持续集成 结合 Jenkins,完成钉钉推送 (python+pytest+allure)
前言
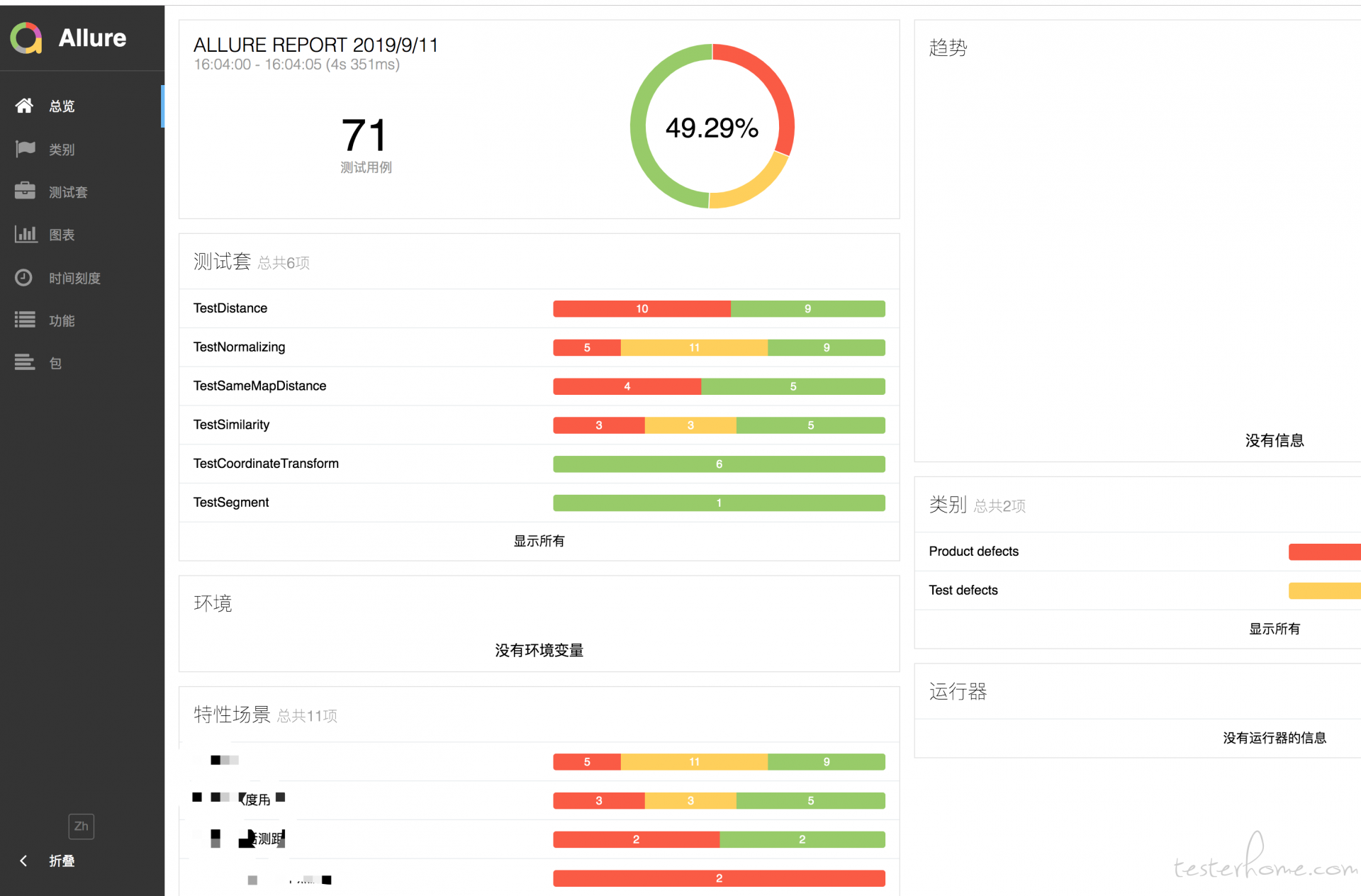
因为公司用钉钉办公,所以执行完自动化脚本之后,需要推送至相关群;本文不具体阐述怎么生成 allure 报告,主要推送为主。领导要求要有运行脚本数量、通过数量、失败数量、构建地址、报告地址;效果如下:

需要做的事
1.找到 allure 生成,包含整体测试结果的文件;
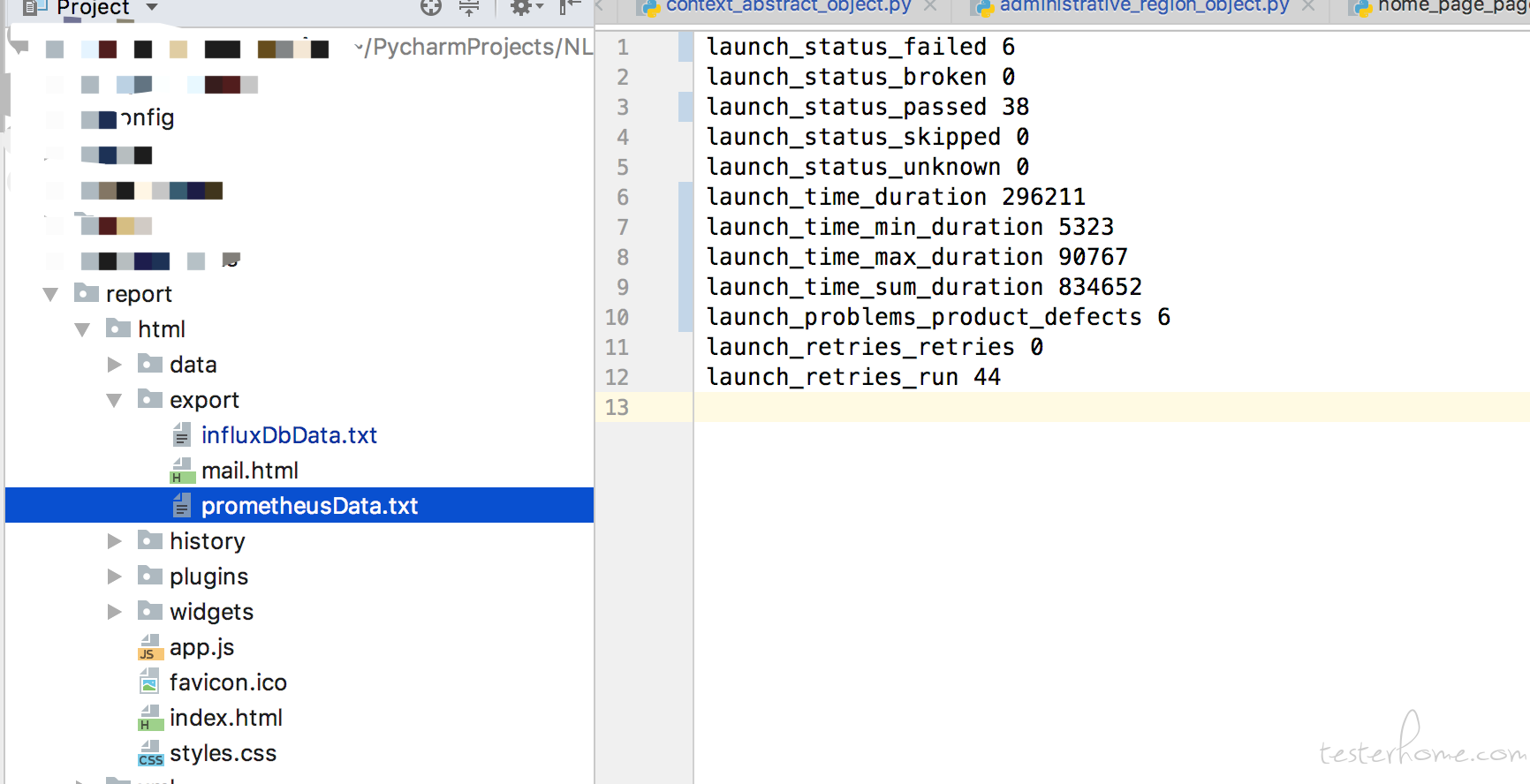
我们主要取 launch_retries_run,launch_status_passed,launch_status_failed 这三个值。
注:html 是 xml 运行 allure 命令生成的,命令如下:
#pytest 运行用例,并指定生成xml报告。
python3 -m pytest -sq -m [pytest.mark.xxx] --reruns 3 -n 3 testcase --alluredir report/xml
