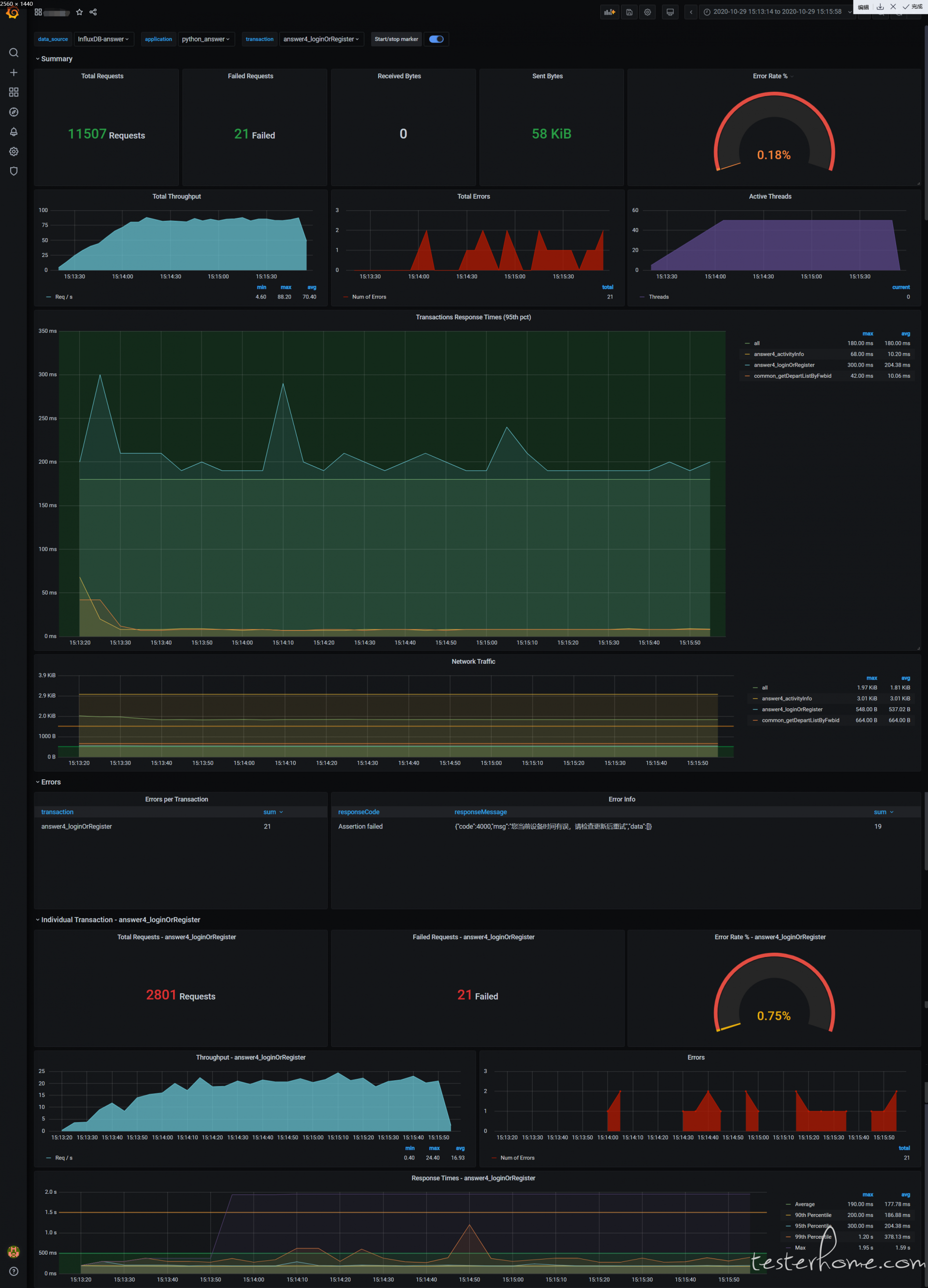
locust 本身提供的测试报告勉强可以用,但是也有很多不方便的地方,于是自己搭建一个测试报告,下面是测试报告的效果图
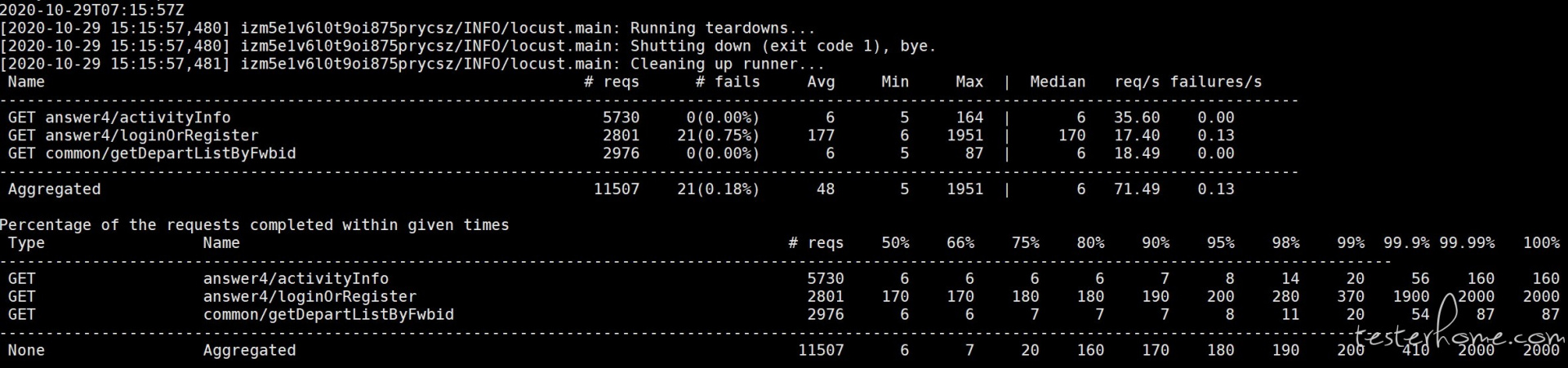
下面是 locust 输出的测试结果,可以看到和图形报告展示的数据是一致的
下面是搭建过程,(省去了 locust 和 grafana 安装过程,安装比较简单,可自行百度)
一 locust 测试脚本,注意事项
a.配置写入 csv 文件时间间隔,在测试类中增加
locust.stats.CSV_STATS_INTERVAL_SEC = 5 # 配置写入csv文件频率为5秒,默认是2秒
b.启动命令
locust -f test_answer.py -u 50 --csv=fileName --csv-full-history --headless -t10m
--csv=fileName中的fileName是生成文件名的前缀
二 influxDb 配置
a.启动 influxdb
后台启动:nohup influxd -config /etc/influxdb/influxdb.conf &
b. 进入 influxdb 数据库
进入终端:influx -host 127.0.0.1 -port 8096 可以知道端口和 ip,不不指定默认是本机 8086 端口
如果需要修改端口,在/etc/influxdb/influxdb.conf 修改端口
c.创建数据库
create database databaseName
show databases
d.进入数据库
use databaseName
e.查看表
show measurements
三 grafana 配置
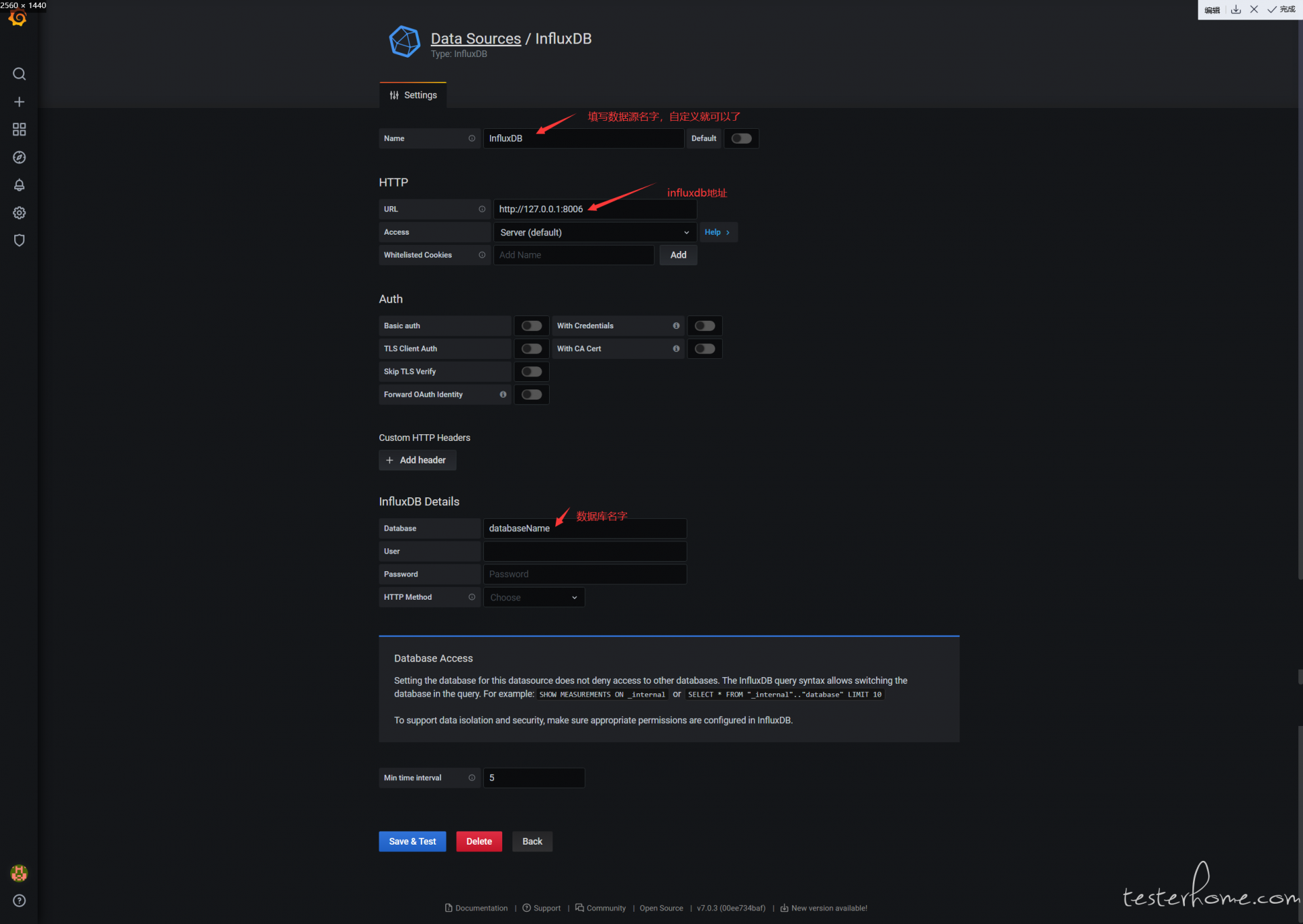
a.配置数据源
按图配置就可以了,最下面还有个 Min time interval 填 5 不要忘了
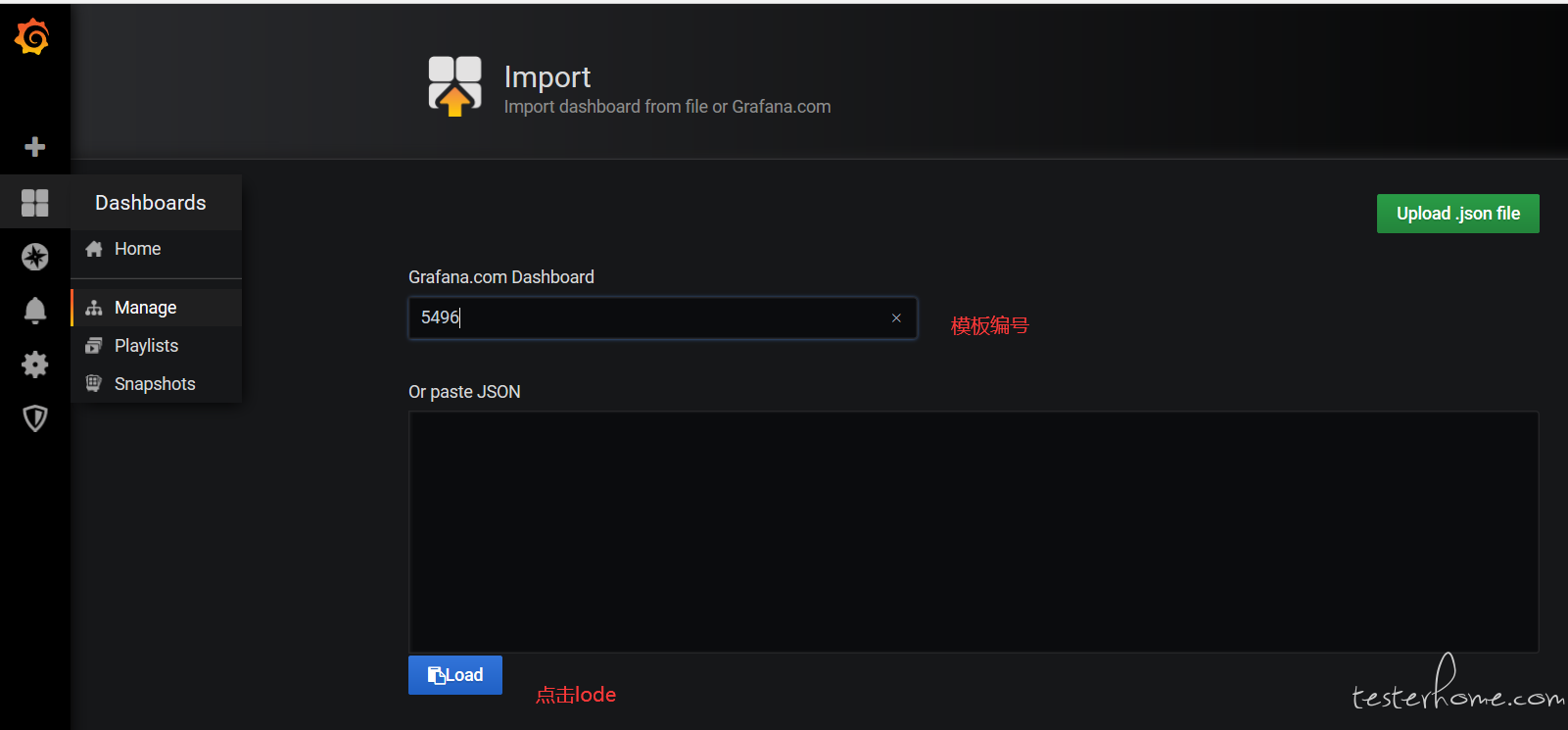
b. 配置仪表模板
官方模板地址:https://grafana.com/grafana/dashboards
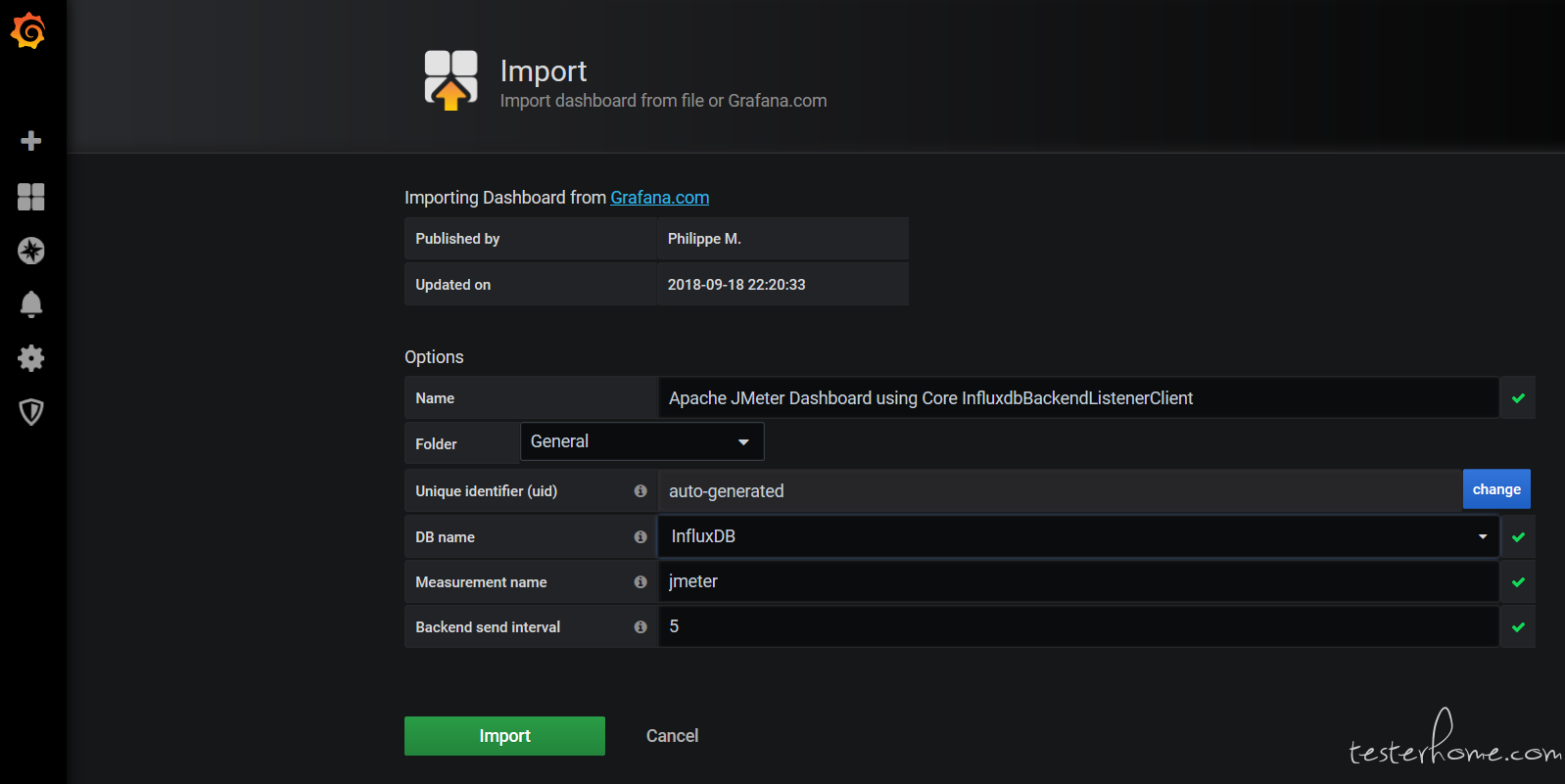
我们选 5496 模板,点击 lode 下载
然后选择数据源等配置点击 import 按钮
四 将 locust 测试数据写入 influxDB
需要注意的是 influxdb 的包和 locust 的包不兼容,建议 influxdb 在虚拟环境中运行,可以避免这个问题
脚本启动命令:python3 csv_to_influxdb.py -h "127.0.0.1" -p 8086 -db "database" -f "fileName _failures.csv" -s "fileName _stats_history.csv" -a "application" -m "measurement"
