-
请教一个 pytest 中 fixture 相关问题:将 fixture 中写入 allure 附件的代码提出来定义成自定义方法后,就无法按预期写入 allure 附件了 at July 04, 2024
哇,实践了下,可以成功达到预期效果。过程和原因我得在思考消化下,谢谢。
方便加您一下微信吗,
GXY1162031010 -
请教一个 pytest 中 fixture 相关问题:将 fixture 中写入 allure 附件的代码提出来定义成自定义方法后,就无法按预期写入 allure 附件了 at July 03, 2024
试了下确实可以,但问题是 check_response 中的 return,不同的 fixture 需要返回数据的位置是不一样的,所以起初我才想的是将这个返回数据的位置作为参数传进来,然而作为参数传进来就无法按期望写 allure 附件了。
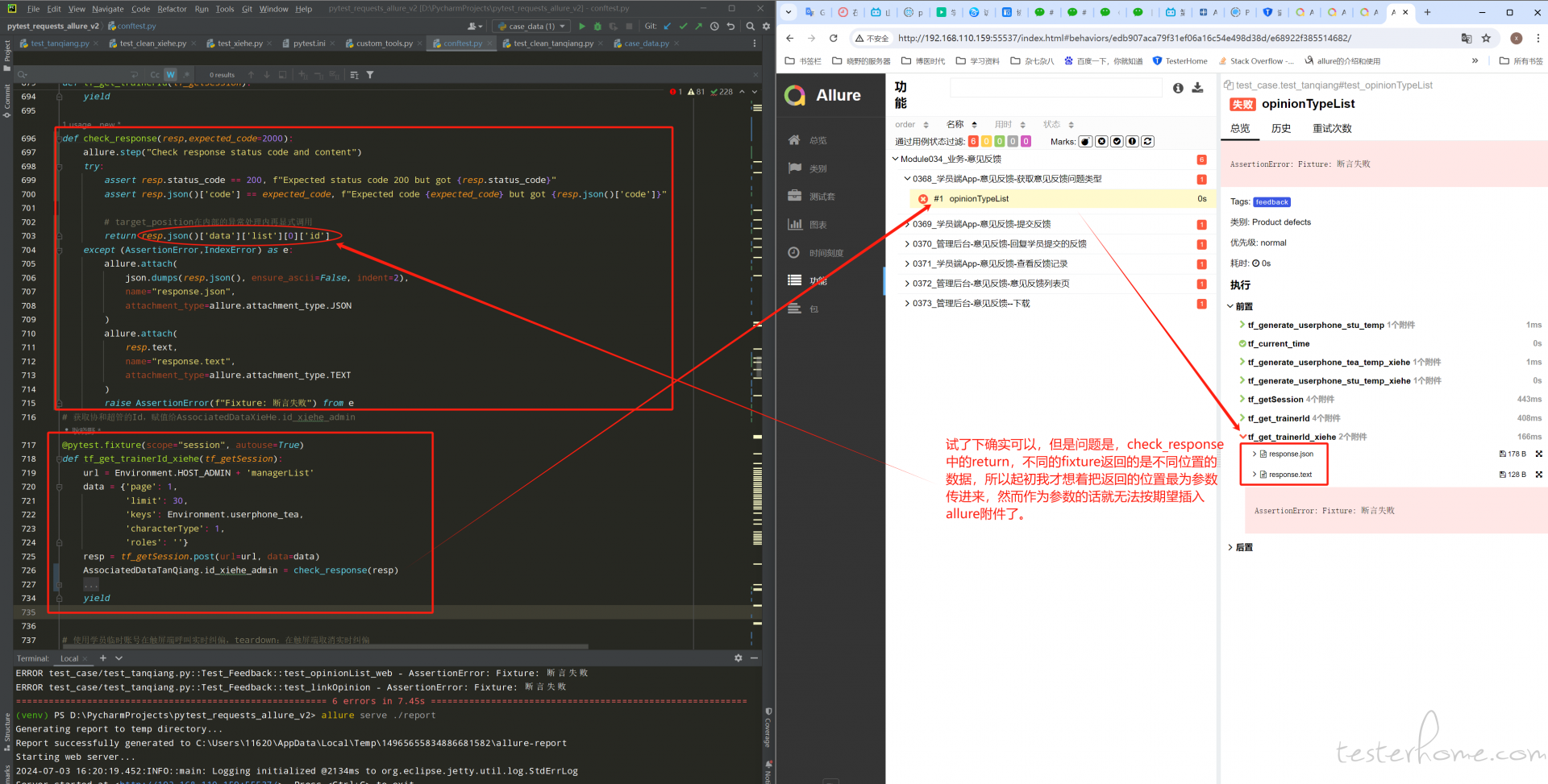
-
请教一个 pytest 中 fixture 相关问题:将 fixture 中写入 allure 附件的代码提出来定义成自定义方法后,就无法按预期写入 allure 附件了 at July 03, 2024
当前,我把写入 allure 附件的代码从 try 中提出来了,目前不论 fixture 自身报不报错,我都将请求和响应的相关信息写进附件。以下代码可以实现添加附件功能。可是我还是不太明了文中提到的问题原因,难道是因为在 try 中调用自定义方法导致达不到预期效果的?
