1.引言
如果做自动化的同学应该有这样的感受,测试 case 多,单进程执行测试用例,速度慢,执行时间长。这个时候我们可以引入多进程、多线程去执行测试用例。
又比如说,我们有时候我们在可以使用 Python 或者 java 对服务端进行压测的时候,单进程只能模拟单个用户的行为,我们采用多线程、多进程去压测也是可以的。
2.正文
2.1 进程与线程
进程(英语:process),是指计算机中已运行的程序。你可以理解成一个任务就是一个进程,比如打开浏览器,启动音乐播放器等。
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在 Unix System V 及 SunOS 中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。
1.随着多核处理器主见成为主流而非特例,与以前相比,将处理在和分布到多台处理器上 (以便充分利用所有可用的处理器资源) 变得更吸引人,也更具有可行性。有两种方法可用对工作和在进行分布:多进程、多线程。
2.使用多进程,也就是运行多个单独的程序,每个进程都是独立运行的,这是的对并发性进行处理的所有任务都是由底层的操作系统完成的。不足之处在于,程序与各单独进程间通讯与数据共享可能不是很方便。在 UNIX 系统上,这可以使用 exec 与 fork 来完成;但是对跨平台程序,就必须使用其他解决方案。最简单的,也是在这里进行展示的,就是由调用程序为其运行的进程提供数据进行处理。一种更灵活的方法是使用网络,并可以极大地简化这种双向通信。当然很多情况下,这种通信并不是必要的——我们只需要从一个负责协调的程序来运行一个或多个其他程序。
3.一种将工作和在分布到独立进程上的替代方法是创建现成话程序,并将工作和在分布到独立的线程上处理。优势在于:通信可以简单地通过共享数据 (前提是要确保共享数据一次只能由一个线程进行存取) 完成,但同时也将并发性管理等任务留给了程序员。
-《python3 程序开发指南第二版》
2.2 多进程
2.2.1 使用多进程模块 subprocess
我们这里学习使用 subprocess 模块进行多进程模块的编写
我们先看下面的一个例子:
child.py
# child.py文件
import sys
import os
import time
input_msg = sys.stdin.read()
msg = '当前获取到的参数:{0},当前进程号:{1}'.format(input_msg, os.getpid())
print(msg) # 子进程是标准输出不能直接在控制台看到
with open(r'./a.txt', 'a+', encoding='utf8') as f:
f.write(msg)
f.write('\n')
time.sleep(1000)
father.py
import subprocess
import sys
import os
child_path = os.path.join(os.path.dirname(__file__), 'child.py')
command = [sys.executable, child_path] # sys.execcutable就是Python命令的路径
pipes = []
n = 0
while n < 5:
# 开启5个进程
pipe = subprocess.Popen(command, stdin=subprocess.PIPE, stdout=subprocess.PIPE)
pipe.stdin.write(str(n).encode('utf8')) # 这里只接受字节串输入,可以查看源码
pipe.stdin.close()
pipes.append(pipe)
n += 1
while pipes:
pipe = pipes.pop()
pipe.wait()
child.py 和 father.py 处于同一目录。
1、我们先看看没有执行前的 python 进程:

2、然后我们启动 father.py
python3 father.py
这时候启动了 child.py 的子进程,我们看看这个时候的我们获取到参数的日志文件
日志文件:

当前进程:

日志和进程对比:

3、由于子进程,我们把每个进程挂了 10 分钟,我们可以看看,我们强制结束主进程的情况
我们看看执行的情况:可以看到并没有子进程的标准输出
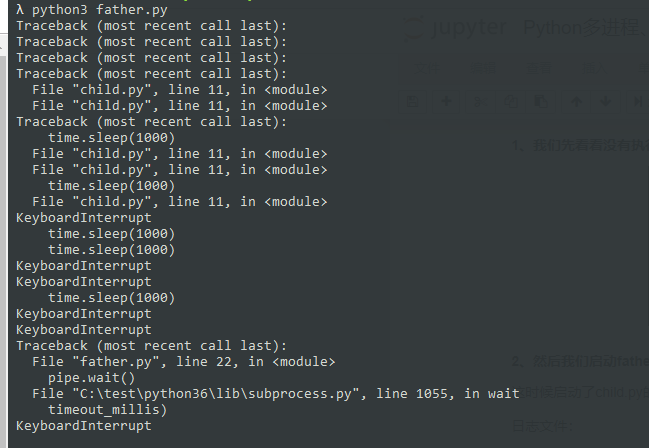
由于我们在主进程中使用 wait(),因此所有子进程结束后,主进程继续往下走;若主进程被中断,所有子进程也中断。

