通用技术 非会员批量清理百度网盘重复文件方法
由于网速不稳定,在某天添加一个很大的分享时多点了几次,导致重复添加一百多个不同文件夹路径的文件。今天打开时提示我可以一键清理,本觉得百度还是挺人性化,虽然没做重复添加的校验,还是给了我清理办法。燃鹅,当我点击删除时,弹出了"不充钱,玩不了 “的温馨提示,真是社会我百度。
气愤之余,打了个座,于是有了下面破解之法。
环境:
1.火狐浏览器 charles 抓包已配置好
步骤
1. 打开 web 百度网盘点击更多》垃圾清理》扫描重复文件(注意:这个功能有使用次数限制)


2.获取扫描完成页面的接口数据
页面如下:
(因为我的重复数据已经清理掉了,这里随便复制了个做示例)
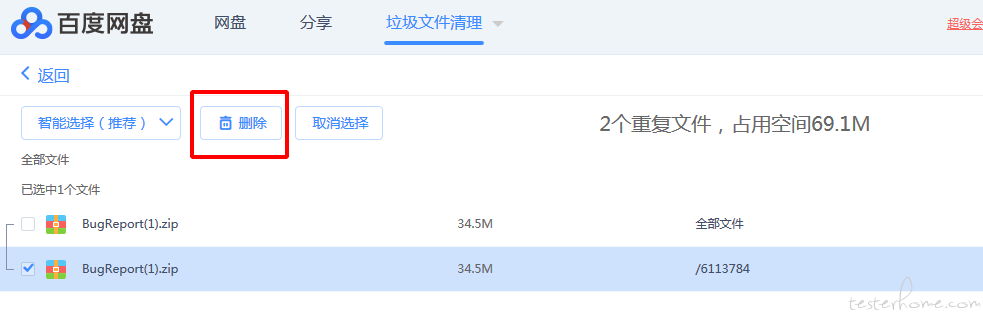
接口是这个:
https://pan.baidu.com/api/garbagelist
保存数据到文件 baidu.json,如下:
#baidu.json
{
"errno": 0,
"info": {
"group_crashed": false,
"next_index": 2,
"count": 2,
"has_more": false
},
"list": [
{
"fs_id": 0,
"data": [
{
"size": "36218244",
"category": "6",
"fs_id": "413693152779790",
"path": "\/BugReport(1).zip",
"isdir": 0,