# 向fixture中添加附件 def add_allure_attachment(url, data, resp): allure.step("Check response status code and content") allure.attach( url, name="request_url.txt", attachment_type=allure.attachment_type.TEXT ) allure.attach( json.dumps(data, ensure_ascii=False, indent=2), name="request_data.json", attachment_type=allure.attachment_type.JSON ) allure.attach( json.dumps(resp.json(), ensure_ascii=False, indent=2), name="response.json", attachment_type=allure.attachment_type.JSON ) allure.attach( resp.text, name="response.text", attachment_type=allure.attachment_type.TEXT ) # 实例化一个session,用于管理后台请求需要验证身份的接口 @pytest.fixture(scope="session") def tf_getSession(): url = Environment.HOST_ADMIN + 'loginin' data = { 'username': Environment.userphone_tea, 'password': Environment.password_tea } ses = requests.session() resp = ses.post(url=url, data=data) add_allure_attachment(url=url, data=data, resp=resp) try: assert resp.status_code == 200, f"Expected status code 200 but got {resp.status_code}" assert resp.json()['code'] == 2000, f"Expected code {2000} but got {resp.json()['code']}" return ses except (AssertionError, IndexError) as e: raise AssertionError(f"Fixture 断言失败") from e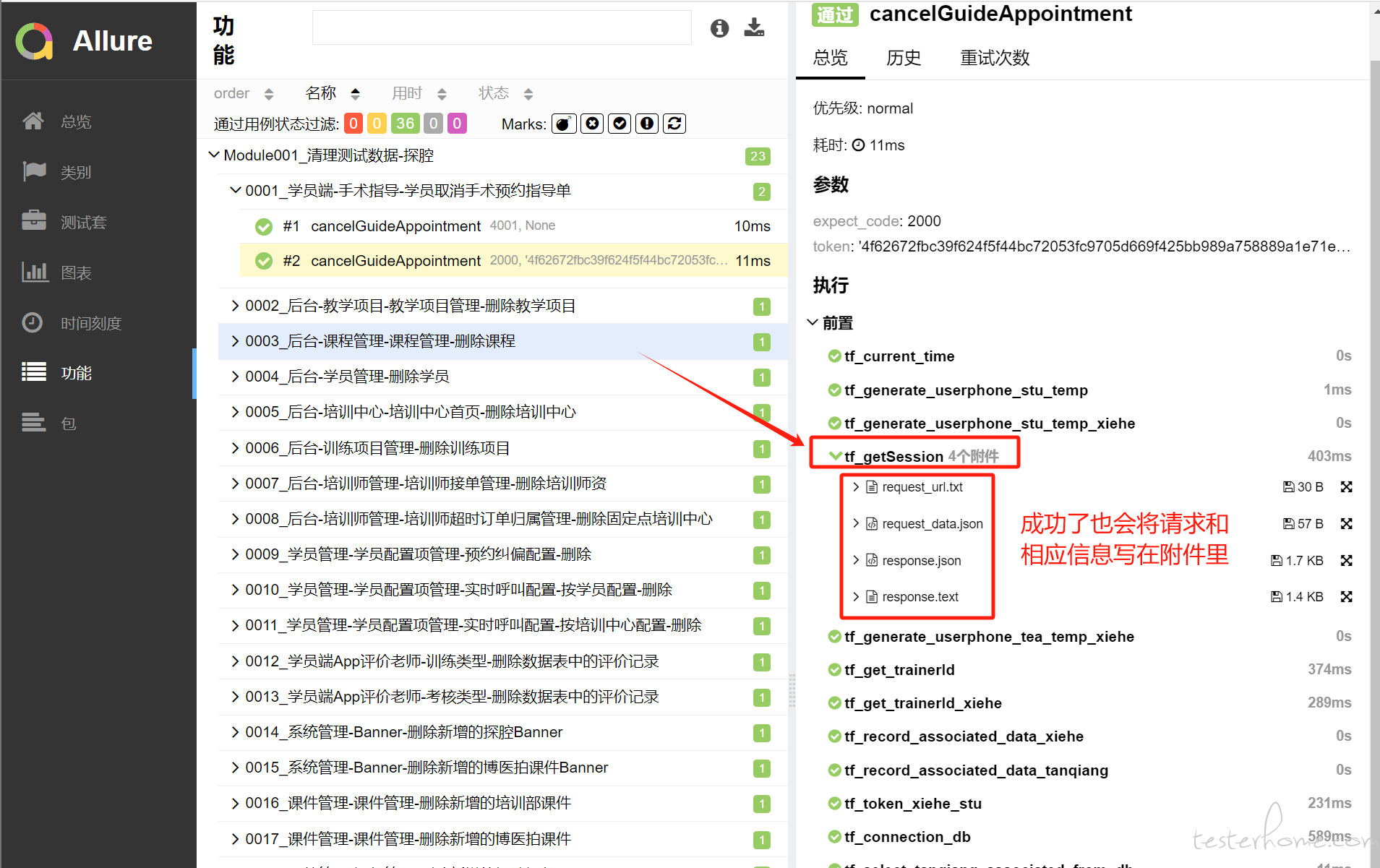
-
请教一个 pytest 中 fixture 相关问题:将 fixture 中写入 allure 附件的代码提出来定义成自定义方法后,就无法按预期写入 allure 附件了 at July 03, 2024
不太明白还是,如果想提出来的话应该怎么提呢

-
这次,我掌握了 pytest 中 fixture 的使用及 pytest 运行测试的加载顺序 at May 21, 2024
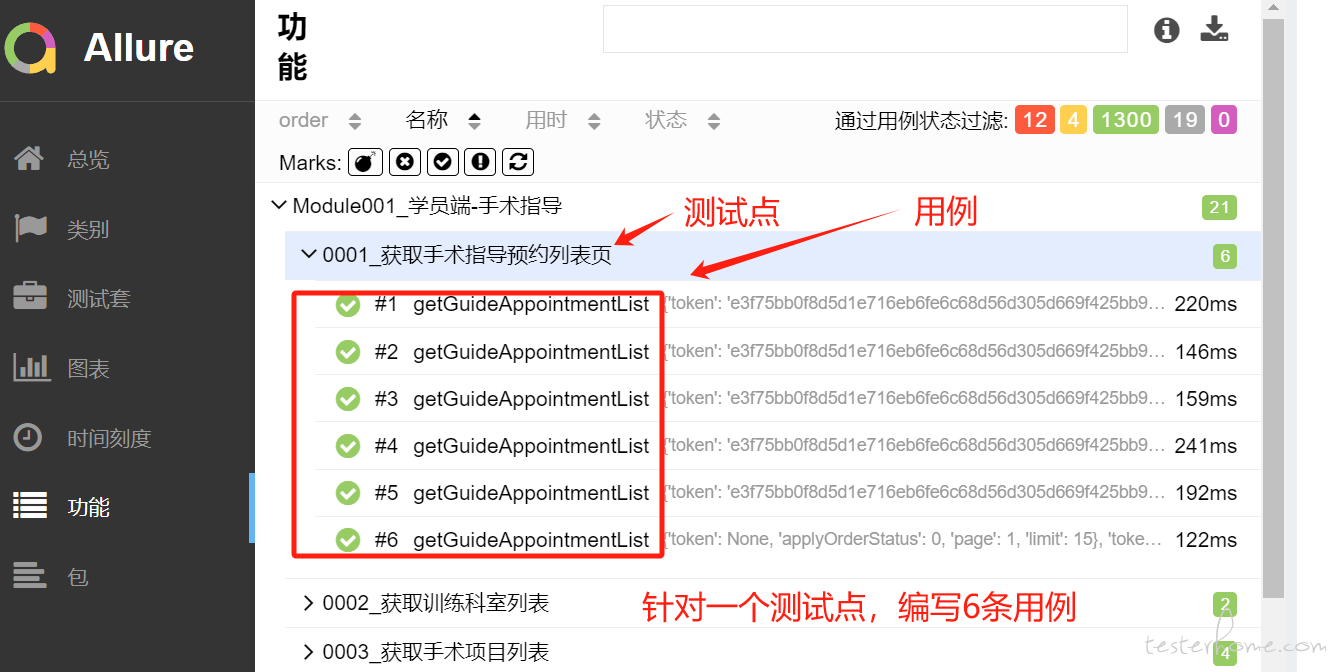
针对一个测试点我们会设计多条用例,总不能一个测试点就一条 case 吧,像这样:
-
这次,我掌握了 pytest 中 fixture 的使用及 pytest 运行测试的加载顺序 at May 17, 2024
