前言
前一段时间(很久之前了😳)弄了 sonarQube 以及如何开发自定义规则,在之前一直也没有去接触过。于是兴致勃勃的到网上一顿搜索的骚操作,本地的 sonarQube 就搭建好了,并且通过 sonar 自带的规则扫描自己的项目发现了一些问题。就在我准备更进一步去学习如何进行自定义规则开发的时候,碰坑了。。。
在网上查了很多关于 sonar 自定义规则开发的资料,其内容都大同小异,介绍如何搭建 sonarQube 环境几乎占了 80% 或者更高,仅仅少数是进行最简单的开发环境 demo 介绍(其中包括如何创建规则,以及规则的一些相应配置), 但对于更深入的如何去开发一个规则以及内部原理的文章比较少(可能关键词不当),于是乎。。。为了记录学习的过程便有了这篇文章,希望对于初入学习sonar 自定义规则开发的小伙伴有一定的帮助。
深入了解sonar自定义规则开发
小白阶段
当我第一次看到 sonar 规则,一脸懵逼。。。基于有一定的编程能力,通过规则对应的单元测试进行一步步的 debug 调试(当时每个方法里面都被我打上了断点┑( ̄▽  ̄)┍)
在一步步的调试下,终于大致看懂了一个规则的数据流向,于是撸起袖子准备开始敲自己的代码,刚打完规则名后就卡住了。。。因为原来代码里面的各种 nodesToVisit、 visitNode 方法都没弄清楚为什么要这么写,更不知道该从哪里开始。于是又重新开始 ( ̄﹏ ̄)。
进阶 ing
直接拿 sonar 规则官网 的BadMethodNameCheck规则进行后面的解释,我们就根据 debug 的路径一步步开始讲解。
-
Test JavaCheckVerifier.verify ("sonar 前置")
