UWA 每周推送的知识型栏目《厚积薄发 | 技术分享》已经伴随大家走过了 252 个工作周。精选了 2020 年十大精彩问答分享给大家,期待 2021 年 UWA 问答继续有您的陪伴。
UWA 问答社区:answer.uwa4d.com
UWA QQ 群 2:793972859(原群已满员)
Q1:IL2CPP 的内存问题
最近看问答上面有个关于 IL2CPP 和 Mono 的对比,看到 IL2CPP 内存冲高会下降。关于这个,我问了 Unity 的官方技术,回答是:你好,Unity 有自己的 GC 机制,为了避免频繁向操作系统申请/释放内存,Reserved Mono 值会保持在一定区间内,达到某些条件或在某些特殊情况才会触发 GC。 有人说是:“内存池管理逻辑都是一样的,属于上层管理一样。它们只是中间语言不一样而已,也是只涨不降。” 也有其他大佬说是 IL2CPP 冲高会下降。现在很困惑,求解答。
A:看下来题主说的内存冲高不降,涉及两个指标,一个是 Profiler 里的 Reserved Mono,一个是设备内存(PSS)。目前确实没有权威的文档说明这一点,所以下面通过真实数据来说明一下。
先说第一个(Reserved Mono)。
1)在 Script Backend 是 Mono 的情况下,如果选择的是旧版本里的 Mono 2.x,或者新版本里的 .Net 3.5(Runtime Version),那么这个值是只升不降的。比如这个数据,Unused 已经很高了,但也不会下降:
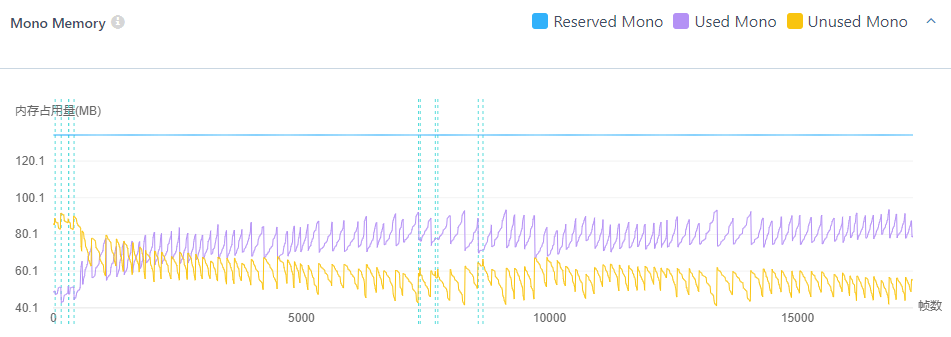
2)同样在 Script Backend 是 Mono 的情况下,如果选择的是.Net 4.x(Runtime Version),那么这个值是可以下降的(但不确定具体是从哪个版本开始的)。比如这个数据,可以看出虽然会下降,也并不是频繁执行下降操作的:

3)最后 Script Backend 是 IL2CPP 的情况下,那么这个值也是可以下降的。比如这个数据,看上去和上面的情况相差不是太大:
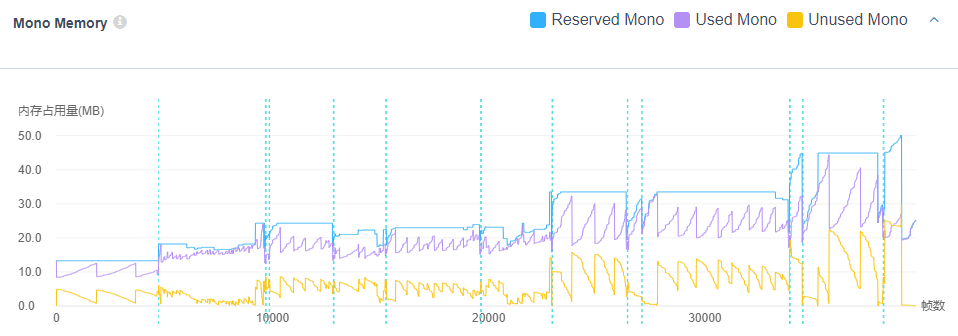
而对于第二个,设备内存。这个就和安卓系统的内存管理机制有关了,即使 Unity 把 Reserved Mono 降低了,减少了自身的内存占用,系统也不一定会立即会把这块内存释放,所以这里的行为就很难说清楚了。
该回答由 UWA 提供
Q2:加载配置内存过大问题
配置表太多占用内存过大时,除了采用 Sqlite,还有什么好的解决办法没有,有没有大佬能否指点下。FlatBuffer 不用全部进内存吗?如果不全部进内存,访问速度如何呢?
A1:第一问题参考如下:
1)可以针对重复数据进行剔除,尤其是一些字符串的配置。在配置导出时把这样的数据提取一份,其他用到的地方只是引用,会节省不少。
2)数据类型要合理。
