WeTest腾讯质量开发平台 机器学习在启动耗时测试中的应用及模型调优 (一)
作者:熊玉辉, 腾讯 OMG 质量管理部 高级工程师
商业转载请联系腾讯 WeTest 获得授权,非商业转载请注明出处。
原文链接:http://wetest.qq.com/lab/view/392.html
WeTest 导读
启动耗时自动化方案在关键帧识别时,常规的图像对比准确率很低。本文详细介绍了采用 scikit-learn 图片分类算法在启动耗时应用下的模型调优过程。在之后的续篇中将采用 TensorFlow CNN、迁移学习等算法,给出对比识别效果
1、常规思路与困境
App 启动、关键页面加载耗时是一个常规的性能指标,也是竞品对比的关键性指标。在耗时测试中,如何自动化识别关键图片至为关键。由于视频 App 启动过程广告、首页运营内容是分分钟变化的。在识别关键图片时,传统的基于灰度直方图 + 阈值的自动化对比方法行不通。
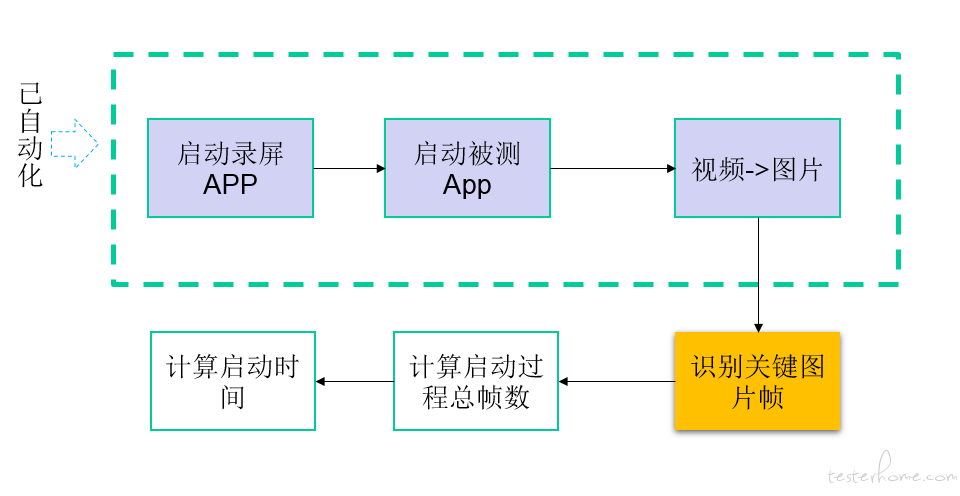
关键点:如何识别关键帧的自动化