@Test public void test() { JavaCheckVerifier.verify("src/test/files/checks/naming/BadMethodName.java", new BadMethodNameCheck()); }在上面的代码中,测试用例里面调用了类JavaCheckVerifier的verify方法,传入一个文件路径(需要被扫描的测试代码)以及一个 BadMethodNameCheck对象(自定义的规则),那么里面具体做了什么呢?接着看下面在这个过程中的简略版流程图。
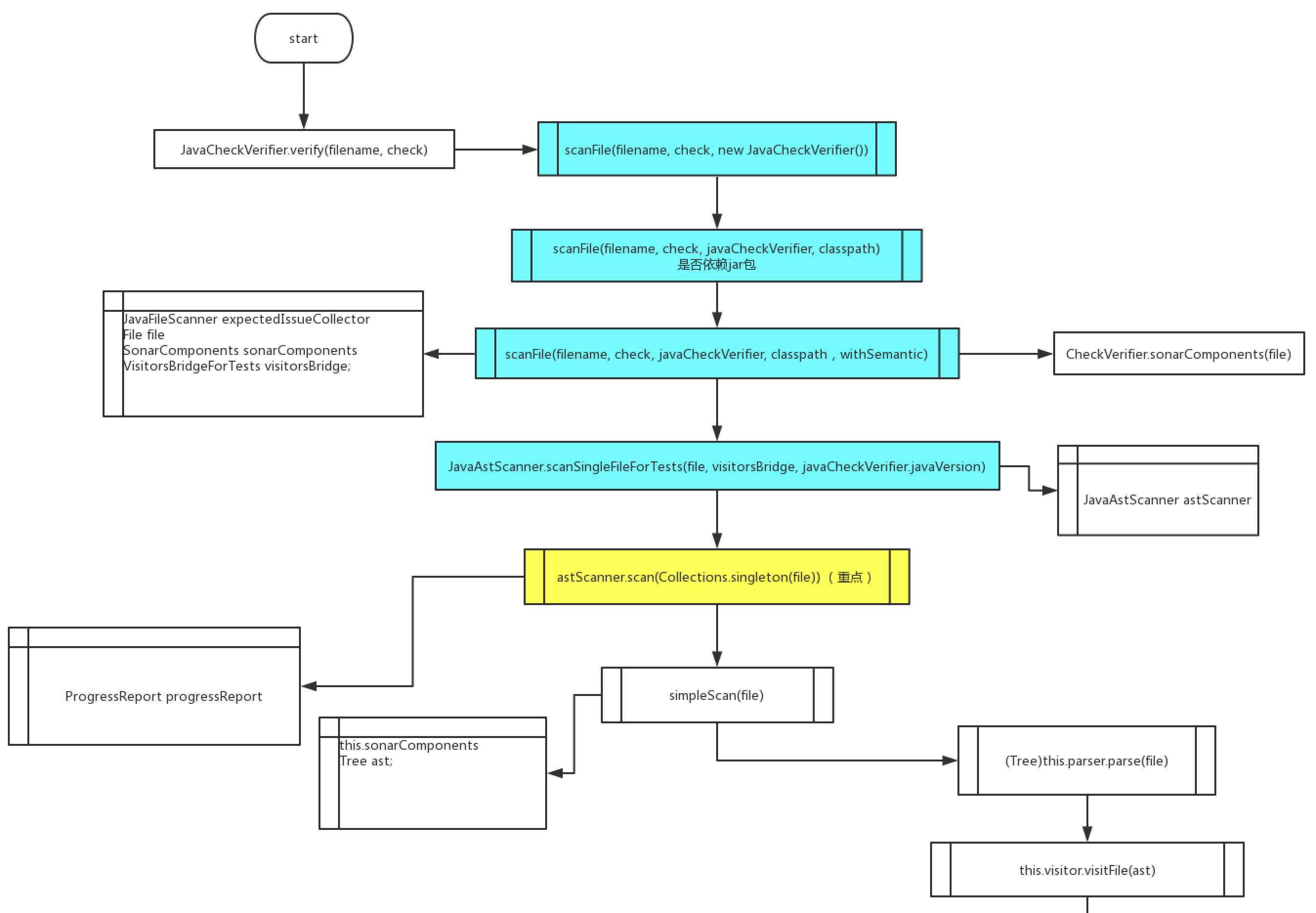
传入了文件以及规则后,sonar 内部进行了一系列的 scanFile 操作,大多数是进行一些前置准备。其中对理解比较重要的是 visitorsBridge、astScanner、ast 等对象。
-
visitorsBridge 对象
用于保存通过规则对被测代码扫描后的结果
-
astScanner 对象
提供扫描被测代码的解析功能并生成抽象语法树--Tree ast对象。
简单的来说,在这一阶段就是进行各种初始化,生成保存结果集的变量,并且将被测代码解析为抽象语法树。
通过维基上定义的 抽象语法树,这里就不多介绍了, 也可以通过 Idea 下载插件 JDT AST 工具 (可能需要 ***) 生成抽象语法树帮助理解。知道了什么是语法树后,基本上自定义开发规则的进展就完成了 50%。(但实际 sonar 生成的语法树在格式上与 JDT 生成的会不太一致,使用时候需要注意下)
下面是我们的被扫描代码内容(为了内容简短,删除了部分代码):
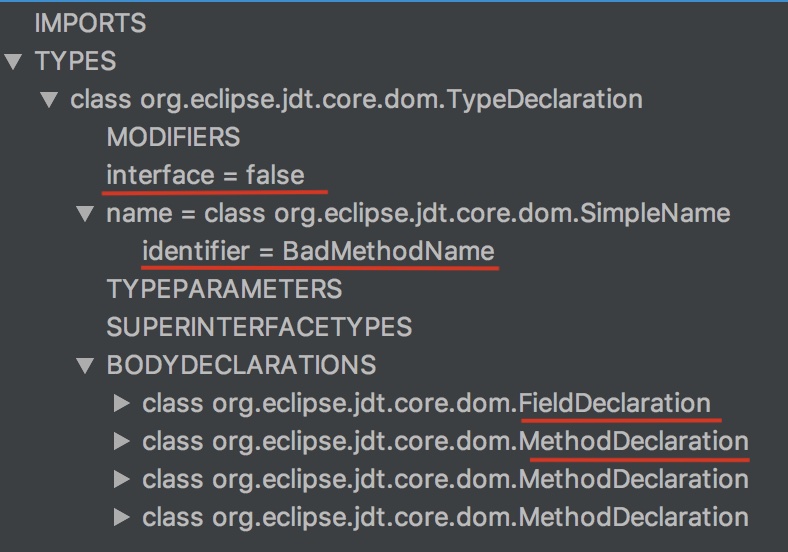
