背景
- 最近在测试大数据时,需要往 redis 大写入大量数据
1.最原始的版本,直接使用 hset,效率很低
写 30w 条完耗时 365 秒,这样有两个问题:
- 相同的 key,写入多条应该用 hmset 代替 hset
- 另外可以用 pipeline,避免频繁跟 redis 服务端交互,大量减少网络 io
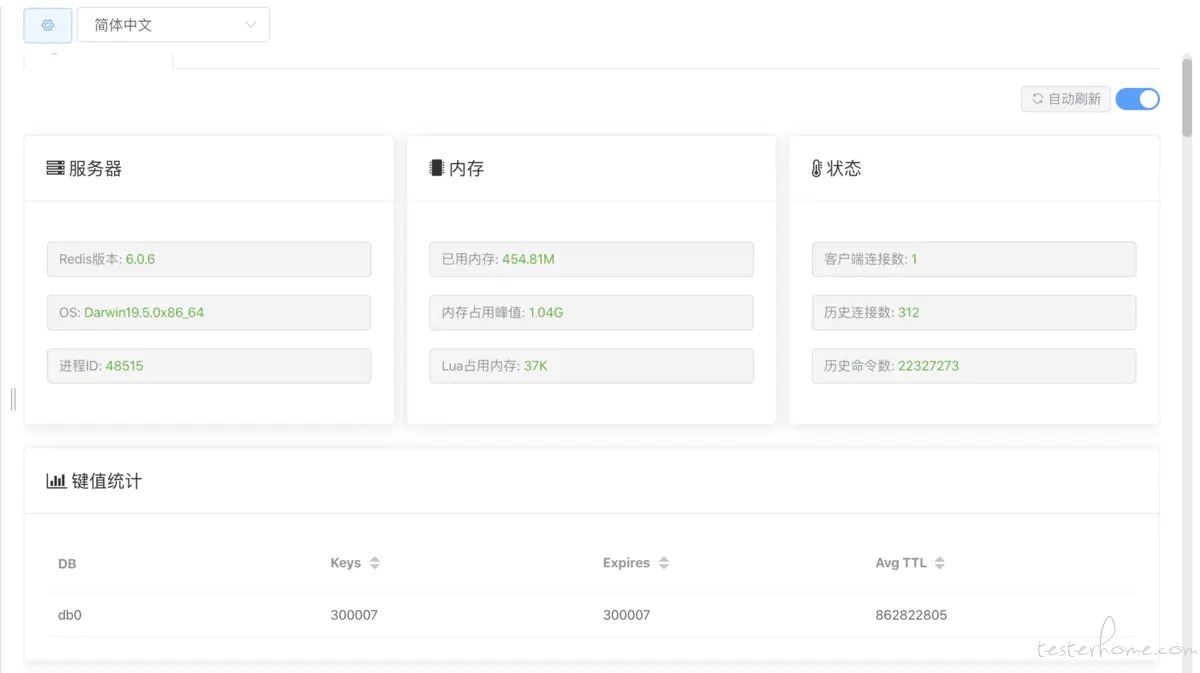

def get_conn():
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
return r
def test_set_redis():
conn = get_conn()
machineId = 43696000000000
device_no = 88800000
work_in = time.time()
source = "1"
factory_no = "factory"
today = datetime.date.today()
oneday = datetime.timedelta(days=1)
tomorrow = str(today + oneday).replace("-", "")
afterTomorrow = str(today + oneday + oneday).replace("-", "")
todayZero = int(time.mktime(today.timetuple()))
today = str(today).replace("-", "")
for i in range(300000):
upAxisId = "uxi" + str(device_no)
axisVarietyId = "axi" + str(device_no)
varietyId = "vi" + str(device_no)
axisNum = "axn" + str(device_no)
try:
conn.hset('mykey_prefix' + str(device_no), "machineId", str(machineId))
conn.hset('mykey_prefix' + str(device_no), "machineNum", str(machineId))
conn.hset('mykey_prefix' + str(device_no), "factoryId", factory_no)
conn.hset('mykey_prefix' + str(device_no), "groupId", "group_id")
conn.hset('mykey_prefix' + str(device_no), "groupName", "groupName11")
conn.hset('mykey_prefix' + str(device_no), "workshopId", "workshopId11")
conn.hset('mykey_prefix' + str(device_no), "workshopName", "workshopName11")
conn.hset('mykey_prefix' + str(device_no), "source", source)
