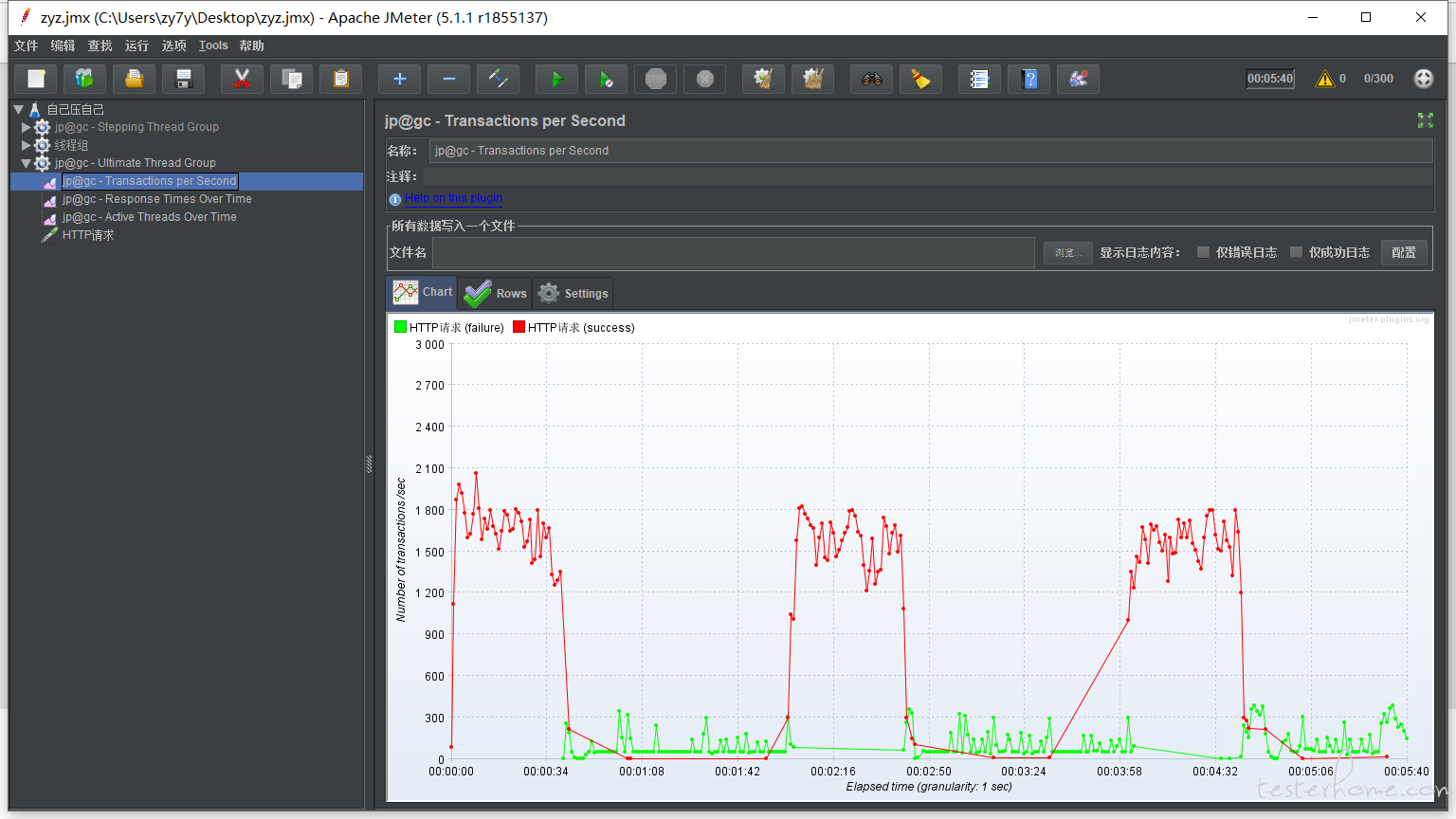
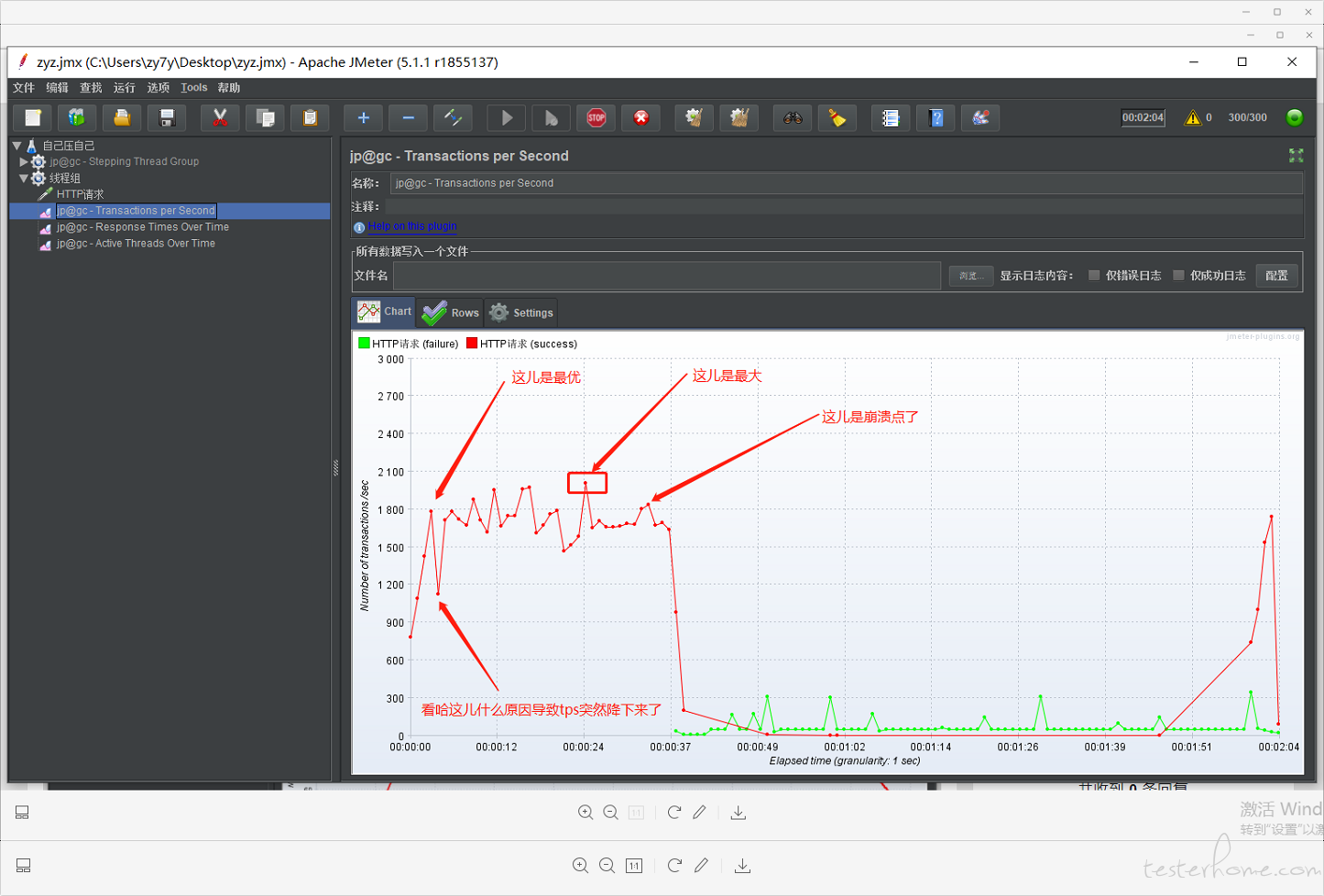
真的不懂。。,请问下图中的最优 最大如何看
2
3
我一朋友告诉我
二八原则
感觉要么是你施压机有问题,要么是 service 有性能问题,这 TPS 波动也太大了吧。。
