新手
kingween (未来的养鹅人)
第 43068 位会员 / 2019-04-29
2 篇帖子 • 14 条回帖
-
使用 selenium 访问不了公司内网的问题 at 2019年06月17日
前面的数据准备应该没有问题,就一个简单的实例化 driver 那些。。。。我打开页面之后在刷新一下页面就可以访问了。。
-
使用 selenium 访问不了公司内网的问题 at 2019年06月17日
没有开代理。我打开页面之后在刷新一下页面就可以访问了。。
-
使用 selenium 访问不了公司内网的问题 at 2019年06月17日
好像跟这个没关系,我打开页面之后在刷新一下页面就可以访问了。。
-
使用 selenium 访问不了公司内网的问题 at 2019年06月17日
并不是哦,我的可以访问的。我打开页面之后在刷新一下页面就可以访问了。。。
-
使用 selenium 访问不了公司内网的问题 at 2019年06月17日
这个问题暂时解决了。 我打开页面之后在刷新一下页面就可以访问了。。。。不知道为什么
-
使用 selenium 访问不了公司内网的问题 at 2019年06月13日
哈哈,这就不知道了
-
使用 selenium 访问不了公司内网的问题 at 2019年06月13日
就是 selenium 自动化的时候,访问一个内网网站,提示页面不存在。但是我复制 URL 出来在浏览器访问就可以。然后我用脚本访问百度也可以。
-
使用 selenium 访问不了公司内网的问题 at 2019年06月13日
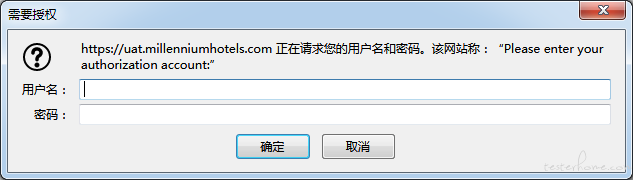
可以吧,只是需要账号密码 -
使用 selenium 访问不了公司内网的问题 at 2019年06月13日
没有错,我复制出来手动访问是可以的
-
使用 selenium 访问不了公司内网的问题 at 2019年06月13日
你的公司内网有限制外网吗
-
使用 selenium 访问不了公司内网的问题 at 2019年06月13日
你的应该是公司内网没有禁外网吧
-
请大神解答 element-UI 如何定位下拉框里的内容 at 2019年05月30日
试试用 xpath 定位 span 就行了
xpath = “//span[contains(text(),’ 宋青 ‘)]” 或者 xpath = “//span[contains(.,’ 宋青 ‘)]” -
selenium 定位问题 at 2019年05月07日
其实这个页面很多元素公用一个 class,你可以定位到酒店的图片,然后点击就行了。不行的话,你在看看这个 div 下面的其他元素,其实都有共同点的
xpath = //div[@class='cardRoomDetails-gallery']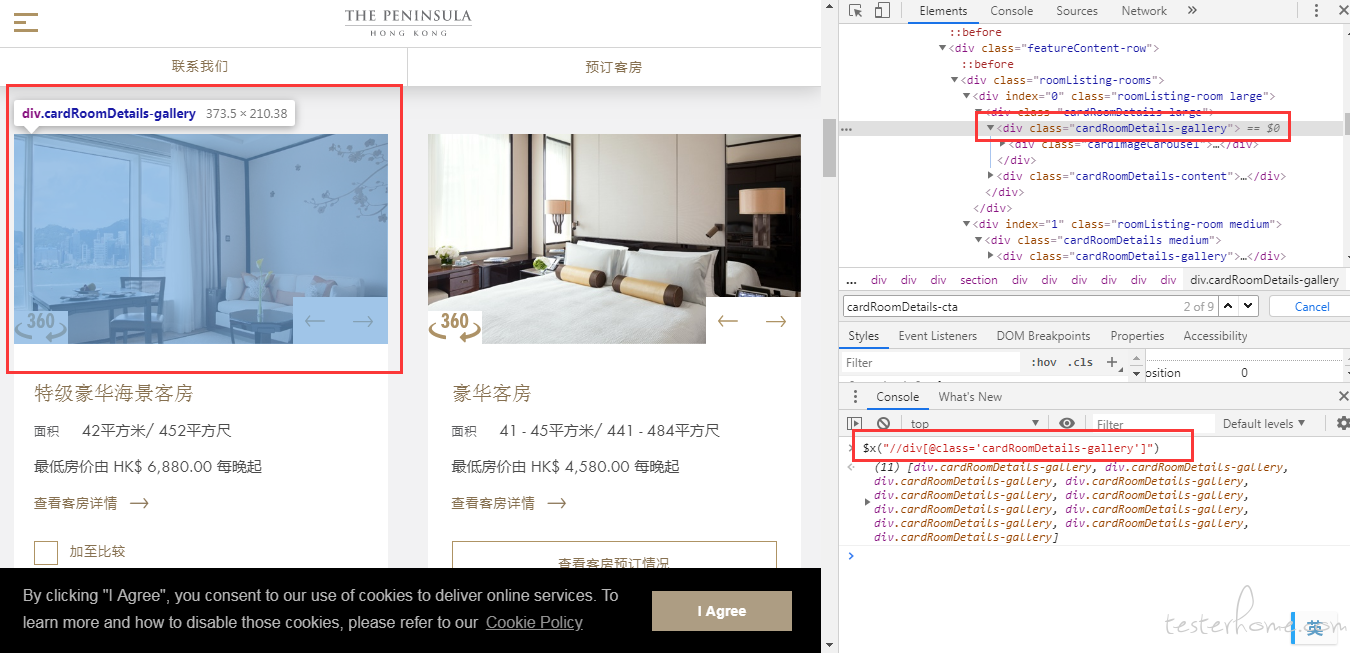
-
selenium 定位问题 at 2019年05月07日
我看了下页面,你可以用 span 标签对"查看客房详情"进行定位。
xpath = //span[contains(text(),'查看客房详情')]