# 将xml报告转成html,这步执行完成,就有上图的txt文件了。
allure generate --clean report/html report/xml -o report/html
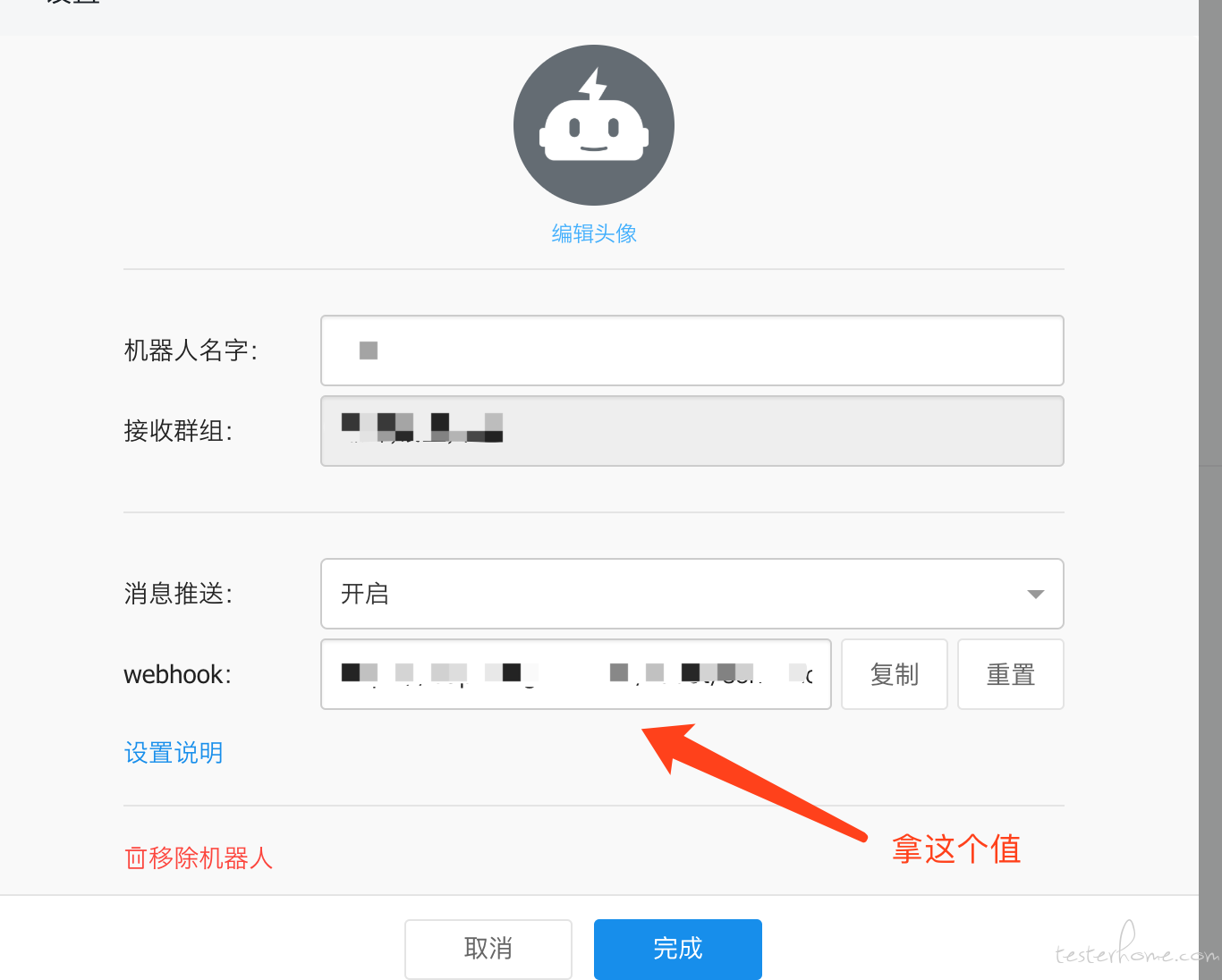
2.钉钉群,新建自定义机器人,并获取它的 webhook,如下图:
3.运行推送脚本,需要的依赖
- os
- jenkins
- json
- urllib3 没有安装就行了。
4.获取 jenkins,运行测试脚本的 job 名称和该 job 最后构建号
这块其实有两种方式实现:
第一种:安装上面 jenkins 库,写脚本登录,使用 job 名称;获取 job 最后构建号码;
第二种:Jenkins 其实每个页面,右下角都有 REST API;

可以按照自己习惯选择,用那种方式获取最后一次构建号;

本文用第一中方式。
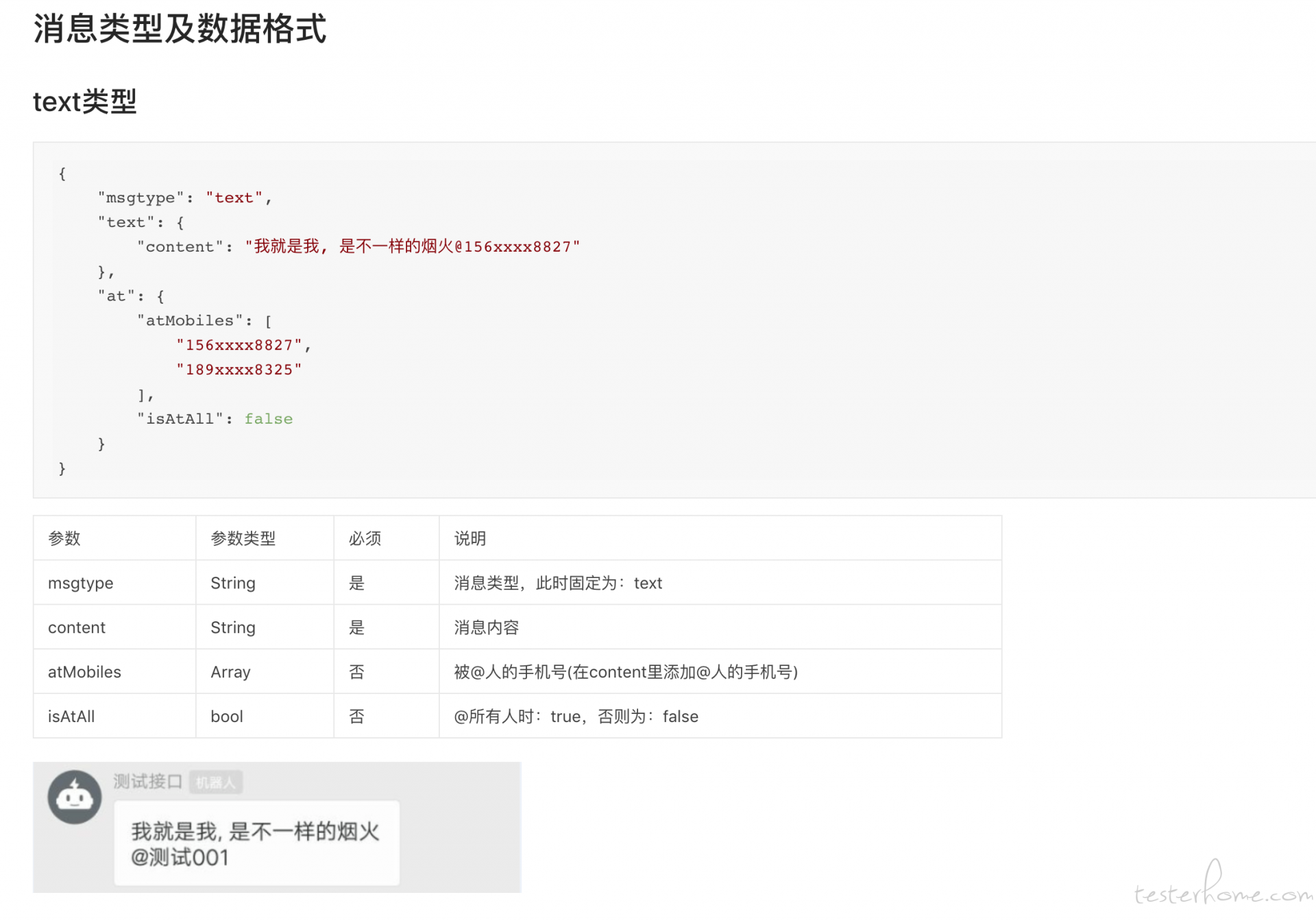
5.确定要使用的钉钉推送接口
钉钉自定义机器人
https://ding-doc.dingtalk.com/doc#/serverapi2/qf2nxq
我们用的 text 类型
编写推送钉钉的代码
一切就绪,该写代码了,代码如下:
# !/usr/bin/env python3
#coding=utf-8
import os,jenkins,json,urllib3
'''
获取jenkins构建信息和本次报告地址;
'''
jenkins_url="xxxxxxx" #jenkins登录地址
server = jenkins.Jenkins(jenkins_url, username='xxxx', password='xxxx')
# print(server.jobs_count())
job_name="job/xxxxxxx/" # job名称
job_url=jenkins_url+job_name # job的url地址
job_last_number=server.get_info(job_name)['lastBuild']['number'] # 获取最后一次构建
# print(job_last_number)
# print(job_url)
report_url=job_url+str(job_last_number)+'/allure' # 报告地址
# print(report_url)
'''
钉钉推送方法:
读取report文件中"prometheusData.txt",循环遍历获取需要的值。
使用钉钉机器人的接口,拼接后推送text
'''
def dd_test_group():
d = {}
proDir = os.path.abspath(os.path.dirname((__file__)))
f = open(proDir + '/report/html/export/prometheusData.txt', 'r')
for lines in f:
# lines.strip('\n').replace(' ', '').replace('、', '/').replace('?', '').split(' ')
for c in lines:
launch_name = lines.strip('\n').split(' ')[0]
num = lines.strip('\n').split(' ')[1]
d.update({launch_name: num})
f.close()
retries_run = d.get('launch_retries_run') # 运行总数
status_passed = d.get('launch_status_passed') # 通过数量
