这坨代码解决的问题:
公司主站做好了,哪些路由配置有问题,或者没资源,nginx 搞错了,404, 5xx,挨个点?
下面进入不正经时间
肯定是在造轮子,而且必须是方的.但 wo 孤落寡闻,在坛子上找了找,看到个 c# 工具
写完了也没仔细测, 凑合能用,真是凑合能用
只适用于特定的网站,不要指望改个网址就能用了. 一直认为开发出让所有人都能用的测试工具, 简直扯淡,等同于让所有人都幸福
为啥不用
request-html,这个...,暂时不会,没看;-
可以拓展:
- 需要用户登录后去扫,会 Se 就成
- 需要处理特殊超链接,比如不是写在
<a href=xxx>那,像我们公司的网站的分页... - 404 了,没准是网络不好,再抓一次
- 愿意改成多线程多什么就去改吧
反正是凑合能用
效果图如下, 不好意思 扫了宜信的网站,抱歉.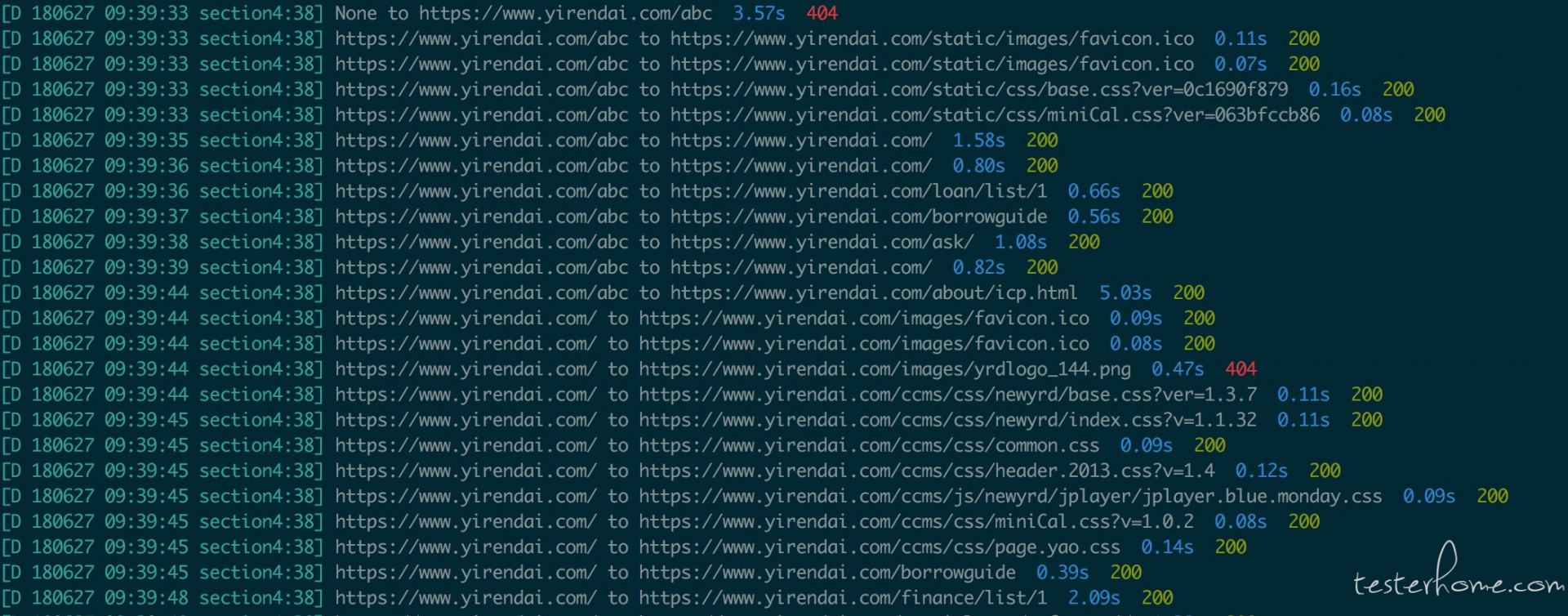
代码如下:
#! /usr/bin/env python3
# coding=utf-8
import time
from urllib.parse import urljoin
from selenium import webdriver
from bs4 import BeautifulSoup
from logzero import logger
domain='https://www.yirendai.com/abc'
title404="您访问的页面不存在-宜人贷"
dr=webdriver.Firefox()
def scrap_url(url,orginal_url=None,scrap=True):
"""
a页面有b页面超链接,同时b页面有a页面超链接.访问a->解析出b->访问b->解析出a
->访问a,不对a页面再次解析,此时scrap=False
"""
status_code=200
try:
now=time.time()
dr.get(url)
#根据title判断/或者404页面文件都比较小
if dr.title==title404: status_code=404
html=dr.page_source
soup=BeautifulSoup(html,'html.parser')
except Exception as e:
dr.get_screenshot_as_base64('f{orginal_url}_to_{url}')
finally:
t='%.2f' %(time.time()-now)
if status_code==200:
mod="32m"
elif status_code==404:
mod="31m"
logger.debug(f'{orginal_url} to {url} \033[0;34m {t}s \033[0m '
f'\033[0;{mod}{status_code}\033[0m')
more_seeds=[]
#有些网站的站内的超链接不是href参数提供的,需要继续在if修改
# 有些还有外链,都是在这处理....
if scrap:
for a in soup.find_all(href=True):
if a['href'].startswith('/'):
more_seeds.append((urljoin(domain,a['href']),url))
return more_seeds
def main(domain):
seeds=scrap_url(domain)
old_urls=[]
while seeds:
seed,seeds=seeds[0],seeds[1:]
url,orginal_url=seed
if url not in old_urls:
more_seeds=scrap_url(url,orginal_url)
old_urls.append(url)
else:
more_seeds=scrap_url(url,orginal_url,False)
seeds.extend(more_seeds)
main(domain)
可耻的放上我的 github: https://github.com/mixure/tools