前言
在机器学习的大部分使用场景中,模型是要为线上业务服务的,需要处理业务请求来做实时的预估。 所以需要把模型发布成为一个服务。 最近在测试我司对 tensorflow 的集成功能的时候,涉及到了模型的上线。在 github 上面有 tensorflow serving 的开源项目,它就是专门为了让一个 tensorflow 模型发布成线上服务而设立的,它能够支持固定的 tensorflow 模型格式,让保存到本地的模型不需要做任何改动就可以发布上线的同时,也提供了统一的 API 让我们访问模型服务。
模型的保存
在 tensorflow 中保存模型有好几种方式, 从最一开始的 tf.saver 到后来的 exporter 再到现在的 savedmodel。 随着 tensorflow serving 的发展,模型的 API 和格式都发生了变化。 目前 tensorflow serving 推荐的模型格式是 savedmodel, 接下来我们就看看 tf.saved_model.builder.SavedModelBuilder
builder = tf.saved_model.builder.SavedModelBuilder('gaofei_cnn/0')
上面是声明一个 savedmodel 的代码。 创建这个 builder 的方式很简单,只需要传递想要保存的模型的路径就可以了。 注意在这里我使用了 gaofei_cnn/0 这样的格式。 这是 tensorflow seving 的约定俗成。 /之前的 gaofei_cnn 是模型名称,之后的 0 是模型的版本。 在 tensorflow serving 中,我们是可以同时上线不同版本的模型的。所以我们一般都用这样的路径保存模型的。
签名 (signature)
同时保存模型需要至少一个签名 (signature),上面的代码就是声明一个签名。那这个签名有什么用呢,在我们的模型发布上线之后,其实就一个 API。 我们调用 API 的时候需要把线上的数据传递过去。 但这里会有一个问题,我再之前的文章中写过。 一个模型训练的过程差不多是下面的样子的。
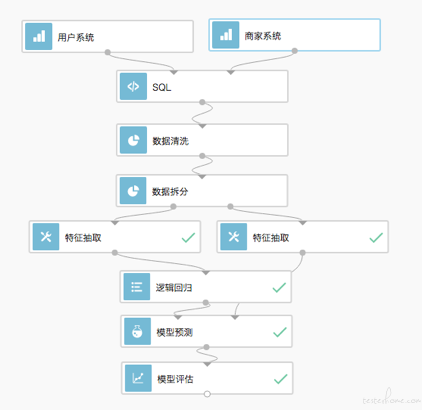
数据进来以后需要拼接,清洗,特征抽取等等过程。 之后才会输入到机器学习训练算法中进行训练。 也就是数据是要经过一系列的处理后才会进入模型训练。 同样的,在我们做线上预测的时候,也需要这样的步骤,才能输入到在线的模型中进行预测。 这是在机器学习中会遇到的很常见的问题。 同样的逻辑分布在线上和线下,但他们的代码却不一样。在之前很多的机器学习场景中,这都是非常头疼的问题,我们之前要做的线上线下模型一致性测试,其实就是这个问题带来的。 其实严格上说不是模型的一致性, 而是处理数据的逻辑的一致性。 测试他们是不是对数据处理的过程都是一样准确的。 如果线上处理的逻辑的代码出现了问题,和线下的不一样,那么输入到模型的数据就是不一致的,导致预测结果不准确。 而 tensorflow 的 signature,可以很好的帮我们解决这个问题,从之前对于 tensorflow 的学习来看,在 tf 中的代码中我们也需要针对数据进行处理之后 (比如上一篇我们用 pandas 对数据进行了筛选) 才进行的训练。 所以如果我们能把这份数据处理的代码也保存在模型里并带上线的话。 就可以解决这个问题了。 这就是我们签名(signature)的作用。 在 signature 中,我们可以把训练中的 tensor op 通过 signature 的方式保存到模型中。 这些 tensor op 其实都是一段计算逻辑。 我们的 tf 是图计算的,一个 tensor 会保存之前的所有操作。我们看看一个例子。
# x 为输入tensor
inputs = {'image': utils.build_tensor_info(input_x_image)}
# y 为最终需要的输出结果tensor
outputs = {
"softmax": utils.build_tensor_info(softmax_op),
"prediction": utils.build_tensor_info(prediction_op),
}
signature = tf.saved_model.signature_def_utils.build_signature_def(inputs, outputs, method_name=signature_constants.PREDICT_METHOD_NAME)