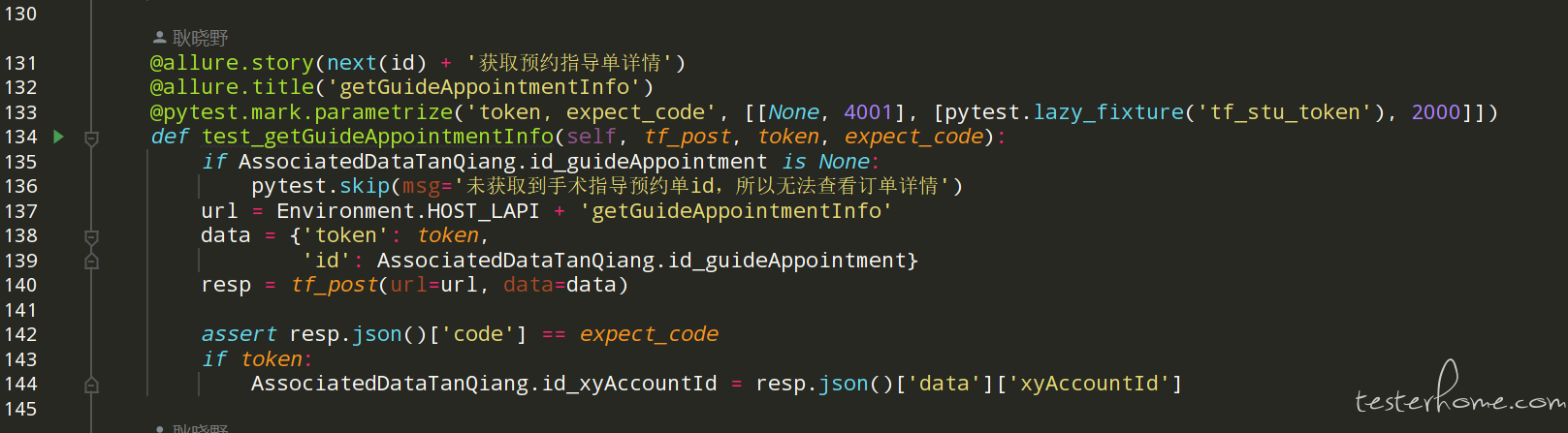
在 parametrize()里放 fixture 需要用 pytest-lazy-fixture。我有用过,像下面这样:
-
这次,我掌握了 pytest 中 fixture 的使用及 pytest 运行测试的加载顺序 at May 17, 2024
如果把造数放在用例内部,那最后的测试报告应该就会显示一条 case 吧,像上面的例子,如果把造数函数放在参数化里,allure 报告就会显示 6 条 case,以至于哪条 case 不通过显示的也比较明显

-
Pytest 顺序执行,依赖执行,参数化执行 at May 15, 2024
你说得对哦铁铁,使用生成器确实不能解决作者的问题,使用生成器只能解决写死数字致使的后续编辑时需要重新编辑排序数字的问题,并且是在特定的顺序执行的情况下才能达到预期效果。
那有什么好的办法可以解决及不想将排序写死,还能控制用例执行顺序的方法呢? -
Pytest 顺序执行,依赖执行,参数化执行 at May 14, 2024
用 order 确实是控制用例执行顺序的好办法,但最大的弊端就是不利于修改,比如已经拍好了 order(1),order(2),,,后面编辑的时候要在其中插入一条 case,那就得重新遍历后面所有已经写好的序号。
我目前用的是生成器,可以有效解决后续编辑需要修改 order 编号的问题,大致如下:

-
pytest 接口测试 - 接口依赖 情况下实现 参数化 的问题和解决过程 at May 14, 2024
