自动化工具 接口自动化框架从 windows 迁移至 linux 后执行脚本 htmltestrunner 中的 report 一直不显示
求助!最近把接口自动化框架(python+unittest+htmltestrunner)从自己本地的 windows 迁移至了 linux 中,linux 中也已安装了相关的 python 环境及需要的第三方类库,框架代码及测试脚本也通过 svn 同步到 linux 中的相关目录下。这时候运行脚本后在报告 report 目录中查看运行的结果,结果打开后,显示如下:
而同样的脚本在 windows 下运行是正常的,自己也调试了很多次,都没有任何效果。不知道各位大神有没有遇到过这种情况,还能给与解答,谢谢!
现在通过在 windows 和 linux 下的层层代码调试,好像定位到了一个问题,如下图:


我的框架下是把测试数据提取到 excel 中,通过读取 excel 去执行,现在从以上两个图片中的打印日志可以看出,linux 中没有读取到 excel 中的 sheet 文件,是不是 linux 默认不支持读取 excel 文件?还请知道的大神能给与解答,谢谢!
linux 的 文件路径和 Windows 的不一致,是不是你获取测试用例的路径写错了
testsuite 应该不是读取测试数据的,应该是遍历 python 包寻找测试用例,Linux 这个就是测试用例的 list 为空,你把执行的代码贴下
执行代码如下
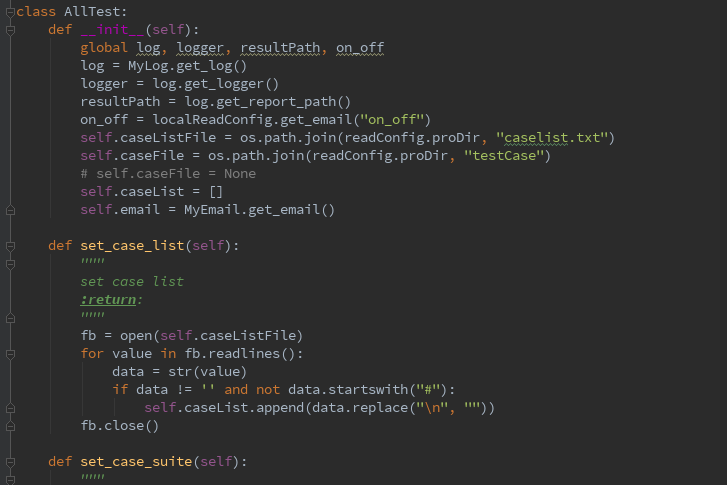
class AllTest:
def init(self):
global log, logger, resultPath, on_off
log = MyLog.get_log()
logger = log.get_logger()
resultPath = log.get_report_path()
on_off = localReadConfig.get_email("on_off")
#caselist 所有平台的 OP 接口,caselist1 为除 dmp 平台外的所有接口
self.caseListFile = os.path.join(readConfig.proDir, "caselist1.txt")
self.caseFile = os.path.join(readConfig.proDir, "testCase")
# self.caseFile = None
self.caseList = []
self.email = MyEmail.get_email()
# 添加需运行用例
def set_case_list(self):
fb = open(self.caseListFile)
for value in fb.readlines():
data = str(value)
if data != '' and not data.startswith("#"):
self.caseList.append(data.replace("\n", ""))
fb.close()
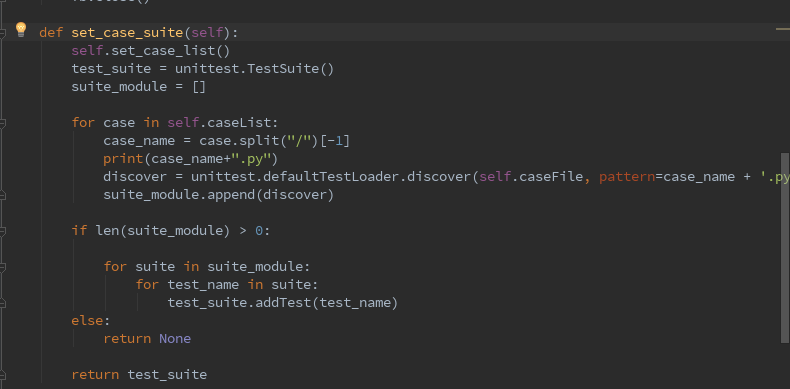
def set_case_suite(self):
self.set_case_list()
test_suite = unittest.TestSuite()
suite_module = []
for case in self.caseList:
case_name = case.split("/")[-1]
print(case_name+".py")
discover = unittest.defaultTestLoader.discover(self.caseFile, pattern=case_name + '.py', top_level_dir=None)