conn.hset('mykey_prefix' + str(device_no), "errorTimeLimit", str(20))
conn.expire('mykey_prefix' + str(device_no), 864000) # 设置10天过期时间
conn.hset('mykey_prefix' + str(device_no), "axisInfo", json.dumps(axisInfo))
conn.hset('mykey_another_prefix:' + today, str(machineId), json.dumps(fbfcalue))
conn.hset('mykey_another_prefix:' + tomorrow, str(machineId), json.dumps(fbfcalue2))
conn.hset('mykey_another_prefix:' + afterTomorrow, str(machineId), json.dumps(fbfcalue3))
conn.hset('mykey_another_prefix1:' + today, str(machineId), json.dumps(fbfcalue))
conn.hset('mykey_another_prefix1:' + tomorrow, str(machineId), json.dumps(fbfcalue2))
conn.hset('mykey_another_prefix1:' + afterTomorrow, str(machineId), json.dumps(fbfcalue3))
conn.expire('mykey_another_prefix:' + today, 259200) # 3天
conn.expire('mykey_another_prefix:' + tomorrow, 259200)
conn.expire('mykey_another_prefix:' + afterTomorrow, 259200)
conn.expire('mykey_another_prefix1:' + today, 259200)
conn.expire('mykey_another_prefix1:' + tomorrow, 259200)
conn.expire('mykey_another_prefix1:' + afterTomorrow, 259200)
conn.hset('fy:be:de:ma', str(device_no), str(machineId))
conn.expire('fy:be:de:ma', 864000)
machineId = int(machineId) + int(1)
device_no = int(device_no) + int(1)
except Exception as e:
print("设置异常,错误信息:", e)
2.使用 pipeline 代替每次设置一个 key 就请求一次
## 方法很简单,只需要两处小小的改动
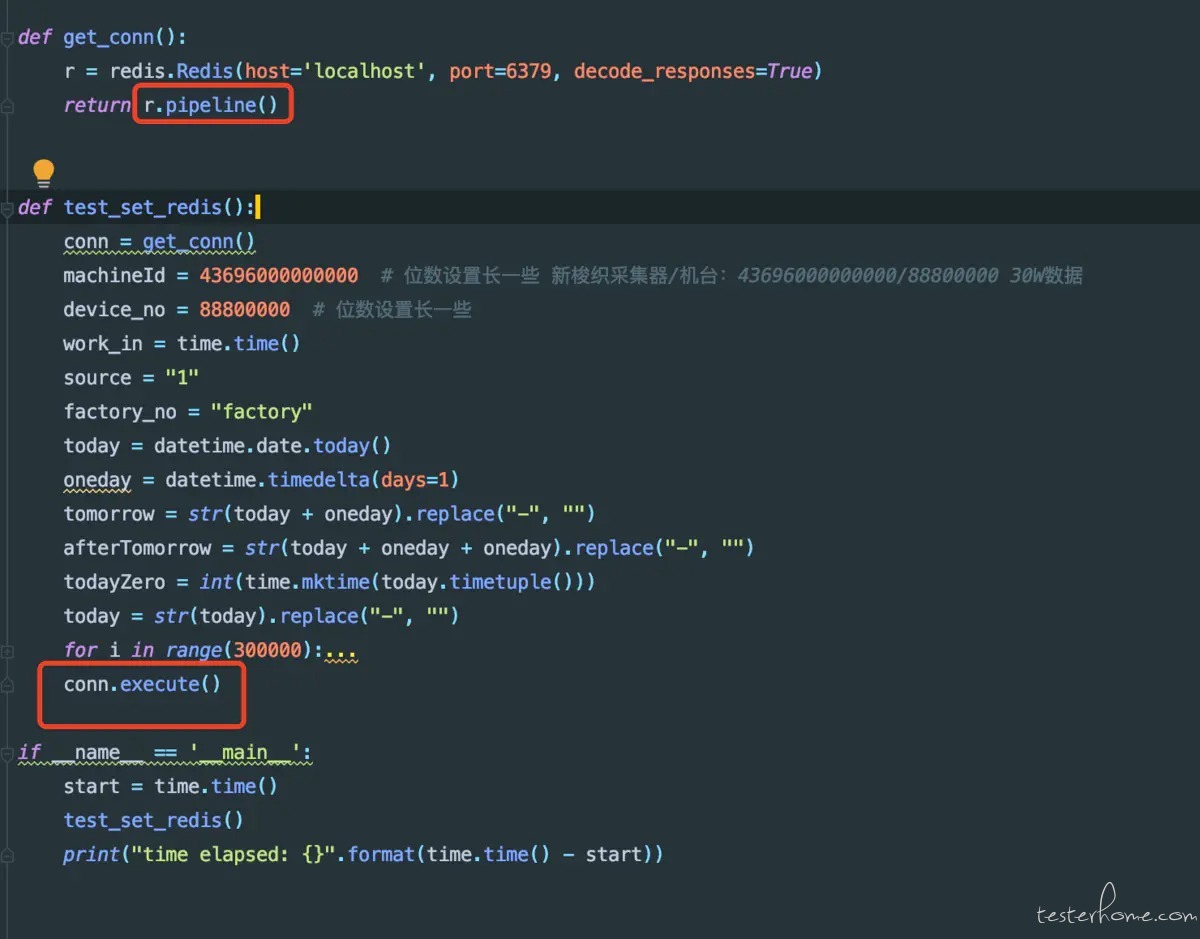
使用pipeline效果非常明显,已经从 365 秒变成了 126 秒,一下子就减少了 239 秒,将近 4 约分钟!

