什么是多分支 pipeline
在 jenkins 中存在两种类型的 pipeline, 之前我们讲述的都是普通类型的 pipeline。 而多分支 pipeline 作为一个非常重要的类型重要为我们完成持续集成的第一个步骤—打通 gitlab 的通信。 这样研发再 push 代码后通知 jenkins 运行我们预先定义的 pipeline 完成整个持续集成流程。 要做到这样的效果需要分别在 jenkins 和 gitlab 中做如下准备工作。
jenkins 的配置
配置 jenkins(这里已经在咱们的 jenkins 中配置好,凭据名称为 gaofeigitlab 账号)
- 安装 gitlab 插件
- 在安全设置中添加 jenkins 凭据
- 类型选择:Gitlab API Token (获取方式:在 gitlab 中使用自己的账户登录,在 User settings 中找到 Access Tokens。 在这里创建一个 token)
- 复制这个 token 保存到上面说的 jenkins 凭据中。
创建多分支 pipeline
在 jenkins 中创建一个 job,选择类型为多分支 pipeline。 在 git 中填写研发的 repo 地址,jenkins 凭据以及要监控的分支。 如下:
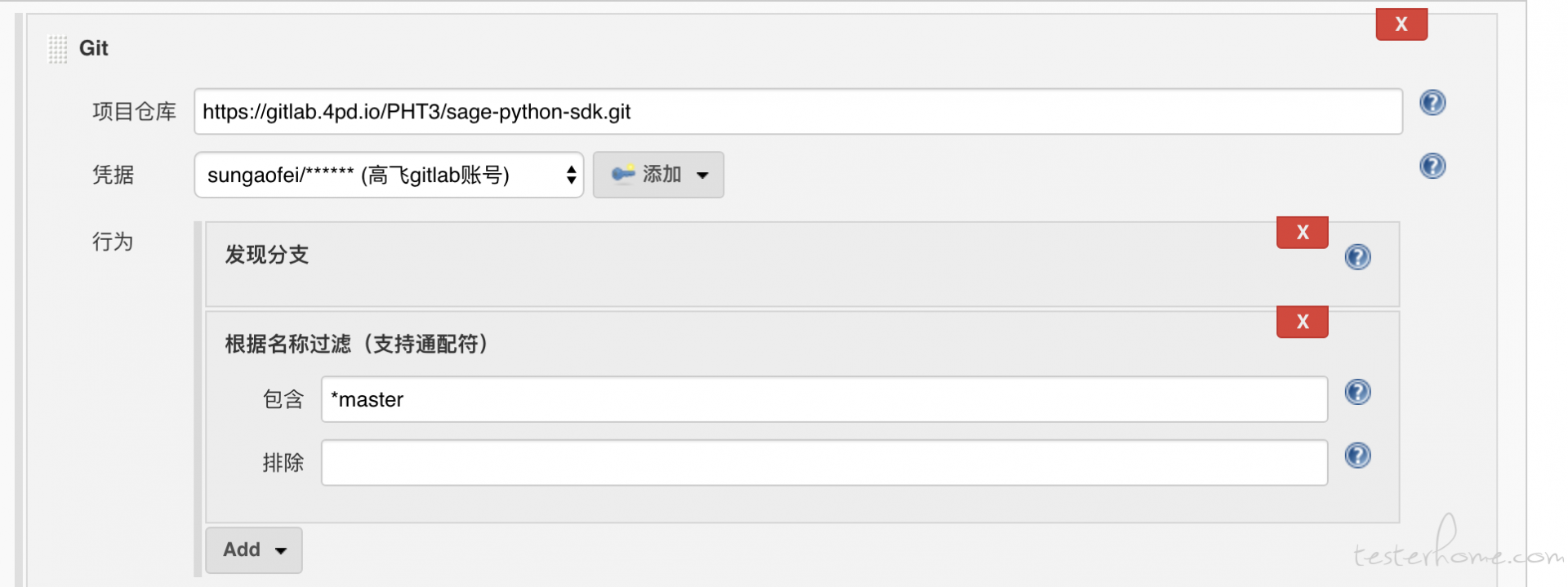
gitlab 的配置
到研发的 repo 中,添加一个跟 jenkins 通信的 webhook。 需要进入 settings->integration→添加 webhook。 中间要填写 jenkins job 的 url 以及 勾选 push event 和 merge event。如下:
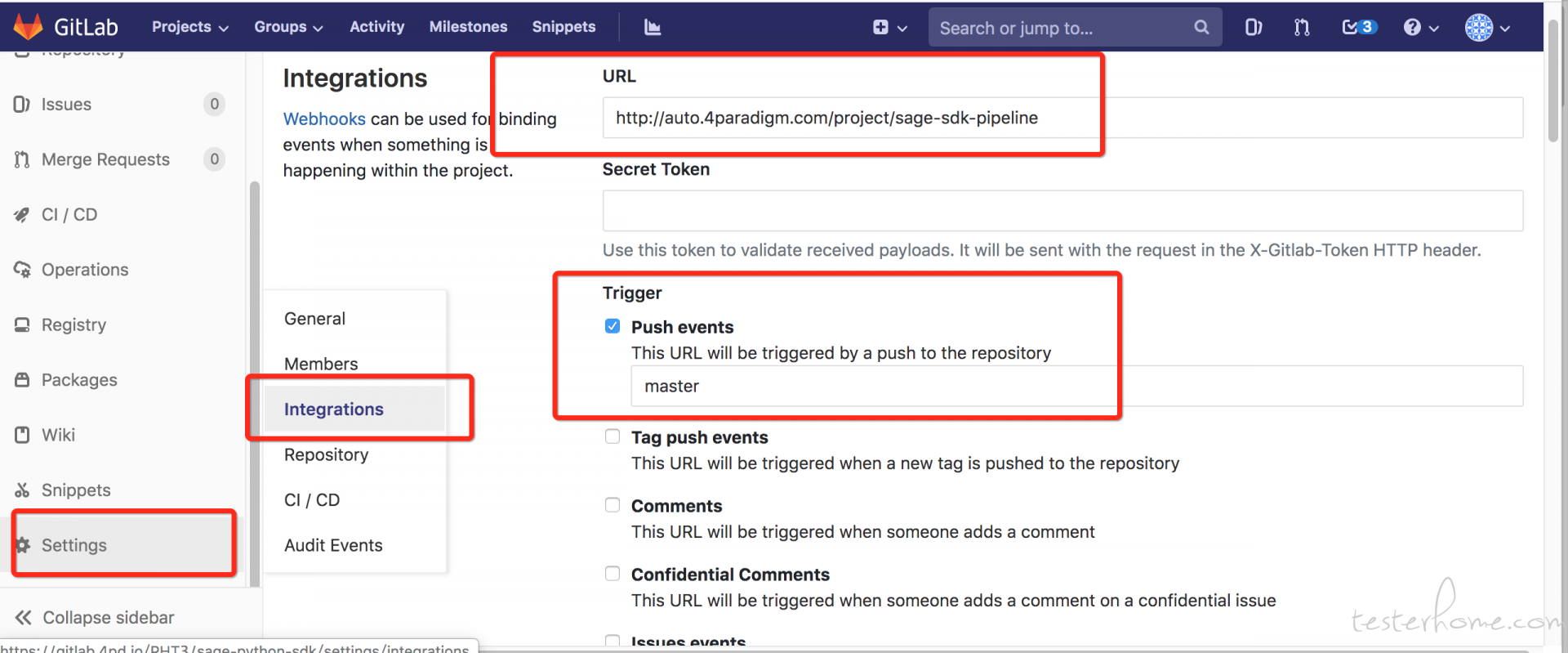
注意:jenkins job 的 url 的格式是:http://JENKINS_URL/project/PROJECT_NAME
通过上面的配置,我们就打通了 jenkins 与 gitlab 的通信。 一旦有研发在提交代码和提交 merge 的时候就会触发这个多分支 pipeline 运行。
准备 jenkinsfile
多分支 pipeline 的规则是打通了研发 repo 中所有分支的事件。 可以理解为它监控了 repo 中的所有分支的代码变动。 所以它不准在 job 的脚本框中编写 pipeline,我们需要在研发的分支中添加 jenkinsfile 来保存我们的 pipeline。