suite_module.append(discover)
print suite_module
if len(suite_module) > 0:
for suite in suite_module:
for test_name in suite:
test_suite.addTest(test_name)
else:
return None
return test_suite
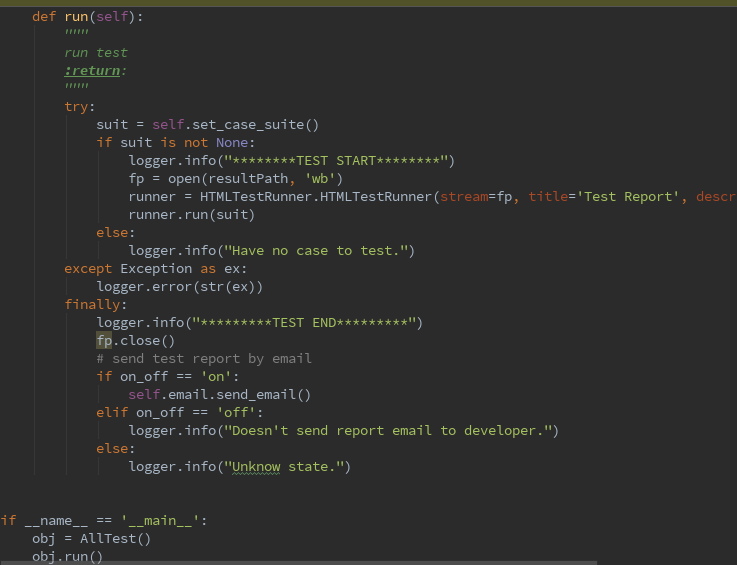
def run(self):
"""
run test
:return:
"""
try:
suit = self.set_case_suite()
if suit is not None:
logger.info("*****TEST START**")
fp = open(resultPath, 'wb')
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title='Test Report', description='Test Description')
runner.run(suit)
else:
logger.info("Have no case to test.")
except Exception as ex:
logger.error(str(ex))
finally:
logger.info("***TEST END******")
fp.close()
# send test report by email
if on_off == 'on':
self.email.send_email()
elif on_off == 'off':
logger.info("Don't send report email.")
else:
logger.info("Unknow state.")
if name == 'main':
obj = AllTest()
obj.run()
上面的代码格式不对,还是看下面这个截图清晰一点:
case.split('/') 看下这里有没有问题?
另外,markdown 代码块支持代码着色的,不需要贴图。
重点调试下从 txt 里读取出来的数据对不对吧,加多几个输出看下
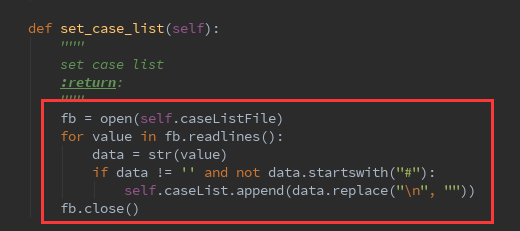
这边调试过都能正常读取 txt 里面的数据,脚本如下:
实际打印显示如下: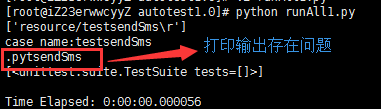
print case_name+".py" 这个本来应该显示未 testsendSms.py 而实际却显示成了.pytsendSms 了,这个很奇怪啊,我在 linux 上单独试了打印输出效果是好的,这个跟 python 版本应该没关系吧,linux 中安装的 python 版本是 2.7.5 的
discover 方法里的 pattern 参数改成 "test*.py" 试试
pattern='test*.py'
之前忘了更新这个帖子了,问题之前已经得到解决了。先说下之前无法显示.py 之前内容的问题,是由于在 linux 中从文本中读取的用例名称中最后都包含\r 结尾,导致在输出的时候.py 会直接覆盖.py 之前的内容,在打印该用例名称之前增加 case_name = case_name.replace('\r','') 过滤掉\r 内容即可正常打印出对应的用例名称.py ,现在已经能够正常在 linux 中跑用例脚本了

这是什么
初次学习使用 linux+jenkins;我 jenkins 装到 linux 服务器上的,想把 selenium+python 的脚本用 jenkins 来运行。但是不知道具体步骤;求大佬指点:
1、需要把 selenium 和 python 都装到服务器上去搭建好环境吗?