class BadMethodName { private String id; public BadMethodName() {} void Bad() { // Noncompliant [[sc=8;ec=11]] {{Rename this method name to match the regular expression '^[a-z][a-zA-Z0-9]*$'.}} } void good(String id) { System.out.println("Test"); } }通过 AST 工具生成的抽象语法树
全局的语法树如下:可以获取代码中的该类是否是接口、类名以及类中定义的类变量以及方法。
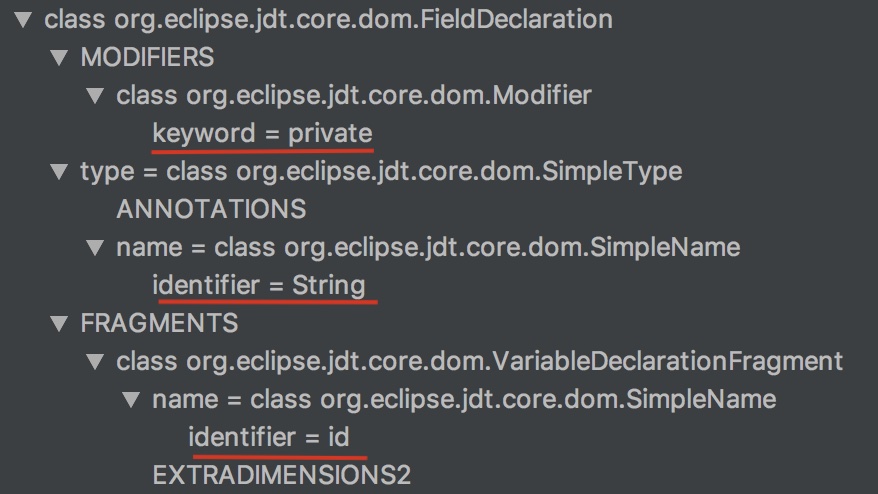
针对类变量的语法树如下:可以获取到变量名称、类型、修饰类型。
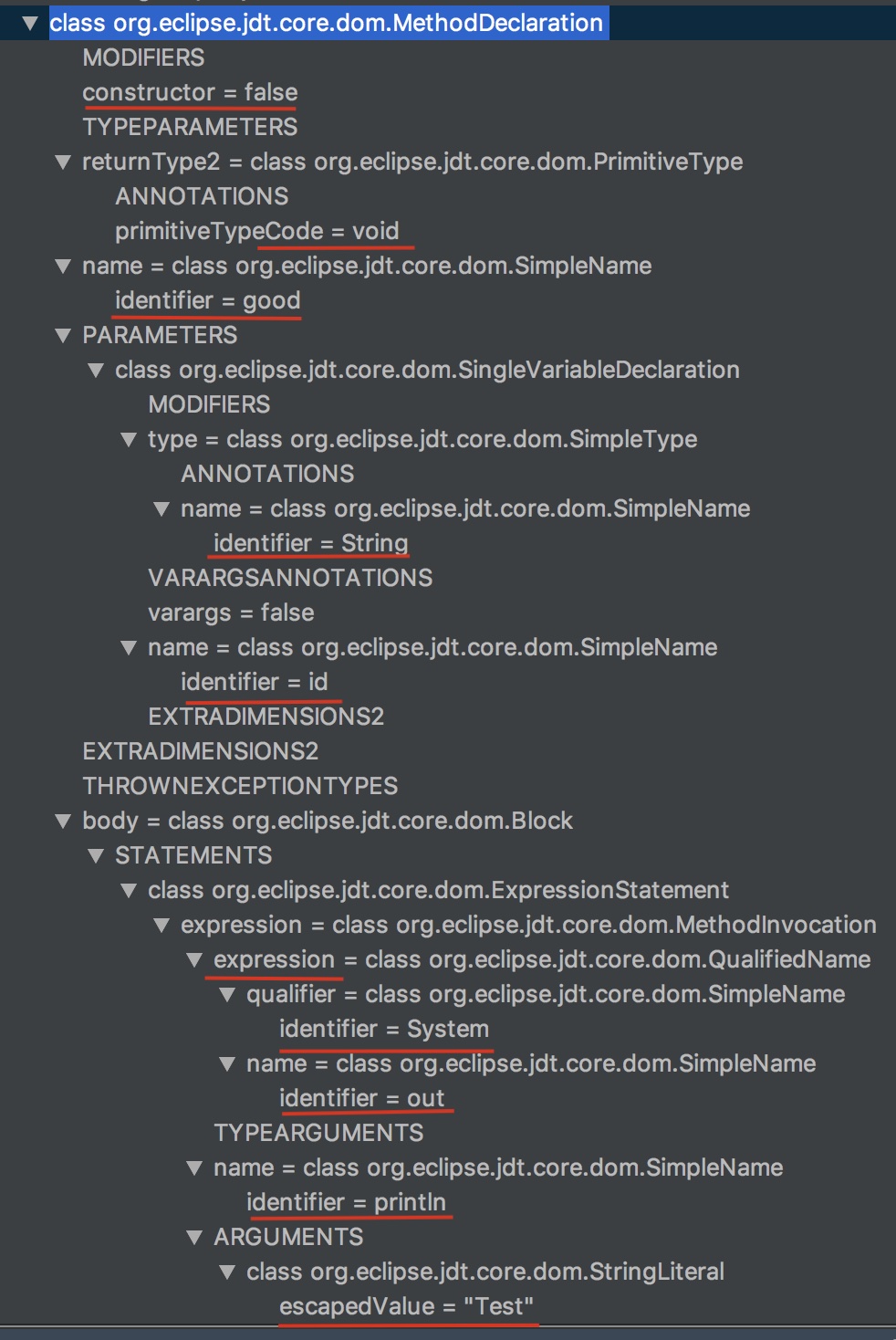
针对方法生成的语法树如下:可以获取到方法名、返回值、修饰符、是否是构造函数和代码块,所有在 { code } 内的又会被解析成一个blockTree。
所以,通过 sonar 的前置操作解析后,我们就拿到了一套标准化的语法树。
-
-
用户代码
自定义规则开发的大致思路就是通过过滤顶层 Tree 拿到想要的节点 Tree(如MethodTree、ClassTree、BlockTree、ExpressionStatementTree等),然后根据自己开发逻辑代码实现校验功能。现在来说明下前面说到的 sonar 在用户代码里面常用的一些内部方法。
-
nodesToVisit()
public List<Tree.Kind> nodesToVisit() { return ImmutableList.of(Tree.Kind.METHOD); }指定要扫描的节点 (也就是树的分支),并在 visitNode 方法中获取到指定的节点,像上面代码就是返回Tree中的所有MethodTree。
-