Ø人工识别:耗时,费人力
Aphone610 版本 3 家竞品、14 个场景,每个场景 10 次,2 分钟 1 次 ,约 14h ==2 人天
Ø图像对比:灰度直方图 + 阈值(不可行)
1)整图对比:视频启动过程中的广告、首页海报是变化的
2)部分对比:app 完整启动后第一屏不完全展示的地方,每次不一定在同一处
Ø埋点上报:结果准确性一直被质疑(不可行)
1)adb shell am start -W [packageName]/[packageName.MainActivity] 获取
2)app 埋点上报:代码里加埋点,首页加载完成后数据上报
2、为什么机器学习
启动速度关键帧图片识别,其实就是机器学习中常见的图片分类问题。当前图片分类算法和开源的代码库非常成熟,应用也屡见不鲜。之前在网上有浏览到一篇文章提到用机器学习实现耗时自动化的关键帧识别,眼前一亮,在此给出实现和调优过程。
3、实施方案
整体思路:
如下图所示,采用录屏软件 + 自动化脚本,完成启动过程录屏之后将视频拆成一系列图片帧。通过训练好的机器学习模型,识别出每一张图片所对应的启动过程,计算启动第一张图片到启动稳定后的总帧数,即可得出最终的启动时间。
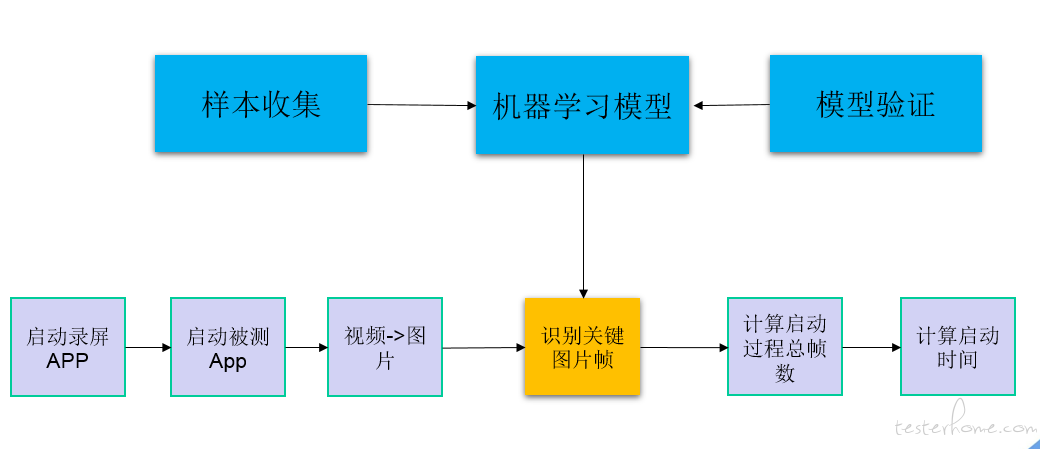
样本与分类 label 设计

特征选择
常见的图像特征处理方法有:
1)原始像素特征扁平化
2)提取颜色直方图(使用 cv2.normalize 从 HSV 色域中提取一个 3D 颜色直方图并做平滑处理)
在本方案中,最开始首先选择方法(1)。即录屏视频分辨率为 480p*720p,拆帧后压缩 8 倍,每个像素点 3 个数据表示,最终一张图片用 16200 维列表表示——16200 个特征,后续会对比 3D 颜色直方图作为特征进行对比。
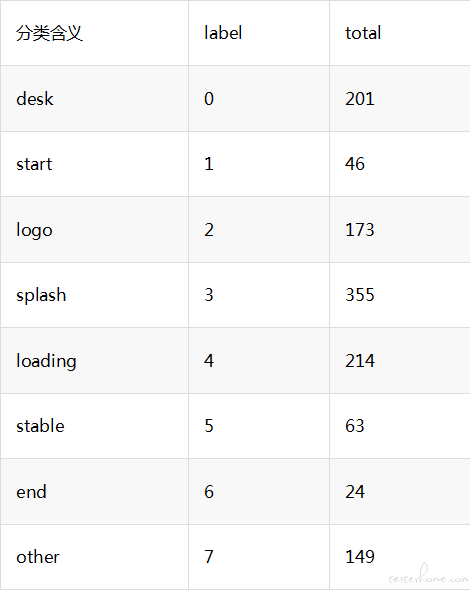
第一批样本集
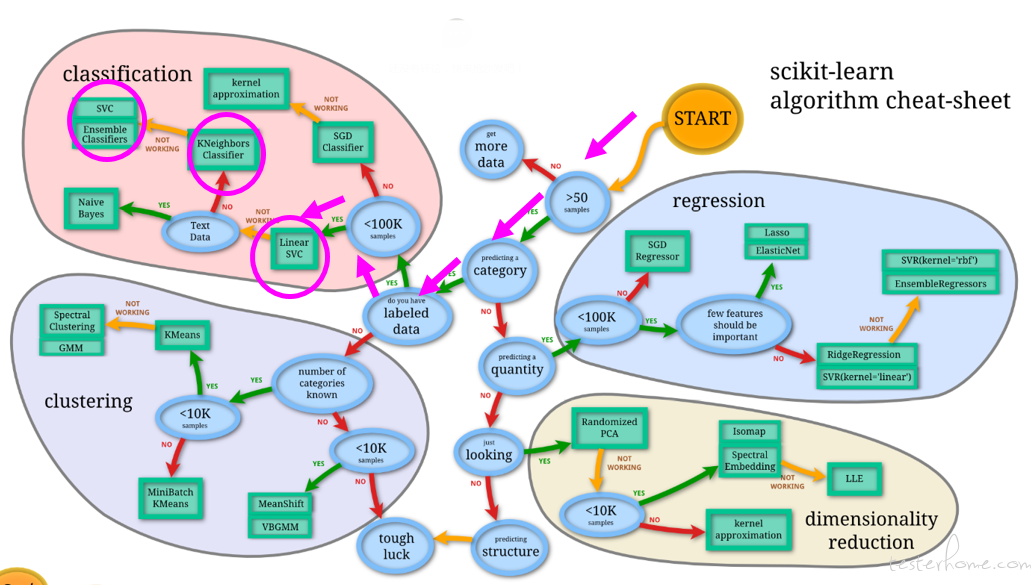
算法选择
在算法选择的过程中,依据 “不要在算法选择上花费太多时间,先让你的模型 run 起来” 以及 sklearn 官网算法选择引导,因为样本数 1000+<100k,选择 SVM+ 线性核 入手。