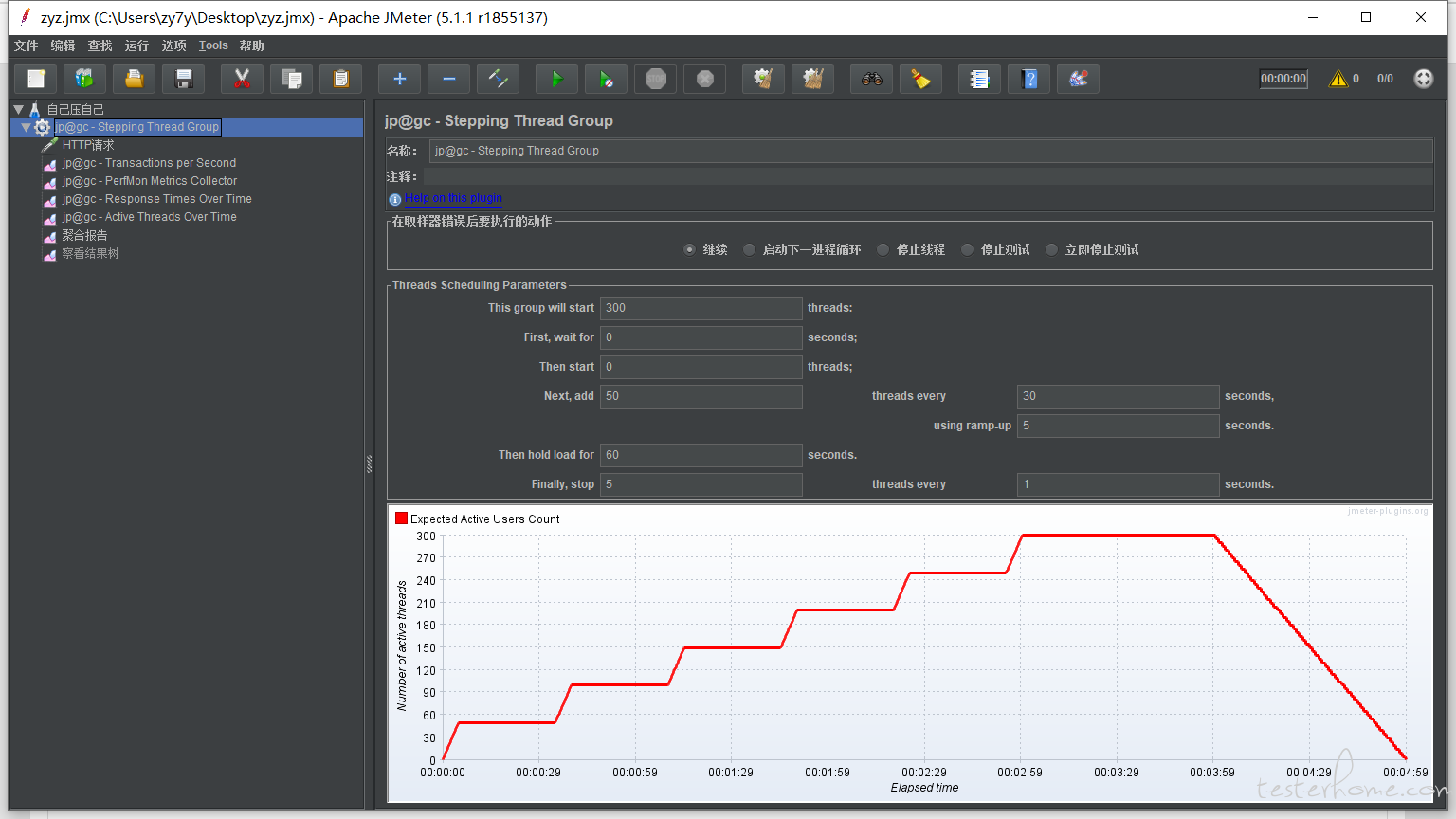
当 TPS 不能随着并发用户数的上升而增长时,那首先达到最高 TPS 的并发数就是最优的
最大并发数一般要结合性能需求来,比如超过多少用户后,TPS 下降,响应时间增长,服务器负载过高到某个阈值等等。