3)可以使用类似 FlatBuffer/ZeroFormatter 的延迟加载的思路,在真正使用时再去反序列化。一次游戏过程中实际用到的配置量比较有限,使用这种策略可以尽可能的减少不必要数据的加载。第二个问题参考如下:
我们上个项目也是到后期优化时遇到类似问题,只是参考了这种思路,并没有进行完全替换。我们当时在打包时,会对配置以行为单位,进行 Offset 和 Length 的计算,在 Runtime 阶段,初始加载只会加载每行的 ID,对应的这一行的 Offset 和 Length,然后后续逻辑调用配置表接口拿数据的时候,如果发现没有反序列化过,就根据 Offset 和 Length 再去构建一下相应的数据提供给上层。访问速度的话肯定不如开始直接全部加载好,但我们测下来影响不大。
感谢范君@UWA问答社区提供了回答
A2:字符串吃内存不说了,尽量少用或者复用。表格中比较多的会是那种:攻击-1000;防御-2000;血量-3000,每个 int 都是 4 个字节,数量多了会顶不住。这种可以考虑用一个 int32/int64/uint32/uint64 去存多个数值。
感谢萧小俊@UWA问答社区提供了回答
Q3:Instruments 如何看 Mono 内存分配
例如在分配了一个 10MB 数组,对应在 Unity Profiler 中会看到开辟了至少 10MB 大小的 Mono 内存。
那么在 Instruments 中,如何查看分配的内存信息呢?Allocations 中的信息是此进程中分配的所有内存信息吗,尝试分配过 100MB 内存,Allocations 中的统计没有任何增长。


A:我这边也做了测试:
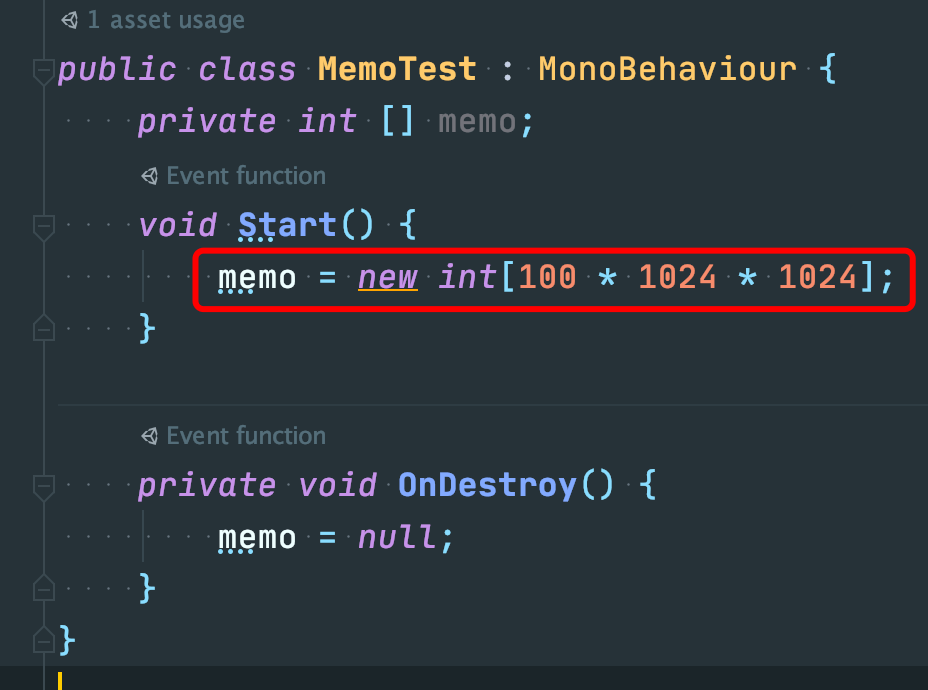
创建了 100MB 大小的 int 数组,Size 实际应该是 400MB。
然后到 Profiler 观察:
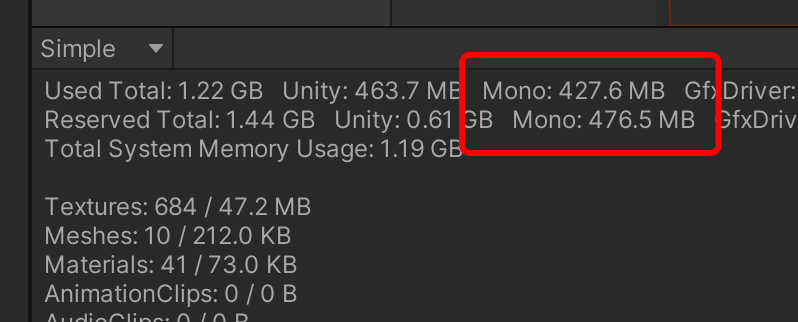

可以看到 ManagedHeap 正确分配了这 400MB 的空间。
然后打包 iOS 后到 xCode 运行,运行前首先吧 Run 这个 Scheme 的 Malloc Stack 勾上:

Run 以后点选 Memory 并导出 Memory Graph 来观察:
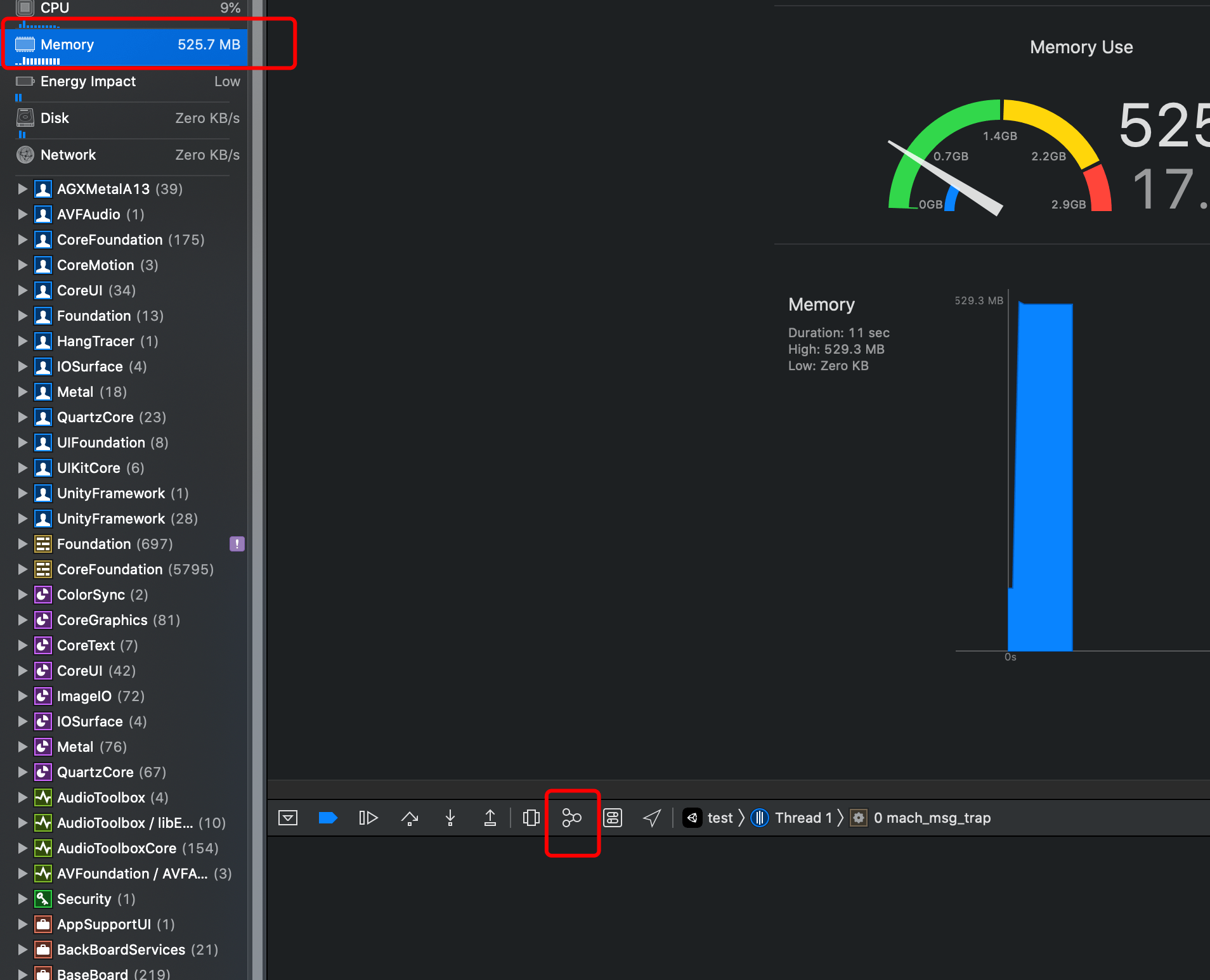
由于应用程序的内存都是在 VirtualMemory 空间分配的,因此查看 VM Regions 的 VM_ALLOCATE 部分。

于是就可已发现 128X3+16 刚好 400MB 的分配。
调用堆栈也很好确定:
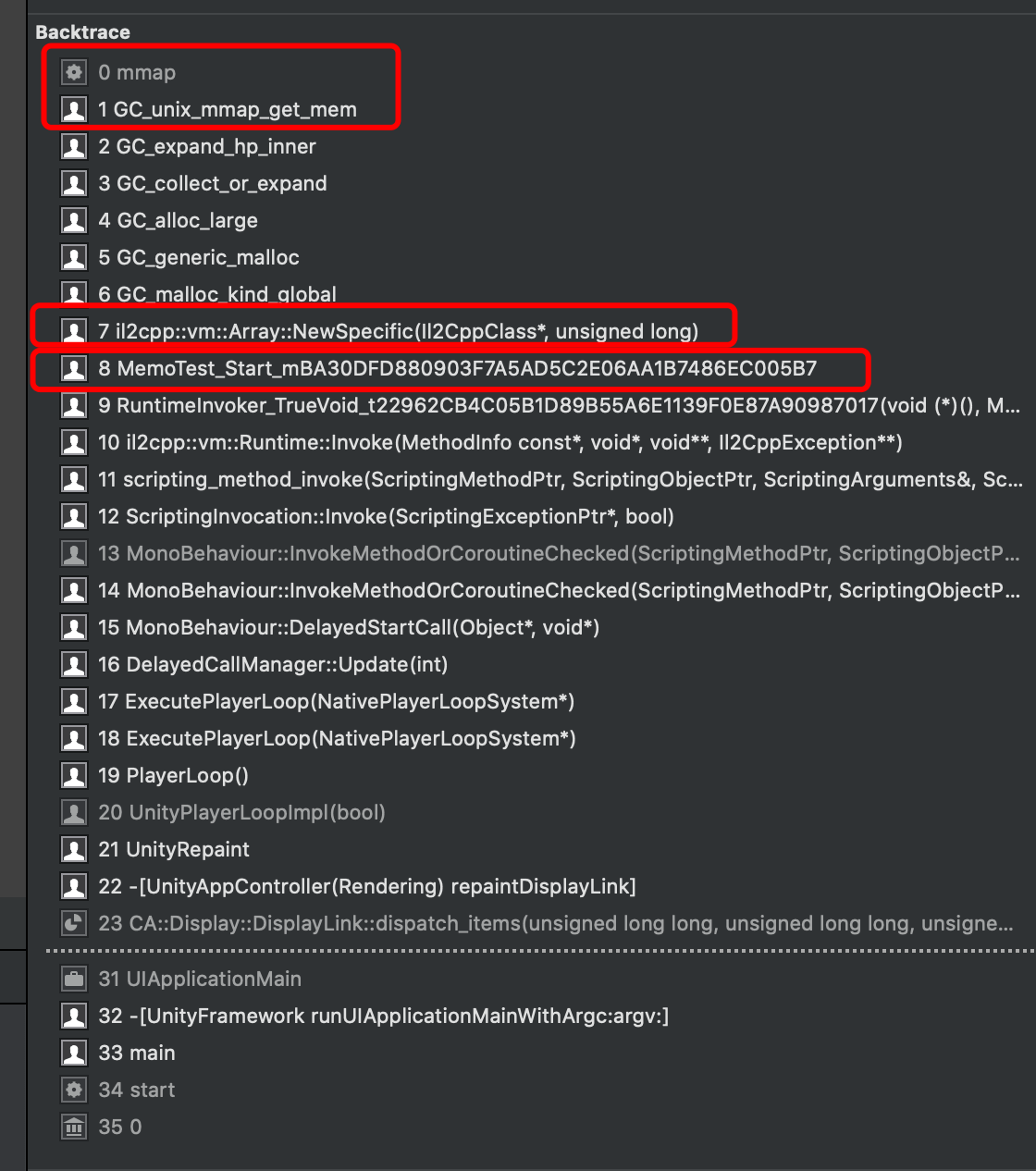
正式我们的测试代码。
然后我们来看 Instruments。
首先是 Allocations 部分,有一点要注意,该栏的下部有一些选项:

注意最后一个选项,如果选择第一个:
All Heap & Anonymous VM,All Heap 对应 App 实际分配的物理空间,不包含 VM,Anonymous VM 的官方解释是:
interesting VM regions such as graphics- and Core Data-related. Hides mapped files, dylibs, and some large reserved VM regions。因此一些比较大的预留分配空间是不会显示的。
将这个选项切换为 All VM Regions,就能看到分配的 400MB 了:

并且右边详情页面也正确显示了调用堆栈:
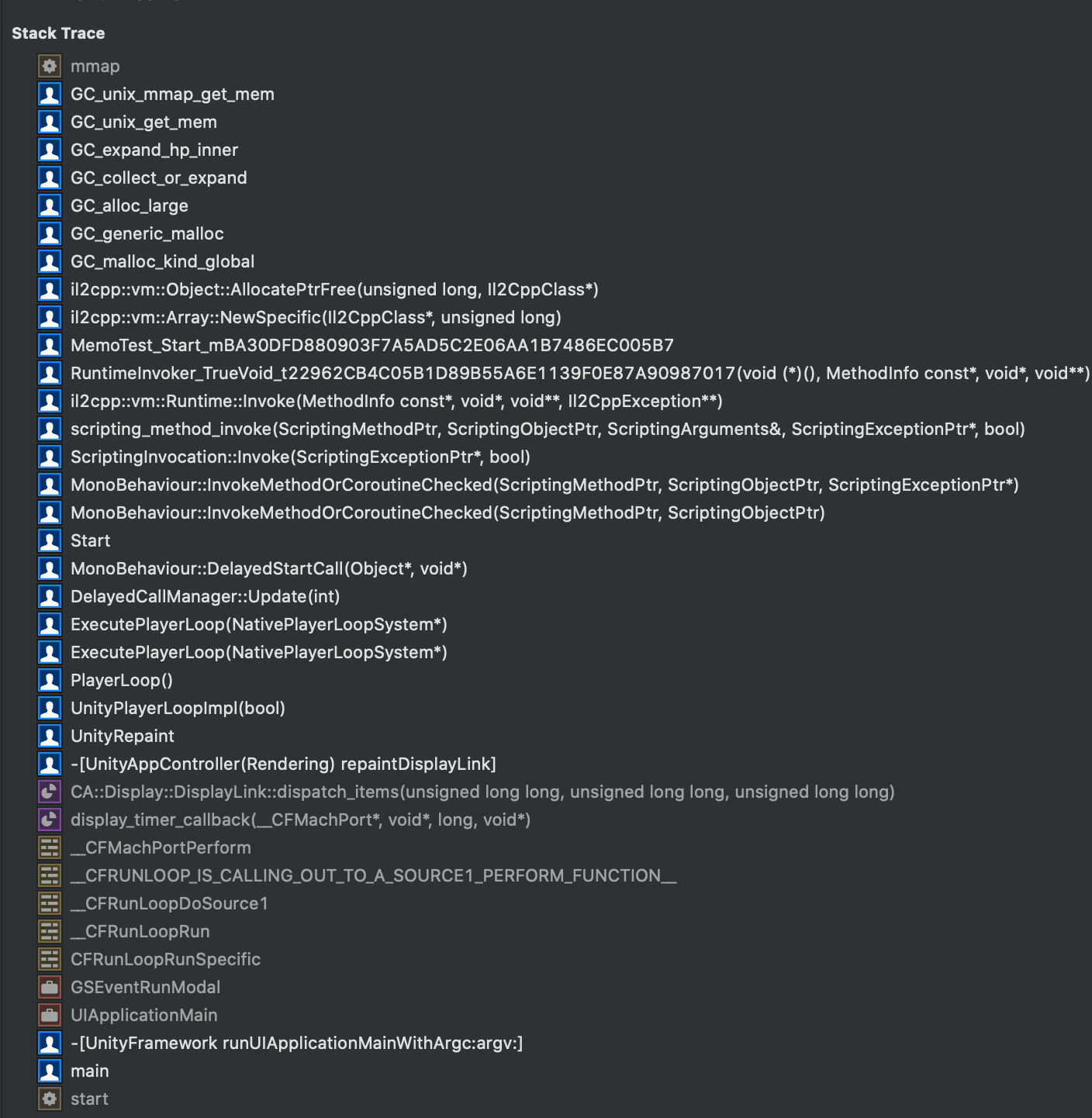
另外我们还可以从 VM Tracker 来观察,打开 VMTracker 的 Snapshots:
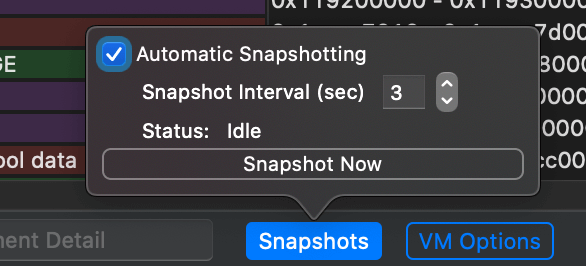
于是就能看到这 400MB 的详细分配信息:
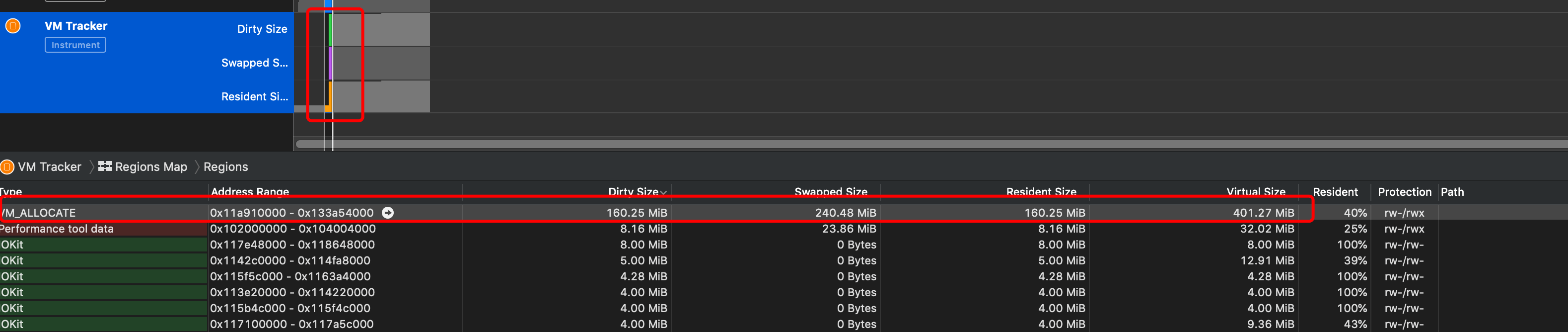
可以发现,Virutal Size 略大于 400MB,因为程序其他部分也要申请一些内存。而这 400MB 又分别保存在 Resident 和 Swapped 内,其中 Resident 部分又基本等于 Dirty Size,说明这部分大小的空间被标记了 Dirty 是不能被交换出去的,剩下 240MB 左右空间是 Clean 空间,可以暂时被交换出去以保证有足够的物理空间能使用。这也是因为我们只是申请了这部分空间,并没有进行具体的赋值初始化和使用。
那如果赋值使用了呢?修改代码测试:

运行 Instruments 后再观察:

可以清楚的发现这 400MB 都在 Dirty Size 内。这种情况真正会给该 App 和 iOS 以内存压力。
推荐阅读:
《写给 Unity 开发者的 iOS 内存调试指南》
《Understanding iOS Memory (WiP)》
感谢黄程@UWA问答社区提供了回答
Q4:URP 关于多个摄相机的性能优化
URP7.4.3,除开主相机外,还有一个子相机,用于将照到的模型渲到游戏主界面 UI 上,在 Profiler 中看到以下情况:

可以看到,在子相机中也进行了包括对 LOD 的计算,但子相机的 Cullingmask 只开了一个名为 RTModel 的 Layer,在这一层里只有一个 3D 对象。按说子相机 CullScriptable 这块开销不应该有才对。
目前怀疑可能的原因是 URP 会对每个 Base Camera 都进行这部分的计算,但如果用 Overlay 相机,又无法用原来的方式将相机的 targetTexture 渲到一张 RawImage 上了,有人遇到过么?
A:题主的疑惑是:子相机的 CullScriptable 这块的开销不应该有那么大对吧(毕竟只有一个物件)?
这里有两个问题:
1)Culling 到底做了什么,只有一个物件为什么要 Culling 那么久(难道只有一个物件也要做很多的准备工作)?
2)在 Profiler 里面看到的数据真的是真实数据吗?也就是说,子相机的 Culling 真的做了 1.68ms 吗?抛开这两个问题,也可以有更好的做法:
我们一共两个相机,主相机和 UI 相机,那么 UI 上显示的 3D 物件怎么办呢?
我们有个虚拟相机,所谓相机,其实就是做一个 VP 矩阵,做一个 RT,绘制可见的物件就可以了。使用 Unity 的 SRP,随机选一个地方,设置 VP 矩阵,设置 RT,接着绘制指定的物件(UI 中所有的 3D 物件都会挂在这个物件下面),然后这个 RT 就可以随意使用了。假如一个 UI 上有两个 3D 物件,尽量都放在一个 RT 上;如果不行,就放在两个或更多的 RT 上,只是会多几个绘制命令。几个 RT(还不需要是全屏的),而且会多几个 Swap RT 的操作。由于我们项目没需求需要若干 RT,所以假设一下,在这种需要若干 RT 的情况下,也可以用一个 RT 加多个 Viewport 来解决的。这个代码都是现成的,参考一下 Cascade Shadow Map 的做法,这样 Swap RT 也就省了。
综上所述,既然你都知道自己要绘制什么,就不要给 Unity Culling 的机会了。
在 Development Build 中连真机看到的性能数据,是真实数据吗?目前在使用类似于 HLOD 的方式来减少掉这个 LOD 的巨大开销。楼上说的 “设置一下 VP 矩阵,设置 RT”,还不太清楚这个 VP 矩阵的操作具体是个什么,可否详解下或者推荐些相关资料?
A:你提的 HLOD 和 LOD 和上面的 Culling 没关系。VP 矩阵就是 view 矩阵和 projection 矩阵。相机的作用就是提供这俩矩阵的。
如果你在管线里面设置了相应的矩阵,然后绘制指定的物件,就可以完全不用多一个相机,毕竟多一个相机就多一个 Culling。
如果你对 VP 矩阵不熟悉,不清楚怎么实现,也简单。依然用一个额外相机,关上这个相机的 Culling,然后在渲染 pass 中,不要绘制 cullingresult.visibleobject,而直接用 Graphics.DrawMesh 或者 CommandBuffer.DrawMesh 绘制你要显示的那个 3D Object 的物件就好了。
感谢王烁@UWA问答社区提供了回答
Q5:关于_CameraDepthTexture 的疑惑
如果开启_CameraDepthTexture,Camera 就需要渲染一遍场景内所有带有 ShadowCaster 的可见物体的 Pass 来实现深度图。
但是场景中的物体在开启 ZWrite 的时候就把深度写进了 Depth Buffer 中了,直接获得这个 Depth Buffer 是不是比近乎 DrawCall 翻倍的方式更有效率呢?还是 Unity 在这方面有什么考虑?