import subprocess, copy, time, threading, csv, click
from datetime import datetime
from influxdb import InfluxDBClient
@click.command()
@click.option('--host', '-h', default='127.0.0.1', help="influxdb地址")
@click.option('--port', '-p', default=8086, type=int, help="influxdb端口")
@click.option('--database', '-db', required=True, help="influxdb数据库名")
@click.option('--m', '-m', required=True, help="influxdb表名 measurement")
@click.option('--fp', '-f', required=True, help="locust的failures_csv_file_path失败结果文件路径")
@click.option('--sp', '-s', required=True, help="locust的status_csv_file_path测试结果文件路径")
@click.option('--application', '-a', required=True, help="测试标签,在数据库中区分不同的测试计划")
def run(host, port, database, m, fp, sp, application):
click.echo('host=%s,port=%s, database=%s, m=%s, fp=%s, sp=%s, application=%s' % (host, port, database, m, fp, sp, application))
client = InfluxDBClient(host=host, port=port, database=database)
light = threading.Thread(target=stats_history_to_influxdb, args=(client, m, sp, application))
light.start()
car1 = threading.Thread(target=failures_to_influxdb, args=(m, fp, application))
car1.start()
lock = threading.Lock()
body = [] # 测试数据容器
stats_history_count_dict = {} # 请求总数的容器
stats_history_failures_count_dict = {} # 请求明细中的失败总数容器
failures_count_dict = {}
'''
failures_count_dict使用来存放失败总数的容器,由于locust写入的*_failures.csv文件是覆盖写入的,所以这个文件使用csv库读取,每隔5秒读取一次
