新手区 pytest+requests+allure-pytest+jsonpath+xlrd 接口自动化测试 (学习成果)
废话 (初次发文日期 2020 年 8 月)
最近在自己学习接口自动化测试,这里也算是完成一个小的成果,欢迎大家交流指出不合适的地方,源码在文末
功能 (2022 更新)
- 测试数据隔离: 测试前后进行数据库备份/还原
- 接口间数据依赖: 需要 B 接口使用 A 接口响应中的某个字段作为参数
- 自定义扩展方法: 在用例中使用自定义方法 (如:获取当前时间戳...) 的返回值
- 接口录制:录制指定包含 url 的接口,生成用例数据
- 用例跳过:支持表达式、内置函数、调用变量实现条件跳过用例
- 动态多断言: 可(多个)动态提取实际预期结果与指定的预期结果进行比较断言操作
- 对接数据库: 讲数据库的查询结果可直接用于断言操作
- 邮件发送:将 allure 报告压缩后已附件形式发送
运行机制
- 通过读取配置文件,获取到 host 地址、提取 token 的 jsonpath 表达式,提取实际响应结果用来与预期结果比对的 jsonpath 表达式。
- 读取 excel 用例文件数据,组成一个符合 pytest 参数化的用例数据,根据每列进行数据处理(token 操作、数据依赖)
- token,写,需要使用一个正常登录的接口,并且接口中要返回 token 数据,才可以提取,token,读为该请求将携带有 token 的 header,token 无数据的将不携带 token
- 数据依赖处理,从 excel 中读取出来的格式{"用例编号":["jsonpath 表达式 1", "jsonpath 表达式 2"]},通过用例编号来获取对应 case 的实际响应结果(实际响应结果在发送请求后,回写到 excel 中),通过 jsonpath 表达式提取对应的依赖参数字段,以及对应的值,最终会返回一个存储该接口需要依赖数据的字典如{"userid":500, "username": "zy7y"},在发送请求时与请求数据进行合并,组成一个新的 data 放到请求中
- 每次请求完成之后将回写实际的响应结果到 excel 中
- 根据配置文件中配置的 jsonpath 表达式提取实际响应内容与 excel 中预期结果的数据对比
- 生成测试报告
- 压缩测试报告文件夹
- 发送邮件
目录结构

执行顺序
运行 test_api.py -> 读取 config.yaml(tools.read_config.py) -> 读取 excel 用例文件 (tools.read_data.py) -> test_api.py 实现参数化 -> 处理是否依赖数据 ->base_requests.py 发送请求 -> test_api.py 断言 -> read_data.py 回写实际响应到用例文件中 (方便根据依赖提取对应的数据)
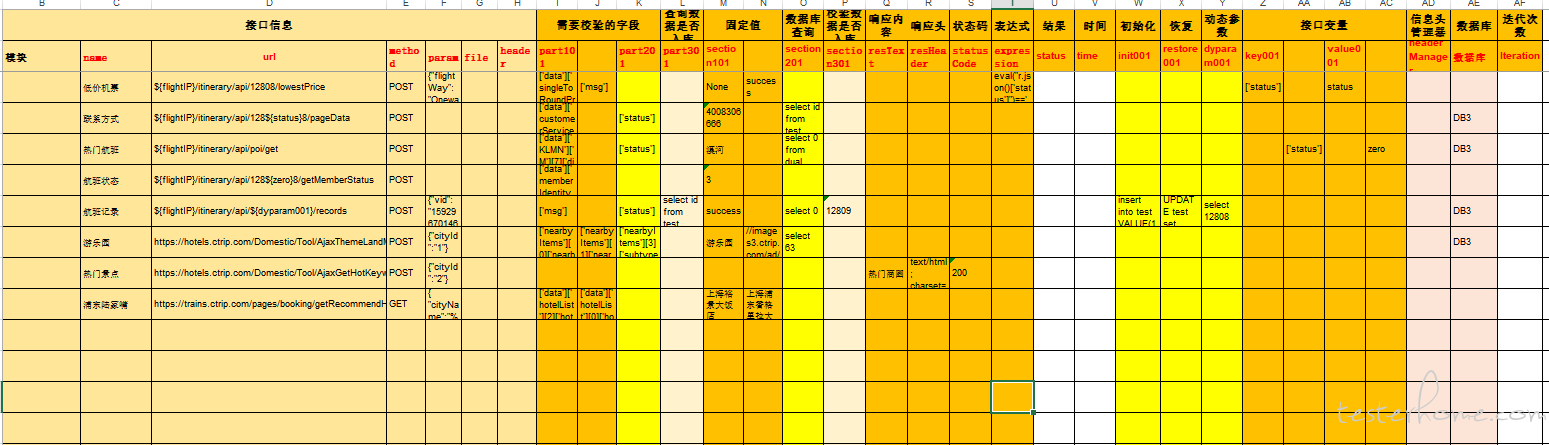
EXcel 用例展示


运行结果

致谢
jsonpath 语法学习:https://blog.csdn.net/liuchunming033/article/details/106272542
zip 文件压缩:https://www.cnblogs.com/yhleng/p/9407946.html
这算是学习接口自动化的第一个成果,但是要应用生产环境,拿过去还需要改很多东西,欢迎交流。
视频记录 (该视频指向tag2.0)
更新:2020/12/08 支持 mysql 数据库 的查询(单条数据)并可以 用响应结果与查询结果来断言,打扰了
更新 2020/11/23
最新用例截图以及用例填写格式


数据依赖/路径参数依赖
我理解的参数依赖/接口依赖就是接口进行关联操作,比如有些查询接口需要登录之后才可以操作,那么我们就需要拿到 token 之类的东西,这一部分东西是放到 header 中的,apiAutoTest 围绕的只有路径参数依赖,请求数据依赖
- 路径参数依赖
譬如说现在的 restful,一个 users 接口,路由一般这样的users他的请求方式是 get,这个路由我们把他认为是查所有用户,如果查某一个用户可能是这样的users/:id也是个 get 请求,这里这个 id 想表达的意思是这里有个需要个用户 id 的参数,比如 1-500 里面的任意 1 个,也就是说这个 id 是可变的,可以从登录接口的返回响应取一个叫 userId 的值
- 请求参数依赖
这个应该好理解些,就是说支付接口需要的订单 id,是从上一步提交订单接口返回的响应订单 id
举个例子
假设现在有个实际响应结果字典如下
{"case_002": {
"data": {
"id": 500,
"username": "admin",
"mobile": "12345678",