visitNode()
public void visitNode(Tree tree) { MethodTree methodTree = (MethodTree) tree; if (isNotOverriden(methodTree) && pattern.matcher(methodTree.simpleName().name()).matches()) { reportIssue(methodTree.simpleName(), "Rename this method name to match the regular expression '" + format + "'."); } }获取到nodesToVisit中的过滤后的所有节点 Tree,并且按照用户指定的逻辑进行校验。
-
setContext()
public void setContext(JavaFileScannerContext context) { if (pattern == null) { pattern = Pattern.compile(format, Pattern.DOTALL); } super.setContext(context); }super.setContext(context) 获取第一步中初始化的 visitorsBridge 对象,用于存储测试结果。
本阶段的难点就在于如何保证自己的校验代码不出现漏查或者误查,避免出现扫描检测出来的结果有误,这块类似功能实现,具体的实现方式就不细说了
-
-
单测结果校验
reportIssue(methodTree.simpleName(), "Rename this method name to match the regular expression '" + format + "'."); public void reportIssue(Tree tree, String message) { context.reportIssue(this, tree, message); }一般在用户规则中,当触犯规则后需要进行一个错误校验,来看下大致的流程图。
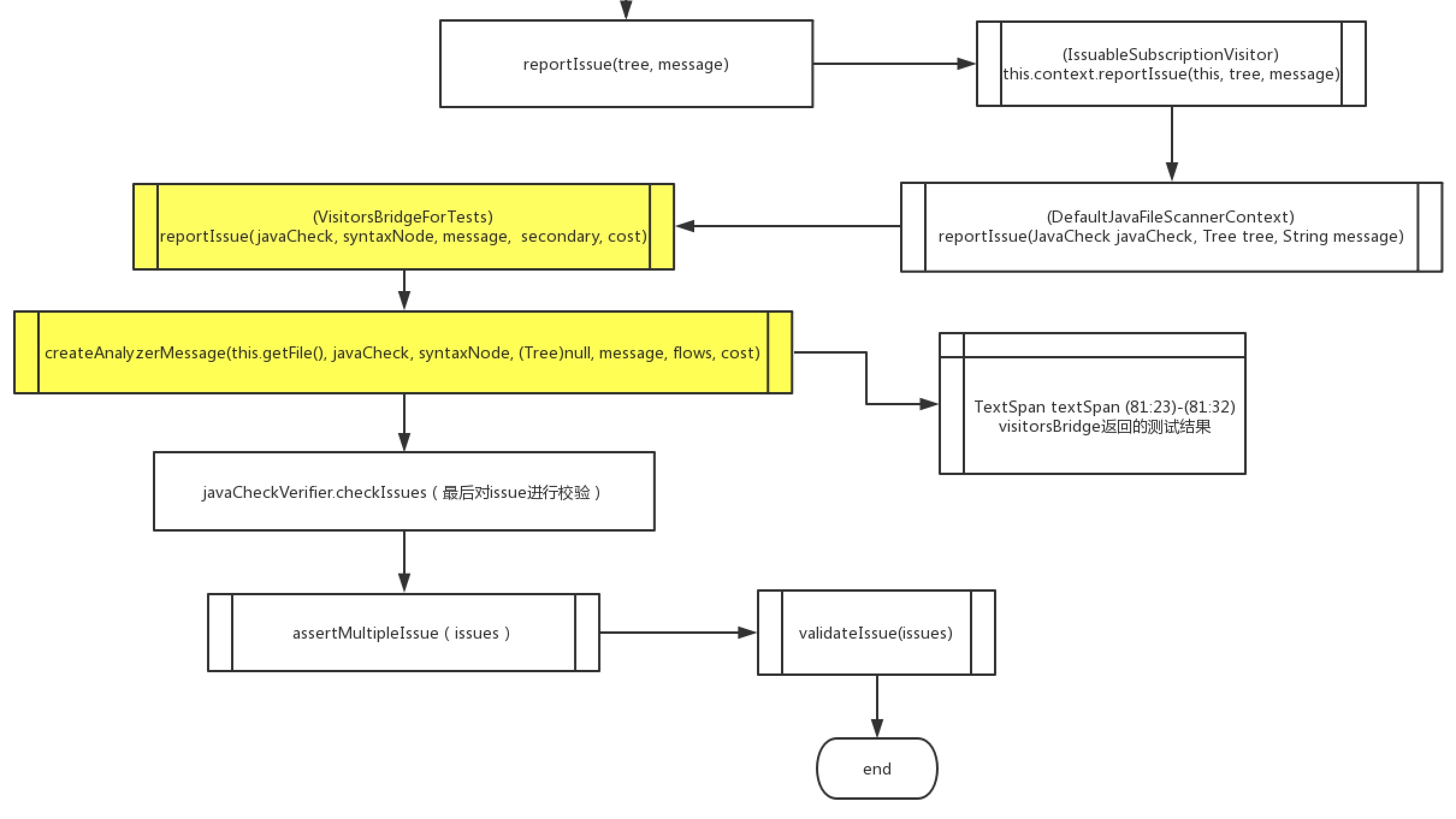
从流程图可以很清楚的发现,开始也是一系列 reportIssues 结果收集,一直到 VistorsBridgeForTests 中才开始进行触发规则的内容解析操作,获取了触犯规则的代码行数以及字符串具体的位置,记录在textSpan变量中,结果保存在issues列表中。
void Bad2() { // Noncompliant通过最初扫描代码记录了标记Noncompliant的行数以及字符串位置为预期值,最后根据CheckVerifer.validateIssue方法进行预期与实际 issues 存储的结果进行比较。至此单测自定义规则的整个流程就结束了。
在结果校验中很容易出一些错误, 大家可能在最初都会遇到,在这里大概说明一下:
-
At least one issue expected
这是通过规则进行文件扫描后,未发现任何一个触发了reportIssue方法,最后的 issues 的长度为 0 导致报错。
-
Expected {3=[{}]}, Unexpected at [11]
预期的标记 Noncompliant 位置的代码行数与实际扫描出来的结果不一致
-
总结
基本上了解了上面的逻辑后,整个 sonar 的自定义规则开发就十分的简单了。后续的深入就是怎么写好用户校验代码,保证校验的结果正确性以及减少误报率。
由于也是自己随意发挥,可能某些细节上有一些偏差,欢迎各位大佬们指正。
个人 blog 原文链接: sonar 自定义规则