locust同一个请求的同一个失败的失败数是累计的,所以这里将每个错误信息分别保存,后面计算本5秒钟每一个api的每一个失败的失败数
failures_count_dict = {
'request_name': { # 接口层
'response_msg': { # responsemsg层
'url': 1.0
}
}
}
'''
def body_append(value):
'''
往body里面写值
:param value:
:return:
'''
lock.acquire() # 加锁
global body
body.append(value)
lock.release() # 释放锁
def body_clear():
'''
清空body
:return:
'''
lock.acquire() # 加锁
global body
body.clear()
lock.release() # 释放锁
def stats_history_to_influxdb(client, measurement, status_csv_file_path, application):
'''
读取locust测试结果并写入influxdb
1.使用tail读取stats_history.csv文件,正因为使用了tail命令,所以该脚本只能在linux环境下运行
2.判断是否是首行,是则跳过
3.从csv文件取出请求总数,减去容器中存放的上次请求总数,然后将新值赋值给stats_history_count_dict容器,如果count是负数则说明容器里面有上一次的测试数据,那么直接存csv文件里面的count,并将容器清空
4.从csv文件取出失败数,减去容器中存放的上次失败数,然后将新值赋值给stats_history_failures_count_dict容器,如果count是负数则说明容器里面有上一次的测试数据,那么直接存csv文件里面的count,并将容器清空
5.将处理好的数据存入body
a.如果transaction是Aggregated,则额外增加一条transaction等于internal的数据
b.如果failures_count > 0,则额外增加一条statut等于ko的数据
6.最后将body存入influxdb
:return:
'''
p = subprocess.Popen('tail -Fn 0 %s' % status_csv_file_path, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
for line in iter(p.stdout.readline, b''):
click.echo('m=%s, fp=%s, application=%s' % (measurement, status_csv_file_path, application))
line = line.rstrip().decode('utf8')