}},
"case_005": {
"data": {
"id": 511,
"create_time": 1605711095
},
}
}
- excel 中接口路径内容:
users/&$.case_005.data.id&/state/&$.case_005.data.careate_time&
代码内部解析后如下:users/511/state/1605711095
&$.case_005.data.id& 代表从响应字典中提取 case_005 字典中 data 字典中的 id 的值,提取出来的结果是 511
- excel 中请求参数内容如下:
{
"pagenum": 1,
"pagesize": "12",
"data": &$.case_005.data&,
"userId": &$.case_002.data.id&
}
代码内部解析后如下:
{
"pagenum": 1,
"pagesize": "12",
"data": {
"id": 511,
"create_time": 1605711095
},
"userId": 500
}
其实不难看出其中规则&jsonpath提取语法&,如果你需要的内容是字符串类型,只需要这样"&jsonpath提取语法&"
上传文件
用例中书写格式,在上传文件栏
# 单文件上传在excel中写法
{"接口中接受文件对象的参数名": "文件路径地址"}
# 多文件上传在excel中写法
{"接口中接受文件对象的参数名": ["文件路径1", "文件路径2"]}
预期结果
用例书写格式
# 断言一个内容
{"jsonpath提取表达式": 预期结果内容}
# 多个断言
{"jsonpath提取表达式1": 预期结果内容1,"jsonpath提取表达式2": 预期结果内容2}
其他优化
- config.yaml 文件中新增可配置初始 header,整体代码优化,相比之前,同样测试用例执行下,快了 2s 左右
- 将配置文件读取,用例读取整合在
read_file.py下 - 移除报告压缩方法
- 减少日志信息
现依赖处理代码
tools/init.py
#!/usr/bin/env/python3
# -*- coding:utf-8 -*-
"""
@project: apiAutoTest
@author: zy7y
@file: __init__.py
@ide: PyCharm
@time: 2020/7/31
"""
import json
import re
import allure
from jsonpath import jsonpath
from loguru import logger
def extractor(obj: dict, expr: str = '.') -> object:
"""
根据表达式提取字典中的value,表达式, . 提取字典所有内容, $.case 提取一级字典case, $.case.data 提取case字典下的data
:param obj :json/dict类型数据
:param expr: 表达式, . 提取字典所有内容, $.case 提取一级字典case, $.case.data 提取case字典下的data
$.0.1 提取字典中的第一个列表中的第二个的值
"""
try:
result = jsonpath(obj, expr)[0]
except Exception as e:
logger.error(f'提取不到内容,丢给你一个错误!{e}')
result = None
return result
def rep_expr(content: str, data: dict, expr: str = '&(.*?)&') -> str:
"""从请求参数的字符串中,使用正则的方法找出合适的字符串内容并进行替换
:param content: 原始的字符串内容
:param data: 在该项目中一般为响应字典,从字典取值出来
:param expr: 查找用的正则表达式
return content: 替换表达式后的字符串
"""
for ctt in re.findall(expr, content):
content = content.replace(f'&{ctt}&', str(extractor(data, ctt)))
return content
def convert_json(dict_str: str) -> dict:
"""
:param dict_str: 长得像字典的字符串
return json格式的内容
"""
try:
if 'None' in dict_str:
dict_str = dict_str.replace('None', 'null')
elif 'True' in dict_str:
