HttpRunner ApiTestEngine 正式更名为 HttpRunner
在《ApiTestEngine,不再局限于 API 的测试》一文的末尾,我提到随着ApiTestEngine的发展,它的实际功能特性和名字已经不大匹配,需要考虑改名了。
经过慎重考虑,最终决定将ApiTestEngine正式更名为HttpRunner。
名字的由来
为什么选择HttpRunner这个名字呢?
在改名之前,我的想法很明确,就是要在新名字中体现该工具最核心的两个特点:
- 该工具可实现任意基于 HTTP 协议接口的测试(自动化测试、持续集成、线上监控都是以此作为基础)
- 该工具可同时实现性能测试(这是区别于其它工具的最大卖点)
围绕着这两点,我开始踏上了纠结的取名之路。
首先想到的,ApiTestEngine实现HTTP请求是依赖于Python Requests,实现性能测试是依赖于Locust,而Locust同样依赖于Python Requests。可以说,ApiTestEngine完全是构建在Python Requests之上的,后续无论怎么进化,这一层关系应该都不会变。
考虑到Python Requests的slogan是:
Python HTTP Requests for Humans™
因此,我想在ApiTestEngine的新名字中应该包含HTTP。
那如何体现性能测试呢?
想到的关键词就load、perf、meter这些(来源于 LoadRunner,NeoLoad,JMeter),但又不能直接用,因为名字中带有这些词让人感觉就只是性能测试工具。而且,还要考虑跟HTTP这个词进行搭配。
最终,感觉runner这个词比较合适,一方面这来源于LoadRunner,大众的认可度可能会比较高;同时,这个词用在自动化测试和性能测试上都不会太牵强。
更重要的是,HttpRunner这个组合词当前还没有人用过,不管是PyPI还是GitHub,甚至域名都是可注册状态。
所以,就认定HttpRunner这个名字了。
相关影响
ApiTestEngine更名为HttpRunner之后,会对用户产生哪些影响呢?
先说结论,没有任何不好的影响!
在链接访问方面,受益于 GitHub 仓库链接的自动重定向机制,仓库在改名或者过户(Transfer ownership)之后,访问原有链接会自动实现重定向,因此之前博客中的链接也都不会受到影响。
新的仓库地址:https://github.com/HttpRunner/HttpRunner
在使用的命令方面,HttpRunner采用httprunner作为新的命令代替原有的ate命令;当然,为了考虑兼容性,HttpRunner对ate命令也进行了保留,因此httprunner和ate命令同时可用,并完全等价。在性能测试方面,locusts命令保持不变。
$ httprunner -V
HttpRunner version: 0.8.1b
PyUnitReport version: 0.1.3b
既然是全新的名字,新的篇章必然也得有一些新的东西。
为了方面用户安装,HttpRunner已托管至PyPI;后续大家可以方便的采用pip命令进行安装。
$ pip install HttpRunner
同时,HttpRunner 新增了大量使用说明文档,访问网址:https://httprunner.com/docs
关于项目改名这事儿,就说到这儿吧,希望你们也喜欢。
Hello World, HttpRunner.
项目也已加入 TesterHome 的开源项目收录了,喜欢的去点个赞吧
https://httprunner.com/ 已经可以访问了。
http://httprunner.top/ 里面的文档都是自己写的吗?如果是的话,可以直接写中文不?
ps,东西很赞!
执行完毕,生成的报告为啥跟楼主的不一样,看着像是没有样式了
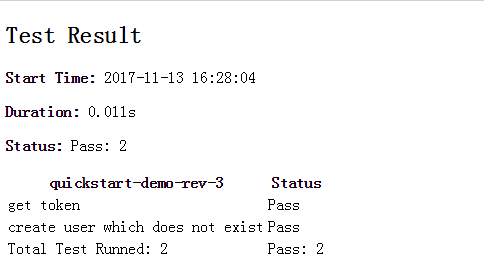
请问支持 no-web 格式吗,httprunner 的执行命令是这样吗:locusts -f baidu.py --full-speed --no-web -c 100 -r 10,会一直提示 waiting for slaves to be ready。
好像是因为我开了代理,尴尬
指定--full-speed之后,就会启用主从模式,例如计算机是 4 核的,那么就会启动一个 master,4 个 slave;而--no-web是只能单线程的,所以这两个参数是冲突的。
这也算一个 bug,提示信息不到位,我调整下。
@debugtalk
你好,最近看到了 Fuzzing 模糊测试,接触了两个开源工具:
1http://hypothesis.works/
2https://github.com/google/oss-fuzz
不知道 httprunner 能否 支持这连个工具的扩展 不知道 九毫 是否考虑接入这种支持。
httprunner 进行性能测试,带参数 --cpu-cores 2 时,web 页面点击开始,然后点击 STOP 后,仍然是 running 状态,刷新后又可以点击 STOP;
web 上,运行状态下面有一个 users 数量,这个数量有时候也和设置不一致。
请查看是否存在问题。(PS:在微信公众号上直接回复,你那边是不是收不到?)