data_list = line.split(',')
# 判断是否是首行和无效的Aggregated
if data_list[0][1:-1].isnumeric() and data_list[7].isnumeric():
name = data_list[3][1:-1].replace('/', '_')
# 判断容器里面有没有count,有就用本次的count减去上次的count
this_time_count = float(data_list[18])
if stats_history_count_dict.get(name):
count = this_time_count - stats_history_count_dict.get(name)
# count小于0说明是重新开始测试,需要清空count_dict
if count < 0:
count = this_time_count
stats_history_count_dict.clear()
else:
count = this_time_count
# 给count容器赋值
stats_history_count_dict.update({name: this_time_count})
# 判断容器里面有没有failures_count,有就用本次的count减去上次的count
this_time_failures_count = float(data_list[19])
failures_count = 0.0
if this_time_failures_count > 0: # 如果有error数据就走下面的处理逻辑
if stats_history_failures_count_dict.get(name):
failures_count = this_time_failures_count - stats_history_failures_count_dict.get(name)
# failures_count小于0说明重新开始测试,需要清空stats_history_failures_count_dict
if failures_count < 0:
failures_count = this_time_failures_count
stats_history_failures_count_dict.clear()
else:
failures_count = this_time_failures_count
# 给stats_history_failures_count_dict容器赋值
stats_history_failures_count_dict.update({name: this_time_failures_count})
test_data = {
"measurement": measurement,
"time": int(data_list[0][1:-1]) * 1000000000,
"tags": {
"application": application,
"responseCode": None,
