本话题系列文章整理自 PingCAP Infra Meetup 第 26 期刘奇分享的《深度探索分布式系统测试》议题现场实录。文章较长,为方便大家阅读,会分为上中下三篇,本文为下篇。
-接中篇-
ScyllaDB 有一个开源的东西,是专门用来给文件系统做 Failure Injection 的, 名字叫做 CharybdeFS。如果你想测试你的系统,就是文件系统在哪不断出问题,比如说写磁盘失败了,驱动程序分配内存失败了,文件已经存在等等,它都可以测模拟出来。
CharybdeFS: A new fault-injecting file system for software testing
Simulate the following errors:
- disk IO error (EIO)
- driver out of memory error (ENOMEM)
- file already exists (EEXIST)
- disk quota exceeded (EDQUOT) 再来看看 Cloudera,下图是整个 Cloudera 的一个 Failure Injection 的结构。
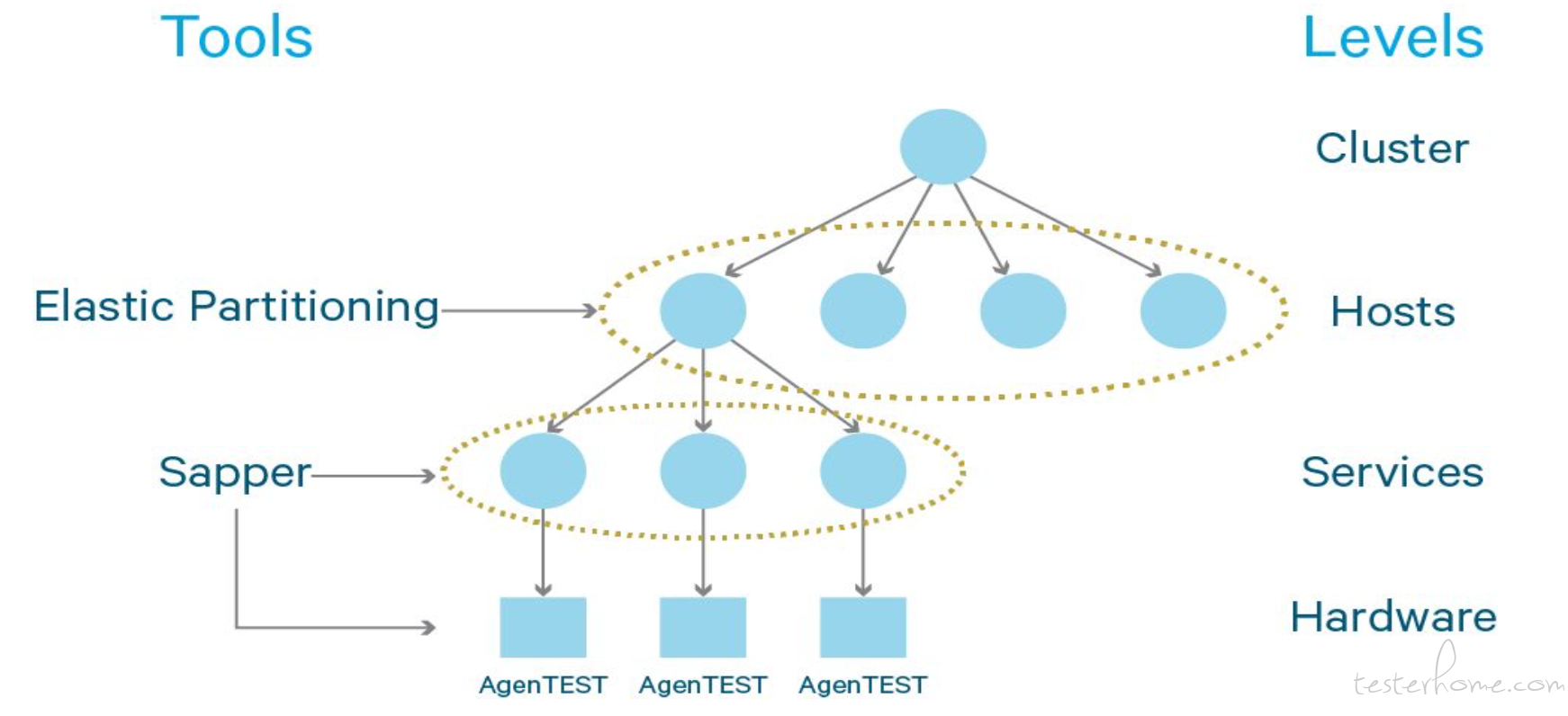
一边是 Tools,一边是它的整个的 Level 划分。比如说整个 Cluster, Cluster 上面有很多 Host,Host 上面又跑了各种 Service,整个系统主要用于测试 HDFS, HDFS 也是很努力的在做有效的测试。然后每个机器上部署一个 AgenTEST,就用来注射那些可能出现的错误。
看一下它们作用有多强大。
Cloudera: Simulate the following errors:
- Packets loss/corrupt/reorder/duplicate/delay
- Bandwidth limit: Limit the network bandwidth for the specified address and port.
