专栏文章 一次 JVM 内存泄漏排查过程
背景
近期发现一个 java 进程内存占用久高不下,重启后恢复,一段时间后又复现。
排查过程
1. 通过 top 命令找到内存占用最高进程的 ID;
2. 通过 ps 命令找到程序启动命令行
java
-Xms1024m
-Xmx1024m
-XX:NewSize=256m
-XX:MaxNewSize=256m
-XX:PermSize=64m
// 设置持久代最大值
-XX:MaxPermSize=128m
// 使用 CMS 内存收集
-XX:+UseConcMarkSweepGC
// 降低标记停顿
-XX:+CMSParallelRemarkEnabled
// 在 FULL GC 的时候, 对年老代的压缩, CMS 是不会移动内存的,
// 因此, 这个非常容易产生碎片, 导致内存不够用, 所以, 内存的压缩这个时候就会被启用。
// 增加这个参数是个好习惯。可能会影响性能,但是可以消除碎片
-XX:+UseCMSCompactAtFullCollection
// 内存页的大小不可设置过大, 会影响 Perm 的大小
-XX:LargePageSizeInBytes=128m
// 原始类型的快速优化
-XX:+UseFastAccessorMethods
// 使用手动定义初始化定义开始 CMS 收集,禁止 hostspot 自行触发 CMS GC
-XX:+UseCMSInitiatingOccupancyOnly
// 使用 cms 作为垃圾回收使用 70%后开始 CMS 收集
-XX:CMSInitiatingOccupancyFraction=70
// 调试使用,gc 日志输出的相关参数
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintHeapAtGC
-Xloggc:gc.log
-server -jar XXXXX-jar-with-dependencies.jar production
3. 在命令行中加上 gc 日志输出的参数(如上图中橙色部分)