"responseMessage": None,
"statut": 'ok' if name != 'Aggregated' else 'all',
"transaction": name if name != 'Aggregated' else 'all'
},
"fields": {
'avg': float(data_list[21]),
'count': count,
'countError': failures_count,
'endedT': float(data_list[1][1:-1]),
'hit': float(data_list[18]),
'max': float(data_list[23]),
'maxAT': float(data_list[1][1:-1]),
'meanAT': None,
'min': float(data_list[22]),
'minAT': None,
'pct90.0': float(data_list[10]),
'pct95.0': float(data_list[11]),
'pct99.0': float(data_list[13]),
'rb': None,
'sb': float(data_list[24]),
'startedT': float(data_list[1][1:-1])
}
}
# 封装测试结果
body_append(test_data)
test_data_detailed = copy.deepcopy(body)[len(body) - 1]
# 判断是否是Aggregated合计数据,如果是就插入一条internal数据,然后写入influxdb
if name == 'Aggregated':
# 封装internal,一组数据的最后一个,直接写入influxdb,并清空body
test_data_detailed['tags']['transaction'] = 'internal'
test_data_detailed['tags']['statut'] = None
test_data_detailed['fields']['avg'] = None
test_data_detailed['fields']['count'] = None
test_data_detailed['fields']['hit'] = None
test_data_detailed['fields']['max'] = None
test_data_detailed['fields']['pct90.0'] = None
test_data_detailed['fields']['pct95.0'] = None
test_data_detailed['fields']['pct99.0'] = None
test_data_detailed['fields']['sb'] = None
body_append(test_data_detailed)
client.write_points(body)
body_clear()
