测试覆盖率 聊聊 Go 代码覆盖率技术与最佳实践
"聊点干货"
覆盖率技术基础
截止到 Go1.15.2 以前,关于覆盖率技术底层实现,以下知识点您应该知道:
go 语言采用的是插桩源码的形式,而不是待二进制执行时再去设置 breakpoints。这就导致了当前 go 的测试覆盖率收集技术,一定是侵入式的,会修改目标程序源码。曾经有同学会问,插过桩的二进制能不能放到线上,所以建议最好不要。
-
到底什么是"插桩"?这个问题很关键。大家可以任意找一个 go 文件,试试命令
go tool cover -mode=count -var=CoverageVariableName xxxx.go,看看输出的文件是什么?- 笔者以这个文件为例
https://github.com/qiniu/goc/blob/master/goc.go, 得到以下结果:
package main import "github.com/qiniu/goc/cmd" func main() {CoverageVariableName.Count[0]++; cmd.Execute() } var CoverageVariableName = struct { Count [1]uint32 Pos [3 * 1]uint32 NumStmt [1]uint16 } { Pos: [3 * 1]uint32{ 21, 23, 0x2000d, // [0] }, NumStmt: [1]uint16{ 1, // 0 }, }可以看到,执行完之后,源码里多了个
CoverageVariableName变量,其有三个比较关键的属性:-
Countuint32 数组,数组中每个元素代表相应基本块 (basic block) 被执行到的次数 -
Pos代表的各个基本块在源码文件中的位置,三个为一组。比如这里的21代表该基本块的起始行数,23代表结束行数,0x2000d比较有趣,其前 16 位代表结束列数,后 16 位代表起始列数。通过行和列能唯一确定一个点,而通过起始点和结束点,就能精确表达某基本块在源码文件中的物理范围 -
NumStmt代表相应基本块范围内有多少语句 (statement)
CoverageVariableName变量会在每个执行逻辑单元设置个计数器,比如CoverageVariableName.Count[0]++, 而这就是所谓插桩了。通过这个计数器能很方便的计算出这块代码是否被执行到,以及执行了多少次。相信大家一定见过表示 go 覆盖率结果的 coverprofile 数据,类似下面:
github.com/qiniu/goc/goc.go:21.13,23.2 1 1这里的内容就是通过类似上面的变量
CoverageVariableName得到。其基本语义为
"文件:起始行.起始列,结束行.结束列 该基本块中的语句数量 该基本块被执行到的次数" - 笔者以这个文件为例
依托于 go 语言官方强大的工具链,大家可以非常方便的做单测覆盖率收集与统计。但是集测/E2E 就不是那么方便了。不过好在我们现在有了https://github.com/qiniu/goc。
集测覆盖率收集利器 - Goc 原理
关于单测这块,深入 go 源码,我们会发现go test -cover命令会自动生成一个_testmain.go 文件。这个文件会 Import 各个插过桩的包,这样就可以直接读取插桩变量,从而计算测试覆盖率。实际上goc也是类似的原理 (PS: 关于为何不直接用go test -c -cover 方案,可以参考这里 我们是如何做 go 语言系统测试覆盖率收集的?