dict_str = dict_str.replace('True', 'true')
elif 'False' in dict_str:
dict_str = dict_str.replace('False', 'false')
dict_str = json.loads(dict_str)
except Exception as e:
if 'null' in dict_str:
dict_str = dict_str.replace('null', 'None')
elif 'true' in dict_str:
dict_str = dict_str.replace('true', 'True')
elif 'False' in dict_str:
dict_str = dict_str.replace('false', 'False')
dict_str = eval(dict_str)
logger.error(e)
return dict_str
def allure_title(title: str) -> None:
"""allure中显示的用例标题"""
allure.dynamic.title(title)
def allure_step(step: str, var: str) -> None:
"""
:param step: 步骤及附件名称
:param var: 附件内容
"""
with allure.step(step):
allure.attach(json.dumps(var, ensure_ascii=False, indent=4), step, allure.attachment_type.TEXT)
tools/data_process.py
#!/usr/bin/env/python3
# -*- coding:utf-8 -*-
"""
@project: apiAutoTest
@author: zy7y
@file: data_process.py
@ide: PyCharm
@time: 2020/11/18
"""
from tools import logger, extractor, convert_json, rep_expr, allure_step
from tools.read_file import ReadFile
class DataProcess:
response_dict = {}
header = ReadFile.read_config('$.request_headers')
have_token = header.copy()
@classmethod
def save_response(cls, key: str, value: object) -> None:
"""
保存实际响应
:param key: 保存字典中的key,一般使用用例编号
:param value: 保存字典中的value,使用json响应
"""
cls.response_dict[key] = value
logger.info(f'添加key: {key}, 对应value: {value}')
@classmethod
def handle_path(cls, path_str: str) -> str:
"""路径参数处理
:param path_str: 带提取表达式的字符串 /&$.case_005.data.id&/state/&$.case_005.data.create_time&
上述内容表示,从响应字典中提取到case_005字典里data字典里id的值,假设是500,后面&$.case_005.data.create_time& 类似,最终提取结果
return /511/state/1605711095
"""
# /&$.case.data.id&/state/&$.case_005.data.create_time&
return rep_expr(path_str, cls.response_dict)
@classmethod
def handle_header(cls, token: str) -> dict:
"""处理header
:param token: 写: 写入token到header中, 读: 使用带token的header, 空:使用不带token的header
return
"""
if token == '读':
return cls.have_token
else:
return cls.header
@classmethod
def handler_files(cls, file_obj: str) -> object:
"""file对象处理方法
:param file_obj: 上传文件使用,格式:接口中文件参数的名称:"文件路径地址"/["文件地址1", "文件地址2"]