最好是通过手动加压来测,因为在测试之前,这些值都是未知,预先制定的加压策略可能说明不了问题
另外做性能首先得根据测试目标定好策略,对曲线的每一个走势都能拿出合理解释。
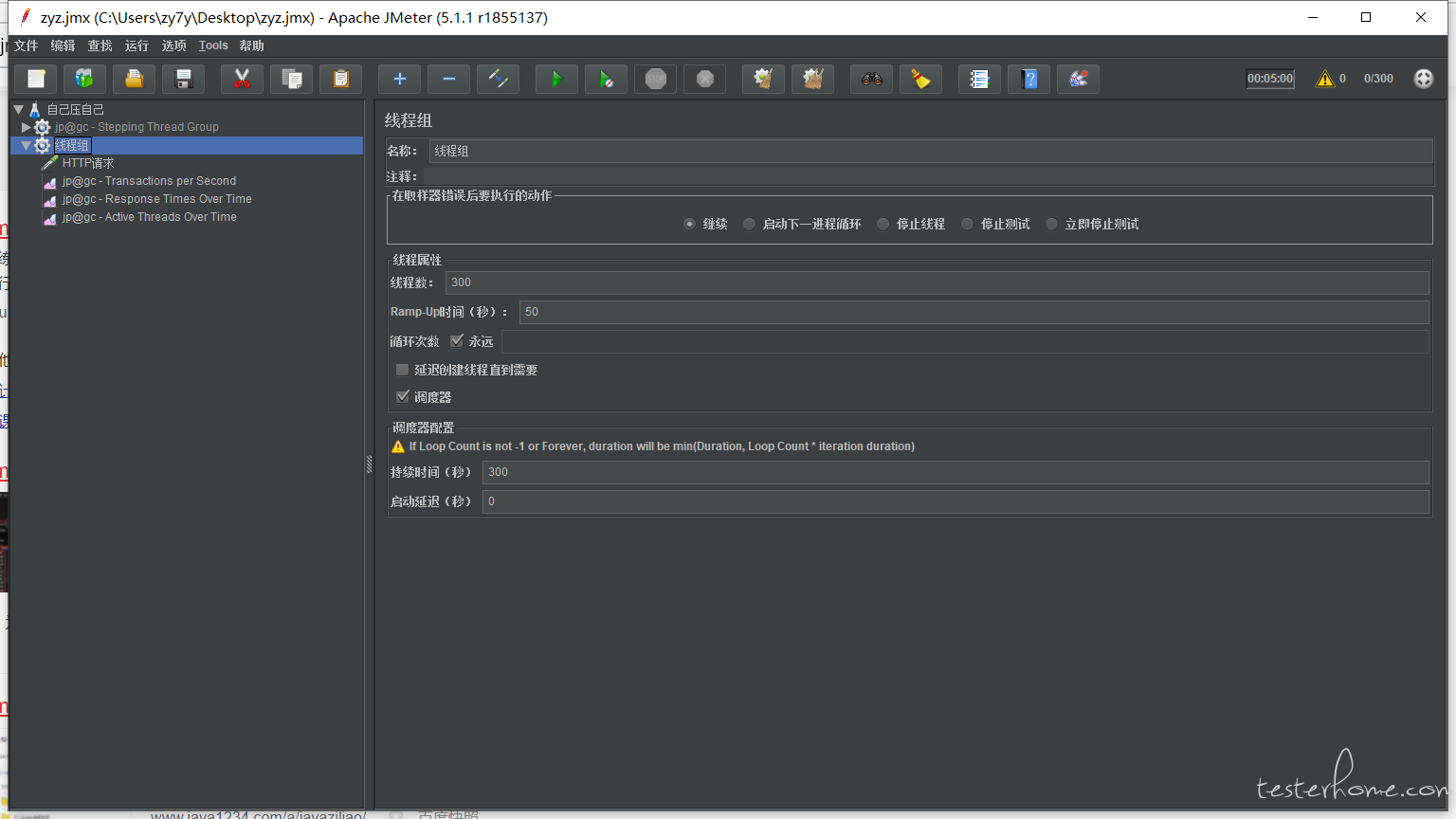
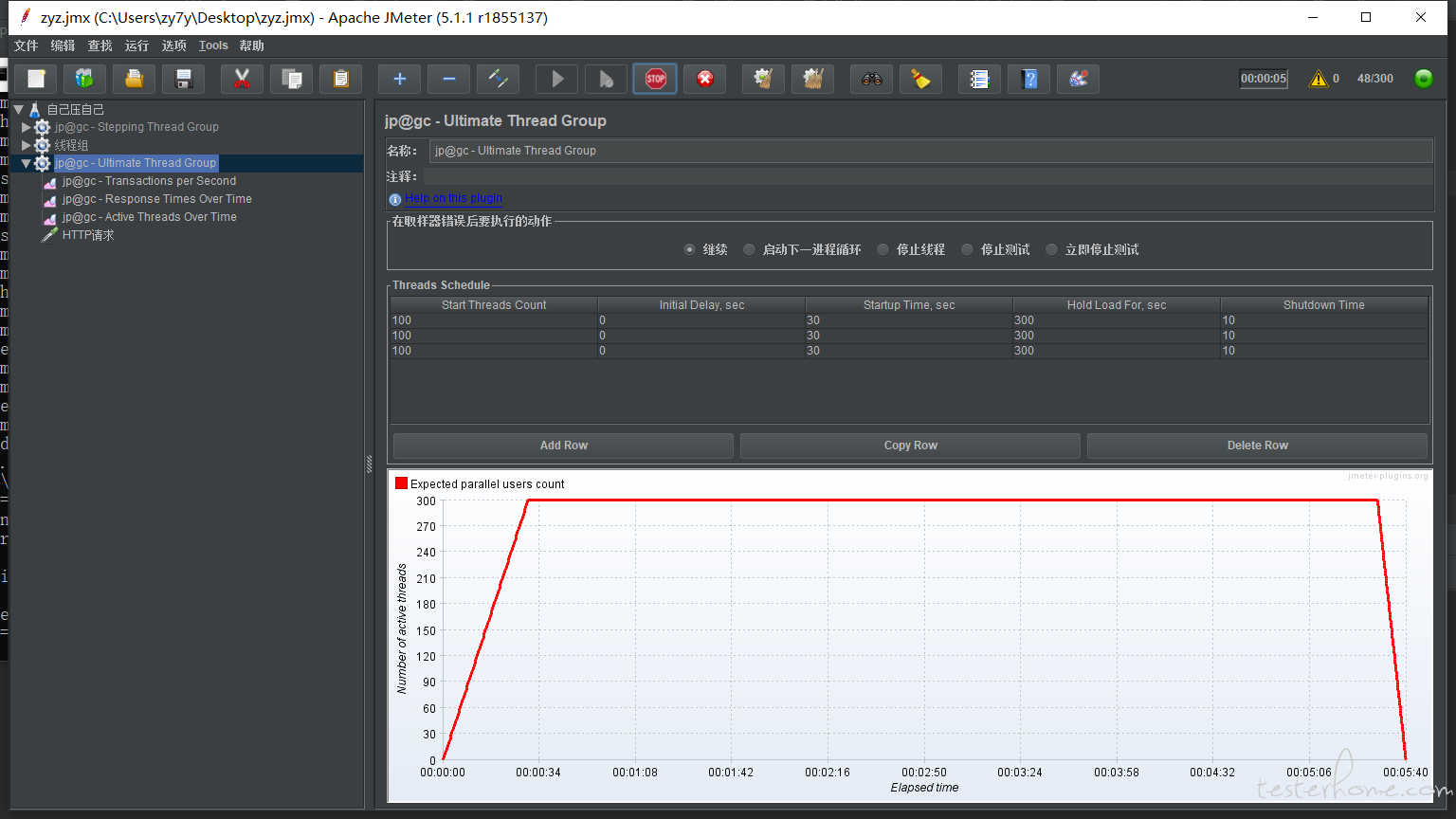