"s3_handle": "a50c2bf7017fb91bc5044e881e8a87d1",
"isdelete": 0,
"server_filename": "BugReport(1).zip",
"server_mtime": "1519452813",
"smart_choose": 1,
"index": 0
},
......
],
"request_id": 2151336299004000452
}
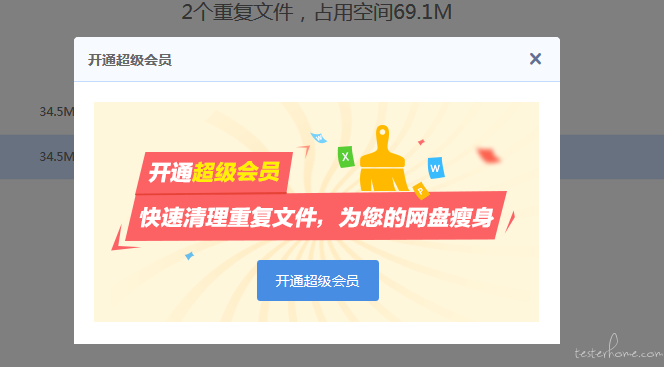
ps:当我满心赞扬的点击这个删除键时,百度就是我下面的回应。
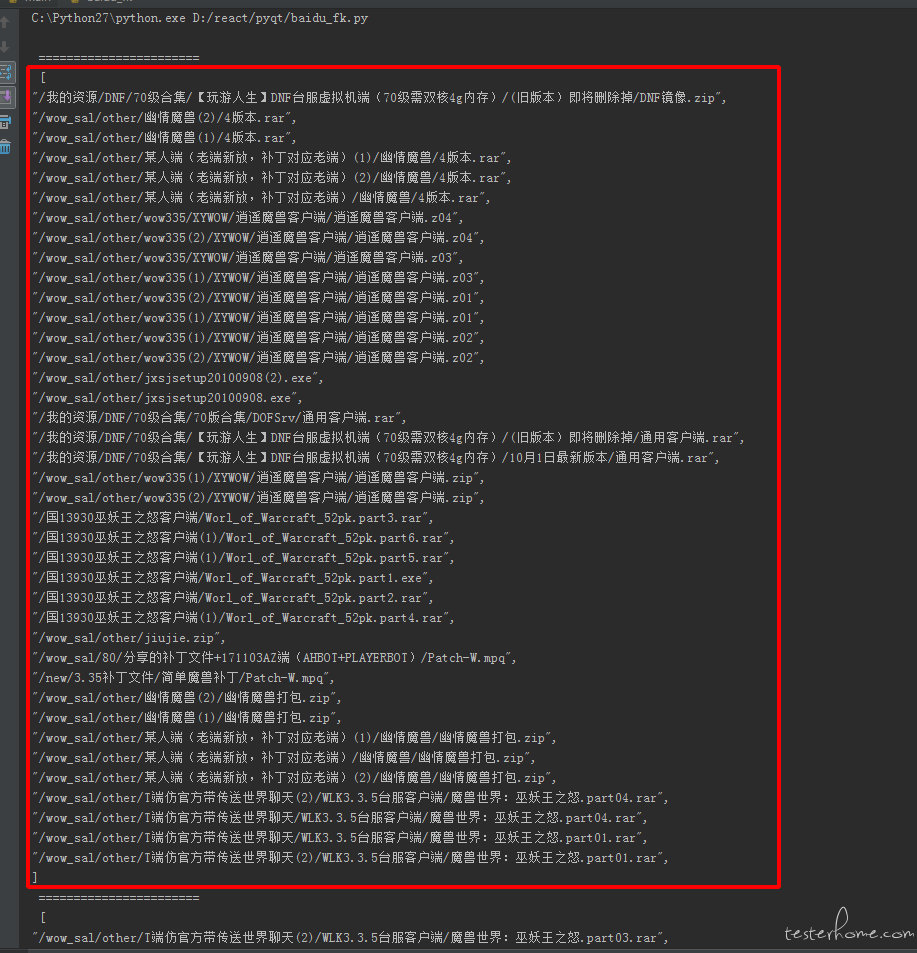
3.进入正题处理数据,获取需要删除的文件路径
我们需要上面从保存的 json 数据中,剔除掉一个作为保留,并把重复的路径放到新的数组中,这里我直接是打印出来的。
# -*-coding:utf-8-*-
import json
def get_need_delete_paths():
with open('baidu.json', 'r') as f:
data = json.loads(f.read())
a = 1
lists = data["list"]
need_delete_paths = []
for list in lists:
list_data = list["data"]
for i in range(1, len(list_data)):
need_delete_paths.append(list_data[i]["path"])