另外,问一个更实际的问题:
我们的项目需要渲染场景的中湖水的深度效果,所有不透明的场景物体的材质都是关联同样一个 Shader,这个 Shader 是带有 ShadowCaster 的。但是只有个别插入水中的物体需要去渲染 ShadowCaster 的 Pass,有没有方法在不增加 Shader 的情况下,让没有插入水里的物体不渲染 Shadow Caster Pass 呢?我们用的是 Built-in 的渲染管线。
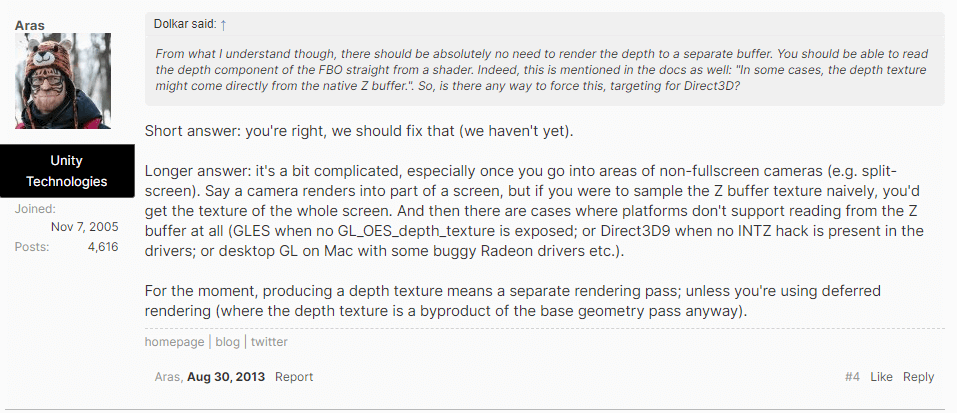
A1:第一个问题,可以参考这个问题中 Unity 官方人员的回复。
里面讲了两个原因,第一是对于非全屏渲染的情况,本来是想拿对应相机渲染的深度,但是 Depth Buffer 是全屏的。第二个原因是因为很多平台不支持直接拿 Depth Buffer 的数据。参考网页:
https://forum.unity.com/threads/poor-performance-of-updatedepthtexture-why-is-it-even-needed.197455/
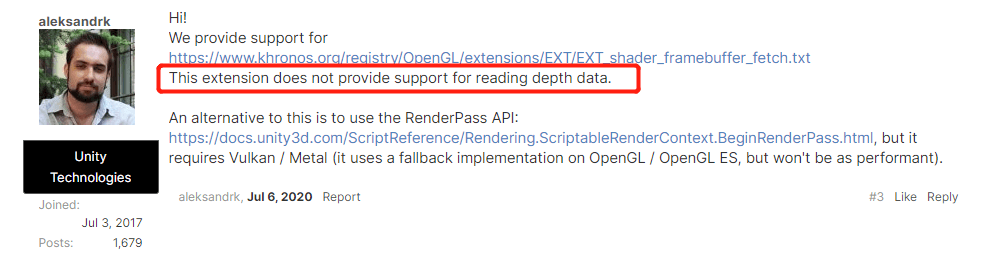
另外查 FrameBufferFetch 相关问题的时候看到 Unity 论坛上另外一个贴子里面的回答。里面说到 Unity 支持了 FrameBufferFetch,但是不支持 DepthBuffer 的获取。
参考网页:
https://forum.unity.com/threads/pixel-local-storage-and-frame-buffer-fetch-on-mobile-devices.604186/
第二个问题,如果不增加 Shader,目前没想到其他好的方法。
如果可以增加 Shader,可以将原来的 Shader 复制一份,只在 ShadowCaster 的部分加一个 “NeedDepth” 这样的 Tag,将水下的物体的材质球换成这个 Shader,另外做一个只有 ShadowCaster 并带有 “NeedDepth” 这个 Tag 的 Shader,这个 Shader 用来做 Replace 操作。额外增加一个 Camera,这个 Camera 跟随主相机,或者作为主相机的子节点,创建一个 RT,让这个 Camera 渲染到这个 RT,在 Update 里面使用 ReplaceShader 去画一下,那么只有有那个 Tag 的 ShadowCaster 会进行深度渲染,后续可以对这个 RT 进行编码等操作,这个 RT 记录的就是水下物体的深度。整个过程看上去没有特别多的额外工作,觉得可以一试(我没有做过测试,但理论上是可行的)。
感谢 Xuan@UWA 问答社区提供了回答
A2:最近自己试着升级项目到 URP,发现 Game View 的湖水深度效果没有了,Scene View 的是正常的,做了很多实验发现了两个现象。
我之前的湖水 Shader 的 Queue 是 Geometry + 150,保证自己在其他不透明物体之后渲染。别的物体有 Shadow Caster 的 Pass,湖水没有,这样在别的不透明物体渲染完成后自己能直接用到正确的_CameraDepthTexture。但是在 URP 下我必须将 Render Queue 设置到 Transparent 层才有正确效果。
发现勾选了 MSAA 抗锯齿后,就有跟 Scene View 一样正确的深度效果了。
URP 默认优先使用 Copy 的方式在所有不透明 Queue 的物体渲染完后把深度 Copy 到_CameraDepthTexture 上,我的湖水 Queue 设置在不透明层了,即使是最后渲染的,他的深度也进入了深度图中,因此效果没了。勾选 MSAA 会正常是因为 MSAA 会影响管线无法用 Copy 的方式把深度图拷出来(需要 Resolve 解析),所以 URP 默认在这种情况下使用老方式通过渲染 Depth Only (原 Shadow Caster) 的 Pass 得到深度图,因此回到了老方式,我的 Shader 就又起效果了。
其实自己如果当时看到 Framedebugger 的时候,是用心读的而不是只是草草看一眼就花心思在自认为的问题原因上会更容易得到答案。
感谢题主安日天@UWA问答社区提供了回答
Q6:渲染大面积草地时,如何降低消耗
请问下大家,渲染大面积草地时,如何降低消耗呢?
A1:回答如下:
1)使用 DrawMeshInstance;
2)上面这个 API 是不会进行视距剔除、视锥体剔除和遮挡剔除的。下面有两种方案:
a)将草地按区域分组,用每组的中心点计算视距,依据距离切换网格 LOD 或剔除;还能用向量点乘简单剔除在相机后方的草地(注意临界问题)。
b)借助 CullingGroup。
CullingGroup.onStateChanged 事件绑定,通过事件触发调整传入;DrawMeshInstanced 的 Matrix 顺序和渲染数量(但是 DrawMeshInstanced 只能指定渲染前几个 Matrix);
通过 cullingGroup.SetBoundingSpheres 实现视锥体剔除和遮挡剔除;
通过 cullingGroup.SetBoundingDistances 实现视距剔除和 LOD。
这个方案最好也进行区域分组,不然 CullingGroup 的事件监听占用会比较高,在中端机上 4000 个监听会占约 2ms 的大小。以后如果有对比两种方案的性能,我再进行补充。
附:
感谢题主李先生@UWA问答社区提供了回答
A2:使用 Indirect 模式的 Instancing,配合 Compute Shader 实现视锥剔除和遮挡剔除。
感谢邹春毅@UWA问答社区提供了回答
A3:推荐一个使用 URP 制作的草海效果,亲测可在 Mobile 端使用。
Unity URP Mobile Draw Mesh Instanced Indirect Example 性能测试:
- can handle 10 million instances on Samsung Galaxy A70 (GPU = adreno612, not a strong GPU), 50~60fps, performance mainly affected by visible grass count on screen(draw distance = 125)
- can handle 10 million instances on Lenovo S5 (GPU = adreno506, a weak GPU), 30fps, performance mainly affected by visible grass count on screen(draw distance = 75)
感谢 Vest@UWA 问答社区提供了回答
Q7:Packages 目录下的 Shader 打包 AssetBundle
Unity 引入了 Package Manager 来进行管理插件管理,例如 URP 引入 Packages 之后会有目录 Packages/com.unity.render-pipelines.universal@7.3.1。请教一下各位,如何对 Packages 目录下的资源进行 AssetBundle 打包?