目前设计线程组如下: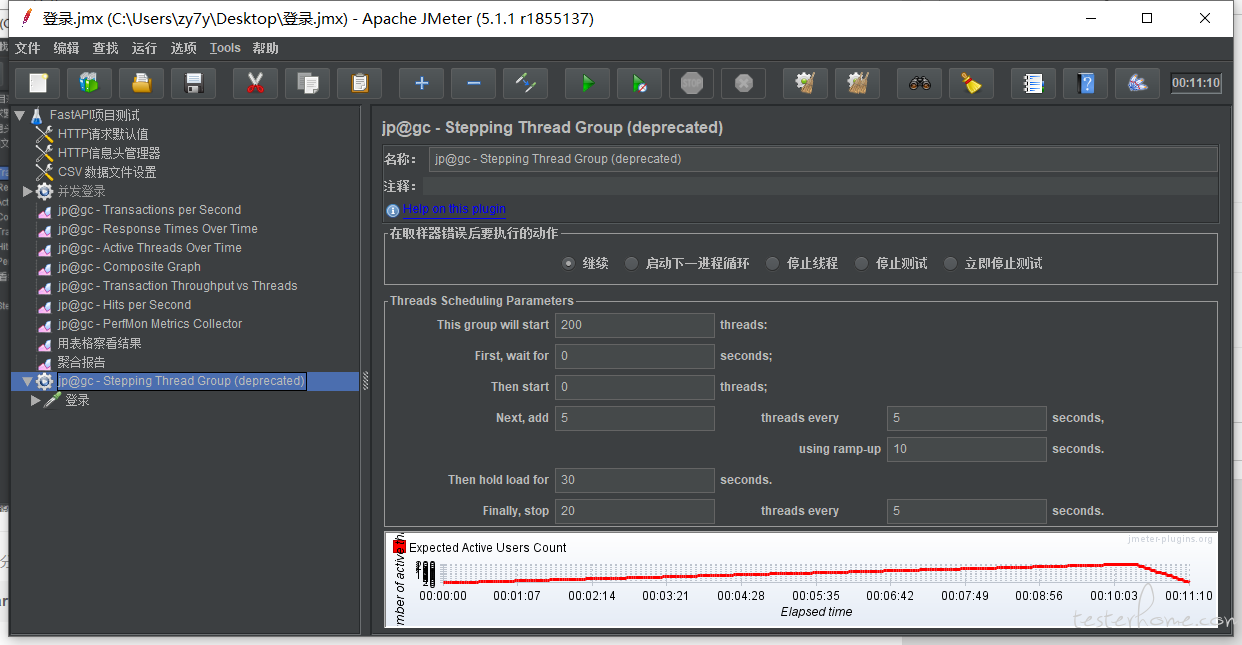
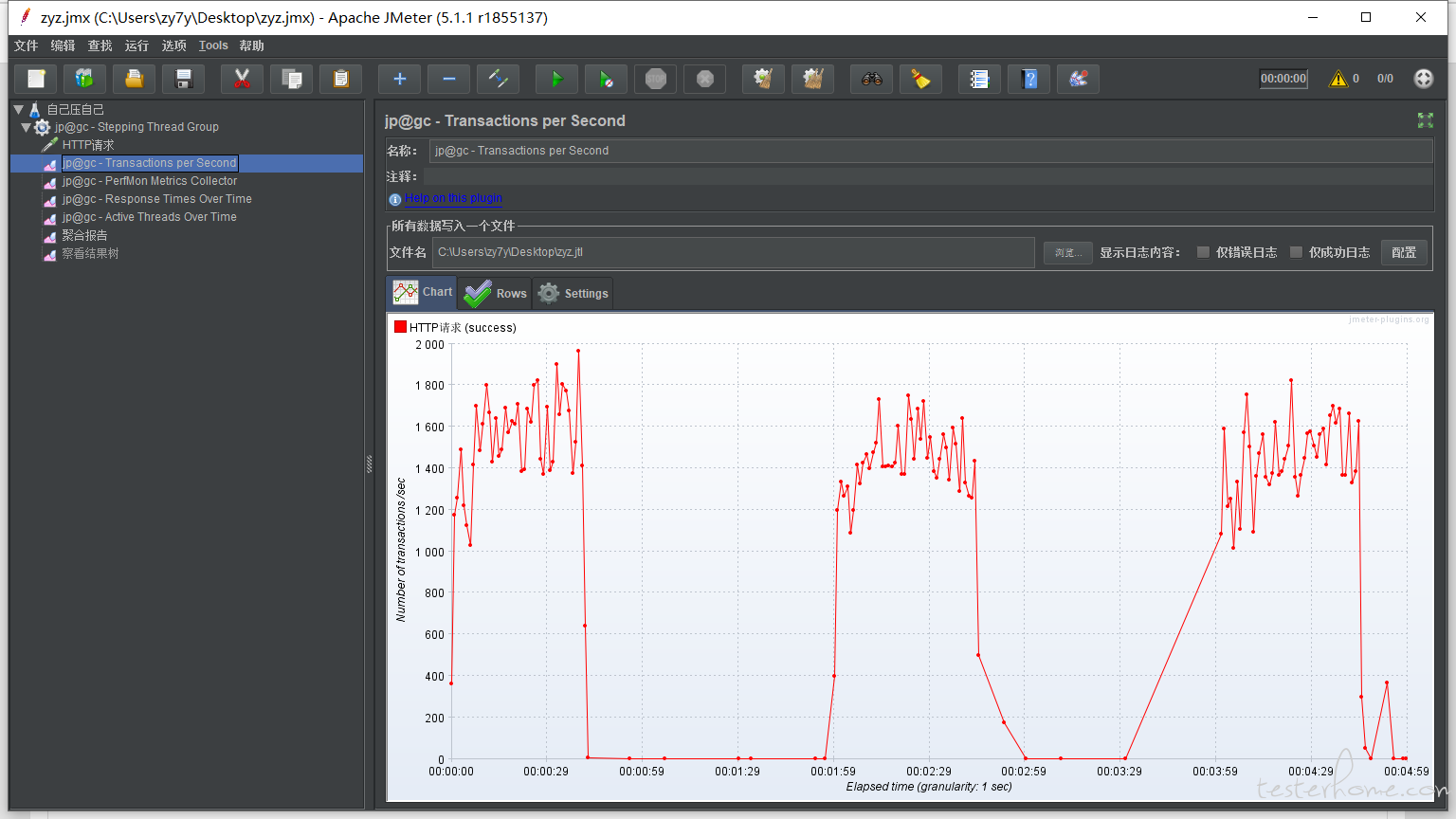
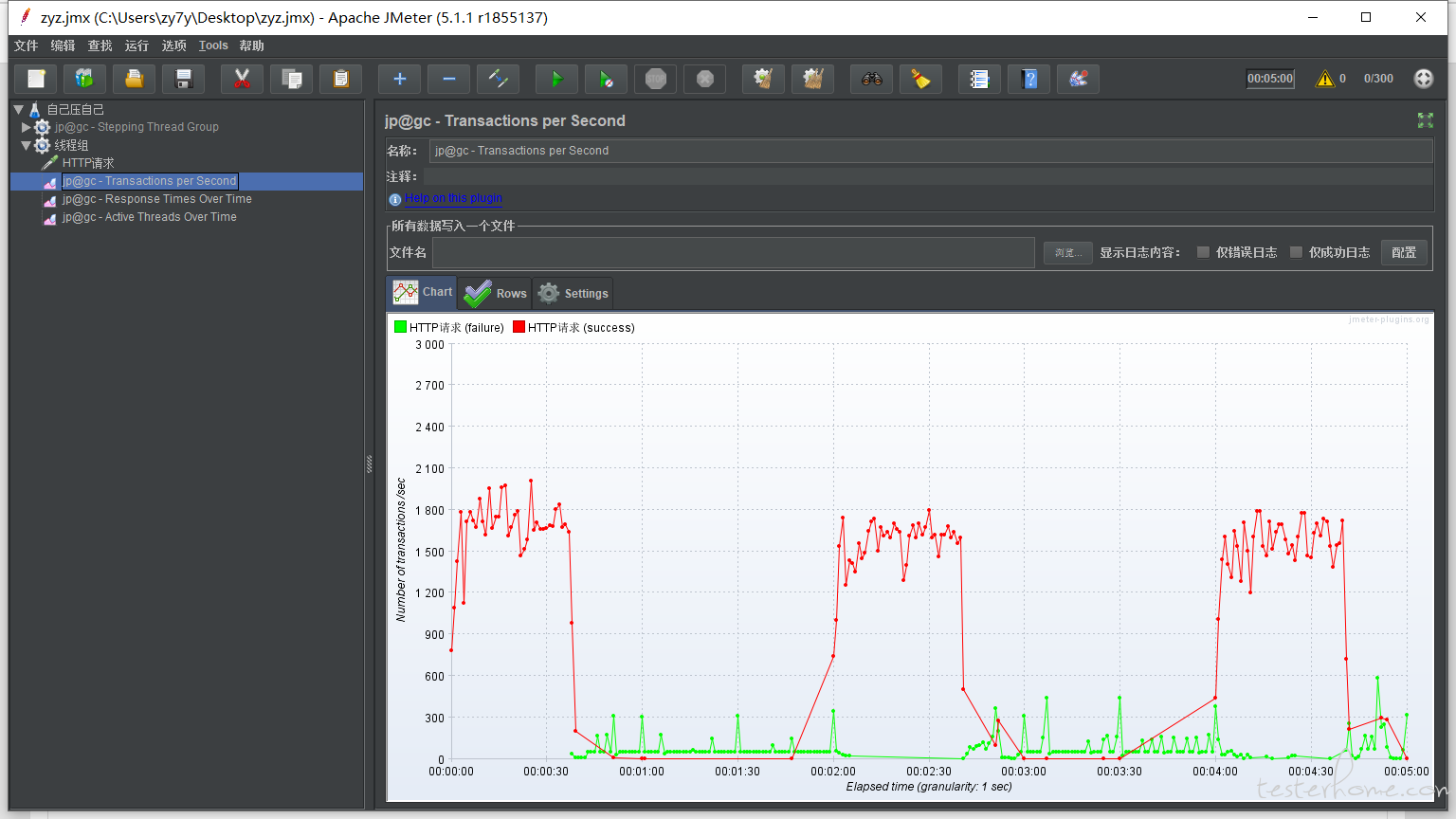
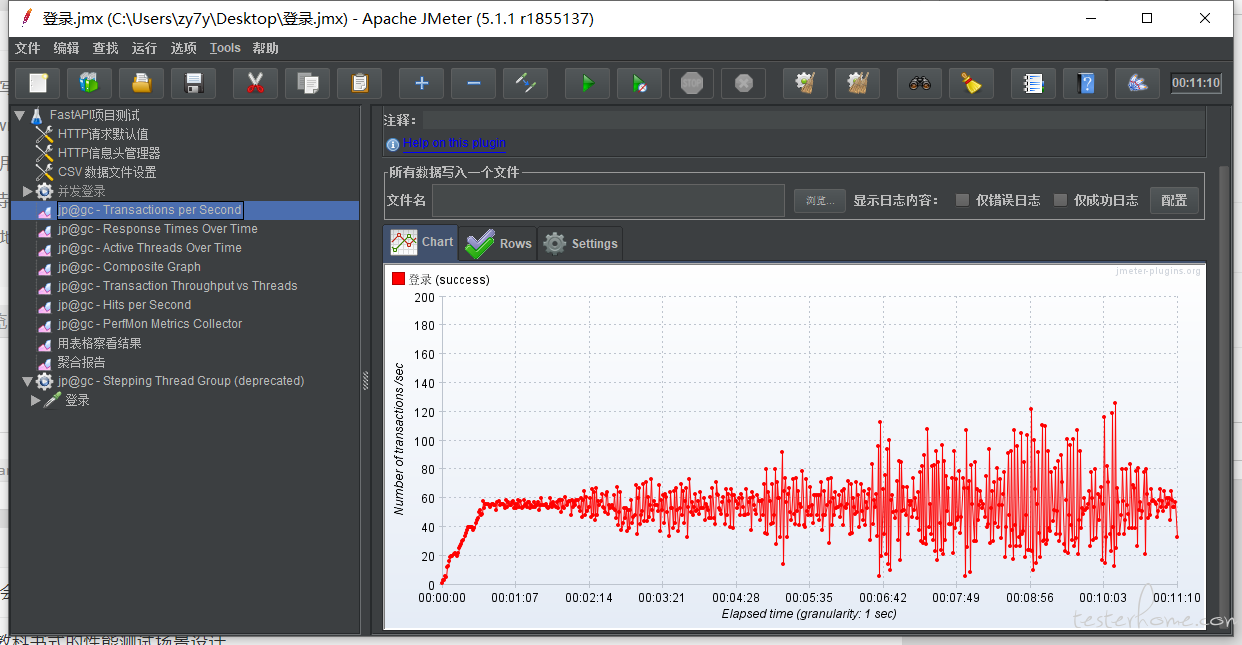
