在大型数据集上进行训练的现代神经网络架构,可以跨广泛的多种领域获取可观的结果,涵盖从图像识别、自然语言处理到欺诈检测和推荐系统等各个方面,但训练这些神经网络模型需要大量浮点计算能力。虽然,近年来 GPU 硬件算力和训练方法上均取得了重大进步,但在单一机器上,网络训练所需要的时间仍然长得不切实际,因此需要借助分布式 GPU 环境来提升神经网络训练系统的浮点计算能力。
TensorFlow 分布式训练
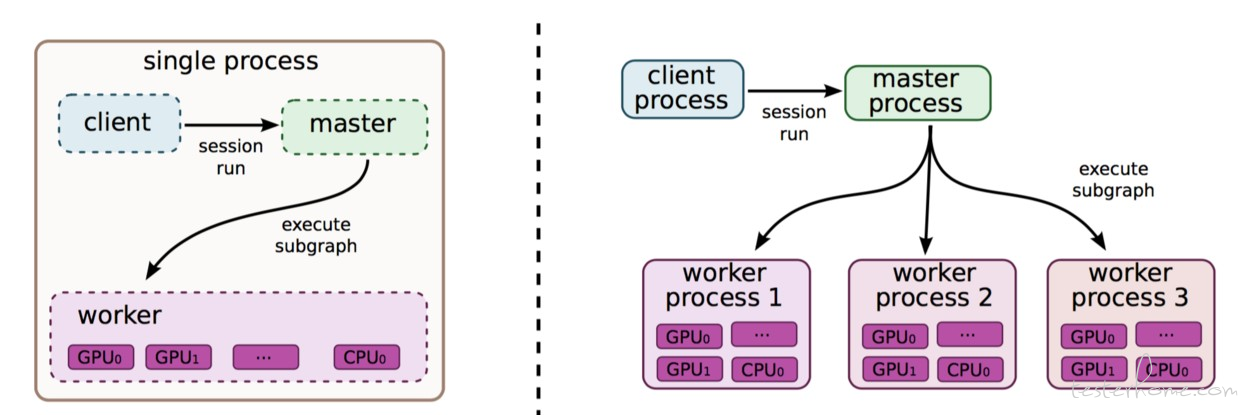
(TensorFlow 分布式训练概述图)
TensorFlow 采用了数据流范式, 使用节点和边的有向图来表示计算。TensorFlow 需要用户静态声明这种符号计算图,并对该图使用复写和分区(rewrite & partitioning),将其分配到机器上进行分布式执行。
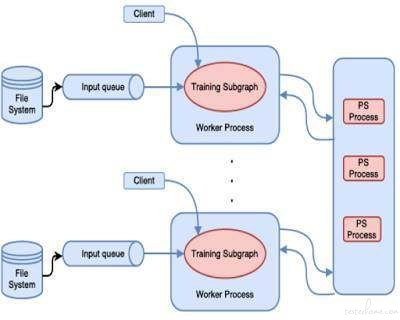
(TensorFlow 训练数据流转图)
TensorFlow 中的分布式机器学习训练使用了如图所示的参数服务器方法 。
Cluster、Job、Task
关于 TensorFlow 的分布式训练,主要概念包括 Cluster、Job、Task,其关联关系如下:
- TensorFlow 分布式 Cluster 由多个 Task 组成,每个 Task 对应一个 tf.train.Server 实例,作为 Cluster 的一个单独节点;2. 多个相同作用的 Task 可以被划分为一个 Job,在分布式深度学习框架中,我们一般把 Job 划分为 Parameter Server 和 Worker,Parameter Job 是管理参数的存储和更新工作,而 Worker Job 运行 OPs,作为计算节点只执行计算密集型的 Graph 计算;3. Cluster 中的 Task 会相对进行通信,以便进行状态同步、参数更新等操作,如果参数的数量过大,一台机器处理不了,这就要需要多个 Task。 TensorFlow 分布式计算模式
◆ In-graph 模式
In-graph 模式,将模型计算图的不同部分放在不同的机器上执行。把计算从单机多 GPU 扩展到了多机多 GPU, 不过数据分发还是在一个节点。这样配置简单, 多机多 GPU 的计算节点只需进行 join 操作, 对外提供一个网络接口来接受任务。训练数据的分发依然在一个节点上, 把训练数据分发到不同的机器上, 将会影响并发训练速度。在大数据训练的情况下, 不推荐使用这种模式。
◆ Between-graph 模式
Between-graph 模式下,数据并行,每台机器使用完全相同的计算图。训练的参数保存在参数服务器,数据不用分发,而是分布在各个计算节点自行计算, 把要更新的参数通知参数服务器进行更新。这种模式不需要再练数据的分发, 数据量在 TB 级时可以节省大量时间,目前主流的分布式训练模式以 Between-graph 为主。
参数更新方式
◆ 同步更新
各个用于并行计算的节点,计算完各自的 batch 后,求取梯度值,把梯度值统一送到 PS 参数服务机器中,并等待 PS 更新模型参数。PS 参数服务器在收集到一定数量计算节点的梯度后,求取梯度平均值,更新 PS 参数服务器上的参数,同时将参数推送到各个 worker 节点。
◆ 异步更新
PS 参数服务器只要收到一台机器的梯度值,就直接进行参数更新,无需等待其它机器。这种迭代方法比较不稳定,因为当 A 机器计算完更新了 PS 参数服务器中的参数,可能 B 机器还是在用上一次迭代的旧版参数值
分布式训练步骤
命令行参数解析,获取集群的信息 ps_hosts 和 worker_hosts,以及当前节点的角色信息 job_name 和 task_index