4、模型调优实战
1)调优步骤
在机器学习中,如果遇到较大误差时,常见的模型调优方法不外乎:
增加样本 -----避免 overfitting
选用更少的特征 ----- 避免 overfitting
获取更多的特征 ----- 避免 underfitting
调整模型,或者正则参数 ----- 均可
当然在实现过程中,我们需要首先找出问题所在,不能盲目的增加样本或者减少参数。一般来说:
快速实现算法
plot learning curve
分析 error—sample 特征,选定要采取的手段
2)绘制学习曲线
模型:LinearSVC(C=1.0),sklearn 中提供了 learning_curve()函数不用自己实现
1)总样本 1225,10%、25%、50%、75%、100% 5 轮,train:valid = 3:1
2)计算平均方差随样本数变化的曲线
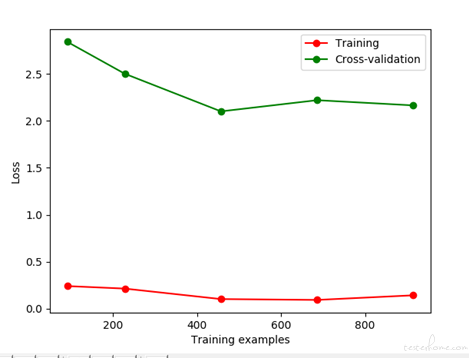