安装 httprunner 用 pip3 install httprunner,先后需要自己安装 colorama、colorlog、pyyaml、requests、jinja2 这些组件,希望在文档中能给个说明,文档中目前只说用 pip3 install httprunner 就可以直接安装,谢谢
你安装 httprunner 的时候,就会自动安装那些依赖包的啊,不信你可以看下 setup.py 文件里面。
不好意思才看到,我刚在本地试了下是正常的;你先升级到最近版本再试下,要是还有问题的话就到 httprunner 提个 issue,附上你本地的环境和日志,我再看下。
@lyctest 感谢反馈,的确是个 bug,已经修复了;你再次安装应该就好了。
 客气客气,我想问下,我们有木有 httprunner 的交流群,现在文档还不完善,大家水平也不一样,所以可能会有许多人碰到不同的问题,所以希望能有个微信或者 qq 群可以交流的
客气客气,我想问下,我们有木有 httprunner 的交流群,现在文档还不完善,大家水平也不一样,所以可能会有许多人碰到不同的问题,所以希望能有个微信或者 qq 群可以交流的
中文文档已经写了很多了,https://httprunner.com/docs
我个人不是很喜欢 QQ/微信群的方式,信息会比较乱,而且内容也不好沉淀。
现在 GitHub 的 issues 中已经有好多人提了各种不同的问题了,你可以看下,要是有新的问题,就提 issue 吧。
主页 404 了