上面定义 signature 的过程中,我们要定义 inputs 和 outputs。 分别代表了输入和输出的 tensor op。 inputs 代表了模型的输入, 输入的数据要使用 inputs 中定义的 op 进行处理。 而 outputs 则代表了输出。 当我们将模型上线后,数据经过 inputs 处理后, 得到的是 outputs 中设置的 tensor。 上图是我再做一个 cnn 模型的时候,保存模型的一段代码。 inputs 使用的名字是 image,代表了图片数据,线上数据通过 inputs 中定义的 tensor op 处理后, 输入到模型中进行预测。 而得到的结果就是在 outputs 中定义的 softmax 和 prediction。 其中 softmax 得到的是 minist 作为 10 分类的每一个分类的概率, 而 prediction 就是最后的预测值。这两个 tensor op 都是在代码中定义的。 之后,我们调用 builder 的方法来保存模型了。
builder.add_meta_graph_and_variables(
sess, [tf.saved_model.tag_constants.SERVING],
clear_devices=True,
signature_def_map={
tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY:
signature}
)
builder.save()
上面的代码我们把 signature 加入到了模型中, 参数有 sess,sess 是 tf.Session。 我们把训练中的计算图传递了进来。 在加上 signature,就可以使用 builder.save 保存模型了。
tensorflow serving
apt-get install tensorflow-model-server
tensorflow_model_server --port=9000 --model_base_path=gaofei_cnn
pip install tensorflow-seving-api-python3==1.7.0
我们安装 tensorflow 的服务。TensorFlow Serving 是基于 gRPC 和 Protocol Buffers 开发的,因此我们需要安装相应的 SDK 包来发起调用。需要注意的是,官方的 TensorFlow Serving API 目前只提供了 Python 2.7 版本的 SDK,不过社区有人贡献了支持 Python 3.x 的软件包。调用过程很容易理解:我们首先创建远程连接,向服务端发送 Example 实例列表,并获取预测结果。client 的代码我就不演示了,我没太研究,我直接使用的我们产品的功能调用的服务请求。
输入的数据是一个图片,处理起来很很麻烦。 需要把图片转换成像素矩阵。 我们不演示了。 直接看下面的图。

还记得我们保存签名的时候,使用的 images 这个 inputs 中定义的名字么。 在调用的时候我们也要指明使用它。然后得到得的结果是我们 outputs 中定义的 softmax 和 prediction。
如下:
{
"prediction": [
5
],
"softmax": [
[
0.008605420589447021,
0.0017572250217199326,
0.17611274123191833,
0.0010755585972219706,
0.000004818202341994038,
0.6004971861839294,
0.011081034317612648,
0.00044339639134705067,
0.20039980113506317,
0.00002279030013596639
]
]
}
我们的 input 是一个图片。 输出的 prediction 预测为 5(我们使用的是之前 mnist 手写图片识别的场景 demo),以及 softmax 输出的 10 分类中,每一分类的概率, 可以看到第六个分类 (分类从 0 开始,第六个就是 5 这个数据) 的概率最高。所以 prediction 才输出为 5.