load_cases() 里面的 order_id 是创建订单接口创建成功后返回的,并非测试前写死的。创建订单接口本身也要作为待测试接口,在此情况下,我是不是可以理解为在 load_cases() 里面将 create 接口默认认为是测试通过的接口,然后根据创建订单接口的返回值来构造 return 的值
-
pytest 接口测试 - 接口依赖 情况下实现 参数化 的问题和解决过程 at May 14, 2024
文中提到的参数化用的是@pytest.mark.parametrize,可能由于编辑器问题,发布后变成了@user5ize

-
请教一个问题:如何让 allure 报告中用例的展示顺序按照用例的执行顺序展示? at April 20, 2023
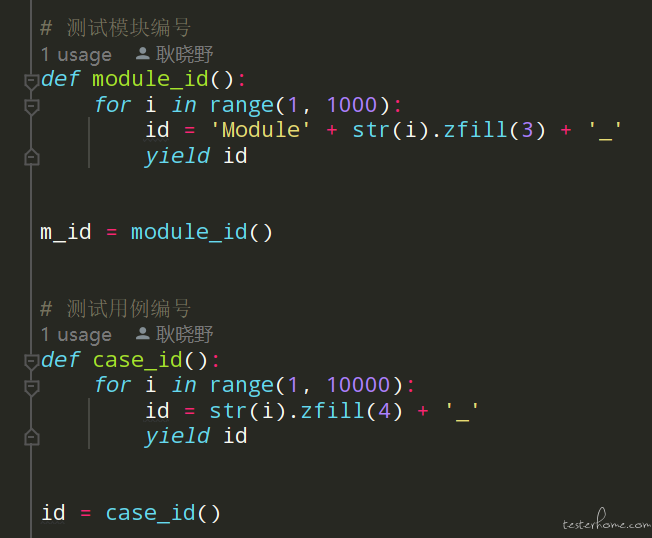
这个问题被解决了!定义两个用于生成编号的生成器
具体是这样的:在此之前为了 allure 报告的展示顺序,我是在编写 case 的同时手动添加的编号,这样就会导致在编写 case 时费时费力,在后期维护过程中也不能很好的解决在用例中间插入新用例的编号如何选取的问题。为此,经过不断地实践,确定了目前的方案:定义两个用于生成编号的生成器函数,一个是用于不同测试板块的编号"module_id()",另一个是用于生成各个测试用例的编号"case_id()",然后在测试用例中,在 allure.feature() 中添加测试板块编号,在 allure.story() 中添加测试用例编号,去除之前版本中的@allure.title() 和测试用例中的编号 (意义不大,那就能省则省。直接上图,直观些:
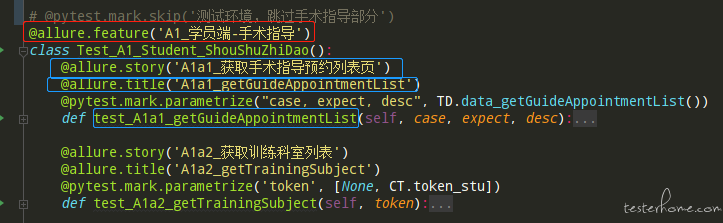
原测试用例如下:
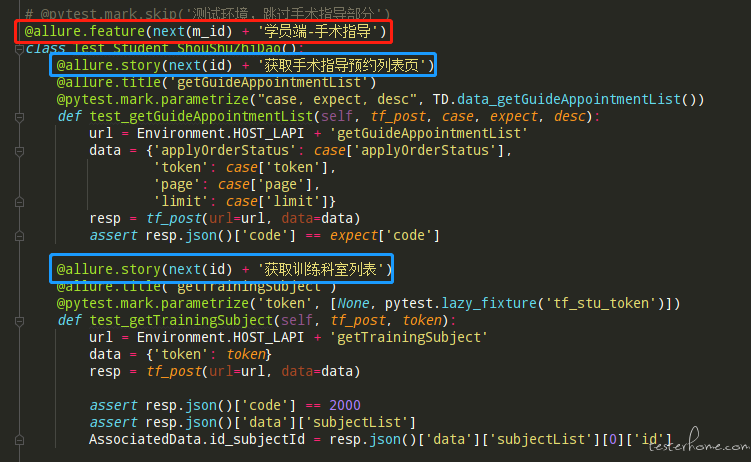
升级后用例如下:

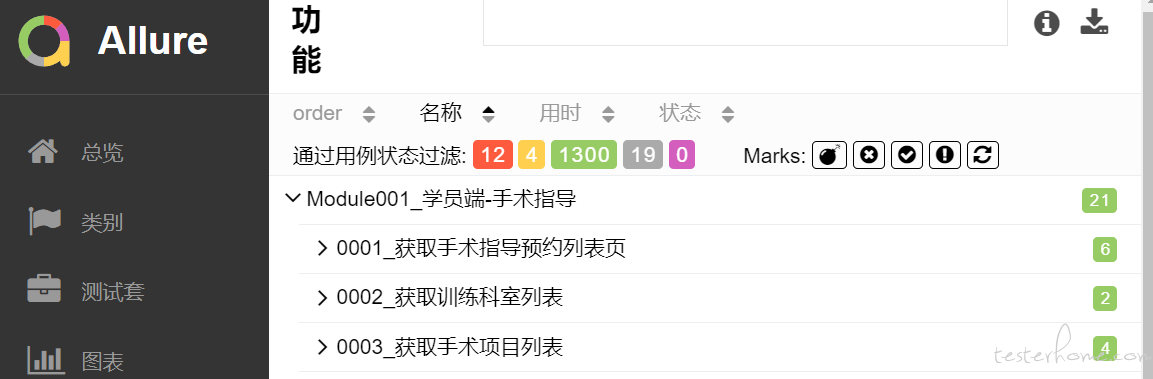
升级后 allure 测试报告如下
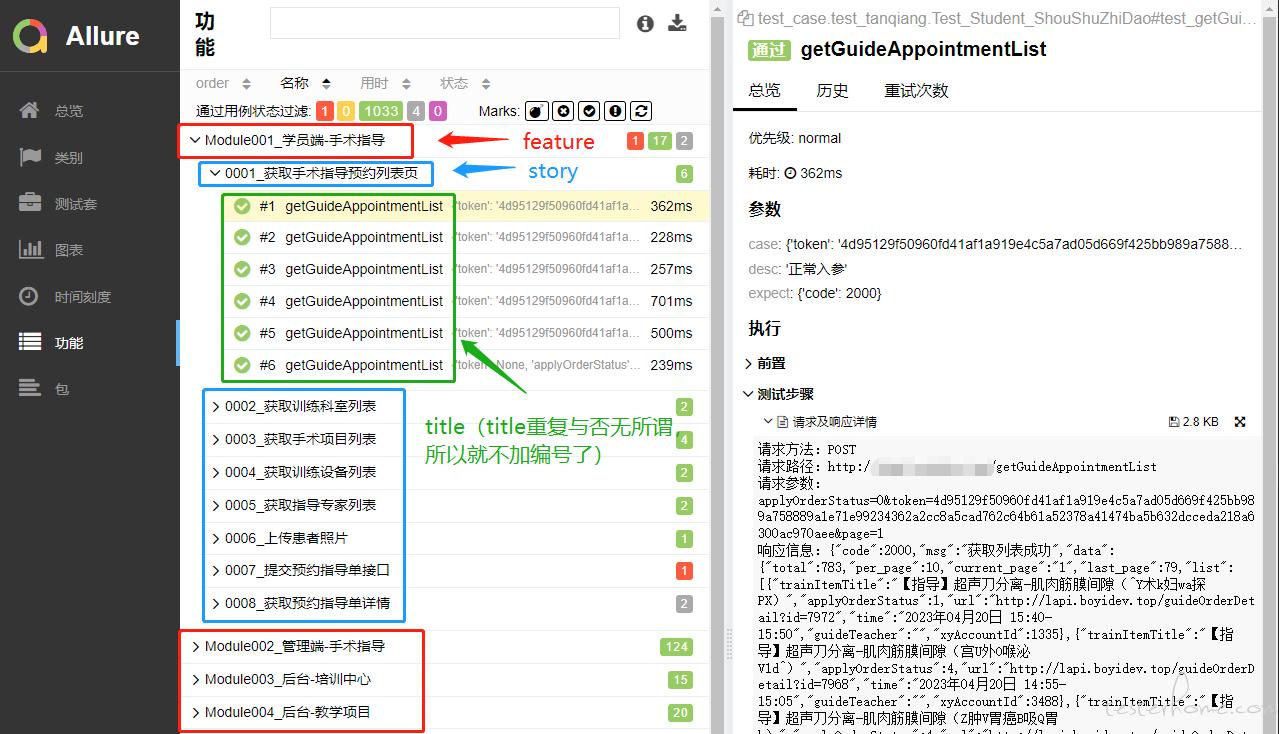
从以上描述可以看出我们即优化了测试用例的编写,又控制住了 allure 报告中的用例展示顺序。
当然,如果有佬儿哥佬儿姐有更好的解决方案,还希望可以多多指点。题外话:此前有关注过我的小伙伴可能知道我将接口自动化的搭建过程总结过两篇文章,将从 0 摸索的过程详细的记录了下来,这本就是一个有趣的不断发现问题,解决问题的过程,距上次升级,又有了一些沉淀,我打算将此次更新过程再总结发布出来,此次升级大致的内容如下:
1.升级测试模块和测试用例的编号形式 (如上);
2.解决接口依赖情况下依赖参数如何做数据驱动的问题;
3.解决各个用例中部分内容重复编写的问题,例如每个用例中都会写 allure 报告信息收集的代码、接口响应时间和 status_code == 200 的断言语句。最终效果是同一用例由原 18 行缩减至 10 行,同样的测试脚本由原 3600 行缩减至 2800 行。
4.增加对接口返回数据的数据类型断言功能;
除此之外还有一些测试脚本的目录优化等内容,如果感兴趣的伙伴可以关注一下。在自我总结之余,我更希望的也是可以收到小伙伴们的各种指导意见,下次见~
-
请教一个问题:如何让 allure 报告中用例的展示顺序按照用例的执行顺序展示? at April 13, 2023
如果在 order 中手动编序号那我感觉和我直接在用例名称里添加序号无异了,后续维护时在用例中间添加新用例的话这个 order 是不是还需要重排

-
请教一个问题:如何让 allure 报告中用例的展示顺序按照用例的执行顺序展示? at April 13, 2023