4. 通过 gc 日志,查看 GC 效果,各个代的内存变化规律:
前期 Minor GC 较为频繁,老年代和永久带内存占用不断增加,直到触发 CMS,且老年代与永久代的内存占用没有明显的减少。
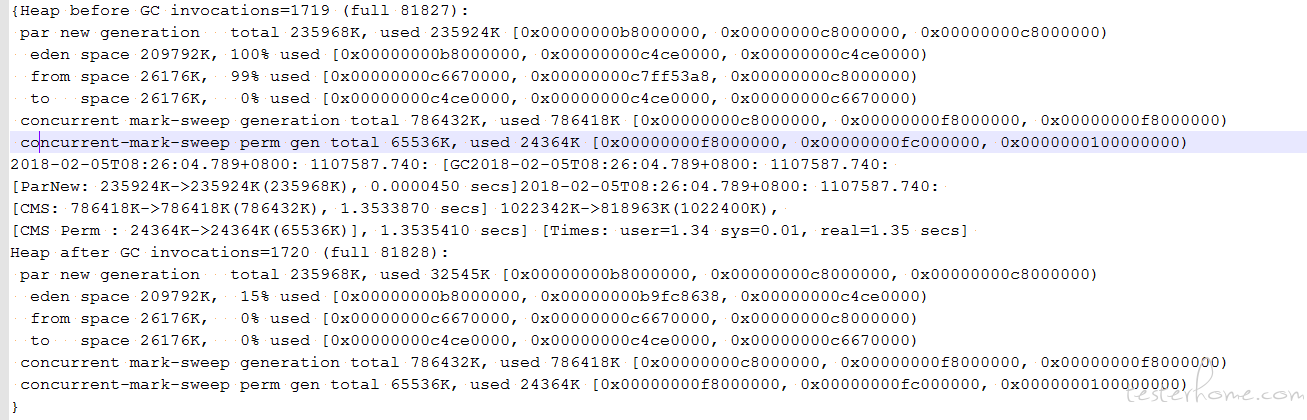
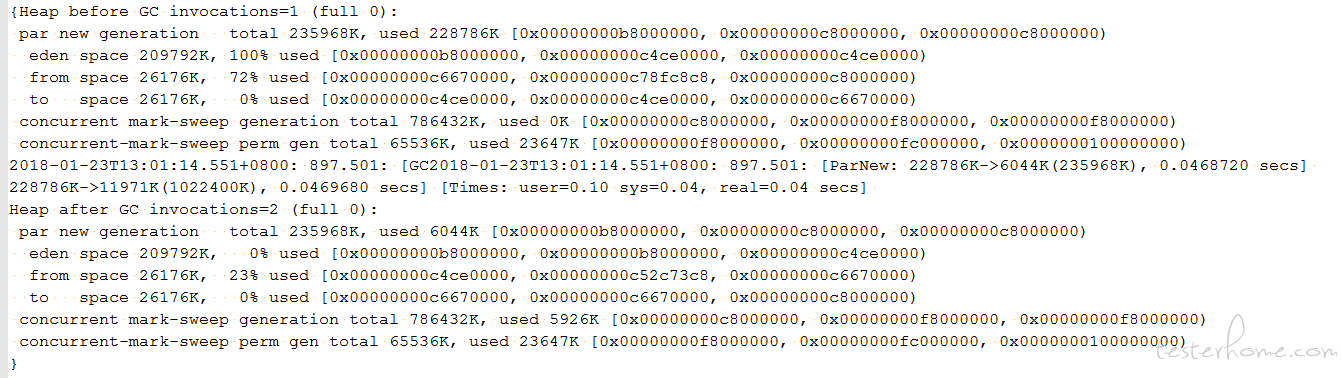
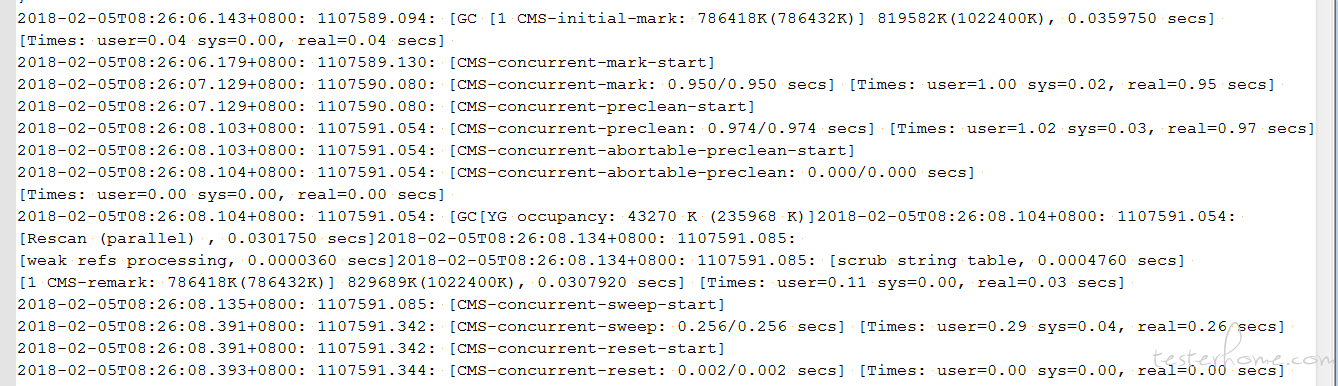
初步诊断:
有对象没有正常被回收。
5. 通过 jmap 命令,查看进程堆栈中对象的分布:
/**
- 3296 是进程 id
- > test-jmap.txt 将 jmap 命令的结果重定向至 test-jmap.txt
- 找出进程所有对象 */ jmap -histo 3296 > test-jmap.txt
/**
- 找出进程中目前还 live 的对象
*/
jmap -histo:live 3296 > test-jmap.txt
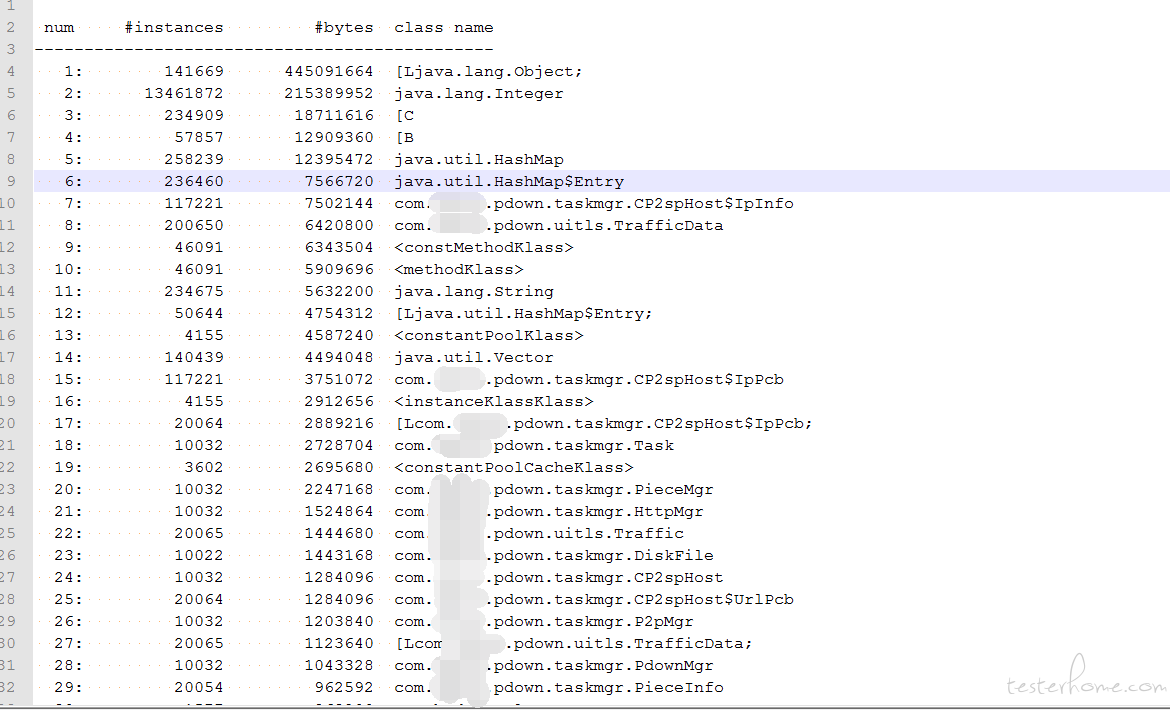 如图中显示:包名 pdown 的对象大量出现,怀疑是该包内某个对象内存泄漏;
pdown 是第三方提供的 jar 包,通过 jd-gui 反编译工具,排查代码发现其中一个 Task 对象在每次创建后放入队列,只有在 unInit 时,才会移除,且该队列属于一个常量对象,所以基本判定是由于 jar 包使用过程中未调用该 api 导致本次内存泄漏,从而 GC 频繁。
如图中显示:包名 pdown 的对象大量出现,怀疑是该包内某个对象内存泄漏;
pdown 是第三方提供的 jar 包,通过 jd-gui 反编译工具,排查代码发现其中一个 Task 对象在每次创建后放入队列,只有在 unInit 时,才会移除,且该队列属于一个常量对象,所以基本判定是由于 jar 包使用过程中未调用该 api 导致本次内存泄漏,从而 GC 频繁。
6. 修改程序代码,加上 pdown 的 unInit 后,该问题解决。
总结:
1. 什么样的 java 对象可以被回收?