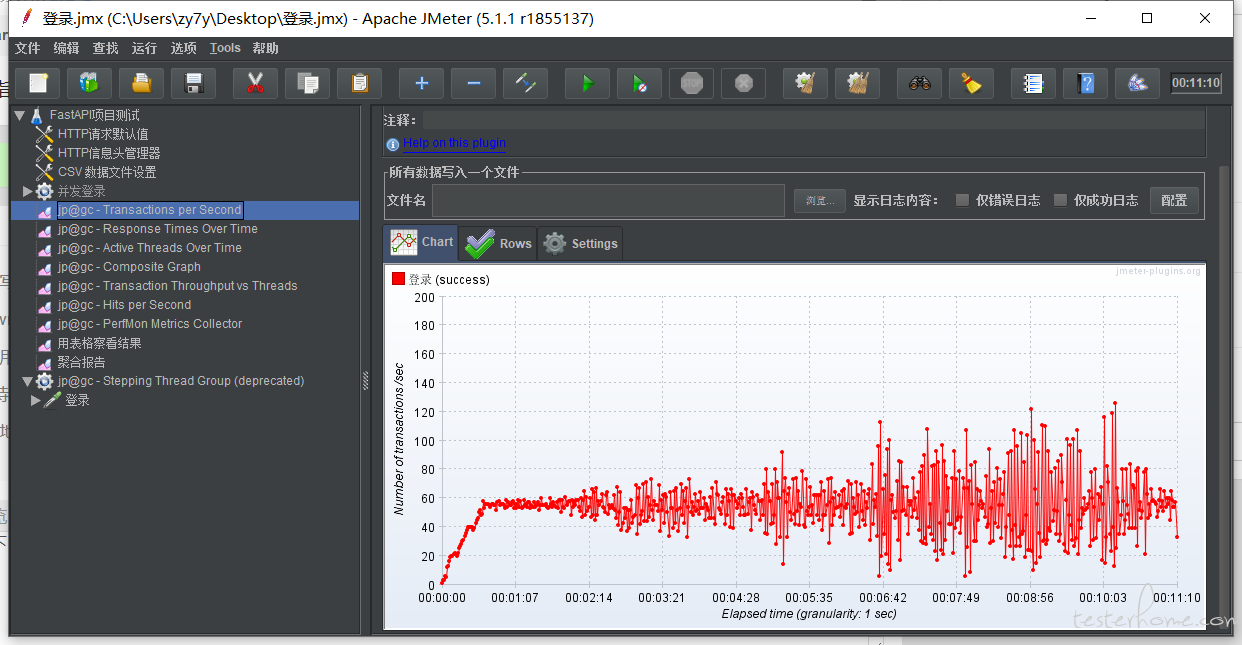
测试结果
tps:
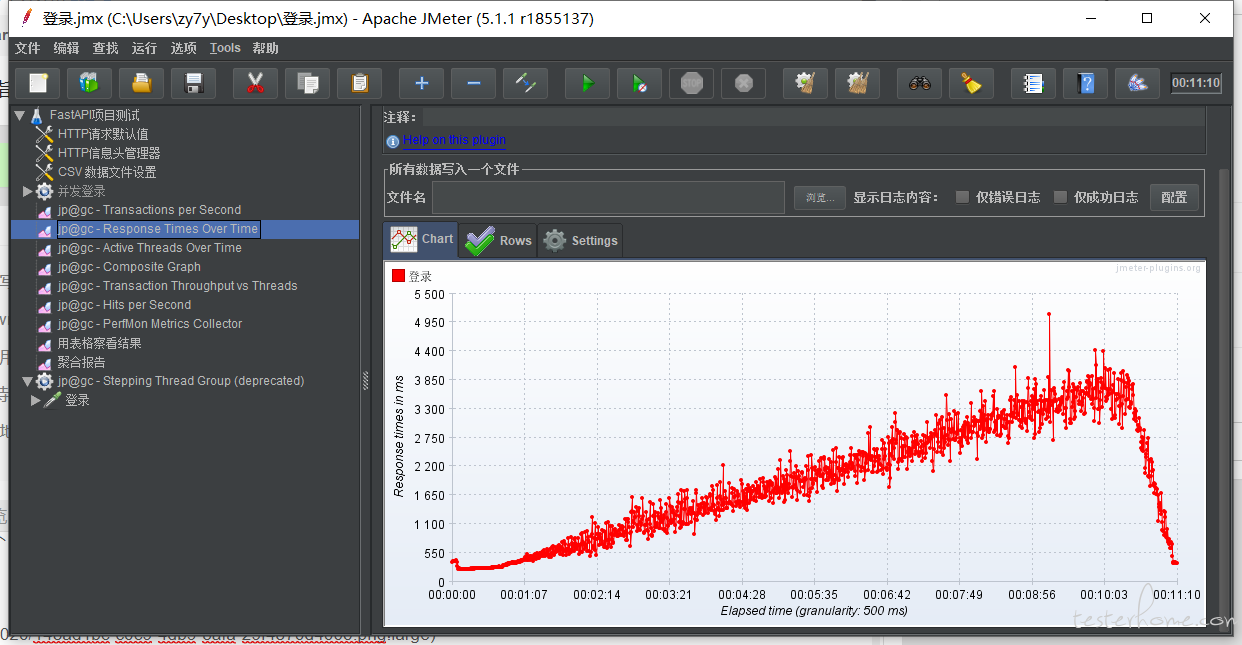
响应时间:
rps:
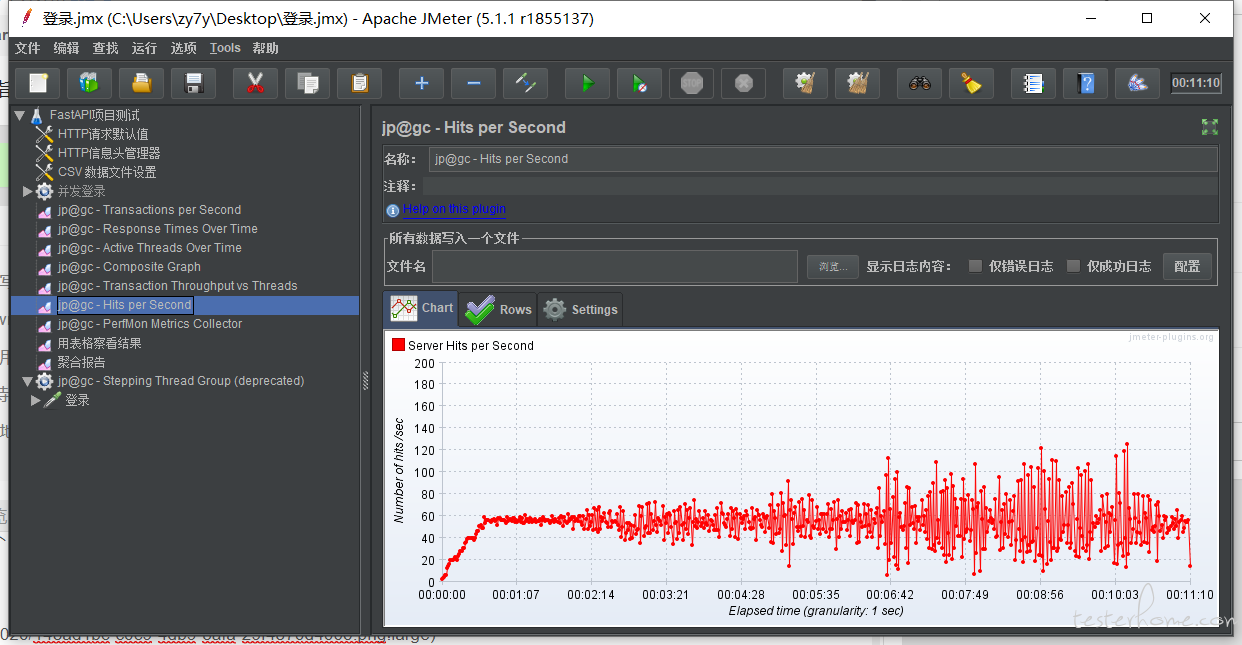
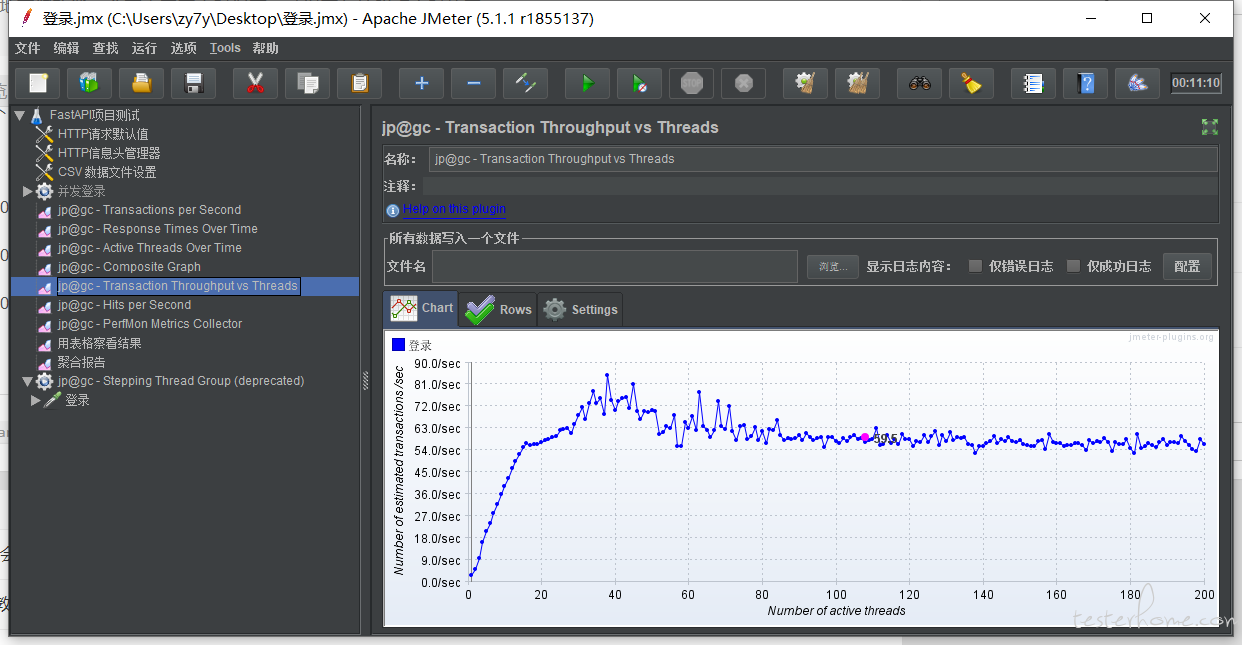
