全文内容主要源于极客大学的算法课,仅作为笔记使用。
1、数组
数组:在内存中,占用连续内存空间的,有序的元素序列。
数组元素的类型没有要求,即为泛型。
底层原理
当申请数组时,内存管理器分配一个连续的内存地址。每一个地址可以直接通过内存管理器进行访问。
如下图所示,即为数组相应的内存地址:
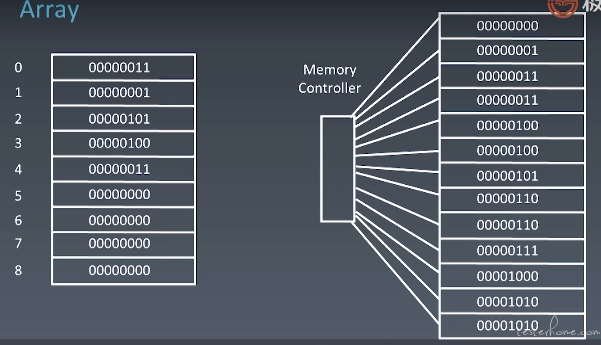
直接访问的话,访问第一个元素和访问任意一个元素,时间复杂度都是一样的,为 O(1)。
数组特性
访问速度快
访问数组时,其实是利用指针,即内存地址,直接访问对应内存地址中的数值,所以访问速度非常快。
访问数组的时间复杂度:常数复杂度 O(1)
删除和插入: O(n)
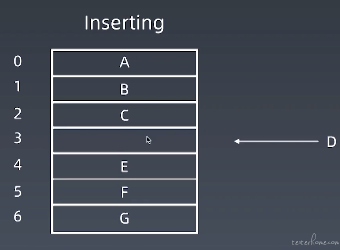
如下图所示:
当向数组中插入元素 D 时,首先要将 E、F、G 都向下挪动一个位置,然后将 index=3 的地址值赋值为 D。
同理:
- 最慢的插入操作:插入位置为第一个元素位置,要挪动 n 个元素,时间复杂度为 O(n)
- 最快的插入操作:插入位置为最后一个元素位置,不需要挪动元素,时间复杂度为 O(1)
- 平均要挪动一半元素
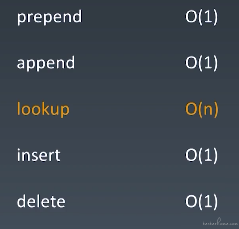
Array 各操作时间复杂度
prepend: O(n),正常情况下是 O(n),但是可以进行特殊优化到 O(1)。初始化时申请稍大一些的内存空间,然后在数组最开始预留一部分空间,然后 prepend 操作只需要把头下标千一一个位置即可。
append: O(1)
lookup: O(1)
insert: O(n)
delete: O(n)
2、链表(LinkedList)