我用例中添加了 feature 和 story,我希望 allure 的报告中也先按照用例定义的 feature 顺序排序,然后同一 feature 下按照用例定义的 story 顺序排序,目前使用 order 只能让最里层的用例 (#1、#2 这些) 顺序排序,至于 feature 和 story 还是乱的。我贴张图可能会清楚些:
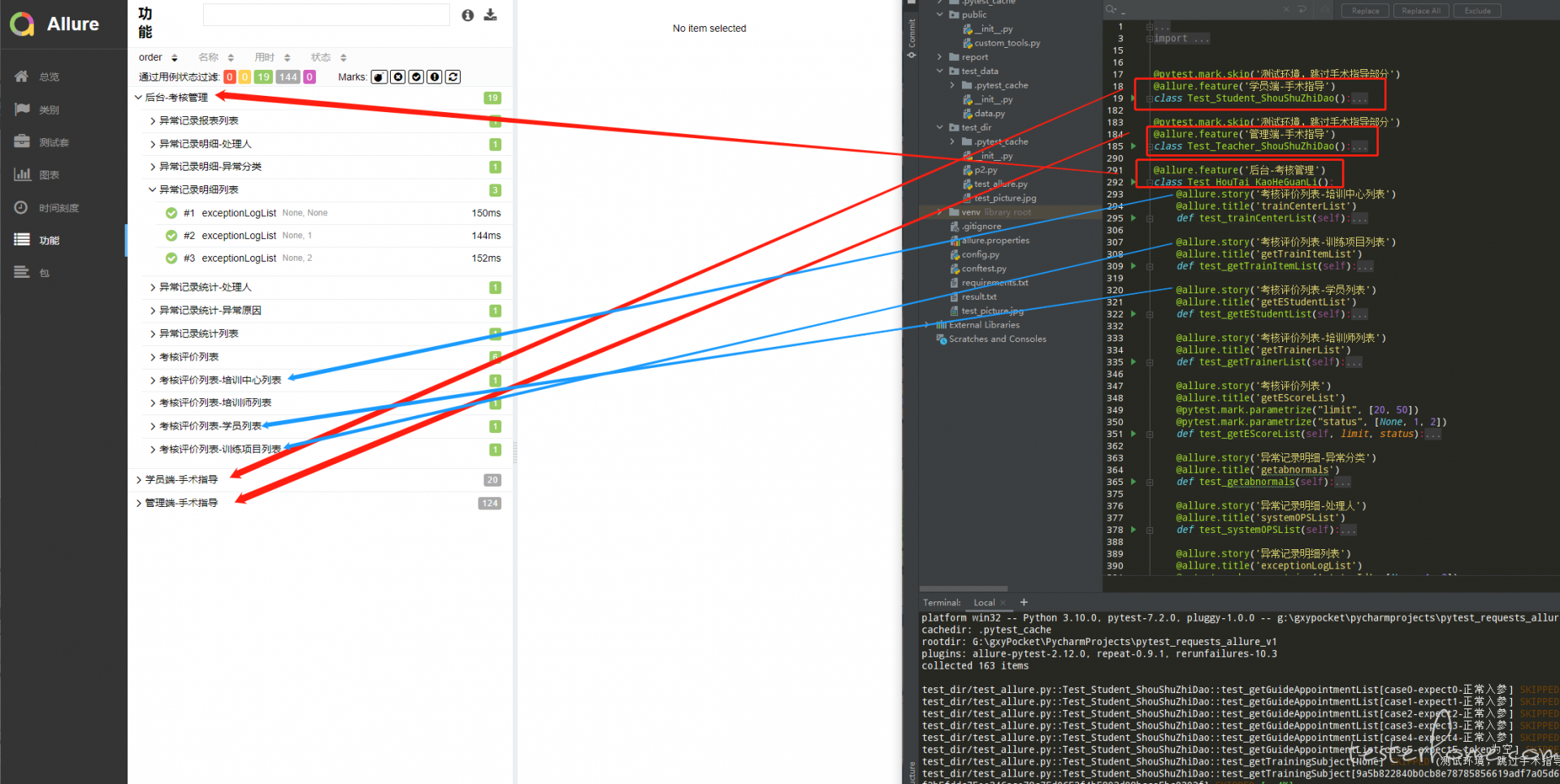
-
请教一个问题:如何让 allure 报告中用例的展示顺序按照用例的执行顺序展示? at April 13, 2023
必然试过了,必然不行,至于 order 和名称的逻辑规则我也正在查
-
测试基础-Python 篇 琐碎但十分实用的知识点 at February 24, 2023
平时多和 Error 见见面,等调试的时候就不那么发憷了!
测试基础-Python 篇 PyCharm 调试步骤及 Python 运行时常见错误
-
测试基础-Python 篇 基础① at February 22, 2023
补充一下 Python 项目目录和文件的命名规范,建议来源于 ChatGPT。

-
接口测试 - 从 0 不到 1 的心路历程 at February 22, 2023
接口自动化除了脚本框架外,核心其实还是用例设计,怎么设计用例才能保证代码覆盖率,更细粒度的场景能不能自动化,比方说服务与三方服务的异常交互,这样就衍变出单服务的自动化测试及测试思维,从单服务入手也能模拟各种故障演练,有时间的话可以研究研究这部分,比研究框架更有价值,框架够用就行。
受益了,确实,接入接口自动化测试一段时间之后,越发的能体会到 “框架够用就行,核心还是用例设计” 这句话,后续会在佬哥儿指出的方向上加大投入,感谢指点。