java 使用可达性分析的方式,从 GC root 开始,根据引用关系遍历,所经过的路径形成一棵引用树,没有挂在这棵树上的对象,为不可达对象,可以被回收。
GC root 包括:

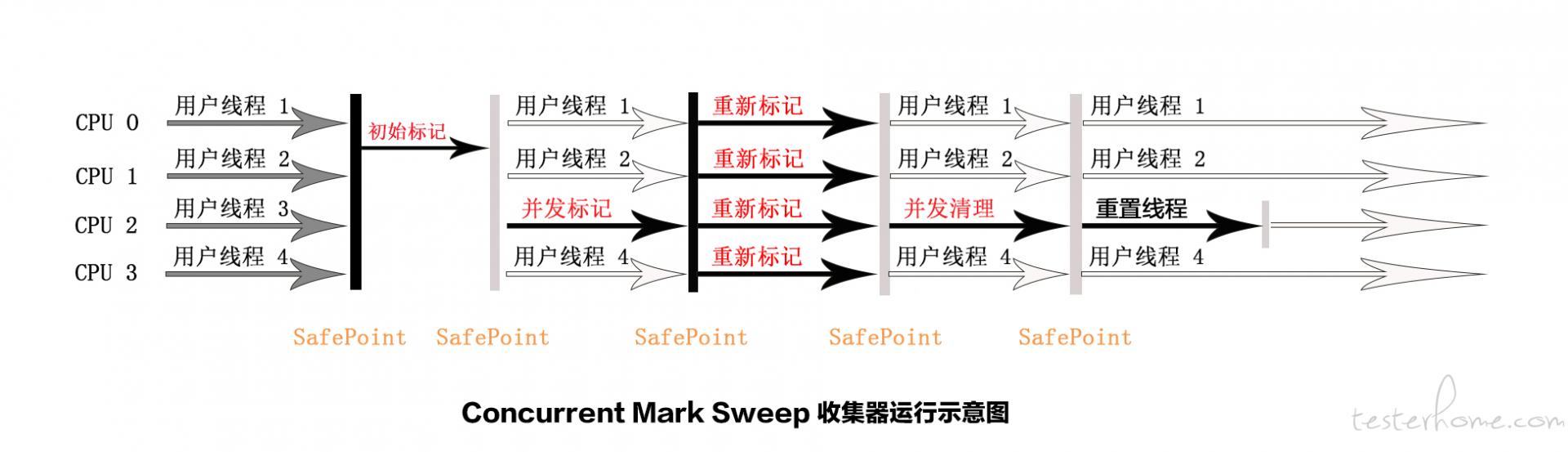
2. CMS(Concurrent Mark Sweep) 收集器:
特点:
针对老年代
标记 - 清除算法 (不进行压缩操作,产生内存碎片)
并发
多线程
收集过程中不需要暂停用户线程
以获取最短回收停顿时间为目标
应用场景:
ParNew + CMS + Serial Old(Concurrent Mode Failure 后备预案)
与用户交互较多的场景。例如:互联网或者 B/S 系统的服务端
参数:
-XX:+UseConcMarkSweepGC:使用 CMS 收集器
-XX:+ UseCMSCompactAtFullCollection:Full GC 后,进行一次碎片整理;整理过程是独占的,会引起停顿时间变长
-XX:+CMSFullGCsBeforeCompaction:设置进行几次 Full GC 后,进行一次碎片整理
-XX:ParallelCMSThreads:设定 CMS 的线程数量(一般情况约等于可用 CPU 数量)
缺点:
对 CPU 资源非常敏感
浮动垃圾
"Concurrent Mode Failure"失败
内存碎片