概念
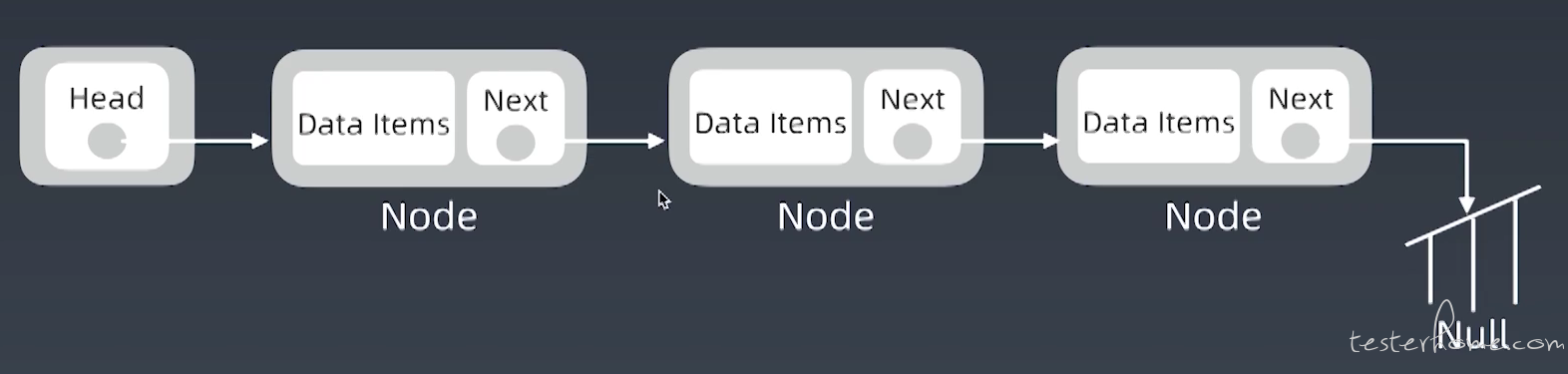
链表:元素由 Value 和 next 组成,next 指向下一个元素,在内存中是非连续空间。链表元素一般由 class 定义。
单向链表:如果只有一个 next 指针,是单向链表。
双向链表:如果由两个指针,next 指向下一个元素,先前指针 prev 或 previous 指向上一个元素。一般头叫做 Head,尾叫做 Tail。
循环链表:如果 next 指向 Head,叫做循环链表。
LinkedList 定义
最简单的链表定义:
class LinkedList {
Node head; // head of list
/* Linked List Node */
class Node {
int data;
Node next;
Node(int d) { data = d; }
}
}
插入和删除
增加节点
节点增加步骤:
- 插入位置前面的 node.next 指向 new node
- new node 的 next 指向插入位置后面的 node 由于只有两步操作,所以时间复杂度为 O(1)
删除节点
删除节点为增加节点的逆操作。
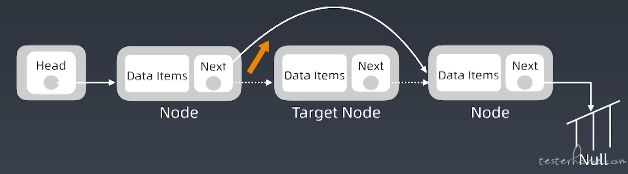
删除节点步骤:
- target_node.prev_node.next = target_node.next_node 只有一步操作,时间复杂度为 O(1)。
由此可见,链表的增加和删除,没有引起整个链表的群移操作,也不需要复制元素。所以移动或修改链表的效率非常高,时间复杂度为 O(1)。
但是,正因为链表的这种特性,当访问中间节点时,必须从 Head Node 一步一步往后找,时间复杂度为 O(n)
链表各操作时间复杂度
3、跳表 Skiped List
科学家在数组和链表基础上,优化了新的数据结构,即 跳表。
主要关注:升维思想 + 空间换时间
跳表的特点
注意:只能用于元素有序的情况。
所以,跳表对标的是平衡树(VAL Tree)和二分查找,是一种插入/删除/查找 都是 O(log n) 的数据结构。
它最大的优势是原理简单、容易实现、方便扩展、效率更高。因此在一些热门的项目里用于替代平衡树,如 Redis、LevelDB 等。
如何给有序的链表加速
有序一维数据结构加速理念:经常采用的方式就是升维,也就是说变成二维。
(1)加一级索引
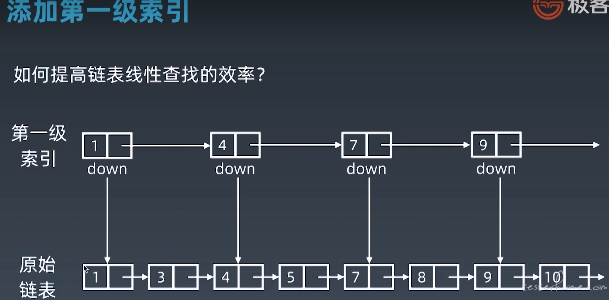
第一级索引指向的是 next.next
(2)加二级索引
二级索引 next 指向的是一级索引链表的 next.next
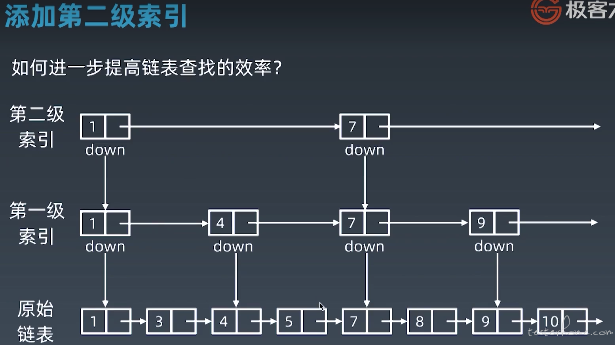
(3)多级索引
以此类推,加多级索引如下图所示:

跳表查询的时间复杂度
n/2、n/4、n/8,第 k 级索引节点的个数就是 n/(2k)
假设索引有 h 级,最高级的索引有 2 个结点。n / (2h) = 2,从而求得 h = log2(n) - 1
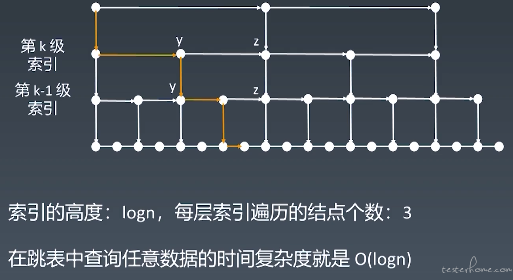
假设原始链表要查询 1024 次的话,那么跳表的时间复杂度是 log2(n),即 10 次就可以找到元素。
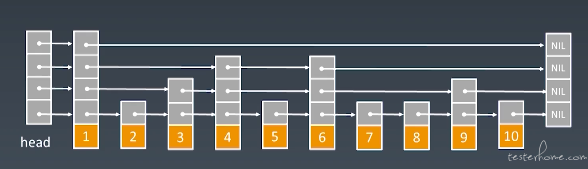
现实中的跳表
如下图所示,现实中的跳表,由于多次的增加和删除,导致有些索引并不是完全工整的,最后经过多次改动后,有些地方的索引会多跨几步,有些地方会少跨或只跨两步。
维护成本相对较高,比如增加或删除一个元素的话,索引要更新一遍,此时时间复杂度就变为 Logn 了。
空间复杂度
跳表的空间复杂度为 O(n),但是比原始链表要多很多。

4、更多
LRU 缓存算法
跳表在 Redis 中的使用
跳跃表、为啥 Redis 使用跳表(Skip List)而不是使用 Red-Black?