- DNSFail: Apply an injection to let the DNS fail.
- FLOOD: Starts a DoS attack on the specified port.
- BLOCK: Blocks all the packets directed to 10.0.0.0/8 (used internally by EC2).
- SIGSTOP: Pause a given process in its current state.
- BurnCPU/BurnIO/FillDISK/RONLY/FIllMEM/CorruptHDFS
- HANG: Hang a host running a fork bomb.
- PANIC: Force a kernel panic.
- Suicide: Shut down the machine.
数据包是可以丢的,可以坏的,可以 reorder 的,比如说你发一个 A,再发一个 B,它可以给你 reorder,变成先发了 B 再发了 A,然后看你应用程序有没有正确的处理这种行为。接着发完一次后面再给你重发,然后可以延迟,这个就比较简单。目前这个里面的大部分,TiKV 都有实现,还有带宽的限制,就比如说把你带宽压缩成 1M。以前我们遇到一个问题很有意思,发现有人把文件存到 Redis 里面,但 Redis 是带多个用户共享的,一个用户就能把整个 Redis 带宽给打满了,这样其他人的带宽就很卡,那这种很卡的时候 Redis 可能出现的行为是什么呢?我们并不需要一个用户真的去把它打满,只要用这种工具,瞬间就能出现我把你的带宽限制到原来的 1%,假设别人在跟你抢带宽,你的程序行为是什么?马上就能出来,也不需要配很复杂的环境。这极大的提高了测试效率,同时能测试到很多 corner case。
然后 DNS fail。那 DNS fail 会有什么样的结果?有测过吗?可能都没有想过这个问题,但是在一个真正的分布式系统里面,每一点都是有可能出错的。还有 FLOOD,假设你现在被攻击了,整个系统的行为是什么样的?然后一不小心被这个 IP table 给 block 了,该怎么办。这种情况我们确实出现过。我们一上来并发,两万个连接一打出去,然后发现大部分都连不上,后来一看 IP table 自动启用了一个机制,然后把你们都 block。当然我们后面查了半个小时左右,才把问题查出来。但这种实际上应该是在最开始设计的时候就应该考虑的东西。
如果你的进程被暂停了,比如说大家在云上跑在 VM 里面,整个 VM 为了升级,先把你整个暂停了,升级完之后再把你恢复的时候会怎么样?那简单来讲,就是如果假设你程序是有 GC 的,GC 现在把我们的程序卡了五秒,程序行为是正常的吗?五十秒呢?这个很有意思的就是,BurnCPU,就是再写一个程序,把 CPU 全占了,然后让你这个现在的程序只能使用一小部分的 CPU 的时候,你程序的行为是不是正常的。正常来讲,你可能说我 CPU 不是瓶颈啊,我瓶颈在 IO,当别人跟你抢 CPU,把你这个 CPU 压的很低的时候,到 CPU 是瓶颈的时候,正常你的程序的这个行为是不是正常的?还有 IO,跟你抢读的资源,跟你抢写的资源,然后 filedisk 把磁盘写满,写的空间很少。比如说对数据库而言,你创建你的 redo log 的时候,都已经满了会怎么样?然后我突然把磁盘设为只读,就你突然一个写入会出错,但是你接下来正常的读写行为是不是对的?很典型的一个例子,如果一个数据库你现在写入,磁盘满了,那外面读请求是否就能正常响应。 Fill memory,就是瞬间把这个 memory 给压缩下来,让你下次 malloc 的时候可能分布不到内存。这个就和业务比较相关了,就是破坏 HDFS 的文件。其它的就是 Hang、Panic,然后还有自杀,直接关掉机器,整个系统的行为是什么样的?