2、jenkins 上怎么去运行这个 python 脚本呢?
1.相关的工具涉及的 python 环境都需要部署安装到你对应的环境中,就跟 windows 中需要运行的环境一样,具体如何在 linux 上安装可以自行百度;
2.jenkins 可以在你新建的 jenkins 任务中进行配置,对应你需要运行的 python 脚本路径即可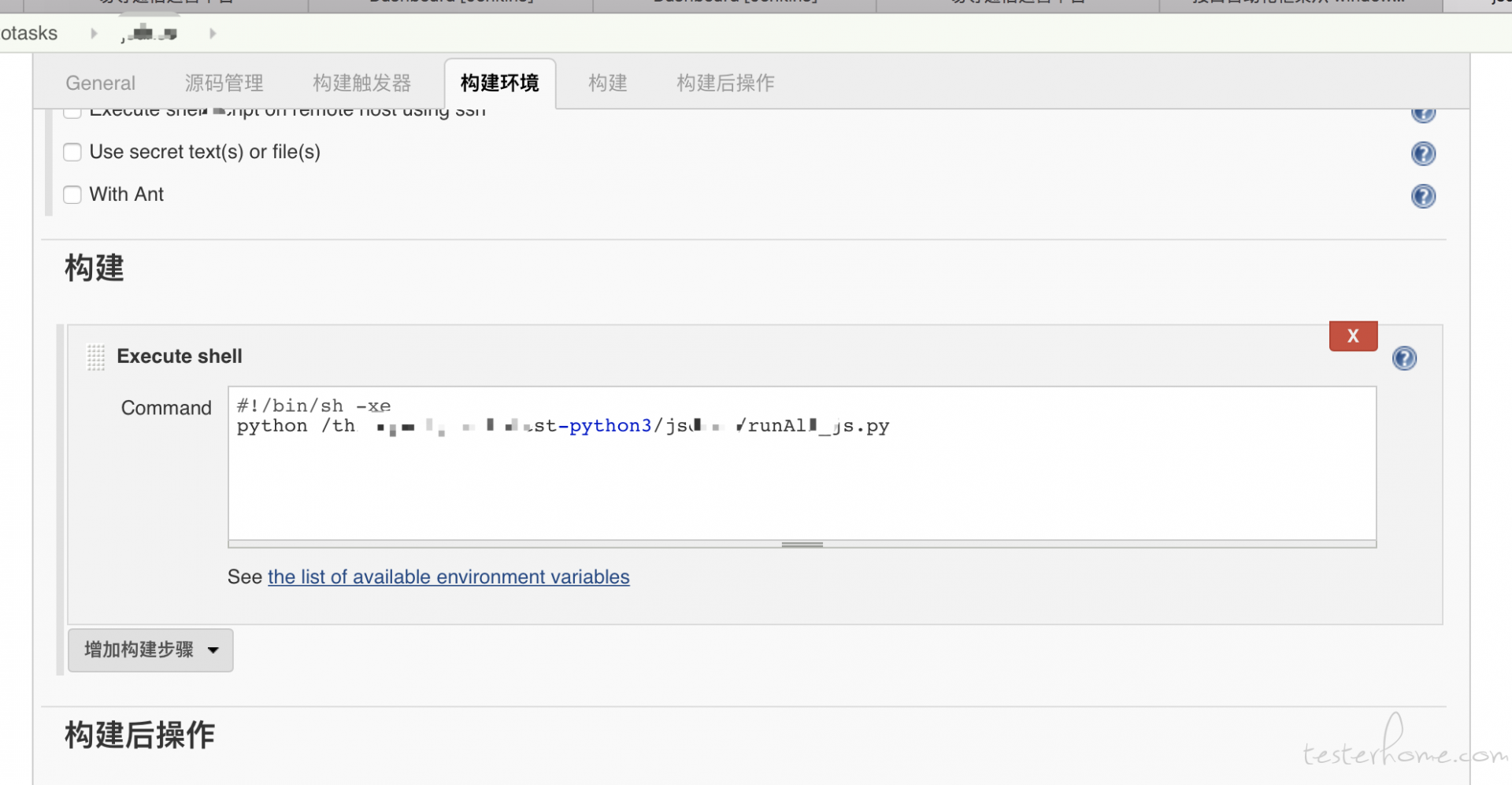
PS:另外 linux 有自带的 crontab -e 跑定时任务的,相关执行脚本和执行时间也可以在这个里面进行配置