所有子进程均停止了。我们这里未标明主进程的进程号,有兴趣的朋友可以自己看看
总结:可以看到主进程启动了子进程,子进程的标准输出不能在控制台看到(如果需要看到子进程的数据,可以通过获取子进程的输出来查看);主进程将每个子进程进行了 wait() 操作,可以使得主进程的继续需要子进程全部结束才会继续,且主进程的中断会使得子进程全部中断。如果子进程需要看到输出结果的话,可以采用子进程输出日志进行监控进程数据。
我们看下主进程获取子进程的标准输出这个代码
while pipes:
pipe = pipes.pop()
out = pipe.stdout
for line in out:
print(line.decode('utf8'))
print(time.time())
pipe.wait()
你试试这个代码呢?这个获取到的日志会在所有子程序全部结束后打印。可以尝试下获取到实时的日志。
2.2.2 使用多进程模块 multiprocessing
在 UNIX 系统上提供了 fork() 的系统调用,这个函数非常特殊。fork() 可以将当前进程 (父进程) 复制一份作为子进程。但是对于跨平台的,就需要选择其他的解决方案了。
Process
process.py
import multiprocessing
import os
import time
def run_case(*text):
print('入参:{0},当前进程号:{1}'.format(text, os.getpid()))
time.sleep(100)
if __name__ == '__main__': # windows必须使用这句话,不要问我为什么,我也不知道
print('当前是父进程,进程号:{0}'.format(os.getpid()))
child = multiprocessing.Process(target=run_case, args=(1,2,))
print('子进程启动')
child.start()
child.join()
print('进程结束')
我们运行这个程序,看看效果
启动前的进程:

启动后的进程:

主进程启动的控制台的输出:

主进程结束后,子进程也结束了。因为我们使用了 join(),这里会等待子进程结束后再继续执行主进程。
Pool
进程池:定义了一个池子,在里面放上固定数量的进程,有需求来了,就拿这个池中的一个进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。如果有许多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。
pool.py
import multiprocessing
import os
import time
def run_case(*text):
print('入参:{0},当前进程号:{1}'.format(text, os.getpid()))
time.sleep(1)
if __name__ == '__main__':
pool_num = multiprocessing.Pool(4)
print('主进程:{0}'.format(os.getpid()))
print('子进程开始咯')
for i in range(20):
pool_num.apply_async(run_case, args=(i,))
pool_num.close()
pool_num.join()
print('子进程结束了')
print('主进程结束了')
这里我们直接看控制台输出:

发现了吗?子进程只启动了 4 个,然后这个 4 个进程结束了,这 4 个进程的进程号没有变化?看到了吗
总结:进程池的优势在于不会立即销毁进程,不会重新启动新的进程。效率更高。
2.2.3 进程间通讯
我们知道进程是独立的,多进程和多线程的最大的不同就在于,多线程共享同样的变量;但对于多进程而言,进程间的变量是独立的。
multiprocess 进程间通讯
进程间需要通讯的话,可以使用 multiprocess 的 Queue 进行通讯。可以参照廖雪峰的教程学习。
multiprocess_queue.py
import multiprocessing
import os
class A:
def __init__(self, num):
self.num = num
pass
def get(self):
return self.num
one = A(1)
two = A(2)
def put_msg(que):
print('写数据,我的进程号是{0}'.format(os.getpid()))
for i in [one, two]:
que.put(i)
def get_msg(que):
print('读数据,我的进程号是{0}'.format(os.getpid()))
while True:
msg = que.get()
print('{0}拿到的数据:{1}'.format(os.getpid(), msg.get()))
if __name__ == '__main__':
print('当前是父进程,进程号:{0}'.format(os.getpid()))
queue = multiprocessing.Queue()
child1 = multiprocessing.Process(target=put_msg, args=(queue,))
child2 = multiprocessing.Process(target=get_msg, args=(queue,))
child1.start()
child2.start()
child1.join()
child2.terminate() # 因为死循环,需要终止
print('子进程启动')
print('进程结束')
subprocess 进程间通讯
subprocess 可以看到一般都是由一个父进程,控制其他的子进程的运行;相对而言,进程间的通讯变得更加简单;可以通过父进程去向子进程入参,收集子进程输出去进行通讯。但是如果有些变量、对象不能通过日志展现的话,通讯会不便利,还有什么更好的办法,笔者现在还没有想到。
2.3 多线程
多线程是共享数据的,因此要注意,且注意死锁。
我们看个例子
import threading
import time
start = time.time()
n = 10
tlock = threading.Lock()
def child():
global n
i = 1000000
while i > 0:
i -= 1
n += 1
n -= 1
t1 = threading.Thread(target=child)
t2 = threading.Thread(target=child)
t3 = threading.Thread(target=child)
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
end = time.time()
print(n)
print('消耗的时间为{0}秒'.format(end-start)) # 消耗了1.18s
控制台输出结果可能不为 10,笔者这里输出的结果为 14、18 之类的。这个例子说明是什么,线程间共享了同一个变量,这种问题就需要我们加锁,当 n 这个变量被线程 1 占用的时候,线程 2、3 等待锁的释放再继续。
那我们应该怎么解决这个多线程的问题导致多线程均对变量进行处理的情况呢?加锁!Z
'''
import threading
n = 10
def child():
global n
i = 1000000
while i > 0:
n += 1
n -= 1
i -= 1
t1 = threading.Thread(target=child)
t2 = threading.Thread(target=child)
t3 = threading.Thread(target=child)
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(n)
'''
import threading
import time
start = time.time()
n = 10
tlock = threading.Lock()
def child():
global n
i = 1000000
while i > 0:
i -= 1
tlock.acquire()
try:
n += 1
n -= 1
finally:
tlock.release()
t1 = threading.Thread(target=child)
t2 = threading.Thread(target=child)
t3 = threading.Thread(target=child)
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
end = time.time()
print(n)
print('消耗的时间为{0}秒'.format(end-start)) # 消耗了14秒
这样的执行结果是 10,因为每次在执行 n 的加减法的时候,加了锁,任何线程在执行加减的时候,如果别的线程没有释放锁的话则无法继续执行,需要等待锁的释放才能继续执行。但是对比消耗的时间,加锁的时间远大于不加锁的时间消耗。锁确保了当关键代码执行的时候只能由一个线程执行完成后,下个线程才能继续拿到锁继续执行,缺点就是组织了多线程并发执行,锁内的代码执行是以单线程执行的。我们这里只加了一个锁,如果多个锁的话,可能造成多个线程争取锁,导致死锁,线程挂起无法继续执行。
2.3.1GIL
关于 GIL,先看一个例子
import threading
def thread():
m = 10
while True: # 死循环
m += 1
m -= 1
if __name__ == '__main__':
for i in range(10):
t = threading.Thread(target=thread)
t.start()
我们看看资源占用情况,我们开了 10 个进程,为什么这个进程没有占满所有 cpu 的使用呢 (笔主的电脑是 4 核的 i5 处理器)。因为这是由于 GIL 的存在的原因。