例如,工程目录中有材质球引用到 URP 的 Shader,那么材质球打成 AssetBundle 之后会将 Shader 包含进去,会有 Shader 解析耗时。
A1:我这边是只使用 SBP 而不用 Addressable,这样通过使用 AssetBundleBuild 是可以将 Packages 中的资源也打包成 AssetBundle 的。
将所有依赖到的 Shader(包括 Packages 中的)都使用 AssetBundleBuild 设置到同一个 shader.bundle 的,打包后也解包确认了,Packages 中的 Shader 也打包在 shader.bundle 而不会被包含在材质 AssetBundle 中。
感谢黄晓文@UWA问答社区提供了回答
A2:我在尝试将现有项目转成 URP 的时候,遇到和 Addressable 系统有些不兼容问题。
在打包引用了 URP 的 Shader 的 Material 时会发生 Shader 被重复打包现象。
如果想把 URP 的 Shader 单独打包,又会发现因为不在 Assets 目录内,Addressable 管不到的问题。我的解决方案是将用到的 URP 的 Shader 拷出来,放到 Assets 目录下通用 Shader 目录。
当然需要将该 Shader 改名,并且要注意将内部引用的 Shader 也一并拷出管理。不过一般项目中使用的 Shader 往往还是会自己编写,直接使用官方提供总会遇到这种那种问题。因此我也会考虑尽量不用官方默认 Shader,这时对于 URP 而言自然更加需要将 Shader 拷出来进行改造了。
感谢黄程@UWA问答社区提供了回答
A3:经过 黄晓文 的思路,已经解决。
打包 AssetBundle 最重要的,就是指定资源 Path 的源路径,以及去往的目的 AssetBundle 地址,这个问题关键是需要知道资源在 Packages 中的源路径。例如一个 Packages 下的 Shader 资源,Lit.shader,通过 AssetDatabase.GetAssetPath 可以发现路径是:Packages/com.unity.render-pipelines.universal/Shaders/Lit.shader,这个是正确的路径,用它即可。
而错误的路径分别是:
1)Unity 中看到的:Packages/Universal RP/Shaders/Lit.shader 错误。
2)在文件目录中看到的:Packages/com.unity.render-pipelines.universal*@7.3.1*/Shaders/Lit.shader 错误所以得出结论:Packages 下的资源打包,去除一下 @x.y.z 即可。
感谢题主一刀@UWA问答社区提供了回答
A4:可以试试使用 Scriptableobject 或 Material 引用到 Shader 文件,然后把 ScriptableObject 或 Material 打到 AssetBundle 里。
感谢上午八点@UWA问答社区提供了回答
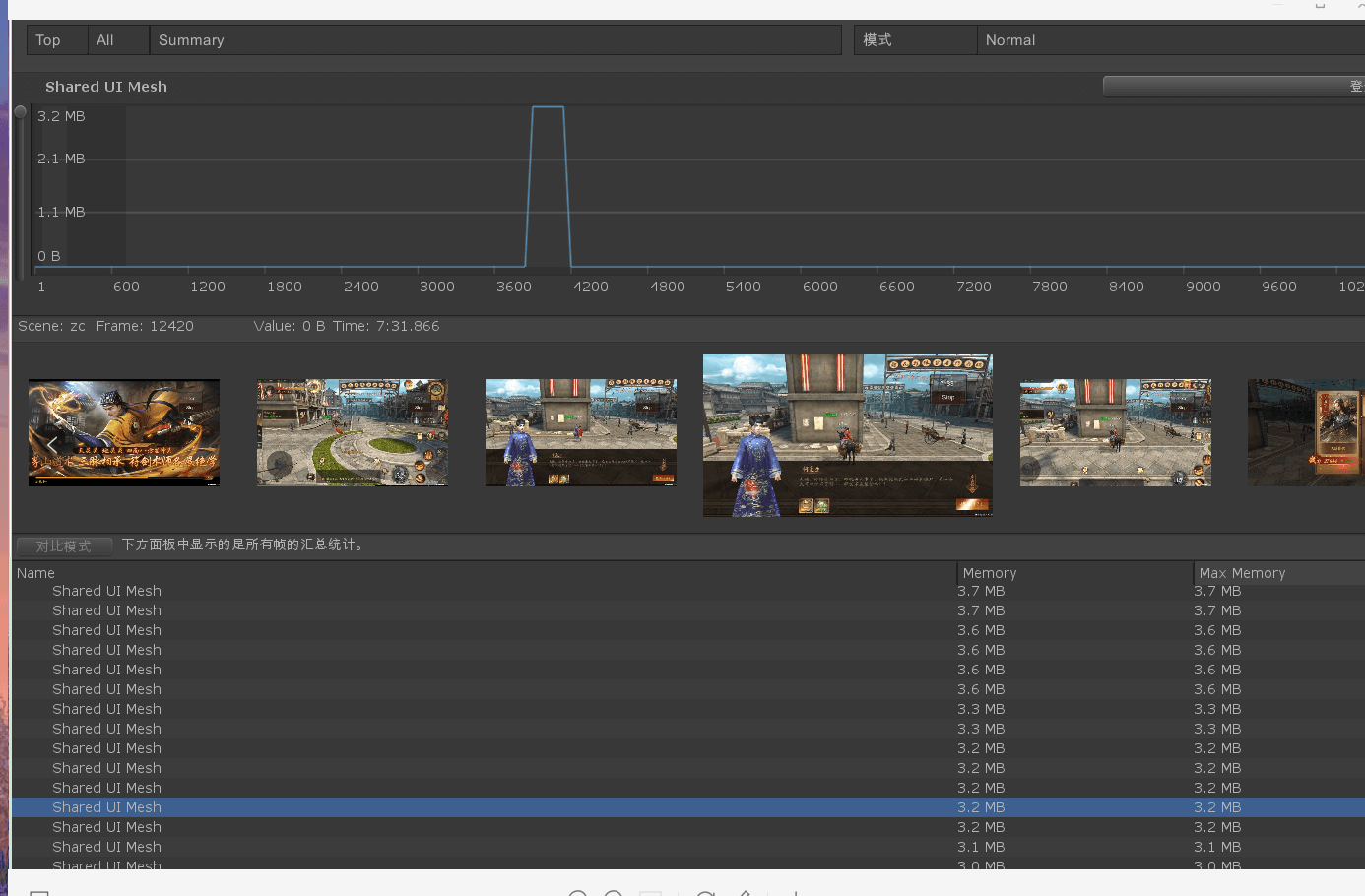
Q8:Shared UI Mesh 内存占用过高
缓存池中的 UI 如果不隐藏,Shared UI Mesh 会比较高;如果隐藏,Shared UI Mesh 会比较低,但是 UI SetActive 又有性能消耗,该如何权衡呢?