else: # 封装单个请求的5秒汇总数据
test_data_detailed['tags']['statut'] = 'all'
body_append(test_data_detailed)
if name != 'Aggregated' and failures_count > 0:
# 写入error数据
test_data_error = copy.deepcopy(test_data_detailed)
test_data_error['tags']['statut'] = 'ko'
test_data_error['fields']['count'] = failures_count
body_append(test_data_error)
def failures_to_influxdb(measurement, failures_csv_file_path, application):
'''
读取locust断言失败的结果,并写入influxdb
1.清除*_failures.csv中的数据,不清楚的话一开始测试就会直接把上次测试的结果写入数据库
2.开始读取*_failures.csv,第一行是表头,直接if index跳过
3.从csv文件取出失败数,减去容器中存放的上次失败数,然后将新值赋值给容器,如果count是负数则说明容器里面有上一次的测试数据,那么直接存csv文件里面的count,并将容器清空
4.将处理好的数据存入body,等待stats_history_to_influxdb方法中写入influxdb
:return:
'''
try:
open('answer_failures.csv', "r+").truncate() # 清空文件
except FileNotFoundError:
print("没有文件!")
while True:
click.echo('m=%s, fp=%s, application=%s' % (measurement, failures_csv_file_path, application))
try:
answer_failures = csv.reader(open(failures_csv_file_path, 'r', encoding='UTF-8-sig'))
except FileNotFoundError:
time.sleep(5)
continue
for index, line in enumerate(answer_failures):
# 判断是否是首行和无效的Aggregated
if index:
# 取出transaction和count
name = line[1].replace('/', '_') # name里面不能有/,如果有这里会替换成_
this_time_count = float(line[3])
# 格式化Error, 将url和responseMsg,拆分开
error_list = line[2].split(' response ')
