性能测试过程中,我们在评估哪些接口是需要测试或核心的接口的时候,总不能通过拍脑袋的方式确认,需要通过数据支撑。
数据如何来?
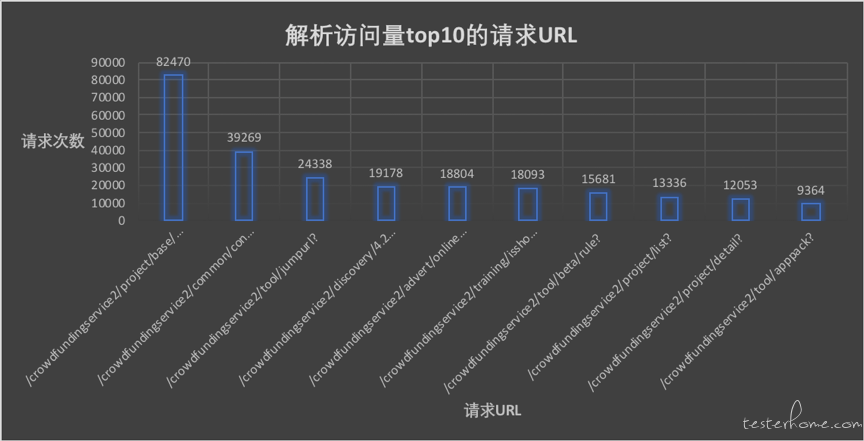
本文通过解析线上的请求日志,统计出访问量 top10 的请求 url,这样我们就很清晰的知道哪些重要核心接口优先测试。
另外运营人员也可以学一学,后续还有随时间分布的流量分析方法,敬请持续关注公众号文章。
为了更好的阅读体验,可以点击下面👇链接阅读,关注**大话性能**,可以持续免费学习工作测试技能干货!
http://dwz.cn/tvitxcGq
废话不说,直接上代码,大家可以根据自己的需求做一些微调。
1# encoding: utf-8
2"""
3@python: v3.5.4
4@author: hutong
5@file: loganalyse.py
6@time: 2018/7/28 下午3:48
7"""
8#日志格式如下
9#120.26.118.33|124.88.36.35, 100.116.167.34|2|2018-07-21 20:20:10|GET|200|913|
10# /crowdfundingservice2/project/base/info?id=6B976313BF15D90AE050190AFD015E55&client=web
11# |Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36
12# |-
13
14
15import re
16import time
17from collections import Counter
18
19def analyse_log(logname,topN):
20 urls={}
21 start = time.time()
22 line_num = 0
23 with open(logname,'r') as f:
24 for line in f:
25 #print(line)
26 url=re.search('(/crowdfundingservice2.+?)[\?|\|]',line)
27 if url is None:continue
28 #print (url.group())
29 line_num += 1
30 url_match = url.group()
31
32 if url_match not in urls.keys():
33 urls[url_match] = 1
34 else:
35 urls[url_match] = urls[url_match] +1
36
37 #sort
38 urlsDictSort=sorted(urls.items(),key=lambda e:e[1],reverse=True)
39 a=0
40 with open (logname+'.csv','wb') as fw:
41 for url,count in urlsDictSort:
42 if a==topN: break
43 #print ('请求的url:',url,' times:',count)
44 a+=1
45 insert_data = url+','+str(count)
46 insert_data = insert_data + '\r\n'
47 #print(insert_data)
48 fw.write(insert_data.encode('UTF-8'))
49 print ('解析%d条日志花费时间:%s' % (line_num,time.time()-start))
50
51if __name__ == "__main__":
52 analyse_log('/*/access_log.2018-08-03',10)
53 #analyse_log('/Users/hutong/PycharmProjects/myprojects/test.log',5)
效果
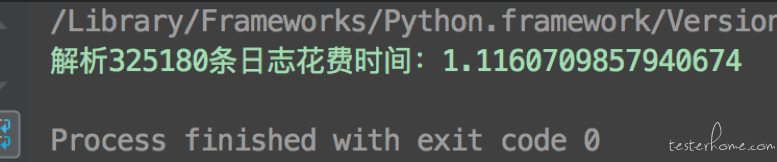
在我自己的 mac 笔记本上,基本上几十万的日志数据,可以在 1s 多内完成。
大家可持续关注大话性能公众号,不断学习测试实战技能和高薪岗位内推。

「原创声明:保留所有权利,禁止转载」