现在比较痛苦的一点是大家各自为政,每一家都做一套,但是没有办法做成一个通用的东西给所有的人去用。包括我们自己也做了一套,但是确实没有办法和其他的语言之间去 share,最早提到的那个 libfu 库实际上是在 C 语言写的,那所有 C 相关的都可以去 call 那个库。
Distributed testing
- Namazu
- ZooKeeper:
- Found ZOOKEEPER-2212, ZOOKEEPER-2080 (race): (blog article)
- Etcd:
- Found etcdctl bug #3517 (timing specification), fixed in #3530. The fix also resulted a hint of #3611, Reproduced flaky tests {#4006, #4039}
- YARN: Found YARN-4301 (fault tolerance), Reproduced flaky tests{1978, 4168, 4543, 4548, 4556}
- ZooKeeper:
然后 Namazu。大家肯定觉得 ZooKeeper 很稳定呀, Facebook 在用、阿里在用、京东在用。大家都觉得这个东西也是很稳定的,直到这个工具出现了,然后轻轻松松就找到 bug 了,所有的大家认为的这种特别稳定的系统,其实 bug 都还挺多的,这是一个毁三观的事情,就是你觉得东西都很稳定,都很 stable,其实不是的。从上面,我们能看到 Namazu 找到的 Etcd 的几个 bug,然后 YARN 的几个 bug,其实还有一些别的。
How TiKV use namazu
- Use nmz container / non-container mode to disturb cluster.
- Run container mode in CI for each commit. (1 hour)
- Run non-container mode for a stable version. (1 week+)
- Use extreme policy for process inspector
- Pick up some processes and execute them with SCHED_RR scheduler. others are executed with SCHED_BATCH scheduler
- Use [0, 30s] delay for filesystem inspector
接下来说一下 TiKV 用 Namazu 的一些经验。因为我们曾经在系统上、在云上面出现过一次写入磁盘花了五十几秒才完成的情况,所以我们需要专门的工具模拟这个磁盘的抖动。有时候一次写入可能确实耗时比较久,那这种时候是不是 OK 的。大家如果能把这种东西统统用上,我觉得还能为很多开源系统找出一堆 bug。
稍微介绍一下我们现在运行的基本策略,比如说我们会用 0 到 30 秒的这个 delay(就是每一次你往文件系统的交互,比如说读或者写,那么我们会给你产生随机的 0 到 30 秒的 delay ),但我们正常应该还是需要去测三十秒到几分钟的延迟的情况,是否会让整个系统崩掉了。
How TiKV simulate network transport
- Drop/Delay messages randomly
- Isolate Node
- Partition [1, 2, 3, 4, 5] -> [1, 2, 3] + [4, 5]
- Out of order messages
- Filter messages
- Duplicate and send redundant messages
怎么模拟网络呢?假设你有网络,里面有五台机器,那我现在想做一个脑裂怎么做?不能靠拔网线对吧?比如在 TiKV 的测试框架中,我们就可以直接通过 API 把 5 个节点脑裂成两部分,让 1, 2, 3 号节点互相联通,4, 5 号节点也能联通,这两个分区彼此是隔离的,非常的方便。其实原理很简单,这种情况是用程序自己去模拟,假如是你发的包,自动给你丢掉,或者直接告诉你 unreachable,那这个时候你就知道这个网络就脑裂了,然后你怎么做?就是只允许特定类型的消息进来,把其他的都丢掉,这样一来你可以保证有些 bug 是必然重现的。这个框架给了我们极大的信心用来模拟并重现各种 corner case,确保这些 corner case 在单元测试中每次都能被覆盖到。
How to test Rocksdb
- Treat storage as a black box.
- Three steps(7*24):
- Fill data, Random kill -9
- Restart
- Consistent check.
