目标网站
http://www.jijitang.com/ # 研究人 UGC 社区
爬取内容
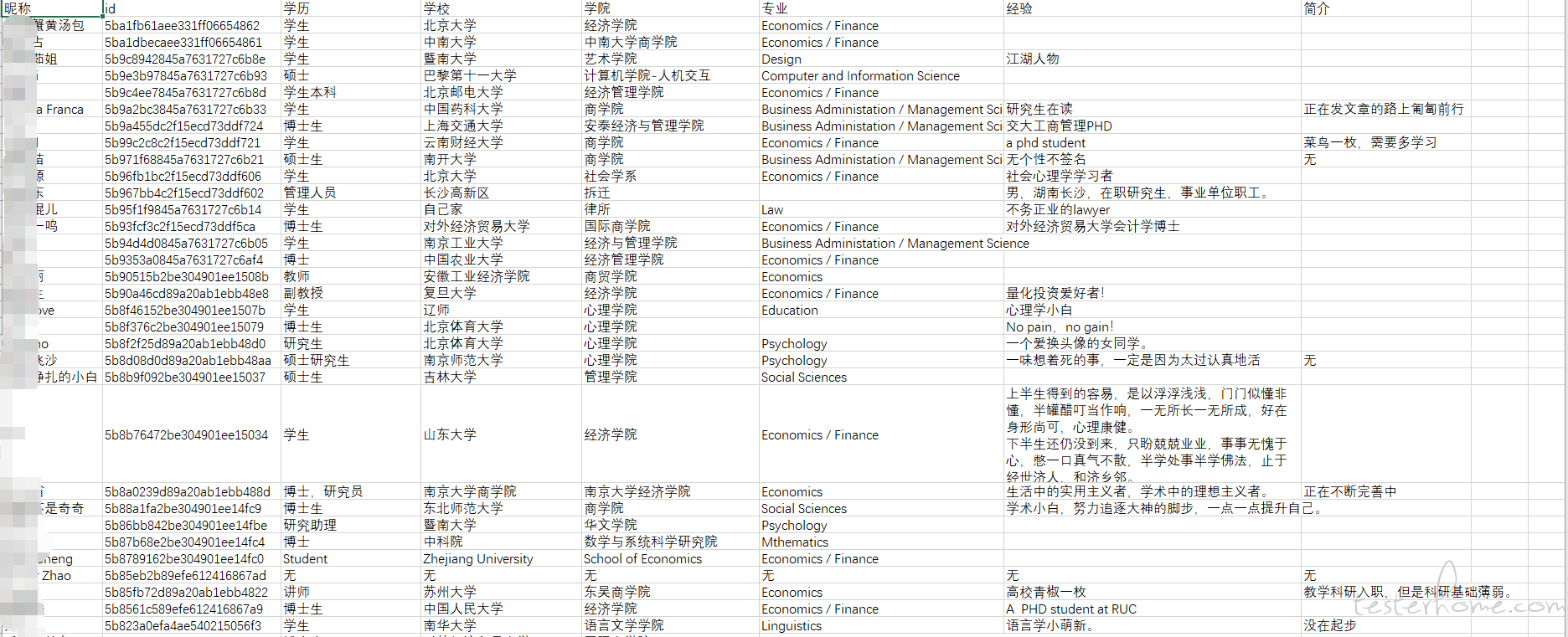
所有研究人的个人信息
网站介绍
唧唧堂是一个从 2012 年开始运营的研究人 UGC 社区,社区用户包括高校的学生、学者、行业研究员等,经过 5 年的积累,社区内已经有 6.5 万高学历、多背景学科的研究人。
唧唧堂创始人 宣悠悠 拥有美国圣塔克拉拉大学信息系统硕士学位,曾在硅谷工作和学习三年,具有超过 6 年的 IT 和互联网工作经验;另一位联合创始人拥有武汉大学金融硕士和学士学位,曾任资产管理公司研究院、金融 IT 上市公司互联网金融产品总监。
完整代码
import requests
import csv
import time
import pymysql
#新建csv文件
csvf = open('jijitang_userdata.csv', 'a+', encoding='utf-8', newline='')
writer = csv.writer(csvf)
writer.writerow(('id','昵称','学历','学校','学院','专业','经验','简介'))
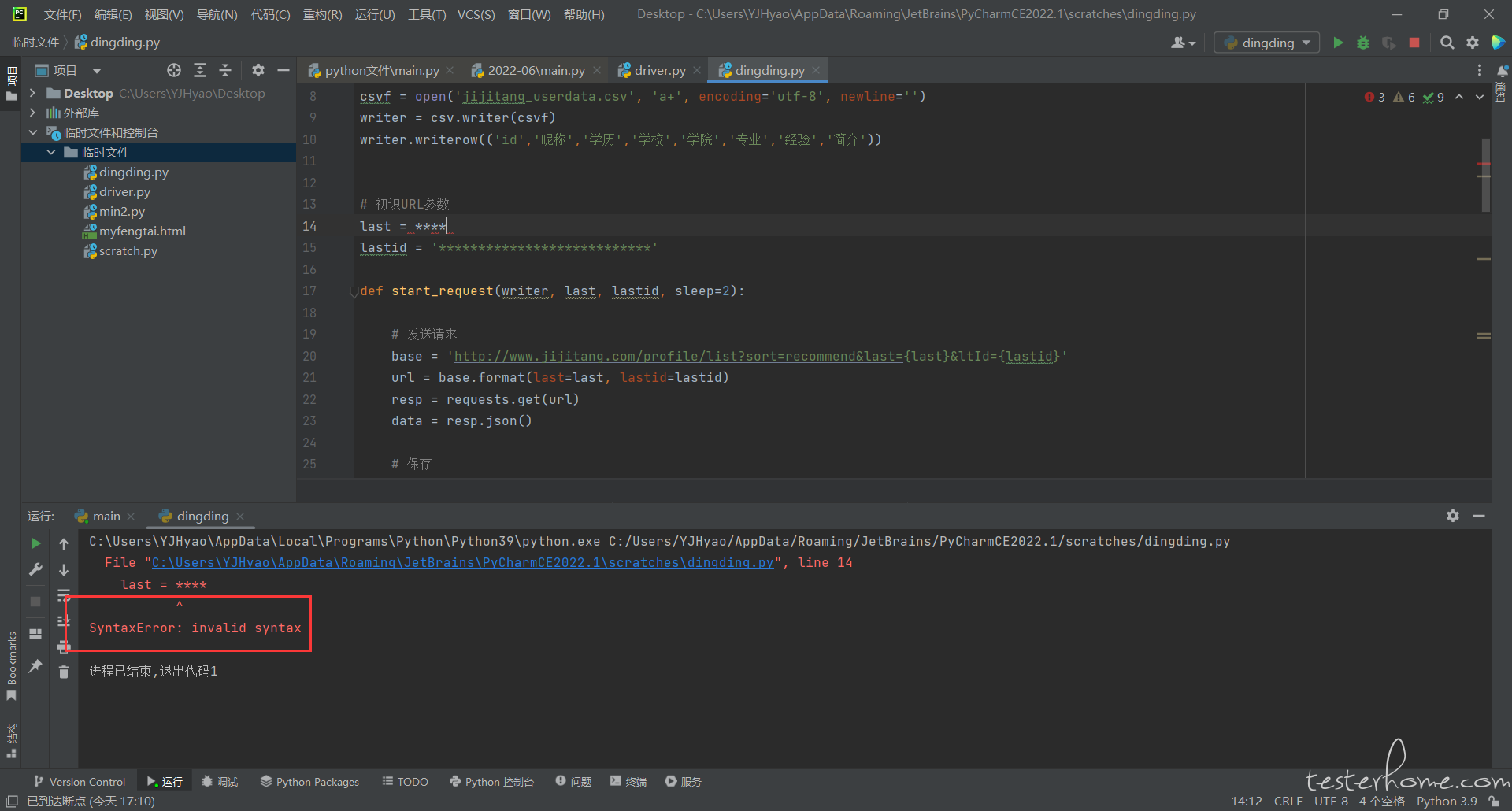
# 初识URL参数
last = ****
lastid = '***************************'
def start_request(writer, last, lastid, sleep=2):
# 发送请求
base = 'http://www.jijitang.com/profile/list?sort=recommend&last={last}<Id={lastid}'
url = base.format(last=last, lastid=lastid)
resp = requests.get(url)