注意: 多分支 pipeline 在创建后就会扫描研发 repo 中所有的分支并寻找 jenkinsfile 文件。 所以我们要在所有需要执行 pipeline 的分支中都要编写一份 pipeline。如果 jenkins 找不到 jenkinsfile 边不会监控此分支。 jenkinsfile 中的 pipeline 脚本与普通的 pipeline 语法一致,没有区别。
效果
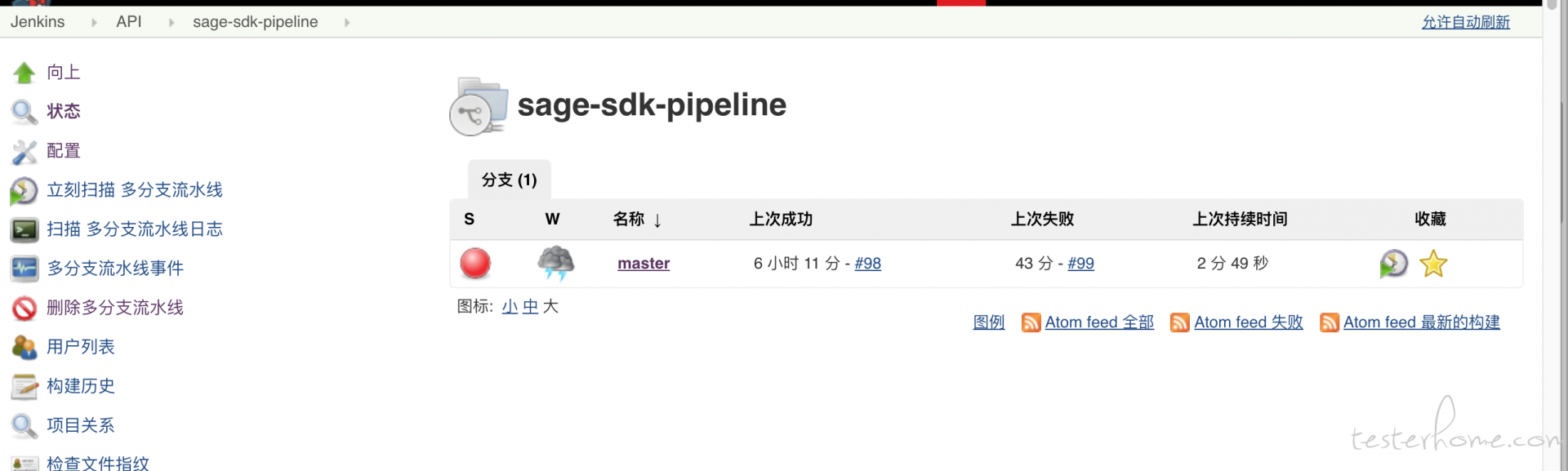
根据上面的配置, 多分支 pipeline 扫描了研发的分支后决定跟踪哪些分支的事件, 这里有两个规则, 一个是它只会监控有 jenkinsfile 的分支,如果没有就不跟踪, 这跟上面说的一样, 第二个规则是在 job 可以根据正则表达式来配置都跟踪哪些分支。 当配置生效后, 多分支 pipeline 会定期的去扫描研发的 repo 去获取最新的要跟踪的分支信息。 然后会根据分支名字作为 job 名字。 当跟踪了多个分支后就会在多分支 pipeline 下创建多个 pipeline job 出来, 就像上面的图, 只不过因为我们这个项目走的是主线开发模型, 所以我配置的只跟踪 master 分支。
可视化
在第四范式我们提倡测试的透明化和可视化。 我们希望每个项目都有一个质量看板,能够实时的反应出当前的 bug,测试用例,覆盖率等相关信息。 举个例子, 我们最近开展的 sdk 项目中,我制作了如下的看板。
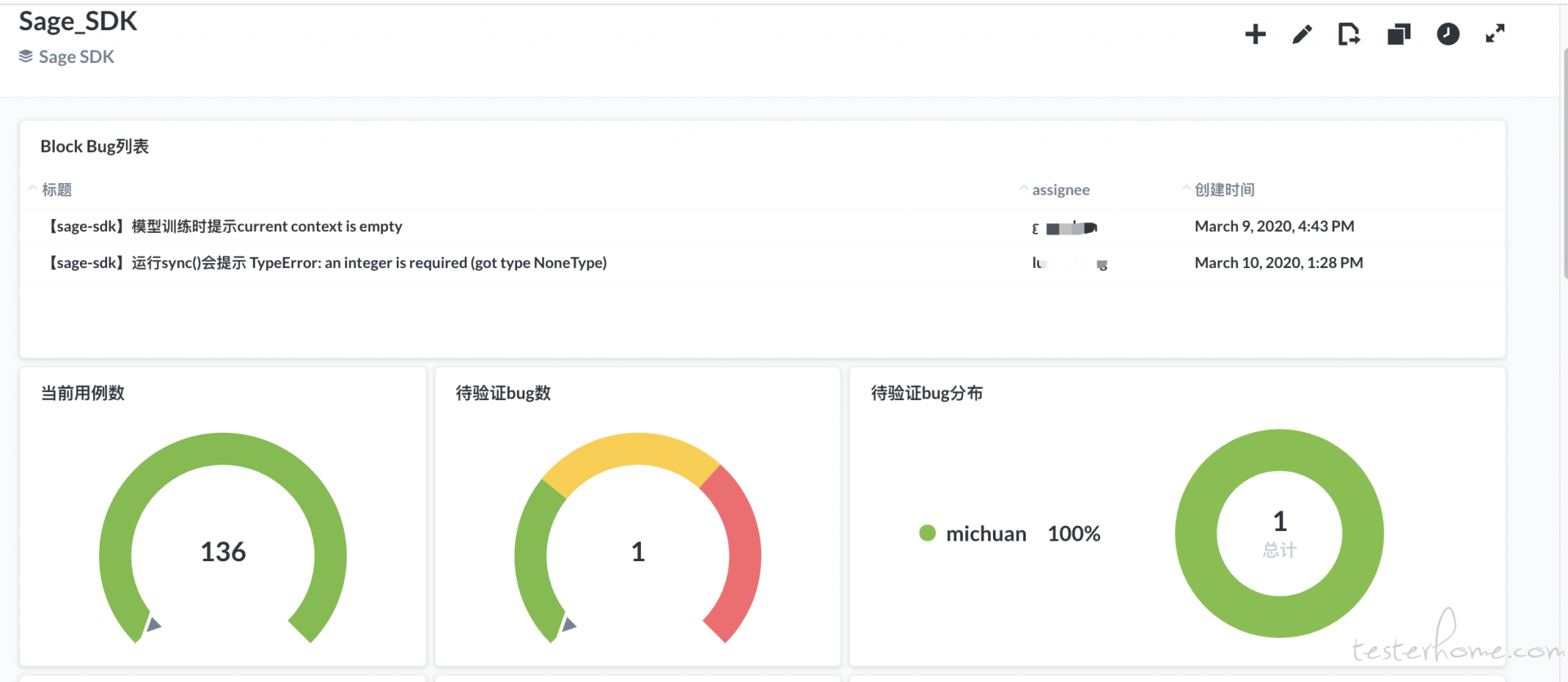
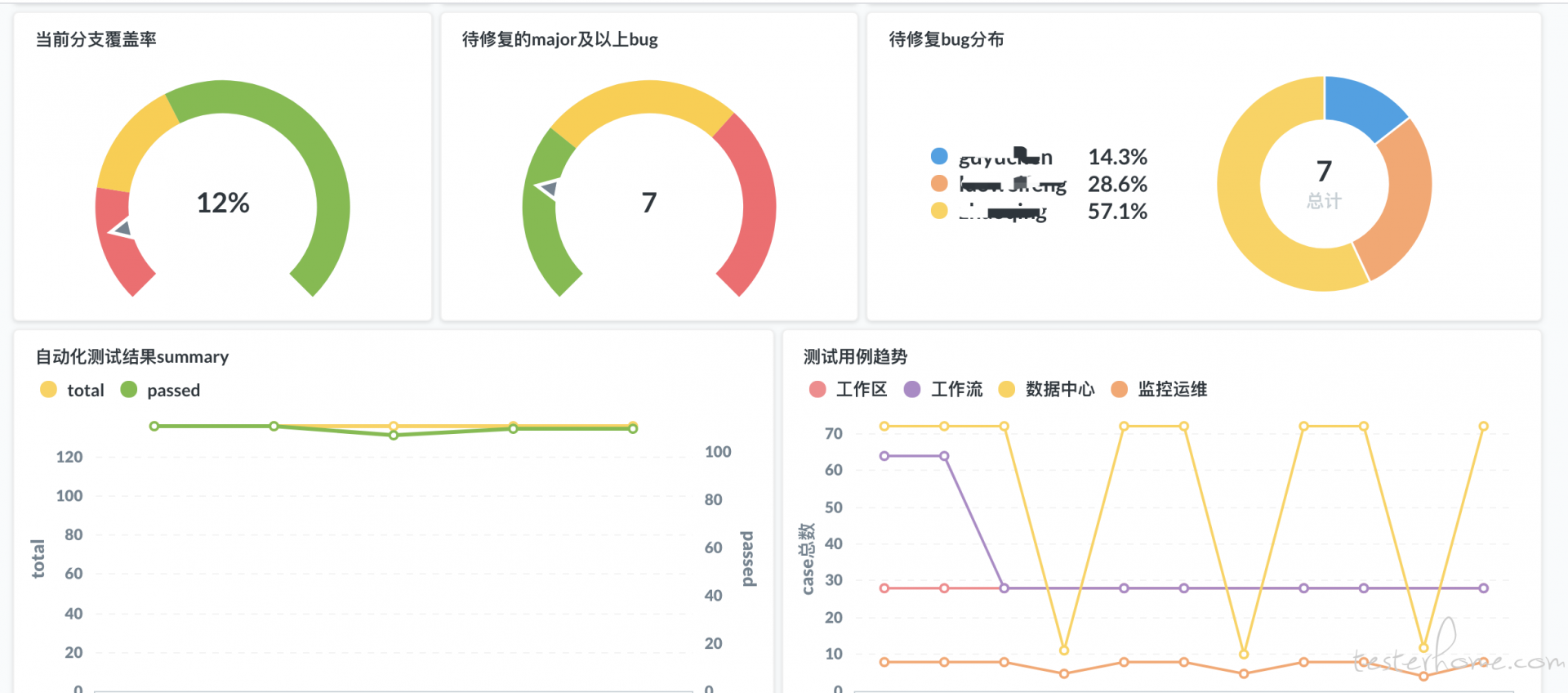
为了达到上面的效果, 我们采取了如下的工具链:
- allure: 不论是 java,python 还是 js 语言来做测试, 选取的测试报告框架一律都是 allure,这个框架在兼容各个主流语言的同时,同时会暴露出 http 接口可以供我们抓取测试结果。 而详尽的用例分类展示功能,也可以让我们统计每个模块的测试用例数据。 这也是上面我能制作出模块级别的测试用例变化趋势图的原因。
- jenkins shared library: 利用之前介绍的这个功能,我们编写了统一的库。 可以让各个项目对接, 只要用了 allure 作为 report 的,都可以无缝对接。