status_failed = d.get('launch_status_failed') # 不通过数量
'''
钉钉推送
'''
url='https://xxxxxxxxxxxxxxxxxxx'#webhook
con={"msgtype":"text",
"text":{"content":"xxxxxxxxxx自动化脚本执行完成。\n测试概述:\n运行总数:"+retries_run+"\n通过数量:"+status_passed+"\n失败数量:"+status_failed+"\n构建地址:\n"+job_url+"\n报告地址:\n"+report_url}
}
urllib3.disable_warnings()
http = urllib3.PoolManager()
jd=json.dumps(con)
jd=bytes(jd,'utf-8')
http.request('POST',url,body=jd,headers={'Content-Type':'application/json'})
if __name__ == '__main__':
dd_test_group()
jenkins 构建运行脚本
要求:执行脚本后,如果存在失败的用例,才推送。
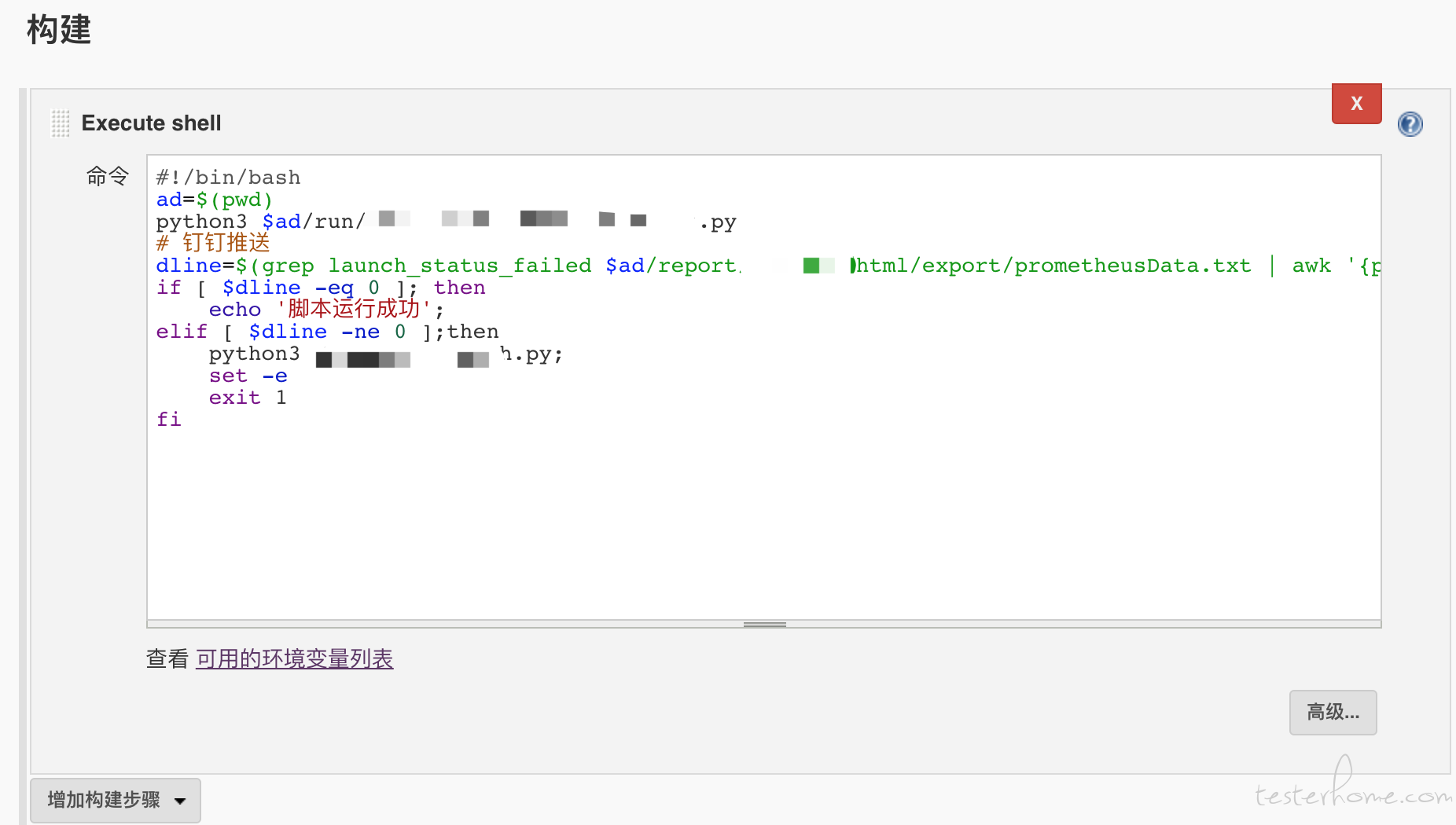
#!/bin/bash
ad=$(pwd)
python3 $ad/[此文件运行注释的测试脚本].py
# 钉钉推送
dline=$(grep launch_status_failed $ad/report/xxxxx/html/export/prometheusData.txt | awk '{print $2}')
if [ $dline -eq 0 ]; then
echo '脚本运行成功';
elif [ $dline -ne 0 ];then
python3 [钉钉推送的脚本文件].py;
set -e
exit 1
fi
结语
其实用 jenkins 的 REST API 的方式做,也挺不错的;之后会写用此方式获取(java+junit+allure)。结合 Jenkins,完成钉钉推送 (java+junit+allure)
「原创声明:保留所有权利,禁止转载」
如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!