头是 4 个字节(里面存放着包体长度)。
简单判断合法性就是先看是否包完整,包完整由 2 个部分组成,第一个部分是 4 个字节,那么就是先判断大于等于 4 个字节,然后解包先去掉头部 4 个字节,那里面的就是包体内容。
包体内容还原就是 decode(),下面看看如何取出包头里面的包体长度
struct.unpack(">i",packet[:4])
其他内容可以看第四篇文章。