- metabase:这是一个开源的 BI 软件,特点是能对接各种数据库, 可以在 UI 上很方便的配置出各种图标, 上述的效果都是用 metabase 制作的。
jenkins 上抓取 allure report 结果的库
/**
* Created by sungaofei on 19/3/1.
*/
@Grab(group = 'org.codehaus.groovy.modules.http-builder', module = 'http-builder', version = '0.7')
@Grab(group = 'org.jsoup', module = 'jsoup', version = '1.10.3')
import org.jsoup.Jsoup
import groovyx.net.http.HTTPBuilder
import static groovyx.net.http.ContentType.*
import static groovyx.net.http.Method.*
import groovy.transform.Field
//可以指定maven仓库
//@GrabResolver(name = 'aliyun', root = 'http://maven.aliyun.com/nexus/content/groups/public/')
//加载数据库连接驱动包
//@Grab('mysql:mysql-connector-java:5.1.25')
//@GrabConfig(systemClassLoader=true)
//global variable
@Field jenkinsURL = "http://auto.4paradigm.com"
@Field int passed
@Field int failed
@Field int skipped
@Field int broken
@Field int unknown
@Field int total
@Field Map<String, Map<String, Integer>> map = new HashMap<>()
@NonCPS
def getResultFromAllure() {
def reportURL = ""