3)防止过拟合
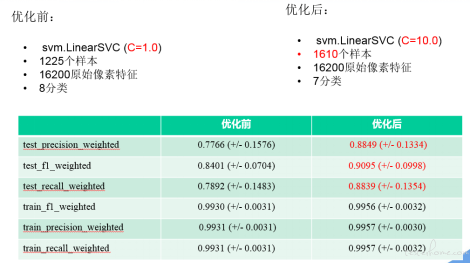
第一步:调整 LinearSVC 参数(如 C 、class_weight)——确认 C=10 最合适
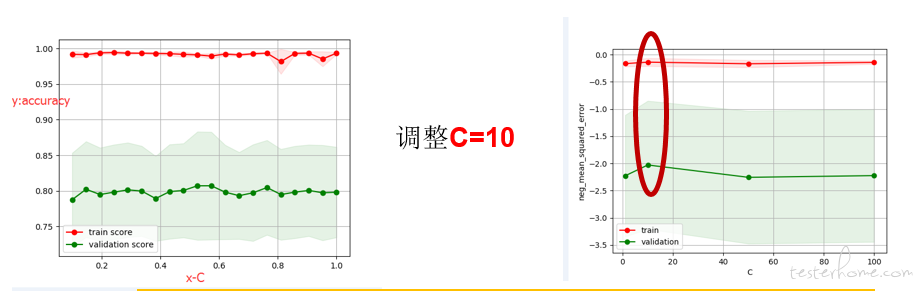
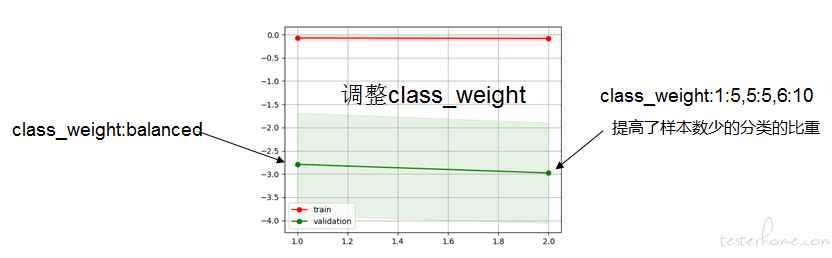
第二步:增加样本 (优先增加数量少的分类样本、test_set 准确率低的分类样本)1610 个样本时误差最低
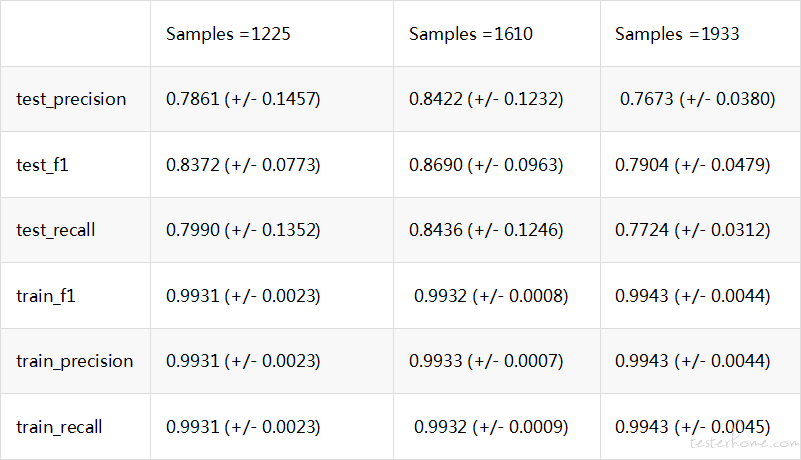
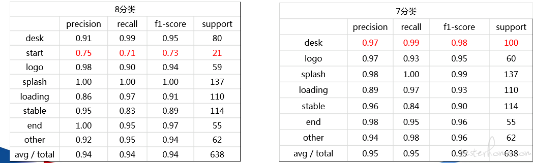
为了更好的分析问题,可以通过 classification_report 来得出各个分类的具体精确率情况
from sklearn.metrics import classification_report
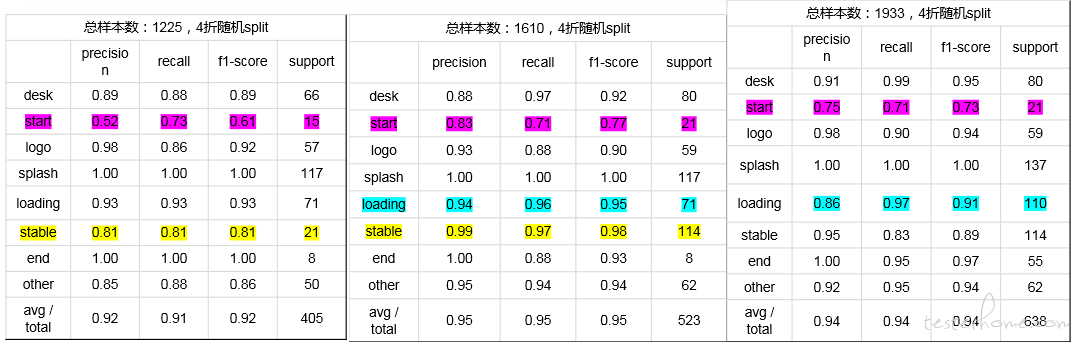