创建当前 Task 结点的 Server
cluster = tf.train.ClusterSpec({“ps”: ps_hosts, “worker”: worker_hosts}) server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
- 如果当前节点是 Parameter Server,则调用 server.join() 无休止等待;如果是 Worker,则执行下一步
if FLAGS.job_name == “ps”:server.join()
- 构建要训练的模型
build tensorflow graph model
- 创建 tf.train.Supervisor 来管理模型的训练过程
Create a “supervisor”, which oversees the training process.sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0), logdir=”/tmp/train_logs”)# The supervisor takes care of session initialization and restoring from a checkpoint.
sess = sv.prepare_or_wait_for_session(server.target)
Loop until the supervisor shuts down
while not sv.should_stop()
train model
UAI-Train 分布式训练部署
UCloud AI 训练服务(UCloud AI Train)是面向 AI 训练任务的大规模分布式计算平台,基于高性能 GPU 计算节点提供一站式托管 AI 训练任务服务。用户在提交 AI 训练任务后,无需担心计算节点调度、训练环境准备、数据上传下载以及容灾等问题。
目前,UAI-Train 平台支持 TensorFlow 和 MXNet 框架的分布式训练。需要将 PS 代码和 Worker 代码实现在同一个代码入口中,执行过程中,PS 和 Worker 将使用相同的 Docker 容器镜像和相同的 python 代码入口进行执行,系统将自动生成 PS 和 Worker 的 env 环境参数。TensorFlow 分布式训练采用 PS-Worker 的分布式格式,并提供 python 的接口运行分布式训练。

(图:AI 训练平台概述)
UAI-Train 分布式训练采用 Parameter Server 和 Worker Server 混合部署的方法,所有计算节点均由 GPU 物理云主机组成。PS 仅使用 CPU 进行计算,Worker Server 则同时使用 GPU 和 CPU 进行计算,PS 和 Worker 的比例为 1:1。
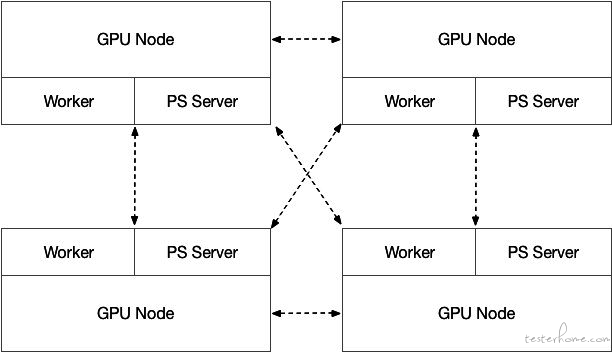
(图:AI 训练平台分布式训练集群部署范例)
数据存储
分布式训练所使用的输入数据可以来自不同的数据源,目前 UAI-Train 仅支持 UFS 作为数据的存储。
◆ Input 数据存储
指定一个 UFS 网盘作为 Input 数据源,UAI-Train 平台在训练执行过程中会将对应的 UFS 数据映射到训练执行的 Worker 容器的 /data/data 目录下,系统会自动将数据映射到执行的容器中,如 ip:/xxx/data/imagenet/tf → /data/data/。
◆ Output 数据存储