for path in need_delete_paths:
if a == 1:
print "\n ======================= \n ["
if a - 40 == 0:
a = 1
print "]\n ======================= \n ["
a = a + 1
print '"'+path+'",'
print "]\n ======================= \n"
get_need_delete_paths()
我的打印内容如下:(注意,因为后面的删除接口字段不能太长,所以我这边是每 40 条做了个分隔。)
4.获取删除文件接口
因为百度有登陆状态的校验,这里我们可以先随意找个没用的文件删除,再直接从 charles 里克隆这条接口。
#删除文件接口
https://pan.baidu.com/api/filemanager
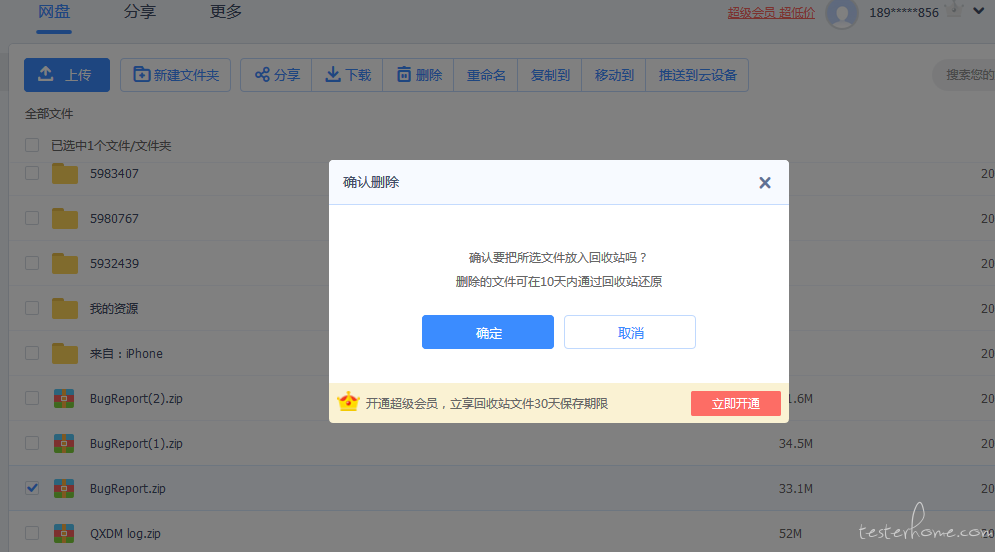
4.1 获取删除文件接口

4.2 克隆接口,并把需要删除的文件路径贴到字段里,(注意是个数组格式)。
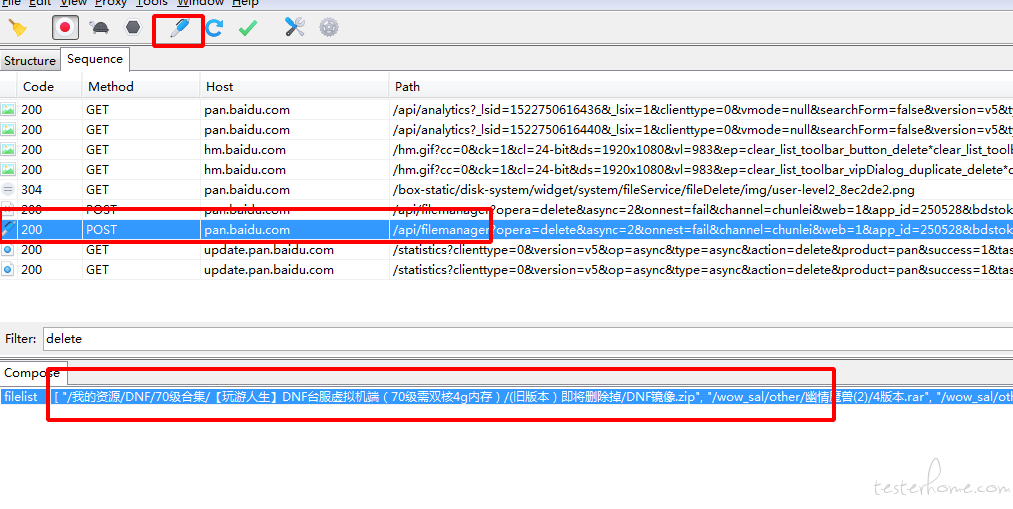
结果
这是我的删除记录,几百条重复数据,几下就清理干净了。
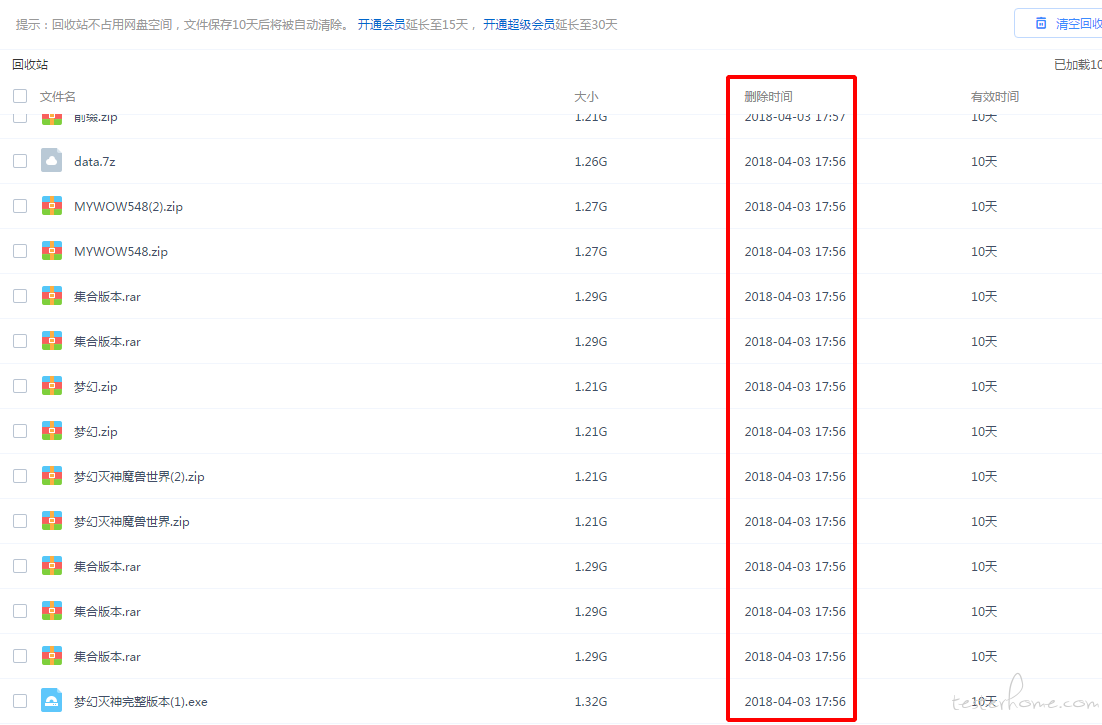
备注
有钱的、重复数据量少的请忽略。
「原创声明:保留所有权利,禁止转载」
如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!