- Results:
- Found 2 bugs. Both fixed
然后说说我们怎么测 RocksDB。 RocksDB 在大家印象中是很稳定的,但我们最近发现了两个 bug。测的方法是这样的:我们往 RocksDB 里面填数据,然后随机的一段时间去把它 kill 掉,kill 掉之后我们重启,重新启动之后去检测我们刚才 fail 的 data 是不是一致的,然后我们发现两个可能造成数据丢失的 bug,但是官方的响应速度非常快,几天就都 fix 了。可是大家普遍运行的是这么 stable 的系统,为什么还会这么容易找到 bug?就说这个测试,如果是一直有这个测试的 cover,那么这两个 bug 可能很快就能够被发现。
这是我们一个基本的,也就是当成一个纯黑盒的测。大家在测数据库的时候,基本也是当黑盒测。比如说 MySQL 写入数据,kill 掉,比如说我 commit 一个事务,数据库告诉我们 commit 成功,我把数据库 kill 掉,我再去查我刚才提交的数据一样能查到。这是一个正常的行为,如果查不到,说明整个系统有问题。
More tools
american fuzzy lop

其实还有一些更加先进的工具,大家平时觉得特别稳定的东西,都被摧残的不行。Nginx 、NGPD、tcpdump 、LibreOffice ,如果有用 Linux 的同学可能知道,还有 Flash、sqlite。这个东西一出来,当时大家很兴奋,说怎么一下子找了这么多 bug,为什么以前那么稳定的系统这么不堪一击,会觉得这个东西它还挺智能的。就比如说你程序里面有个 if 分支,它是这样的,假如你程序有一百条指令,它先从前面一直走,走到某条分支指令的时候,它是一直持续探索,一个分支走不下去,它会一直在这儿持续探索,再给你随机的输入,直到我探索进去了,我记下来了下次我知道我用这个输入可以进去特定的分支。那我可以再往下走,比如说你 if 分支进去之后里面还有 if ,那你传统手段可能探测不进去了但它可以,它记录一下,我这个可以进去,然后我重来,反正我继续输入这个,我再往里面走,一旦我探测到一个新的分支,我再记住,我再往里面走。所以它一出来的时候大家都说这个真厉害,一下发现这么多 bug。但最激动的不是这些人,最激动的是黑客,为什么?因为突然有很多栈溢出、堆溢出漏洞被发现了,然后就可以写一堆工具去攻击线上的这么多系统。所以很多的技术的推进在早期的时候是黑客做出来,但是他们的目的当然不一定是为了测试 bug,而是为了怎么黑一个系统进去,这是他们当时做的,所以这个工具也是非常强大、非常有意思的,大家可以拿去研究一下自己的系统。
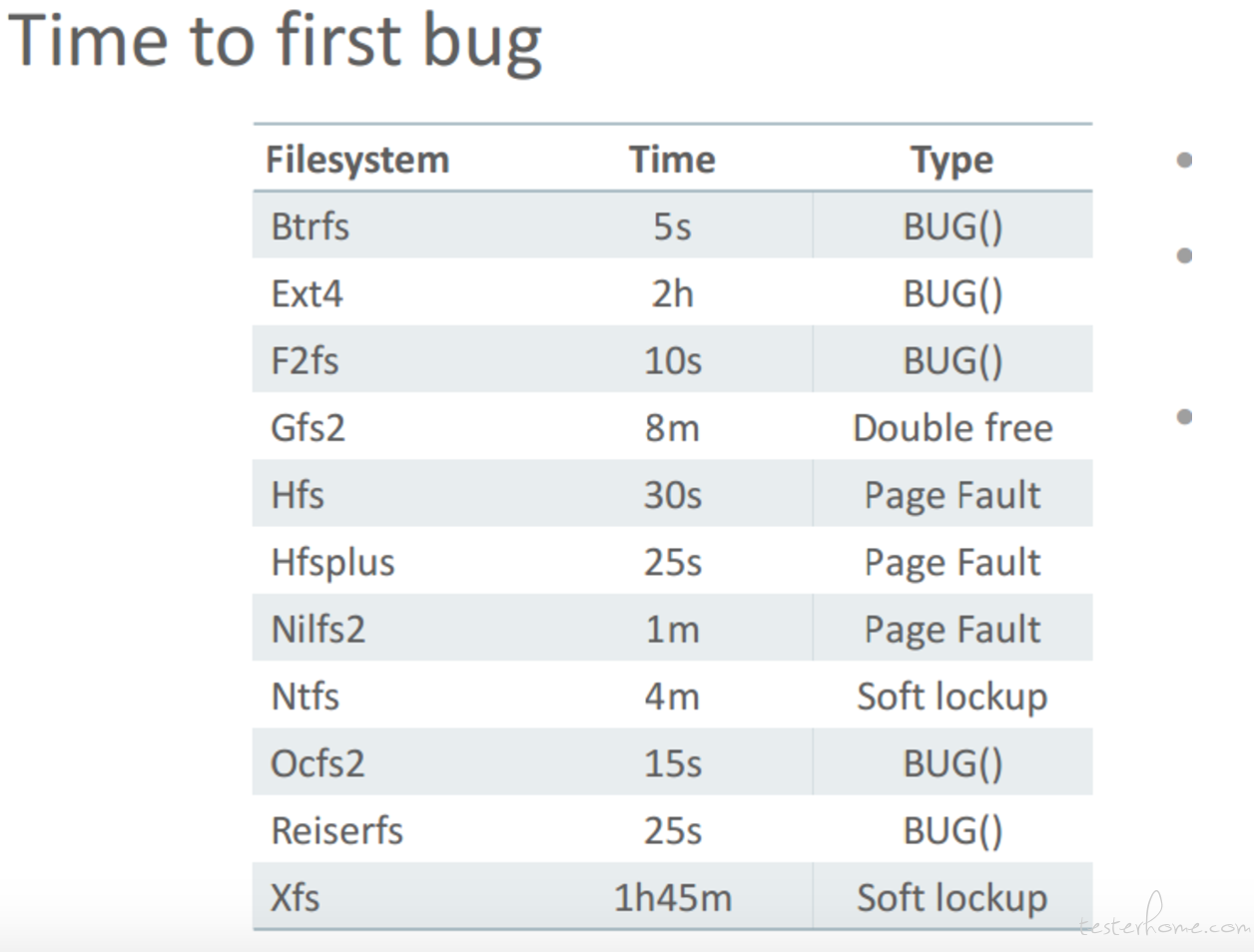
大家印象里面各种文件系统是很稳定的,可是当用 American fuzzy lop 来测试的时候,被惊呆了。 Btrfs 连 5 秒都没有坚持到就跪了,大家用的最多的 Ext4 是最坚挺的,也才抗了两个小时!!!