隐藏缓存池中的 UI 时,Shared UI Mesh 内存占用:

不隐藏缓存池 UI 时 Shared UI Mesh 内存占用:
A1:Shared UI Mesh 是源自 UGUI 框架中的一个静态全局变量 Graphic.workerMesh:

而 workerMesh 主要在以下代码中使用:
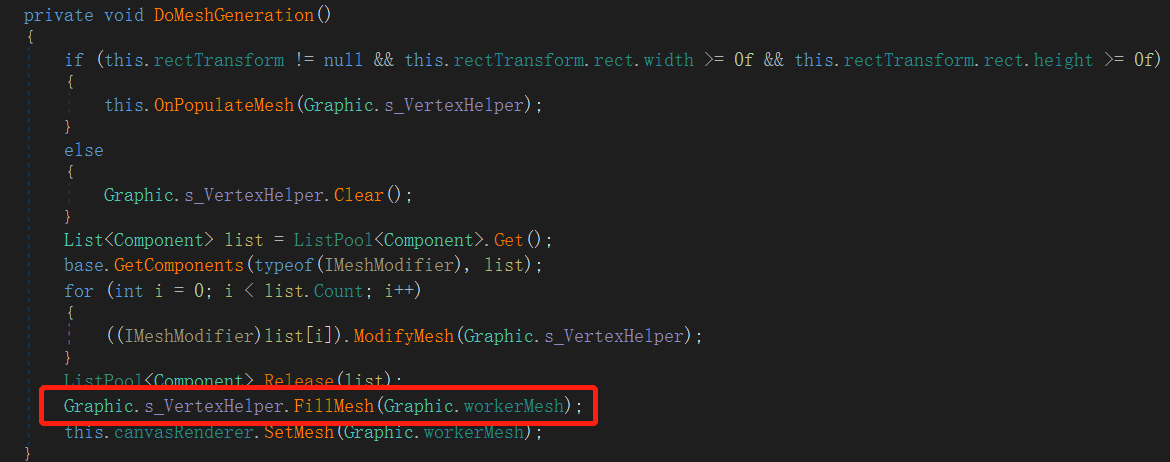
该函数是在 Rebuild 单个 UI 元素的顶点信息,红框里的 FillMesh 就是将更新后的顶点属性数组设置到 workerMesh 上,且每次调用都会先进行 Clear 操作。
看逻辑,这个 workerMesh 的内存大小应该只和单个 UI 元素的顶点量有关,但实际测试下来,是和当前所有激活 UI 元素的顶点总量相关的。
所以,Shared UI Mesh 很大,表示当前所有激活 UI 元素的顶点总量很高。需要对部分复杂元素进行简化。
常见的复杂元素有:
1)Tiled 模式的 Image:该模式下会根据 UI 元素的区域和纹理分辨率的大小,自动生成适当数量的四边形,一旦纹理分辨率很小,而区域很大时,就会产生大量的顶点。
2)Outline 效果的 Text:Outline 效果会将 Text 文本原来的顶点数放大为 5 倍。
3)RichText,且包含了较多样式的 Text:样式标签部分也会产生顶点数。
注:2 和 3 同时使用时,样式标签部分的顶点数也会放大。定位的方法:
1)初步定位:直接在 SceneView 下换到线框模式,肉眼找一下复杂元素;
2)通过 Profiler 的 UI 面板,查看各个 Canvas 下各个 Batch 产生的顶点数,并检查对应的 GameObject 即可。

需要注意的是,Canvas 组件被禁用的情况下,Profiler 里是看不到的,但其下的激活 UI 元素依然会影响 Shared UI Mesh 的大小。
该回答由 UWA 提供
A2:如果只有 SetActive 才能降低 Shared UI Mesh,好像就没有其他选择了;但是如果切换 layer 可以降低,可以选择该办法。
感谢青麈@UWA问答社区提供了回答
A3:也可以试试把 Canvas 的 Enable 设置为 False。
感谢 Crazy_Liu@UWA 问答社区提供了回答
Q9:Addressable 如何删除旧资源
目前计划使用 Addressable 来实现资源热更新,实际真机测试发现当资源更新后,旧的资源 Addressable 并不会把它删除,同时可以看到 App 占用的数据文件会越来越大。请问有什么办法可以把指定的 Group 或 Label 的资源删除吗?
试了 Addressable.ClearDependencyCacheAsync 也不行。实际测试这个接口只能删除最新版本的资源。当本地已经是最新版本资源时这个接口确实有效;但是如果本地需要更新资源时,这个接口应该也是尝试去删除最新资源,然而本地并没有最新版的资源,所以大概就无效了。
A:调用 Addressable.ClearDependencyCacheAsync 实质是调用了 “Caching.ClearAllCachedVersions();”。事实上是使用了 Unity 的 Caching 系统。
在 Windows 编辑器环境测试了一下。
Caching 的目录为 “C:\Users\UserName\AppData\LocalLow\Unity\ProjectFolder”,当正常下载 AssetBundle 以后,该目录内就出现 “stage01_298bd883434eedb69ea7316cb23e0b0d\662ab7a0d2aa99bc7a2dbb7baec63872” 之类的目录,并保存着当前的 AssetBundle 版本,当更新 AssetBundle 并执行下载以后,该目录也会出现其他 AssetBundle 的 Caching 目录。在执行下载之前,先执行了一下 “Caching.ClearCache();”,这时会发现 Caching 目录内已经被清空,所有版本的 AssetBundle 都没有了。下载完成后,该目录只保留了最新的 AssetBundle 资源。由此可推,即使不通过 Addressable 系统,仍然可以通过 Caching 把所有的资源都清理掉。
于是继续进行第二个实验,连续更新几次 AssetBundle 以后,Caching 目录内已经有多个版本的 AssetBundle 目录了,当有新的更新后执行 “Addressables.ClearDependencyCacheAsync(key);”,发现的确并没有将旧版本的 AssetBundle 都删除。因为 “Caching.ClearAllCachedVersions” 的参数是对应的 AssetBundle 名字,而 Addressables 的管理 AssetBundle 包名是带 Hash 的,因为每个版本的 AssetBundle 文件名都不一样的,Caching 系统也就无法分辨了。
继续做实验,将打包名字去掉 Hash,Caching 目录内的 AssetBundle 目录名也不带 Hash 了,然后连续更新几个版本后发现,该 AssetBundle 目录内多了几个不同 Hash 版本的目录,内部才是真正的 AssetBundle。于是走 “Addressables.ClearDependencyCacheAsync(key)”,这时就能正确地删除旧版本,然后再更新新版本了。
确实不勾选 Hash 打包可以成功删除了,这种方式貌似就是覆盖式的打包,不知道会不会有其他隐患,目前来看够用。
A:隐患就是如果按照 Label 来做更新检查,本来可以只下载差异部分,但是因为同样使用 Label 做清除 Caching 的工作就会造成重复下载原本不必要更新的部分。于是就需要遍历所有的 Location 然后去检查更新,并将有更新的 AssetBundle 放入列表,然后再依次清除旧缓存,重新下载。这样就和传统方案没太大区别了。
请问下不勾选 Hash 其实就不用清除了吧?名字一样不是会直接覆盖吗?
A:不勾选 Hash,只是在 Cache 的目录内第一级资源同名子目录是一致的,但是里面保存具体数据的子目录是递增的,因为有不同版本。每个版本都会有一个子目录。这个是 Caching 系统管理的。
如果不勾选 Hash,CDN 有可能不会更新文件,所以要结合自己的项目使用的 CDN 情况来确定如何管理这块。
我是用 Addressables.ClearDependencyCacheAsync(key) 并没有清除 Cache 多次更新后越来越多。上面所说的 “将打包名字去掉 Hash”,是指配置中 Bundle Naming 选择 Fliename 选项嘛?所使用的 Key 是指本次更新的列表吗?