jp@gc - Transaction Throughput vs Threads:
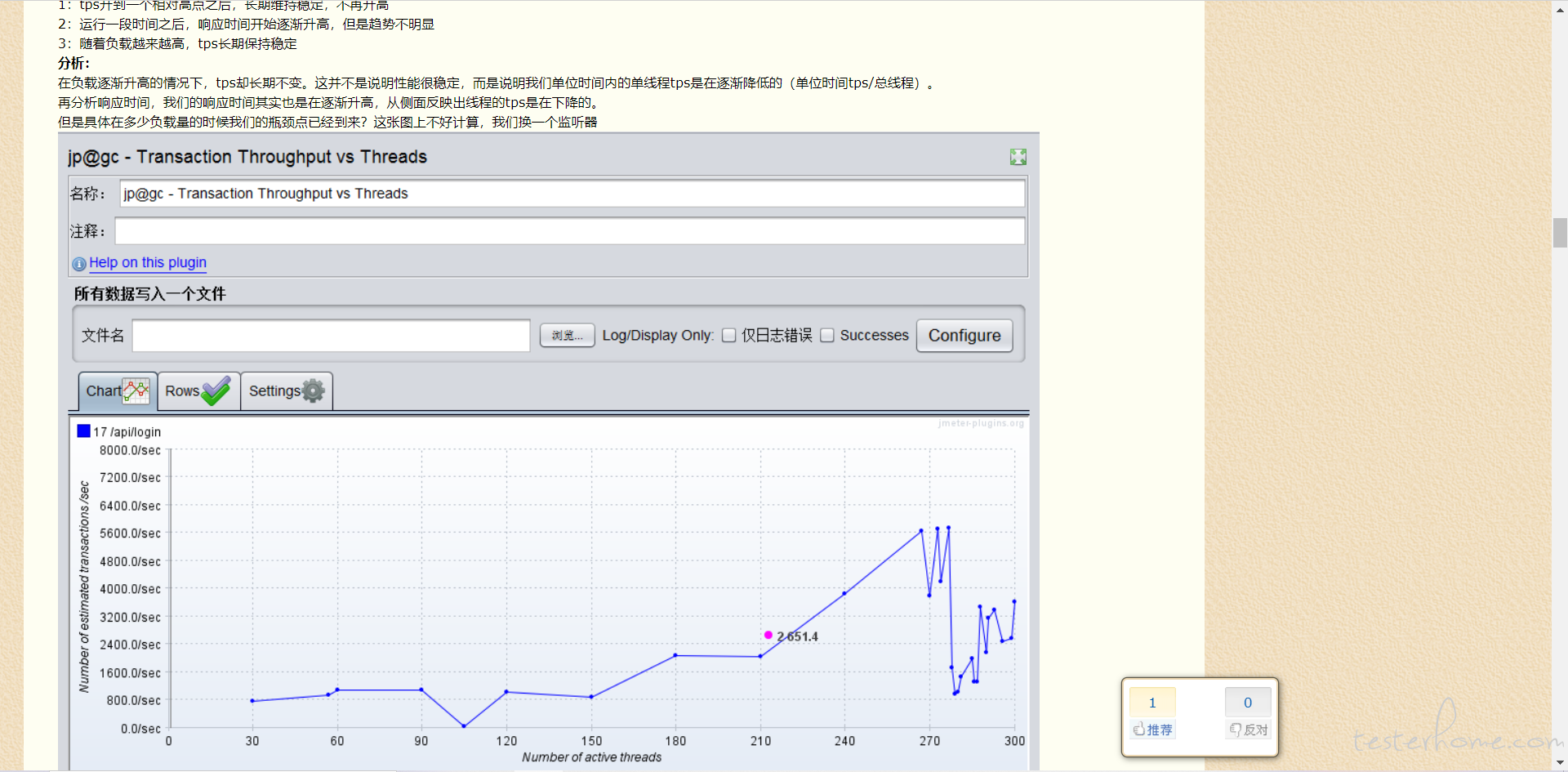
看到一篇博客,解释到:(https://www.cnblogs.com/Zfc-Cjk/p/12432471.html)
所以这里就是下面这个点就是瓶颈?