实例- 单个文件: &file&D:
"""
if file_obj == '':
return
for k, v in convert_json(file_obj).items():
# 多文件上传
if isinstance(v, list):
files = []
for path in v:
files.append((k, (open(path, 'rb'))))
else:
# 单文件上传
files = {k: open(v, 'rb')}
return files
@classmethod
def handle_data(cls, variable: str) -> dict:
"""请求数据处理
:param variable: 请求数据,传入的是可转换字典/json的字符串,其中可以包含变量表达式
return 处理之后的json/dict类型的字典数据
"""
if variable == '':
return
data = rep_expr(variable, cls.response_dict)
variable = convert_json(data)
return variable
@classmethod
def assert_result(cls, response: dict, expect_str: str):
""" 预期结果实际结果断言方法
:param response: 实际响应字典
:param expect_str: 预期响应内容,从excel中读取
return None
"""
expect_dict = convert_json(expect_str)
index = 0
for k, v in expect_dict.items():
actual = extractor(response, k)
index += 1
logger.info(f'第{index}个断言,实际结果:{actual} | 预期结果:{v} \n断言结果 {actual == v}')
allure_step(f'第{index}个断言', f'实际结果:{actual} = 预期结果:{v}')
assert actual == v
源码地址
master: 分支为最新代码
version1.0: 分支为之前开源的代码(通过字典迭代的方式来处理数据依赖)
Https://gitee.com/zy7y/apiAutoTest.git
Https://github.com/zy7y/apiAutoTest.git
后续打算
目前在公司正在做接口测试,说实话也是摸索着来,以上的优化项都是实际做的过程中突然想到的,然后就更新了
- 接入用例前后置 SQL, 前置 SQL 目前想的是现在项目中遇到的问题,有些接口没有返回需要的数据,这里就要用前置 SQL 查询的结果传到请求数据里面了,后置 SQL 主要是请求后查看数据库中的数据是否变动,形成数据库断言
- 企业微信推送:目前项目中预想的效果,是后端人员提交代码,自动部署之后,通过 gitlab-ci 启动测试代码,进行接口测试完成之后采集 allure 中的测试结果一有异常/失败用例就发送邮件并进行企业微信推送给领导
- .... 就不说了还有很多优化项,能力不够好好充电吧,~~
致谢
谢谢各位对 apiAutoTest 的帮助,谢谢~,打扰了
关联下这篇帖子:希望大家能给我些建议--https://testerhome.com/topics/25418
https://gitee.com/zy7y/apiAutoTestDemo 完结,gitee 库中已添加对应使用项目的接口文档,用例书写格式描述文档使用了 pytest.mark.parametrize() 实现参数化,字典存储实际结果响应读取 data 依赖,path 参数依赖,重组 data 以及 path,增加了多文件上传,按道理是支持 restful 接口规范的,其中处理请求数据依赖,path 数据依赖的方法可能过于麻烦 (能力有限目前只能想到这种处理方法),如果在学习的朋友没有:学习 上面的某种思路,希望这个东西能帮到你们:,如果有更好的处理方法希望大家能交流下。(该代码有很多异常情况并没有进行处理,所以需要严格按照用例格式进行用例书写),若之前有小伙伴使用了这个 Demo 的 请将基准地址更换为(我私有的云服务器,已避免不必要的麻烦):http://49.232.203.244:8888/api/private/v1/

关于之前的日志一个问题,在 allure 报告中展示比较乱,可使用日志旁边放大按钮 (会在当前页面弹出一个页面显示日志,会得到部分改善),如有需要交流,可联系我:QQ 396667207,加好友请注明来意,谢谢给我留帖的各位。

 来面试的?如何
来面试的?如何