GIL(全局解释锁) 其实并是不 Python 的问题,而是 CPython 解释器的原因。
任何 Python 线程执行前,必须要会的 GIL 锁,然后每执行 100 条字节码,解释器就会释放 GIL 锁,让别的线程有机会执行。这个 GIL 全局锁实际上把所有线程执行的代码上了锁,所以,多线程是在 Python 中交替执行,即使 100 个线程跑在 100 核 CPU 上,也只能用到一个核。 -- 摘自《廖雪峰网站》
2.3.2 多线程的调用方法
每个 Python 程序至少都有一个线程,即主线程。要创建更多的线程,必须导入 threading 模块,并用其创建我们所需数量的额外线程。要创建线程,有 2 种方法:
1、调用 threading.Thread(),并向其传递一个可调用的对象;2、创建 threading.Thread 类的子类。子类化是最灵活的方法,并且也是很直接的。子类可以重新实现__init__() 方法(这种情况下,必须调用基类的实现),并且重新实现 run() 方法——进程的工作就是在这个方法中完成的。要注意的是,我们的代码绝不要调用 run() 方法——线程是通过调用 start() 方法启动的,该方法内部会在适当的时候调用 run() 方法。
第 1 种方法这里不再详述,前面已经已经有详细的例子了。这里我们讲解一种 threading.Thread 子类的调用方式:
守护线程
import threading
import time
def a():
time.sleep(2)
print('正在执行程序:a')
def b():
time.sleep(5)
print('正在执行程序:b')
t1 = threading.Thread(target=a)
t2 = threading.Thread(target=b)
t2.daemon = True # 守护线程守护的是非守护线程,其他非守护线程执行完成执行
t1.start()
t2.start()
print('当前是主线程')
当前是主线程
正在执行程序:a
t2 作为守护线程,我们可以看到 b 的线程还没有执行完成,守护线程是为了保证非守护线程执行完成。守护线程是为了其他非守护线程。非守护线程运行完毕,守护线程结束。守护线程有种牺牲者的大无畏精神哈哈哈。还有就是关于线程中看到的 t2.join() 的方法是为了等待子线程执行完毕再继续执行主线程。
import threading
from queue import Queue
class Thread2(threading.Thread):
def __init__(self, workers):
super().__init__()
self.workers = workers
def run(self):
while True:
worker = self.workers.get()
print('get的数据:{0}'.format(worker))
self.workers.task_done()
q = Queue()
t = Thread2(q)
t.daemon = True # 守护线程
t.start()
for i in range(20):
q.put(i) # put一个,子线程就开始消费
q.join() # queue.join()一般和task_down()是一对儿,join表示任务未完成挂起;task_down()则会阻塞join()
print('结束了')
这个例子很有意思,主线程一边生产(写队列),子线程一边消费 (读队列)。当队列挂起 join() 的时候,主线程被阻塞,当队列被消费完成后,join() 阻塞失效,继续执行主线程的代码。
3.总结
多线程的通讯相对于多进程来说是比较轻松的,比如使用 queue 队列进行通讯,但是多线程由于 Cpython 解释器的原因很难调度起多个处理器,多线程由于内存是共享的,因此一旦一个线程出现问题,可能整个进程都会崩溃;多进程创建进程的消耗会较长 (参考进程池 Pool),且计算机同时调度的进程数是有限制的 (受到内存和 CPU 等因素的影响)。因此在选择多线程、多进程的时候,需要多考虑应用场景。