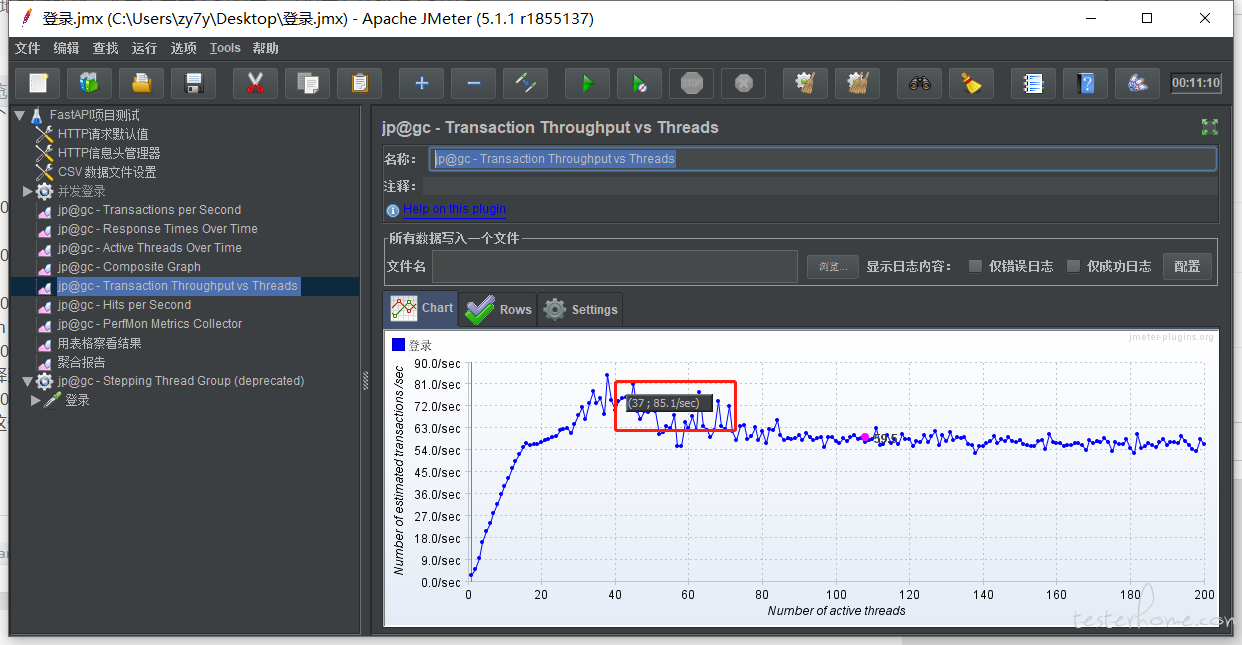
37 个线程,81.xxsec??? 这种可行嘛
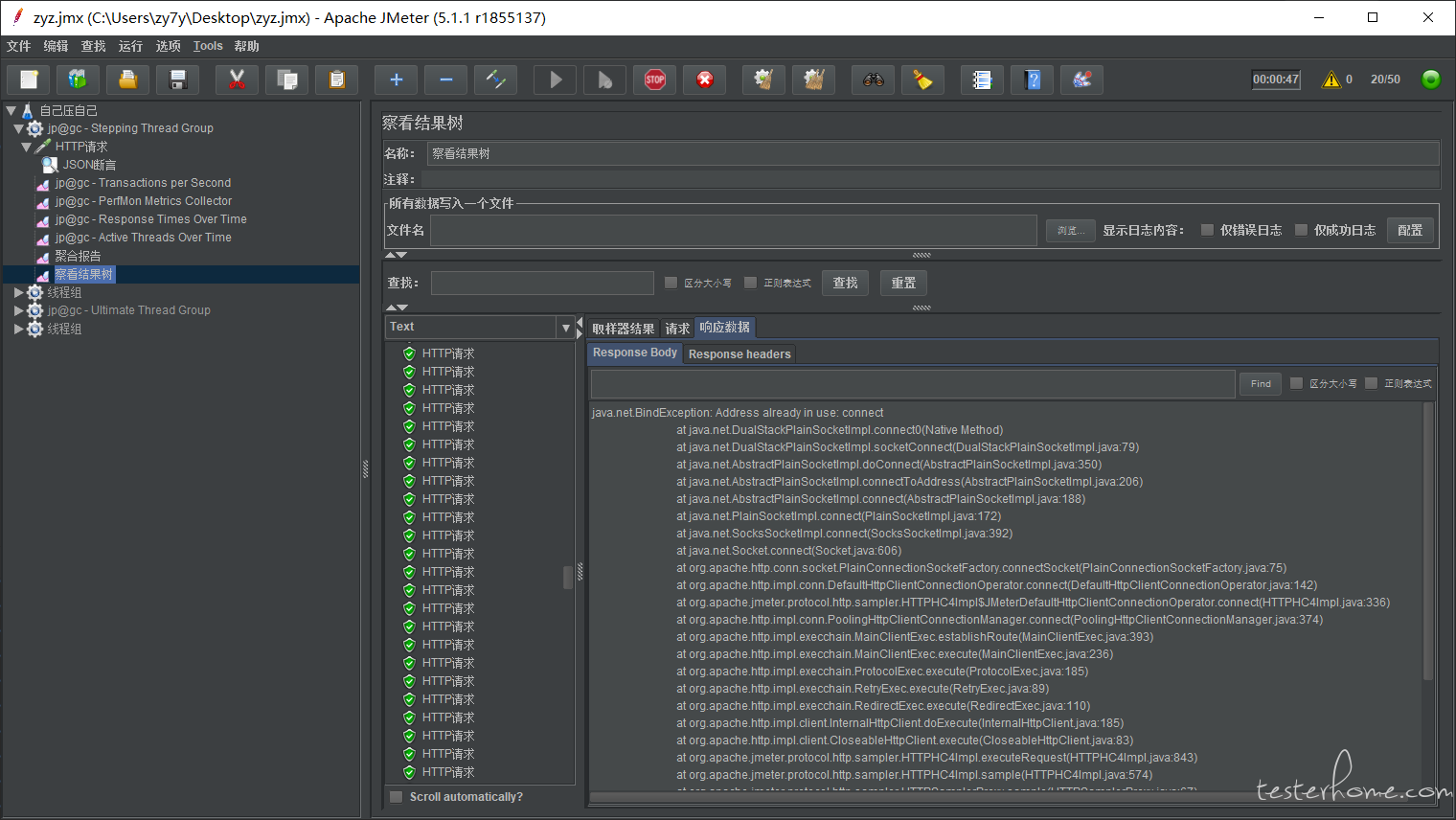
咋没人理你啊。。我也很难,实际跑的话,又有很多 Jmeter 的错误
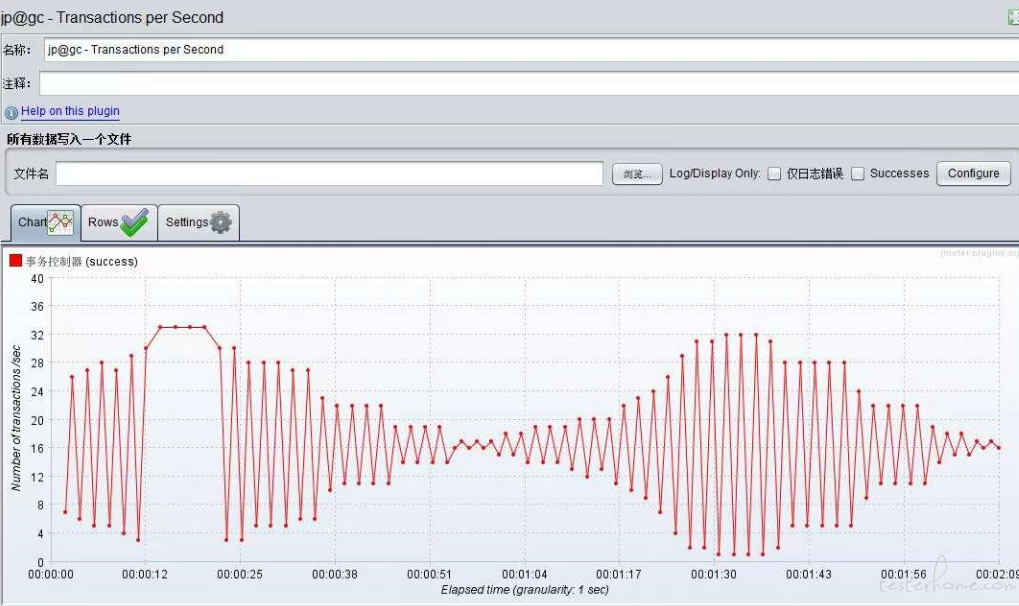
这种怎么分析?