data = resp.json()
# 保存
for users in data:
nickname = users.get('nickname') # 昵称
userid = users.get('_id') # ID
try:
profile = users.get('profile') # 简介
role = users.get('institution').get('role') # 学历
institute = users.get('institution').get('institute') # 所属学校
dept = users.get('institution').get('dept') # 所属学院
experience = users.get('experience') # 经验
field = users.get('field') # 专业
except:
profile = '无'
role = '无'
institute = '无'
dept = '无'
experience = '无'
field = '无'
# 逐行写入并打印
writer.writerow((userid, nickname, role, institute, dept, field, profile, experience))
print(userid, nickname, role, institute, dept, field, profile, experience)
save_to_mysql(userid, nickname, role, institute, dept, field, profile, experience)
#最后一个用户信息
#用户信息的rate对应last参数
#用户信息的_id对应lastid参数
last_user = data[-1]
last = last_user.get('rate')
lastid = last_user.get('_id')
#降低访问速度
time.sleep(sleep)
#根据最后一个用户的last和lastid,实现对下一批用户信息的爬取操作(递归)
return start_request(writer, last, lastid,)
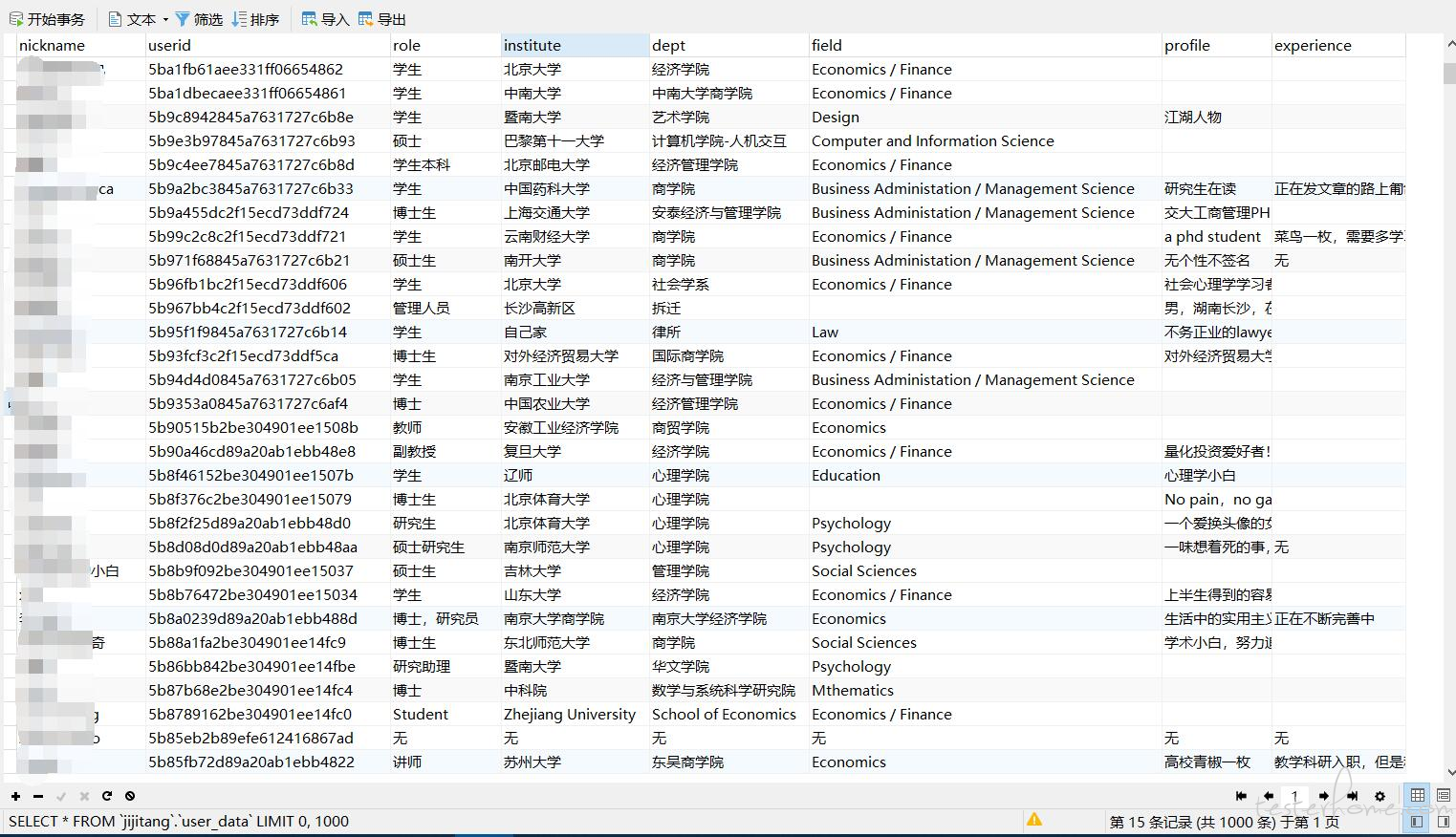
def save_to_mysql(userid, nickname, role, institute, dept, field, profile, experience):
try:
conn = pymysql.connect(host='localhost', port=3306, user='root', password='111111', db='jijitang',charset="utf8")
cursor = conn.cursor()
insert_sql = """
insert into user_data(userid,nickname, role, institute, dept, field, profile, experience)
values(%s, %s, %s, %s, %s, %s, %s, %s)
"""
cursor.execute(insert_sql, (userid, nickname, role, institute, dept, field, profile, experience))
conn.commit()
cursor.close()
conn.close()
except Exception as e:
print('wrong' + str(e))
#开始递归爬取
if __name__ == '__main__':
start_request(writer, last, lastid)
爬取结果
「原创声明:保留所有权利,禁止转载」
如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!