# 算出每一次的count数
if failures_count_dict.get(name, {}).get(error_list[1], {}).get(error_list[0], None):
count = this_time_count - failures_count_dict.get(name, {}).get(error_list[1], {}).get(error_list[0], None)
else:
count = this_time_count
# 判断是否有新增的error
if count > 0:
# 给count容器赋值
# failures_count_dict.update({name: {error_list[1]: {error_list[0]: this_time_count, 'count': count}}})
if failures_count_dict.get(name):
if failures_count_dict.get(name, {}).get(error_list[1], {}):
if failures_count_dict.get(name, {}).get(error_list[1], {}).get(error_list[0], None):
failures_count_dict[name][error_list[1]][error_list[0]] = this_time_count
else:
failures_count_dict[name][error_list[1]].update({error_list[0]: this_time_count})
else:
failures_count_dict[name].update({error_list[1]: {error_list[0]: this_time_count}})
else:
failures_count_dict.update({name: {error_list[1]: {error_list[0]: this_time_count}}})
test_data = {
"measurement": measurement,
"time": datetime.utcnow().isoformat("T"),
"tags": {
"statut": error_list[0], # 将url存放在status字段
"application": application,
"responseCode": "Assertion failed",
"responseMessage": error_list[1],
"transaction": name
},
"fields": {
'count': count,
}
}
# 封装测试结果
body_append(test_data)
elif count < 0:
failures_count_dict.clear()
break
time.sleep(5)
if __name__ == '__main__':
run()
「原创声明:保留所有权利,禁止转载」