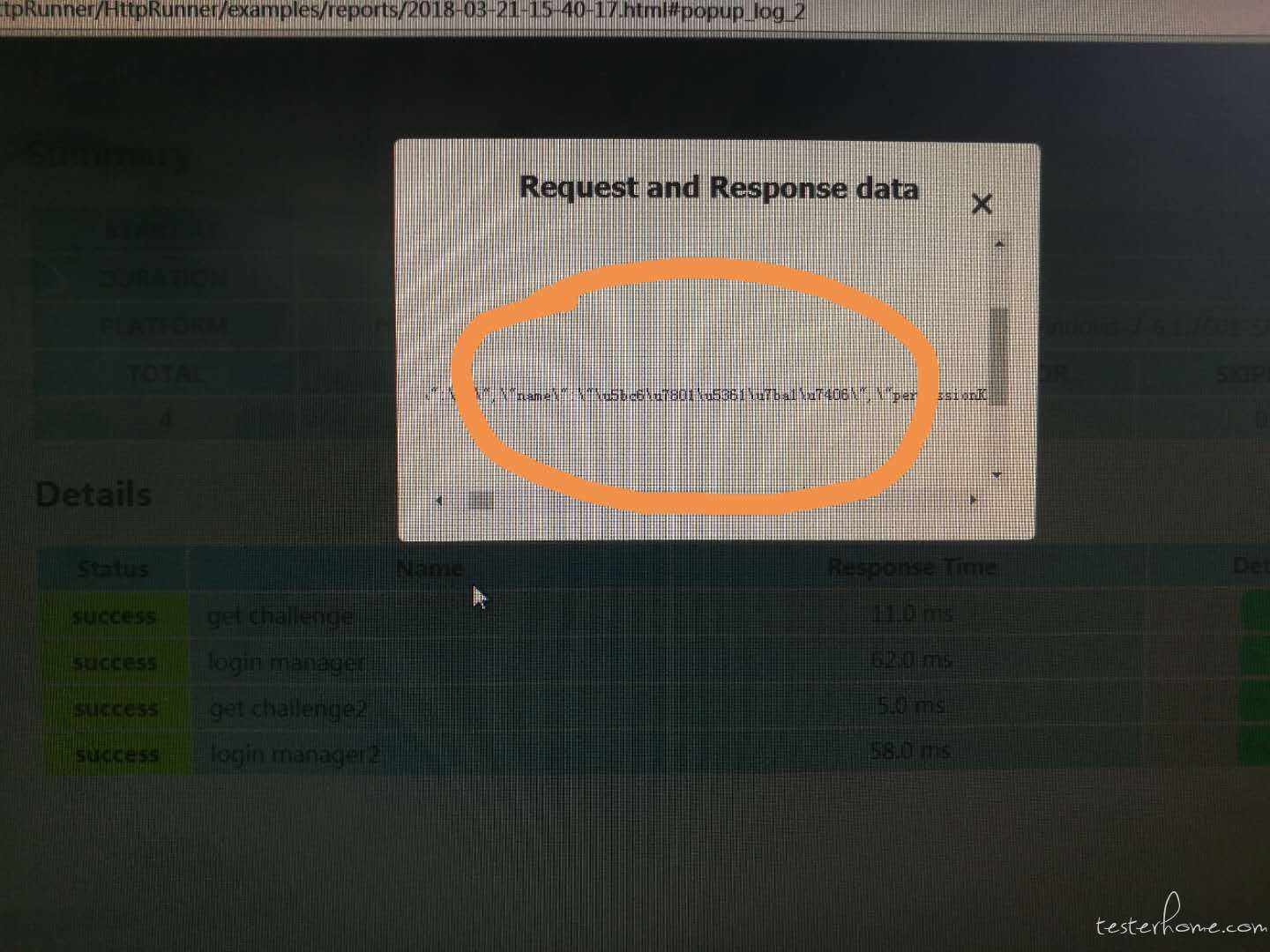
最近在使用过程中,遇到 html 日志中的汉字内容无法展示的情况,请问应该怎么解决呀
比如 response 有个 key:value 为:name: 密码卡管理;
在 html 的 log 中展示为: \"name\":\"\u5bc6\u7801\u5361\u7ba1\u7406\"
关于 setup_hooks 和 teardown_hooks 的更多内容,请参考《hook 机制》,报 404 了
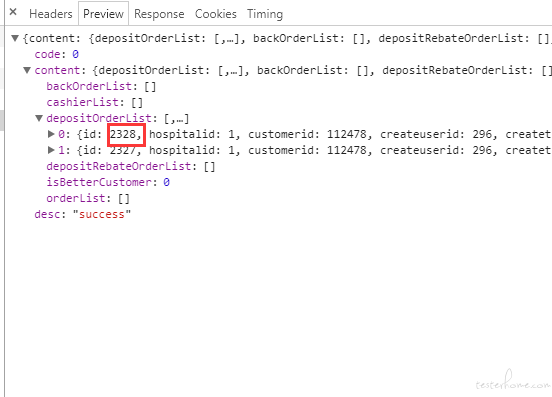
我想获取这个 id 值,该怎么写
@wuhao 已经修复了,更新到 1.3.6 就正常了。
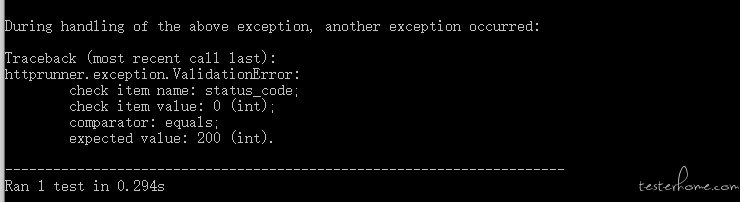
运行测试用例的时候,报错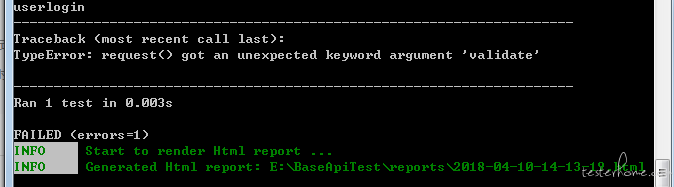 ,request() got an unexpected keyword argument 'validate'
,request() got an unexpected keyword argument 'validate'
@debugtalk ,您好,我抓取 https 开头的请求,报错如下:
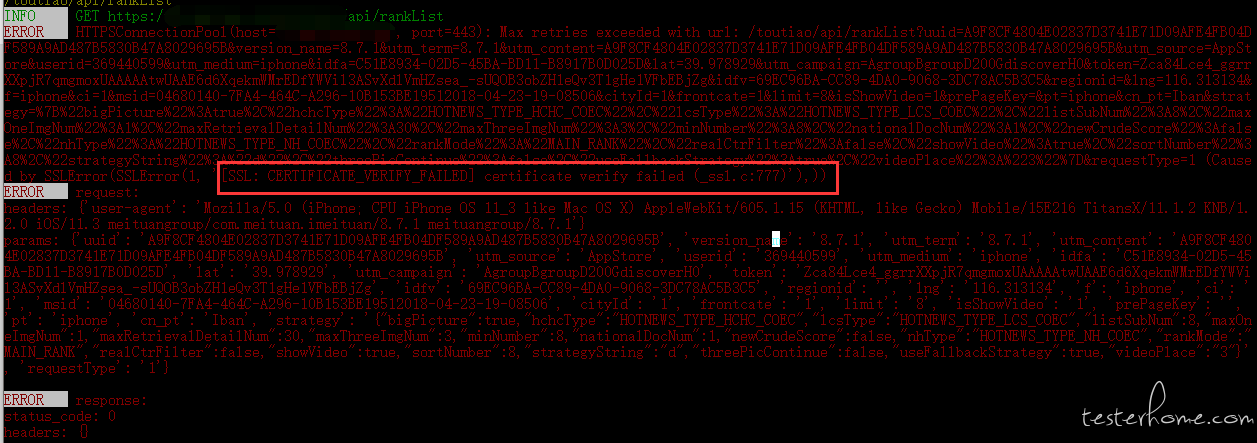
初步使用抓取 http 请求是没问题的,查看报错好像是证书的问题,请问这个框架如何验证证书呢?断言是这样的
非常感谢!