指定一个 UFS 网盘作为 output 数据源,UAI-Train 平台在训练执行过程中会将对应的 UFS 数据映射到训练执行的每一个 PS 容器和 Worker 容器的 /data/output 目录下,并以共享的方式访问同一份数据。同时,在训练过程,可以通过其它云主机实时访问训练保存的模型 checkpoint。
案例分析:通过 CIFAR-10 进行图像识别
CIFAR-10 是机器学习中常见的图像识别数据集,该数据集共有 60000 张彩色图像。这些图像分为 10 个类,每类 6000 张图,有 50000 张用于训练,另外 10000 用于测试。
http://groups.csail.mit.edu/vision/TinyImages/

(图:CIFAR-10 数据集简介)
调整训练代码
为了在 UAI 平台上进行训练,首先下载源代码,并对 cifar10_main.py 做如下修改:
添加相关参数:–data_dir, –output_dir, –work_dir, –log_dir, –num_gpus,UAI-Train 平台将会自动生成这些参数;
在代码中增加 UAI 参数:使用 data_dir 配置输入文件夹、使用 output_dir 配置输出文件夹。
具体案例代码可以在https://github.com/ucloud/uai-sdk/tree/master/examples/tensorflow/train/cifar 获取。
在 UAI-Train 平台执行训练
根据https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10_estimator 的说明生成 CIFAR-10 的 tfrecords;
使用 UAI-SDK 提供的 tf_tools.py 生成 CIFAR-10 样例的 Docker 镜像;
确保 Docker 镜像已经上传至 UHub,在 UAI-Train 平台上执行。
/data/cifar10_main.py –train-batch-size=16
在 UAI 平台上的分布式训练
CIFAR-10 样例代码使用 tf.estimator.Estimator API,只需一个分布式环境和分布式环境配置,便可直接进行分布式训练,该配置需要适用于 tf.estimator.Estimator API 的标准,即定义一个 TF_CONFIG 配置。
TF_CONFIG = {“cluster”:{“master”:[“ip0:2222”],
“ps”:[“ip0:2223″,” ip1:2223”],
“worker”:[“ip1:2222”]},
“task”:{“type”:” worker”,” index”:0},
“environment”:” cloud”
}
UAI-Train 平台的分布式训练功能可以自动生成 TensorFlow 分布式训练的 GPU 集群环境,同时为每个训练节点自动生成 TF_CONFIG。因此,在 UAI-Train 平台上执行 CIFAR-10 的分布式训练和单机训练一样,仅需要指定 input/output 的 UFS 地址并执行如下指令即可:
/data/cifar10_main.py –train-batch-size=16
总结
UAI-Train TensorFlow 的分布式训练环境实现基于 TensorFlow 的分布式训练系统实现,采用默认的 grpc 协议进行数据交换。PS 和 Worker 采用混合部署的方式部署,PS 使用纯 CPU 计算,Worker 使用 GPU+CPU 计算。
在 UAI-Train 平台中可以非常方便的开展分布式计算,提高效率、压缩训练时间。最后通过 CIFAR-10 案例解析在 UAI-Train 平台上进行训练所需作出的修改,并在 UAI-Train 平台上进行分布式训练。