网络字节序
无论是协议测试(接口测试)还是压力测试等,先要了解网络数据包以大端字节序传输还是小段字节序传输。
数据报的在应用层分为 2 段,首部是数据包头,数据包体。
网络包字节序在拿到数据包头就可以知道。如果包头错误了,说明设置错了。
解包完是转成 10 进制的。
来看下面的例子,日志里面是打印出来的,分别按不同的字节拼接成字节数组
例子
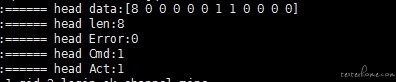
以上包头有 4 个字节数组 [len,error,cmd,act],data 是包头以外的。我们先看 len:8 代表长度为 8
这个长度为 8,作用于包体(不包含包头长度)或者总长度(包头 + 包体)这个是 1 组正确的
来看一组错误的
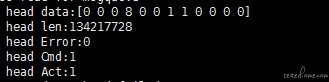
明显 len 字节数组区域的长度异常了,注意这里 len 不代表字节数是 8。
这样的格式 len 长度为 8,占 2 个字节 大端是 00 80 单个字节是 00 08 大端是从低到高
小端是从高到低,80 00 一旦大小端写反了就会出现 len 长度是异常的 2 的 24
最终在服务器应用层的日志
最上面的图片日志要更细的一个级别。

那么常规的日志会提示包头解析异常(如上图),为什么这样的结论,因为处理完黏包后,先解析包头,才解析包体。一旦包头解析错误了,就暂停解析后面的了。
大小端如何设置
Protocol.encode =function (EProtoCmd,EProtoAct,EProtoBody) {
//二进制Cmd和Act传递
var byteLength = EProtoBody === undefined ? 0 : EProtoBody.length; //len长度等于包体的长度
var byteBuffer = new ByteBuffer().littleEndian();//小端
Protocol.decode = function (msg) { //完整一段数据包
var byteBuffer = new ByteBuffer(msg).littleEndian();
在处理网络的应用层里面 encode 和 decode 处理里面设置。这个也是在底层写好的方法
//指定字节序 为BigEndian
this.bigEndian = function(){
_endian = 'B';
return this;
};
//指定字节序 为LittleEndian
this.littleEndian = function(){
_endian = 'L';
return this;
};
this.byte = function(val,index){
if(val == undefined || val == null){
_list.push(_org_buf.readUInt8(_offset));
_offset+=1;
}else{
_list.splice(index != undefined ? index : _list.length,0,{t:Type_Byte,d:val,l:1});
_offset += 1;
}
return this;
};
this.short = function(val,index){
if(val == undefined || val == null){
_list.push(_org_buf['readInt16'+_endian+'E'](_offset));//大端
_offset+=2;
}else{
_list.splice(index != undefined ? index : _list.length,0,{t:Type_Short,d:val,l:2});//小端
_offset += 2;
}
return this;
};
注意网络字节单位写在 buffer 里是 00 1 个字节,所以 1 个字节 byte 是不需要区分大小端的。 从 short 有符号的 2 个字节开始需要 ushort 就是无符号的 2 个字节。具体看上面代码。
流程
这个测试业务这里简单过下哪里会用到 encode 和 decode
client 先把包体按一定的字节顺序拼接,然后序列化压包-->服务端。<--用到 encode
服务端处理完后-->在网络缓存区处理黏包(把多个包分开成 1 个个包)-->在网络缓存区处理解包(可以判断必定是 1 个包)-->用到 decode