本地没有配置证书的原因,你使用 requests 请求也会遇到同样的问题。
解决方式就是关闭校验,即在 config 的 request 中 设置 verify = False。
@debugtalk 直接在 requests 中执行确实是报证书验证失败,我知道 requests 中直接加在 url 的后方。
在您的 client.py 中,是要这样加上 “verify = FALSE”
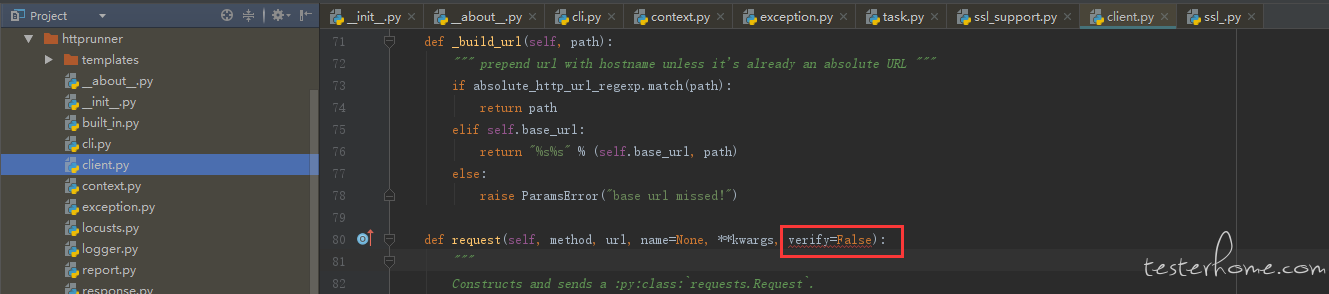 ,看似好像不对,本人小白,望您具体指点下,应该在哪个.py 文件中修改呢?
,看似好像不对,本人小白,望您具体指点下,应该在哪个.py 文件中修改呢?
执行 postman 是正常的。
有一点疑问,就是比如我运行多个文件的时候,比如我有 1.yml, 2.yml,是否可以指定顺序
httprunner 1.yml 2.yml 实际下那是并不会按照我参数顺序去执行,然后实际场景 我就是需要 1 执行完毕后再去执行 2 里面的接口
提一个需要功能提升问题,谢谢。
问题场景是这样的,我需要获取 response 里的一个 int 值作为下一个用例的 header. 而 header 不支持 int. 遂在 extract 里用了一个方法。
转字符串方法:
def tostring(value):
return str(value)
Yml 引用:
extract:
- token: content.token
- userid: content.data.userId
- stringuserid: ${tostring($userid)}
提示 extract 不支持正则:

想请问一下,在 debugtalk.py 定义函数,不靠用例文件的每个参数的传参,可以直接拿到接口的请求参数么
作者大大,最近重新研究了这个框架的源码,有一个疑问,为何当时没有基于 pytest 去扩展,而是基于 unittest 呢(其实我心里有一个答案,但是想看下作者是否和我想的一样 )忘解答
)忘解答
感谢 debug 大大回复,我在看您的《ApiTestEngine 演进之路(1)搭建基础框架》中写到 “如果每条测试用例都要在 unittest.TestCase 分别写一个单元测试进行调用,还是会存在大量重复工作。好的做法是,再实现一个单元测试用例生成功能;这部分先不展开,后面再进行详细描述。” --但是看完后面几章好像也没找到介绍的地方,不知是否是您给忘记这块内容了,忘解答,非常感谢!!(主要是自己在用 pytest 时,也没找到合适的方法去解决重复写用例的方法
- 你好,请问下about文件只是对项目的描述性文件么
resp = {
"code": 200,
"msg": "OK",
"data": [
{
"name": "lisi",
"age": 20,
"company": "百度",
"job": "工程师1"
},{
"name": "张三",
"age": 26,
"company": "阿里",
"job": "工程师1"
}]}
- extract 想提取 content.data 下 怎么通过 name(名称不固定) 拿到 age,实现上一接口里面提取参数,传给下一接口