if (env.BRANCH_NAME != "" && env.BRANCH_NAME != null) {
reportURL = "/view/API/job/${jobName}/job/${env.BRANCH_NAME}/${BUILD_NUMBER}/allure/"
} else {
reportURL = "/view/API/job/${JOB_NAME}/${BUILD_NUMBER}/allure/"
}
// reportURL = "/view/API/job/sage-sdk-test/185/allure/"
HTTPBuilder http = new HTTPBuilder(jenkinsURL)
//根据responsedata中的Content-Type header,调用json解析器处理responsedata
http.get(path: "${reportURL}widgets/summary.json") { resp, json ->
println resp.status
passed = Integer.parseInt((String) json.statistic.passed)
failed = Integer.parseInt((String) json.statistic.failed)
skipped = Integer.parseInt((String) json.statistic.skipped)
broken = Integer.parseInt((String) json.statistic.broken)
unknown = Integer.parseInt((String) json.statistic.unknown)
total = Integer.parseInt((String) json.statistic.total)
}
http.get(path: "${reportURL}data/behaviors.json") { resp, json ->
List featureJson = json.children
for (int i = 0; i < featureJson.size(); i++) {
String featureName = featureJson.get(i).name
Map<String, Integer> results = new HashMap<>()
results['passed'] = 0
results['failed'] = 0
results['skipped'] = 0
results['broken'] = 0
results['unknown'] = 0
List storyJson = featureJson.get(i).children
for (int j = 0; j < storyJson.size(); j++) {
List caseJson = storyJson.get(j).children
for (int k = 0; k < caseJson.size(); k++) {
def caseInfo = caseJson.get(k)
String status = caseInfo.status
int num = results.get(status) + 1
results[status] = num
}
}
int total = 0
results.each { key, value ->
total = total + value
}
results['total'] = total
map.put(featureName, results)
}
}
}
def int getLineCov(){
def htmlurl = "${jenkinsURL}/view/API/job/${JOB_NAME}/${BUILD_NUMBER}/_e4bba3_e7a081_e8a686_e79b96_e78e87_e68aa5_e5918a/index.html"
String doc = Jsoup.connect(htmlurl).get().getElementsByClass("pc_cov").text();
int cov = Integer.parseInt(doc.replace("%", ""))
println("当前行覆盖率为 ${cov}")
return cov
}
def int getBranchCov(){
def htmlurl = "${jenkinsURL}/view/API/job/${JOB_NAME}/${BUILD_NUMBER}/_e4bba3_e7a081_e8a686_e79b96_e78e87_e68aa5_e5918a/index.html"