那可以理解成 tps 的图需要事务控制器嘛,上面的图中,最大最优分别是怎么分析的业,这个应该是 TPs,对应的用户数计算是有什么公式嘛
不知道你这里的最大最优定义是什么?先定个准确定义?
比如响应速度 95% 在 3s 内,且没有引发 fail,系统可在此压力下持续运行 15 分钟且保持稳定的性能表现时,对应的用户数/线程数?
如果单看 TPS 和响应速度指标,个人理解是:
持续增加线程数(压力),TPS 先是变大(程序在长期待命线程基础上增加临时帮忙的线程,所以会加大),然后稳定(达到了 jvm 线程数配置最大值/系统能抗住的最大值,不给加了/没法加了)。
响应时间先是稳定(因为每个线程压力没怎么变,只是线程总数增加获得性能提升),然后变大(线程数加不了了,但活还在增加。来不及立即处理的只能有些排队等待下,所以响应时间长了)。
TPS 稳定且响应时间还没上升到不可接受程度(这个要看具体业务需要)时,可以承受的最大线程数应该就是这个系统的接口在这个配置下最大能承受的并发量了。至于反推用户数,要结合业务场景推算,毕竟 100 个用户在线可能分别在干完全不同的事情,只有极少数场景(比如秒杀)是都在干同一个事情,调用同一个接口。
PS:响应时间不要去看折线图,看不出啥的,因为响应时间是会在一个比较大的范围内波动的,几秒内有可能有的响应速度 3s(可能进了队列等待),也可能 1s(刚好没进入队列直接开始处理),折线图看起来就是一堆线混在一起。要看总体统计数据,95% 响应时间多少,50% 响应时间多少。
PPS:楼主从头到尾都没提及业务场景,所以我也只能顺着下去了纯技术了。实际还得根据业务场景来,比如是否会有固定串行事务、实际上高压力时各接口调用量占比如何等,对应调整压测策略和要观察的数据。
感谢回复,本意是想找出当前系统的最大承载用户数,因为之前一个项目出现了服务器宕机的事故,关于指标并没有明确,个人打算使用业界指标响应时间 2/5/8,至于 jvm(指的是 jmeter 的 Java 环境中的 jvm?),关于错误率 我觉得 98% 就好,其实我不明白的是 最优的 tps/最大 tps 如何看,周末再一个群里交流得到下方结果,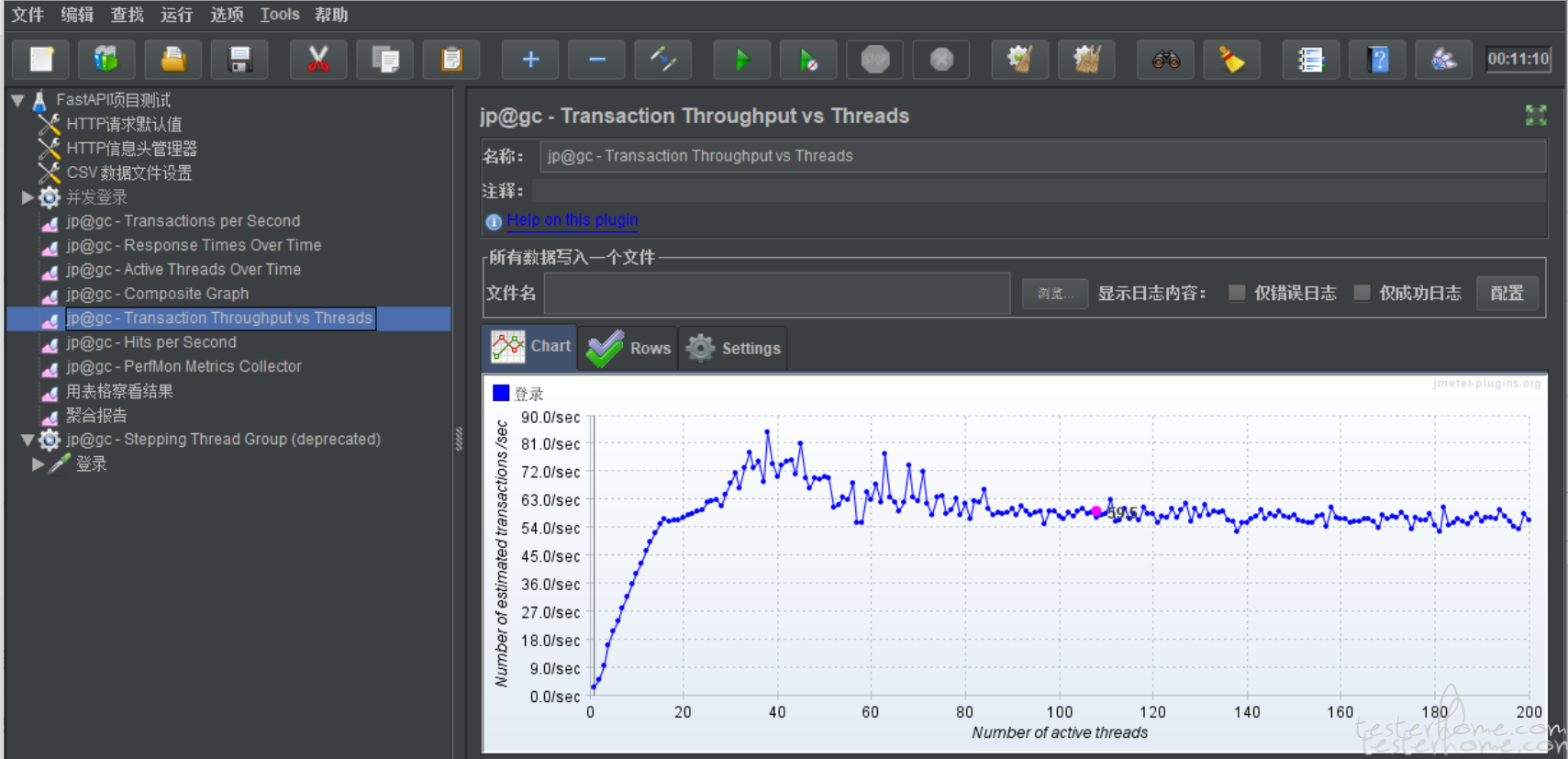
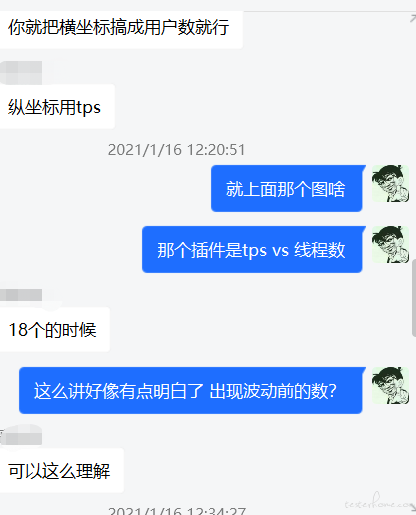
假设这种情况下响应时间满足,错误率为 0,内存占用/cpu/磁盘合理 这里说的 18 成立嘛,那对应着的最优 tps 就是 60?
看了半天。。不知道咋回你,建议问问题拿一个线程组的结果来问,这看起来太费劲了,一堆都是 tps 的图。如果想直接找下性能瓶颈可以参考下https://testerhome.com/articles/20773