-
接口测试 - 从 0 不到 1 的心路历程 at February 16, 2023
哈哈,我这么做了没多久就被社区中的佬儿哥推荐了解使用 allure,学习了解后很快对 excel 的爱就消失了,建议你也了解下,或者看一下我的下一篇文章接口测试 - 从 0 不到 1 的心路历程 (二)
-
测试开发 - 一天一个面试题之计算机网络 at February 15, 2023
又涨了那么亿点点知识

-
在 Linux 上搭建 Jenkins,自动构建接口测试 at February 03, 2023
不好意思,最近有点忙,回复不及时,方便的话加个 V 讨论下:GXY1162031010,不一定能解决,但我尽力帮你搞搞明白。
-
在 Linux 上搭建 Jenkins,自动构建接口测试 at January 13, 2023
我把测试脚本上传到了 git 上,git 上就能看到地址,比如我的:
-
在 Linux 上搭建 Jenkins,自动构建接口测试 at December 28, 2022
-
接口测试 - 从 0 不到 1 的心路历程 (二) at December 25, 2022
那还要感谢伙伴儿们的指点纠偏,找准了方向,行动起来就顺利多了
-
接口测试 - 从 0 不到 1 的心路历程 (二) at December 25, 2022
感谢你能读文,我没太了解你的问题。我现在的公司情况也不是很,,我们部门就我一个测试,可是测试任务就是那么些,作为唯一的测试,要么就选择每次发版后手动回归,要么就是像我这样做接口测试,当然了,不管你怎么选,过程是没有领导要求或者强制的,领导只看结果,所以接口测试两分钟就搞定的事,谁会去选择手点半小时呢,哈哈,加油