String branchAll = Jsoup.connect(htmlurl).get().select(".total > :nth-child(5)").text();
String branchPartial = Jsoup.connect(htmlurl).get().select(".total > :nth-child(6)").text();
println("all branch number: ${branchAll}")
println("cover branch number: ${branchPartial}")
def cov = Integer.parseInt(branchPartial)/Integer.parseInt(branchAll)
println("the branch cov is ${cov}")
return cov
}
def call() {
def version = "release/3.8.2"
getResultFromAllure()
getDatabaseConnection(type: 'GLOBAL') {
map.each { feature, valueMap ->
def sqlString = "INSERT INTO func_test (name, build_id, feature, version, total, passed, unknown, skipped, failed, broken, create_time) VALUES ('${JOB_NAME}', '${BUILD_ID}', '${feature}', '${version}', " +
"${valueMap['total']}, ${valueMap['passed']}, ${valueMap['unknown']}, ${valueMap['skipped']}, ${valueMap['failed']}, ${valueMap['broken']}, NOW())"
println(sqlString)
sql sql: sqlString
}
def lineCov = getLineCov()
def branchCov = getBranchCov()
def sqlString = "INSERT INTO func_test_summary (name, build_id, version, total, passed, unknown, skipped, failed, broken, line_cov, branch_cov, create_time) VALUES ('${JOB_NAME}', '${BUILD_ID}', '${version}', " +
"${total}, ${passed}, ${unknown}, ${skipped}, ${failed}, ${broken}, ${lineCov}, ${branchCov}, NOW())"
sql sql: sqlString
}
}
上面的注意点:
- 使用 grab 来下载 http builder 和 jsoup 的依赖, 分别用来请求 allure 的 http 接口, 以及使用 jsoup 来解析覆盖率这种纯 html 页面。
- allure 的分为 allure1 和 allure2, 不同版本对外暴露的接口不一样, 这一点要注意,我这里统一使用 allure2. 具体的接口细节可以在 chrome 上去抓
- allure 的接口用到的两个: summary 用来获取整体的测试用例情况, 而 behaviors 则能获取每一个模块的测试用例细节。
- 最后入库的 sql 指令使用的是 database 和 mysql-database 的插件,可以在 jenkins 上的插件管理中下载。 然后在全局配置中,按如下进行配置。
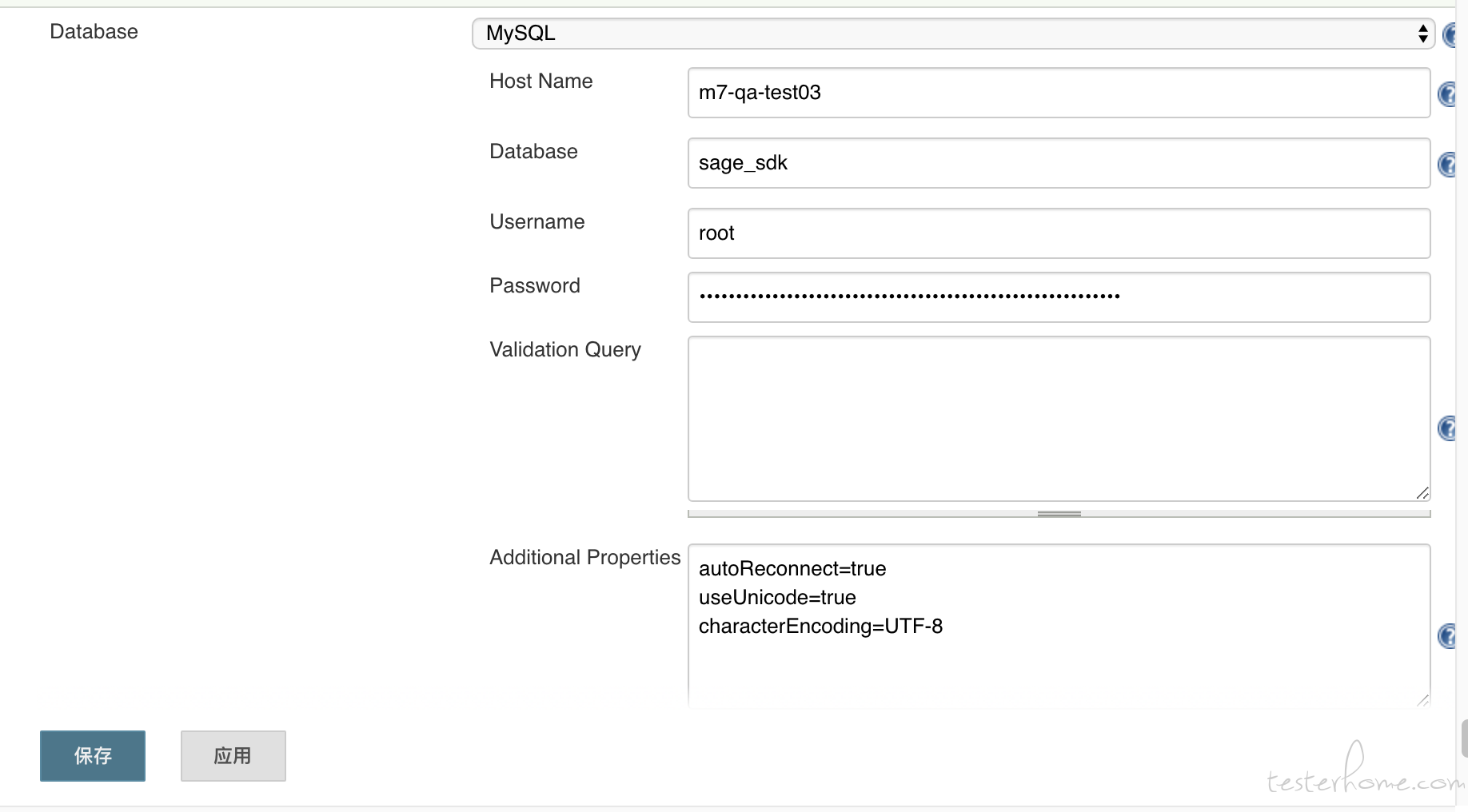
PS: 我曾经想要使用 groovy 的 jdbc 包来与 mysql 通信, 但是在 jenkins 中的 groovy 毕竟跟常规的不一样,导致依赖包无法加载, 一直没有办法解决这个问题。 所以只能用 jenkins 的插件来曲线救国了。
至于 Metabase 这个 BI 软件的教程就不写了, 非常简单,大家随便去搜一下吧, 我当时都没看文档, 直接启动起来以后玩两下子就行了。 上面统计 bug 的信息是做了个定时任务,定时的去抓 jira 的接口然后入库搞的, 也就不详细讲了。
结尾
这个系列写到这,关于 jenkins pipeline 以及相关工具的介绍就结束了, 下一期开始写 docker&k8s。