新手
-
小白疑惑,使用 Py3+appium+unittest+PO 模式,如何定义多线程,目前可以多开 appium server,但不知道怎么定义每个 test.py 里面的 self.driver,恳请大牛给点思路,最好有个源码示例!! at 2018年10月17日
同求...楼主找到办法没
-
python HTMLTestRunner 中文乱码 at 2017年05月21日
self.assertIn(u"11111",ti.text,"失败了")这样写确实可以打印中文了,如下图:
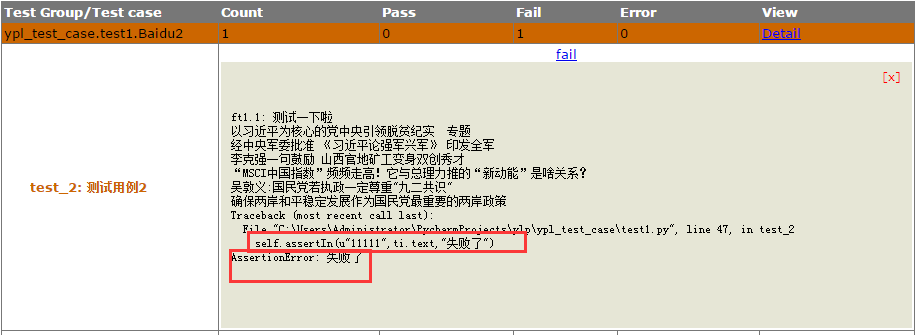
但是如果没有写附加信息时,抛出的异常全是 unicode 编码,怎么破,如下图:

-
python HTMLTestRunner 中文乱码 at 2017年05月21日
谢谢解答,用转码工具确实可以转换出中文。但是这个方法不够完美。
-
python HTMLTestRunner 中文乱码 at 2017年05月20日
我已经设置 utf-8 了。还是乱码。
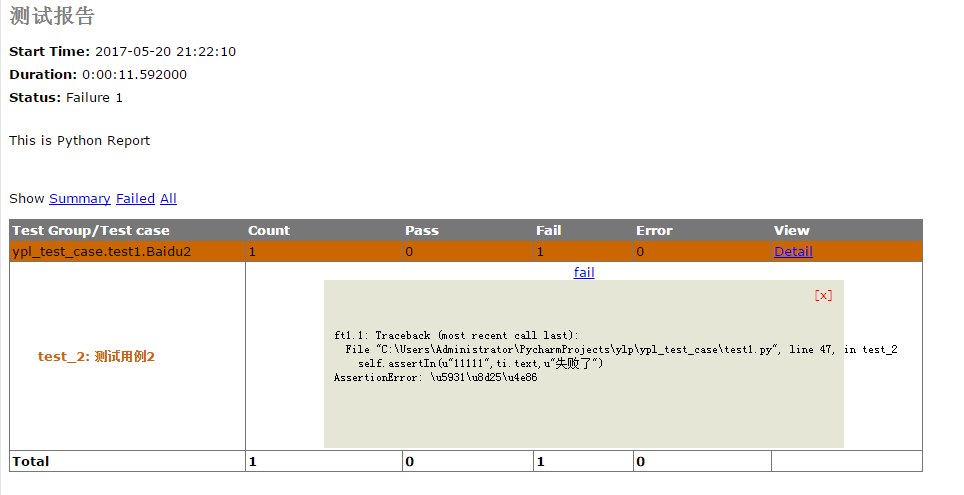
browser.find_element_by_link_text(u"新闻").click() sleep(2) ti=browser.find_element_by_xpath("html/body/div[3]/div[1]/div[1]/div/div[3]/div[1]/div/ul") self.assertIn(u"11111",ti.text,u"失败了")我的断言脚本就是进入百度首页,点击新闻,然后判断网页上的文本,断言是我估计让它失败的。但是失败后打印的信息在 HTML 报告或者 pycharm 控制台都是乱码。
-
appium 遇到用 react-navite 开发的 APP at 2016年11月30日
#11 楼 @sunkuan2007 恩,只能用 xpath 方法的相对路径了
-
appium 遇到用 react-navite 开发的 APP at 2016年11月30日
#12 楼 @tobecrazy 恩,打错了
-
appium 遇到用 react-navite 开发的 APP at 2016年11月29日
-
appium 遇到用 react-navite 开发的 APP at 2016年11月29日
#7 楼 @sunkuan2007 恩,你们有 id 属性吗,试得怎么样了
-
appium 遇到用 react-navite 开发的 APP at 2016年11月28日
-
appium 遇到用 react-navite 开发的 APP at 2016年11月28日
#2 楼 @sunkuan2007 desc 是啥?test 和 class 都试过了,不行
-
appium HTMLTestRunner 报告内容为空 at 2016年07月26日
欢迎加入测试群实时讨论交流 79887633
-
appium HTMLTestRunner 报告内容为空 at 2016年07月20日
#5 楼 @y693055797 把光标位置换一下
-
appium HTMLTestRunner 报告内容为空 at 2016年07月20日
#8 楼 @y693055797 光标放的位置不一样
-
appium HTMLTestRunner 报告内容为空 at 2016年07月12日
#5 楼 @y693055797 要保存才有的。快捷键 ctrl+s
—— 来自 TesterHome 官方 安卓客户端
-
appium HTMLTestRunner 报告内容为空 at 2016年07月11日
-
appium HTMLTestRunner 报告内容为空 at 2016年07月11日
-
求助:公司移动端目前采用 React Native 做 app,有没有好的方法去定位元素,做移动端自动化测试 at 2016年07月07日
monkeyrunner
-
感谢 UCloud 助力 TesterHome at 2016年07月07日
很好。
-
Appium inspector 获取 ios 元素属性的问题 at 2016年07月07日
看看