不过集测时,被测对象通常是完整产品,涉及到多个 long running 的后端服务。所以 goc 在设计上会自动化会给每个服务注入 HTTP API,同时通过服务注册中心goc server来管理所有被测服务。如此的话,就可以在运行时,通过命令goc profile实时获取整个集群的覆盖率结果,当真非常方便。
整体架构参见:
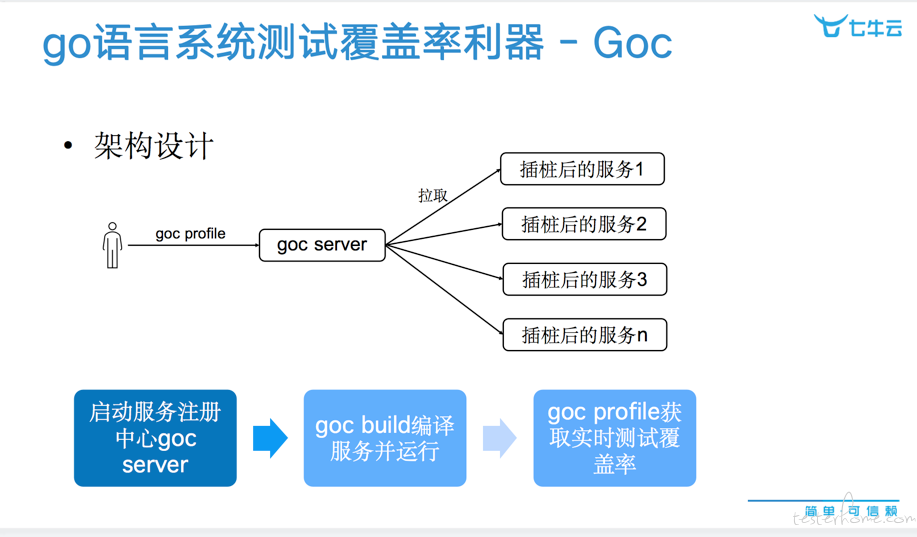
代码覆盖率的最佳实践
技术需要为企业价值服务,不然就是在耍流氓。可以看到,目前玩覆盖率的,主要有以下几个方向:
度量 - 深度度量,各种包,文件,方法度量,都属于该体系。其背后的价值在于反馈与发现。反馈测试水平如何,发现不足或风险并予以提高。比如常见的作为流水线准入标准,发布门禁等等。度量是基础,但不能止步于数据。覆盖率的终极目标,是提高测试覆盖率,尤其是自动化场景的覆盖率,并一以贯之。所以基于此,业界我们看到,做的比较有价值的落地形态是增量覆盖率的度量。goc diff 结合 Prow 平台也落地了类似的能力,如果您内部也使用 Kubernetes,不妨尝试一下。当然同类型的比较知名的商业化服务,也有 CodeCov/Coveralls 等,不过目前她们多数是局限在单测领域。
精准测试方向 - 这是个很大的方向,其背后的价值逻辑比较清晰,就是建立业务到代码的双向反馈,用于提升测试行为的精准高效。但这里其实含有悖论,懂代码的同学,大概率不需要无脑反馈;不能深入到代码的同学,你给代码级别的反馈,也效果不大。所以这里落地姿势很重要。目前业界没还看到有比较好的实践例子,大部分都是解决特定场景下的问题,有一定的局限。
而相较于落地方向,作为广大研发同学,下面这些最佳实践可能对您更有价值:
- 高代码覆盖率并不能保证高产品质量,但低代码覆盖率一定说明大部分逻辑没有被自动化测到。后者通常会增加问题遗留到线上的风险,当引起注意。
- 没有普适的针对所有产品的严格覆盖率标准。实际上这更应该是业务或技术负责人基于自己的领域知识,代码模块的重要程度,修改频率等等因素,自行在团队中确定标准,并推动成为团队共识。
- 低代码覆盖率并不可怕,能够主动去分析未被覆盖到的部分,并评估风险是否可接受,会更加有意义。实际上笔者认为,只要这一次的提交比上一次要好,都是值得鼓励的。
谷歌有篇博客 (见参考资料) 提到,其经验表明,重视代码覆盖率的团队通常会更加容易培养卓越工程师文化,因为这些团队在设计产品之初就会考虑可测性问题,以便能更轻松的实现测试目标。而这些措施反过来会促使工程师编写更高质量的代码,更注重模块化。
最后,欢迎加入七牛云 Goc 交流群,我们一起聊聊 goc,聊聊研发效能那些事。
更多工程效能、测开技术讨论可以关注公账号: 大卡尔
参考资料