再来说说 Google,Google 怎么做测试对外讲的不多,最近 Chrome team 开源了他们的 Fuzz 测试工具 OSS-Fuzz,这个工具强大的地方在于自动化做的极好:
- 发现 bug 后自动创建 issue
- bug 解决后自动 verify 更惊人的是 OSS-Fuzz 集群一周可以跑 ~4 trillion test cases 更多细节大家可以看这篇文章:Announcing OSS-Fuzz: Continuous Fuzzing for Open Source Software
另外有些工具能让分布式系统开发人员的生活变得更美好一点。
Tracing tools may help you
- Google Dapper
- Zipkin
- OpenTracing
还有 Tracing,比如说我一个 query 过来,然后经过这么多层,经过这么多机器,然后在不同的地方,不同环节耗时多久,实际上这个在分布式系统里面,有个专门的东西做 Tracing ,就是 distribute tracing tools。它可以用一条线来表达你的请求在各个阶段耗时多长,如果有几段,那么分到几个机器,分别并行的时候好了多长时间。大体的结构是这样的:
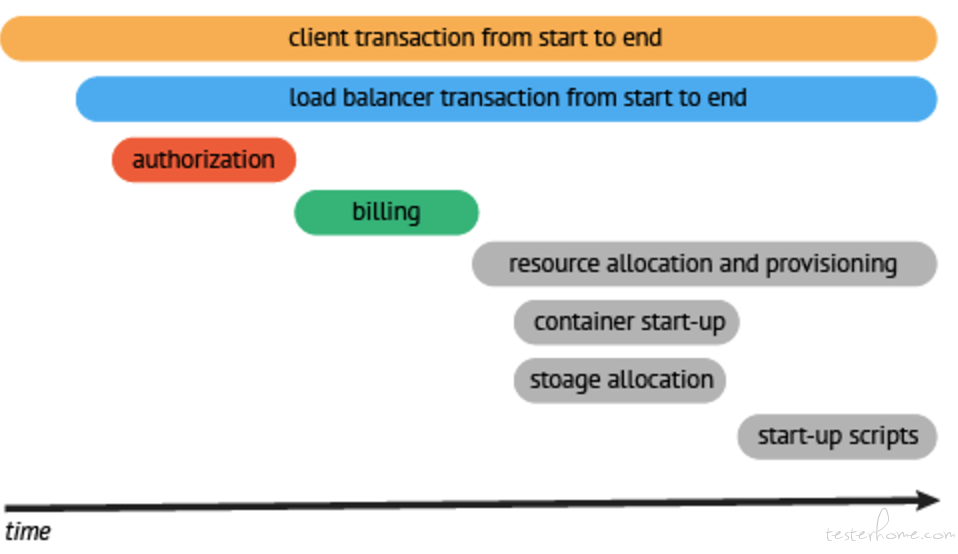
这里是一个具体的例子:

很清晰,一看就知道了,不用去看 log,这事其实一点也不新鲜,Google 十几年前就做了一个分布式追踪的工具。然后开源社区要做一个实现叫做 Zipkin,好像是 java 还是什么写的,又出了新的叫 OpenTracing,是 Go 写的。我们现在正准备上这个系统,用来追踪 TiDB 的请求在各个阶段的响应时间。
最后想说一下,大家研究系统发现 bug 多了之后,不要对系统就丧失了信心,毕竟 bug 一直在那里,只是从前没有发现,现在发现得多了,总体上新的测试方法让系统的质量比以前好了很多。好像有点超时了,先聊到这里吧,还有好多细节没法展开,下次再聊。
-本系列完结-