第三步:减少特征
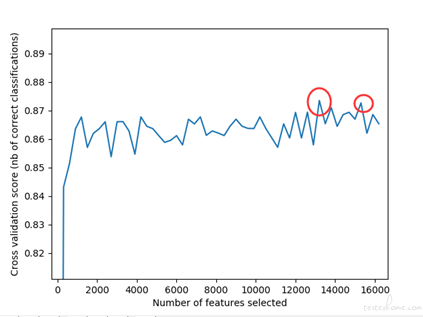
1)减少特征的过程中,尝试通过 RFEVC 获取最优特征数,优化结果并不明显

a.特征增加的步长是人为选择的,太大了可能会漏掉关键特征,太小了计算量太大
b.step 一致的,最优特征数 每次可能不一样
c.提升并不大
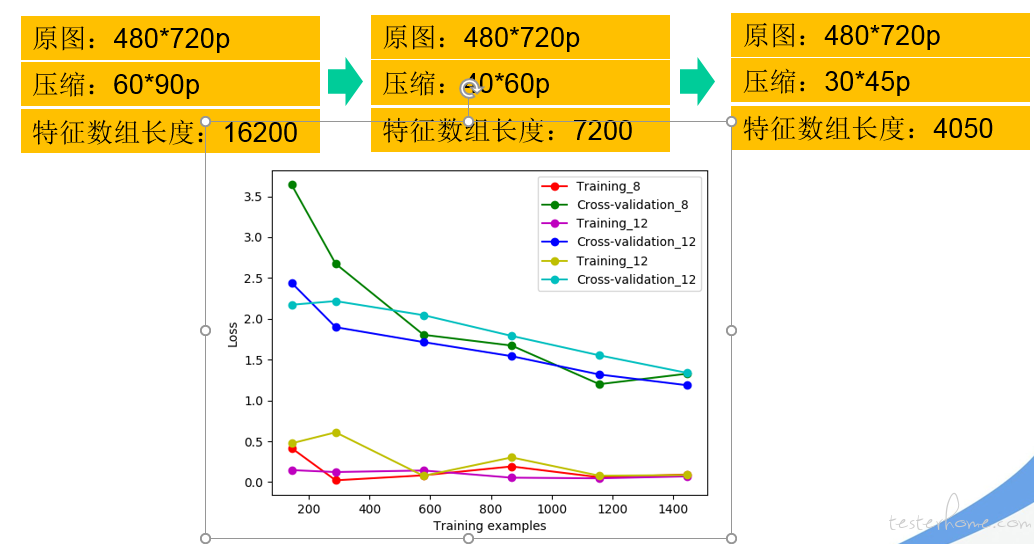
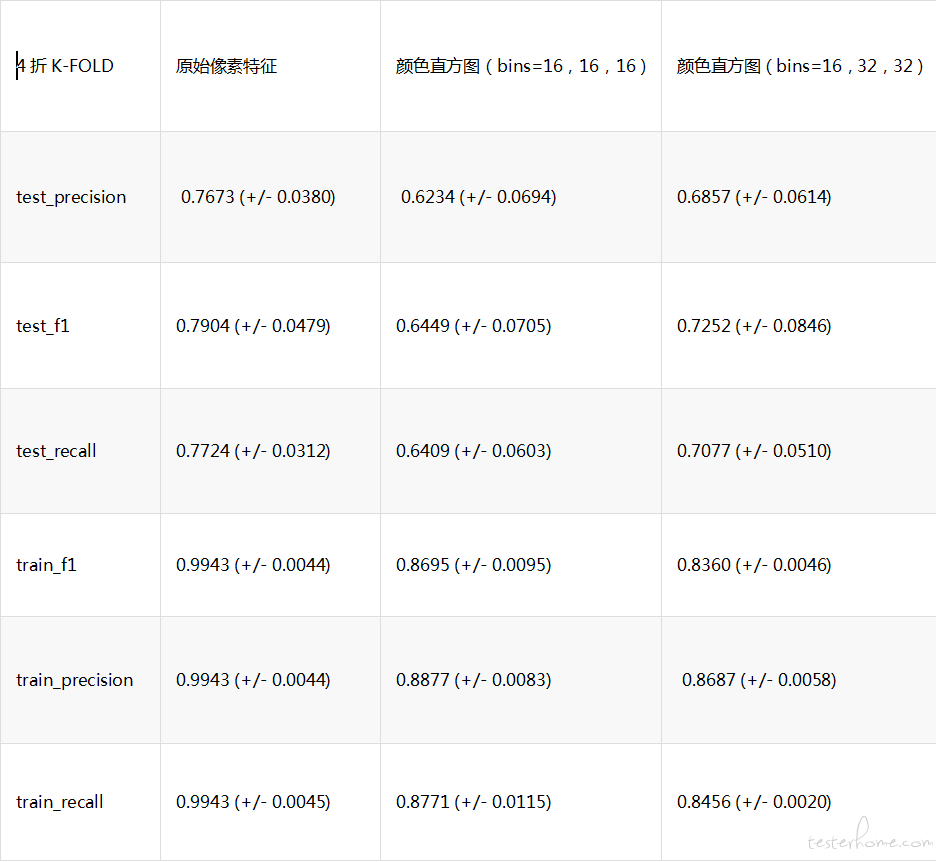
2)加大图像压缩: 从原来的 8 倍->12 倍->16 倍
a.从学习曲线上看过拟合依然存在,整体的 test_error 还是减小了的
b.偏差严重的 label=start 这一分类,压缩倍速越高精确度越低
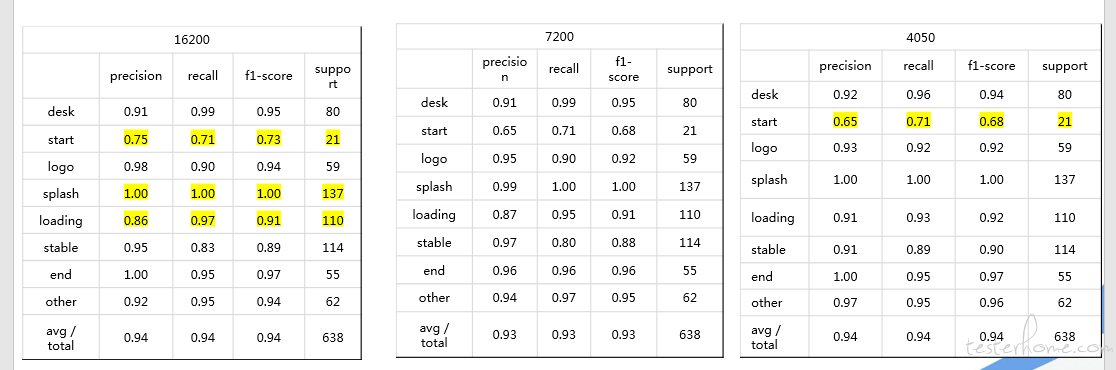
3)PCA
主要成分分析 PCA:特征置换,原特征映射到新特征,从而实现降维。降维的目的主要是减少计算量,但是有热心同志建议试试,便试试。事实证明实际上证明 “利用 PCA 来避免过拟合” 是个 bad case。