结尾
最后附上完整的模型训练和模型保存的代码。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.python.saved_model import (
signature_constants, signature_def_utils, utils)
# 加载数据
mnist = input_data.read_data_sets('MNIST_data', one_hot=True, source_url='http://yann.lecun.com/exdb/mnist/')
# 设置占位符
x = tf.placeholder(tf.float32, shape=[None, 784])
y_ = tf.placeholder(tf.int64, shape=[None, 10])
#image_placeholder = tf.placeholder(tf.float32, shape=[None, 28, 28, 1])
# 创建w参数
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# 创建b参数
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 创建卷积层,步长为1,周围补0,输入与输出的数据大小一样(可得到补全的圈数)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# 创建池化层,kernel大小为2,步长为2,周围补0,输入与输出的数据大小一样(可得到补全的圈数)
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
# 第一层卷积,这里使用5*5的过滤器,因为是灰度图片,所以只有一个颜色通道,使用32个过滤器来建立卷积层,所以
# 我们一共是有5*5*32个参数
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
# 数据加载出来以后是一个n*784的矩阵,每一行是一个样本。784是灰度图片的所有的像素点。实际上应该是28*28的矩阵
# 平铺开之后的结果,但在cnn中我们需要把他还原成28*28的矩阵,所以要reshape
#x_image = tf.reshape(x, [-1,28,28,1])
input_x_image = tf.reshape(x, [-1,28,28])
x_image = tf.reshape(input_x_image, [-1,28,28, 1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 第二层卷积,同样使用5*5的过滤器,因为上一层使用32个过滤器所以相当于有32个颜色通道一样。 而这一层我们使用64
# 个过滤器
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# 全连接层,经过上面2层以后,图片大小变成了7*7
# 初始化权重,全连接层我们使用1024个神经元
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
# 铺平图像数据。因为这里不再是卷积计算了,需要把矩阵冲洗reshape成一个一维的向量
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
# 全连接层计算
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# keep_prob表示保留不关闭的神经元的比例。为了避免过拟合,这里在全连接层使用dropout方法,
# 就是随机地关闭掉一些神经元使模型不要与原始数据拟合得辣么准确。
#keep_prob = tf.placeholder(tf.float32)
#h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 创建输出层
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1, W_fc2) + b_fc2
softmax_op = tf.nn.softmax(y_conv)
prediction_op = tf.argmax(softmax_op, 1)
correct_prediction_op = tf.equal(prediction_op, y_)
accuracy_op = tf.reduce_mean(tf.cast(correct_prediction_op, tf.float32))
# 训练过程
# # 1.计算交叉熵损失
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
# # 2.创建优化器(注意这里用 AdamOptimizer代替了梯度下降法)
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# # 3. 计算准确率
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
import time
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
with tf.Session() as sess:
# # 4.初始化所有变量
sess.run(tf.global_variables_initializer())
# # 5. 执行循环
for i in range(200):
# 每批取出50个训练样本
batch = mnist.train.next_batch(50)
# 循环次数是100的倍数的时候,打印准确率信息
if i % 100 == 0:
# 计算正确率,
#train_accuracy = accuracy.eval(feed_dict={
# x: batch[0], y_: batch[1], keep_prob: 1.0})
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1]})
# 打印
print("step %d, training accuracy %g" % (i, train_accuracy))
# 执行训练模型
#train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
train_step.run(feed_dict={x: batch[0], y_: batch[1]})
# 打印测试集正确率
print("test accuracy %g" % accuracy.eval(feed_dict={
#x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0
x: mnist.test.images, y_: mnist.test.labels
}))
builder = tf.saved_model.builder.SavedModelBuilder('gaofei015/0')
# x 为输入tensor, keep_prob为dropout的prob tensor \n",
inputs = {'image': utils.build_tensor_info(input_x_image)}
# y 为最终需要的输出结果tensor \n",
outputs = {
#'softmax' : tf.saved_model.utils.build_tensor_info(y_)
#'prediction':
"softmax": utils.build_tensor_info(softmax_op),
"prediction": utils.build_tensor_info(prediction_op),
}
signature = tf.saved_model.signature_def_utils.build_signature_def(inputs, outputs, method_name=signature_constants.PREDICT_METHOD_NAME)
builder.add_meta_graph_and_variables(
sess, [tf.saved_model.tag_constants.SERVING],
clear_devices=True,
signature_def_map={
tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY:
signature}
)
builder.save()
from nbsdk import export_model
prn, hdfs = export_model("gaofei015", "gaofei_cnn015")
print(hdfs)
print(prn)
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))