A:就是 “配置中 Bundle Naming 选择 Fliename”,这个 Key 其实是应该是这个 Group 名字,对应到打包后的 Bundle 名字,让 Caching 系统搜索。貌似 1.15.X 后面这块有一些更新,还没确认过。
感谢黄程@UWA问答社区提供了回答
A:在论坛里看到一个方案(11 楼),修改了 Addressables.ClearDependencyCacheAsync(key) 的实现:
首先在 Addressables.ClearDependencyCacheForKey 中对当前使用的资源进行 Cache 标记,然后在 Addressables.ClearDependencyCacheAsync 里清除游戏运行之后未使用的资源。
修改 AddressablesImpl.cs 文件中的以下四个方法:
- ClearDependencyCacheForKey(object key)
- ClearDependencyCacheAsync(object key)
- ClearDependencyCacheAsync(IList locations)
- ClearDependencyCacheAsync(IList keys)
需要注意调用 Addressables.ClearDependencyCacheAsync 的时机。
internal void ClearDependencyCacheForKey(object key) { #if ENABLE_CACHING IList<IResourceLocation> locations; if (key is IResourceLocation && (key as IResourceLocation).HasDependencies) { foreach (var dep in (key as IResourceLocation).Dependencies) Caching.ClearAllCachedVersions(Path.GetFileName(dep.InternalId)); } else if (GetResourceLocations(key, typeof(object), out locations)) { foreach (var loc in locations) { if (loc.HasDependencies) { foreach (var dep in loc.Dependencies){ // added by Lukas AssetBundleRequestOptions options; if ((options = dep.Data as AssetBundleRequestOptions) != null) { //对当前依赖资源进行标记 Caching.MarkAsUsed(dep.InternalId, Hash128.Parse(options.Hash)); } //原方法无法删除旧版本的ab //Caching.ClearAllCachedVersions(Path.GetFileName(dep.InternalId)); } } } } #endif }public AsyncOperationHandle<bool> ClearDependencyCacheAsync(object key) { if (ShouldChainRequest) return ResourceManager.CreateChainOperation(ChainOperation, op => ClearDependencyCacheAsync(key)); ClearDependencyCacheForKey(key); // added to ClearCache Caching.ClearCache((int) Time.realtimeSinceStartup + 10); var completedOp = ResourceManager.CreateCompletedOperation(true, string.Empty); Release(completedOp); return completedOp; }
感谢小魔女纱代酱@UWA问答社区提供了回答
A:我们用的是覆盖式更新的流程(不是增量更新)。Addressables 版本是 1.15.1。
在把 Bundle Naming 设置为 Filename 后发现,在 Caching 中的 AssetBundle 目录还是带有 Hash 值的,这个和楼上的解释不一致,不知道是不是版本的原因。
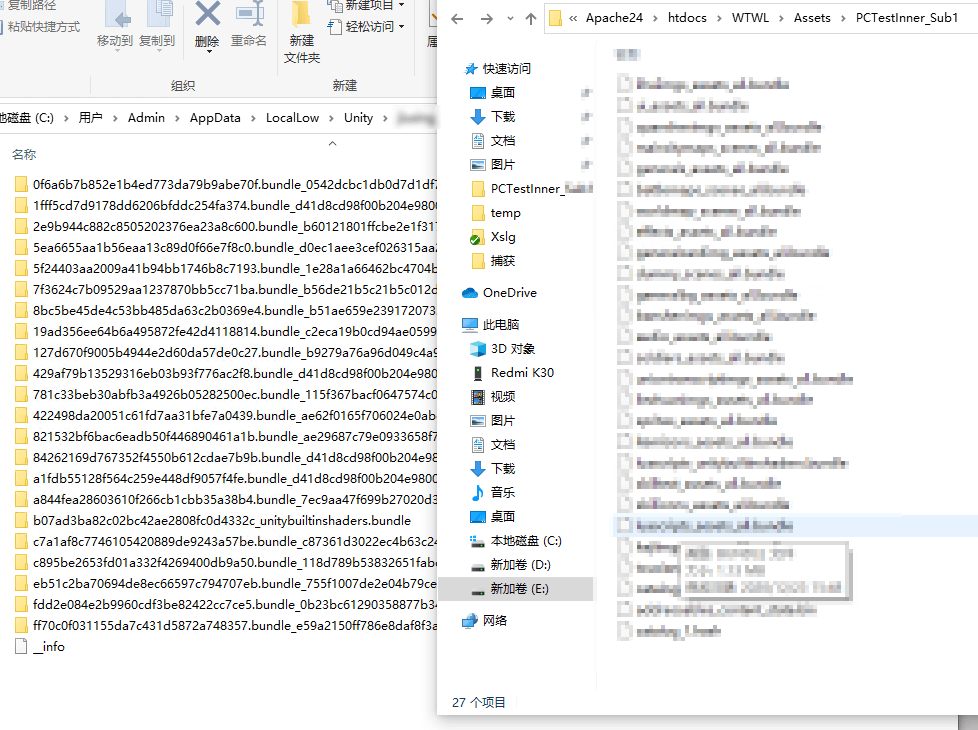
图中可看到 AssetBundle 包名已经是 Group 的名字了,但是下载到 Caching 中还是有 Hash。
然后我们是这么解决的。还是开启文件名的 Hash,将 Caching 中的 AssetBundle 文件夹名保存到 PlayerPrefs 中,当检测到有下载的时候,读出 PlayerPrefs 中的值,把旧的对应 AssetBundle 包删除,并更新 PlayerPrefs。
获取当前 Catalog 中所有 AssetBundle 文件夹名的方法,是从 Addressables 中复制出来的。
// 获得当前catalog中所有 assetbundle 保存的文件夹名 // 这个函数中引用到的方法没有列出,可以去 addressables 中源码中找 // 示例:CollectBundleNames(new string[]{ "SkllIcons", "ItemIcons", "AvatarIcons" }) private static List<string> CollectBundleNames(object[] keys) { List<string> result = new List<string>(); #if ENABLE_CACHING foreach(var key in keys) { IList<IResourceLocation> locations; if (key is IResourceLocation resourceLocation && resourceLocation.HasDependencies) { foreach (var dep in resourceLocation.Dependencies) { if (dep.Data is AssetBundleRequestOptions options) { result.Add(options.BundleName); } } } else if (GetResourceLocations(key, typeof(object), out locations)) { var deps = GatherDependenciesFromLocations(locations); foreach (var dep in deps) { if (dep.Data is AssetBundleRequestOptions options) { result.Add(options.BundleName); } } } } #endif return result; }删除 AssetBundle 包文件夹的方法:
// 这里的 bundleName 就是 CollectBundleNames 的返回值 private static void ClearCacheForBundle(string bundleName) { List<Hash128> hashList = new List<Hash128>(); Caching.GetCachedVersions(bundleName, hashList); foreach (Hash128 hash in hashList) { Caching.ClearCachedVersion(bundleName, hash); } }需要注意的是调用 CollectBundleNames 的时机,如果已经更新了 Catalog,那么返回的是即将要写入 Caching 中的 AssetBundle 文件夹名。如果要得到当前 AssetBundle 文件夹名,要在更新 Catalog 之前调用。
感谢 jim@UWA 问答社区提供了回答
Q10:LuaJIT 性能热点函数优化
项目中的这个函数耗时非常严重,有什么优化的方法吗?

A1:这个是 table.get,对应获取字段或者访问数组时调用的函数:
优先使用连续数组而不是英文名字段,可以显著提升访问效率并降低内存消耗,很多团队喜欢使用 Class 的写法,可以这样改造:
local obj = ClassA.New()
obj.abc = 1
obj.cde = "test"
变成:
local obj = ClassA.New()
obj[1] = 1
obj[2] = "test"
这个方法可以针对使用频率较高的代码进行改造。自己开发工具,在编译 Lua 之前,将 Lua 代码中的常量从英文名变量转换为数值,这个可以结合 1 使用,就可以在开发期写英文名字段名,然后编译时转换为数组。
感谢招文勇@UWA问答社区提供了回答
A2:字符串应该是哈希值计算的消耗,这样的开销应该是很频繁地调用了。
感谢王欢@UWA问答社区提供了回答
今天的分享就到这里。当然,生有涯而知无涯。在漫漫的开发周期中,您看到的这些问题也许都只是冰山一角,我们早已在 UWA 问答网站上准备了更多的技术话题等你一起来探索和分享。欢迎热爱进步的你加入,也许你的方法恰能解别人的燃眉之急;而他山之 “石”,也能攻你之 “玉”。
官网:www.uwa4d.com
官方技术博客:blog.uwa4d.com
官方问答社区:answer.uwa4d.com
UWA 学堂:edu.uwa4d.com
官方技术 QQ 群:793972859(原群已满员)