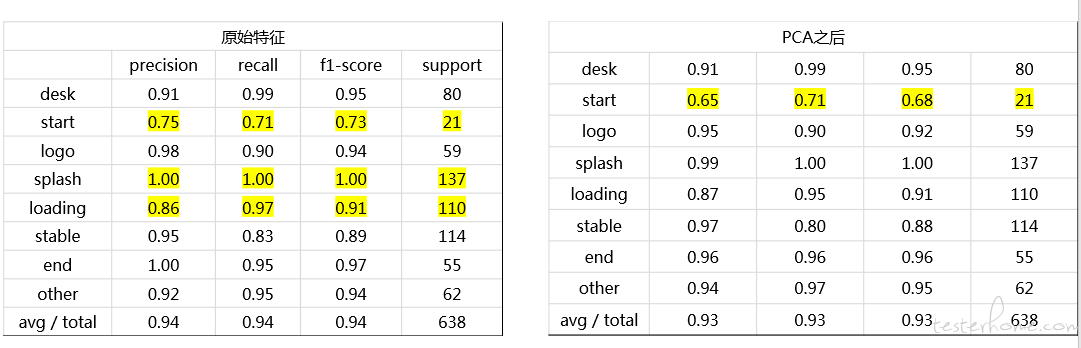
4)提取颜色直方图并做平滑处理后,作为图像特征之后,对比发现 precison 和 recall 低了 10 个百分点~~

第四步:调整结果分类
在前面有分析过,start 这个分类识别准确率很低。 分析对比图片,start 与 desk 区别仅仅在于 app icon 是灰显的。经评估 desk 和 start 分类合成一类,在实际耗时测试中影响并不大,但能提高不少 test set 的准确率
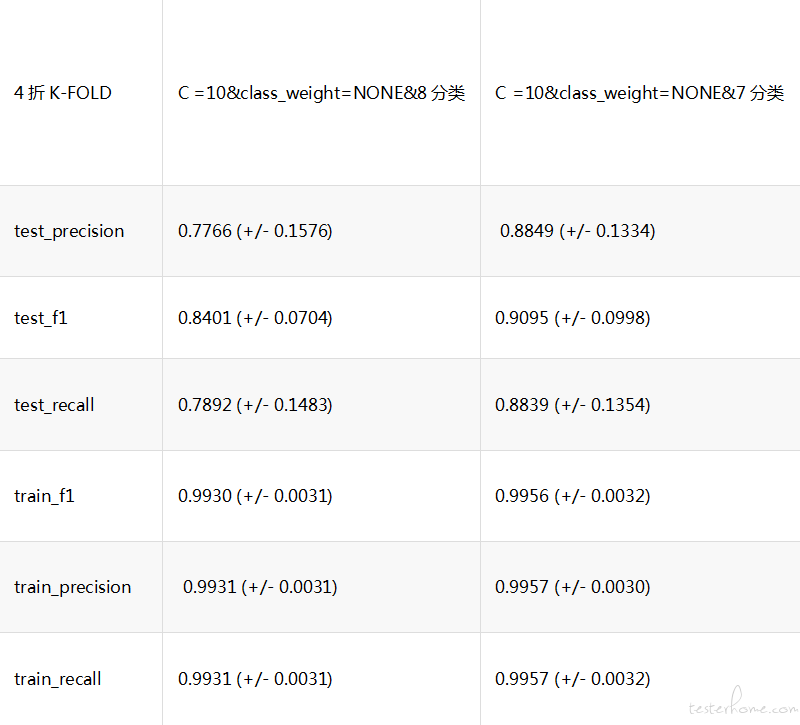
8 分类变成 7 分类之后的学习曲线已经趋于收敛,且过拟合情况好很多了
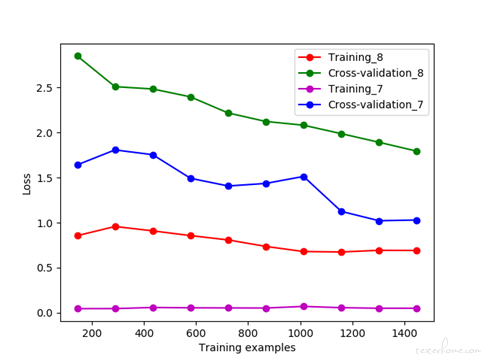
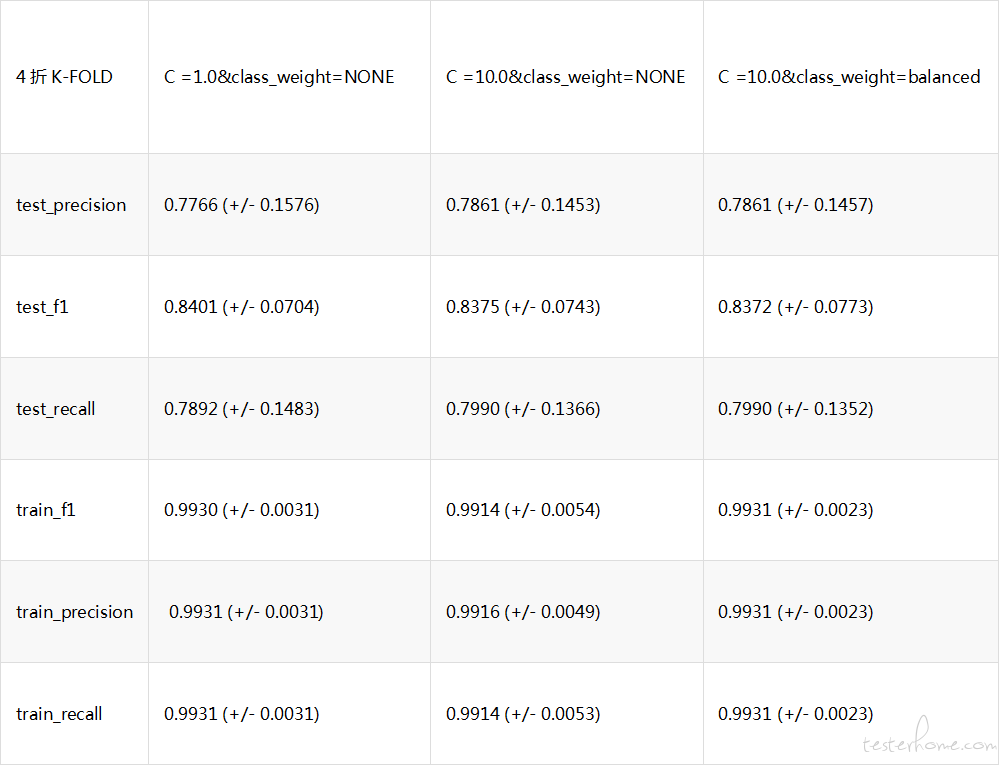
分类准确率提升如下表所示:
4)调优前后对比
5、总结

6、后续 - 模型探讨
SVM 线性核 LinearSVC,在图片分类问题中并非唯一选择,也不是最佳选择。后面将尝试不同的图像特征提取,与 CNN 和迁移学习算法在本问题的应用情况进行对比
1、使用 TensorFlow 构建 CNN
2、使用 Inception v3 进行图像分类
3、尝试新的图像特征提取方式
腾讯 WeTest是腾讯官方出品的一站式质量开放平台。致力于品质标准建设、产品质量提升,历经千款腾讯产品磨砺。平台包含兼容测试、云真机、性能测试、安全防护、企鹅风讯等优秀工具,覆盖产品在研发、运营各阶段的测试需求。金牌专家团队,10 余年品质管理经验,5 大维度,41 项指标,360 度保障产品质量。
目前,我们为 WeTest 平台的认证用户提供免费使用机会,详情点击http://wetest.qq.com/
如果使用当中有任何疑问,欢迎联系腾讯 WeTest 企业 QQ:800024531
腾讯 WeTest 有奖征文活动进行中,欢迎投稿!了解详情:
http://wetest.qq.com/lab/view/379.html