3.使用 pipeline + hmset
把同一个 key 对应的 field 和 value 组装成字典,通过 hmset 一次性搞定
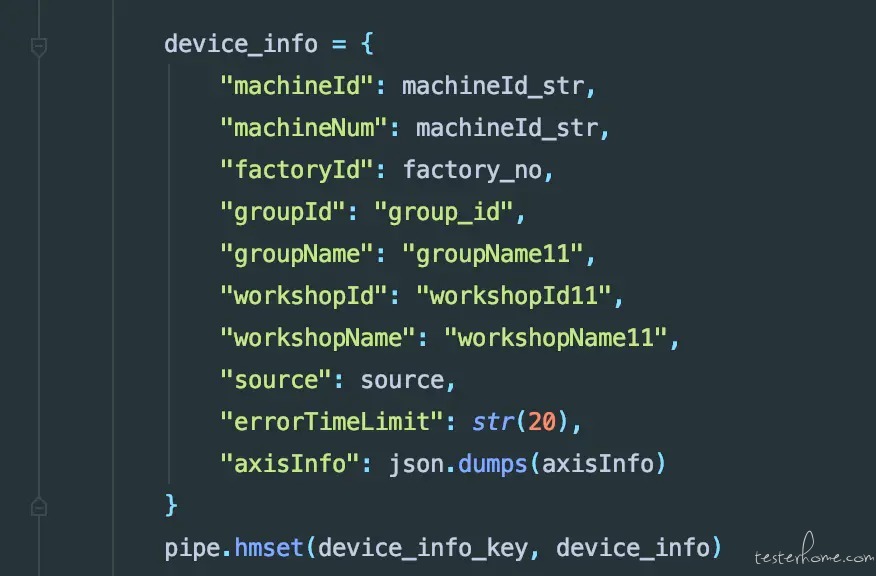
用了 hmset 之后,再次压缩时间,126 变成 98,耗时缩小了 28 秒,将近半分钟

为了进一步压缩时间,使用golang实现了一遍,性能很强劲
从 python 的 98 秒变成了 7.5 秒,整整提升了 13 倍! 是最开始的 365 秒的 48 倍!!!

func setDevice() {
var deviceNo string
var deviceInfo map[string]interface{}
// 获取reids管道
pipe := rdb.Pipeline()
defer pipe.Exec(ctx1)
for i := 0; i < len(devices); i++ {
device := devices[i]
for k, v := range device {
deviceNo = k
deviceInfo = v
}
deviceKey := fmt.Sprintf("%s:%s", deviceInfoKey, deviceNo)
machineId := deviceInfo["machineId"].(string)
// 设置排班信息
shiftInfo, _ := json.Marshal(shiftToday)
pipe.HSetNX(ctx1, fystTodayKey, machineId, shiftInfo)
pipe.Expire(ctx1, fystTodayKey, time.Hour*24)
pipe.HSetNX(ctx1, fymstTodayKey, machineId, shiftInfo)
pipe.Expire(ctx1, fymstTodayKey, time.Hour*24)
// hmset 代替hset,一次性写入map
pipe.HMSet(ctx1, deviceKey, deviceInfo).Err()
pipe.Expire(ctx1, deviceKey, time.Hour*72)
if i%1000 == 0 && i >= 1000 {
failCmd, err1 := pipe.Exec(ctx1)
log.Printf("正在设置第%d个采集器 \n", i)
if err1 != nil {
countFail += len(failCmd)
}
}
}
}
4.总结
- 批量写入时,使用 pipeline 可以大幅度提升性能
- key 相同的 field 和 value,可以用 hmset 代替 hset,也能很好的提升性能
- 操作大量数据时,使用
golang来代替python是很棒的选择