-
app 包能提供一下吗,我需要这 20 块
-
Appium context 切换的问题 at July 20, 2018
发生场景结合 appium 日志能更好的解决你的问题
-
Appium context 切换的问题 at July 19, 2018
手机问题,chromedriver 版本对应,页面加载是否完成
-
Appium 微信小程序 UI 自动化 at July 18, 2018
selenium2.X 的兼容性比较好,相对于 selenium3.X 建议使用 selenium2.X,顺畅很多
-
Appium 微信小程序 UI 自动化 at July 16, 2018
自己可以多尝试看一下 appium 的运行日志,基本每个操作都会有详细日志
-
Appium 微信小程序 UI 自动化 at July 12, 2018
chromedriver 版本对应 (下载)
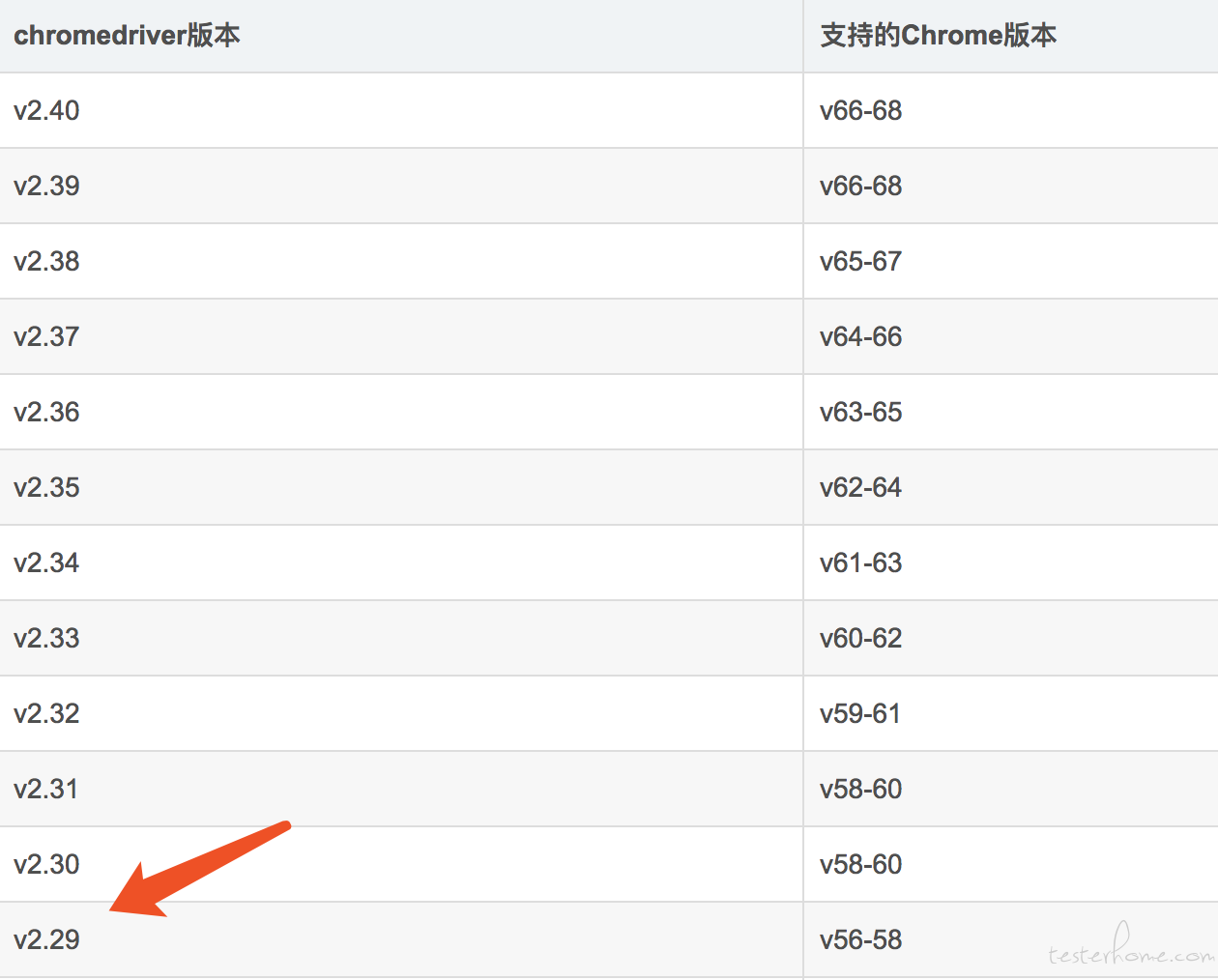
以 Chrome 57 为例,只要下载 chromedriver 2.29
mac 下放到/usr/local/bin 目录下,Windows 放到 Python 的根目录下 (Python 需设置为环境变量)
上面的针对的是 WEB 自动化,更改 appium 的 chromedriver 的话,更换/usr/local/lib/node_modules/appium/node_modules/_appium-chromedriver@4.2.0@appium-chromedriver/chromedriver/mac/下的 chromedriver 即可,名称保持不变 -
Appium 微信小程序 UI 自动化 at July 05, 2018
我之前也超时,原因是 android system Webview(57.0.2987.132) 的版本跟 chromedriver 没对应,换了 chromedriver 就好了
-
Appium 微信小程序 UI 自动化 at July 04, 2018
我看到的帖子好像都没有提及到这一点
-
Appium 微信小程序 UI 自动化 at July 04, 2018
我用的是小米 5S,一直不行的,看错误日志应该可以看出来,实在搞不定也可以在社区发帖,里面有很多大神
-
测试开发之路 -- 每一次发布都是一次成长 at July 02, 2018
总感觉有这种拼尽全力,记忆深刻的事情挺好的
-
Jmeter+ant+Jenkins 接口自动化框架完整版 at May 16, 2018
1·resource 目录下有 a,b,c 三个 jmeter 工程,你想过怎么控制哪个要执行哪个先执行
由 Ant 所在目录 lib 子目录下 ant-jmeter-1.1.1.jar 的"org.programmerplanet.ant.taskdefs.jmeter.JMeterTask"这个类控制
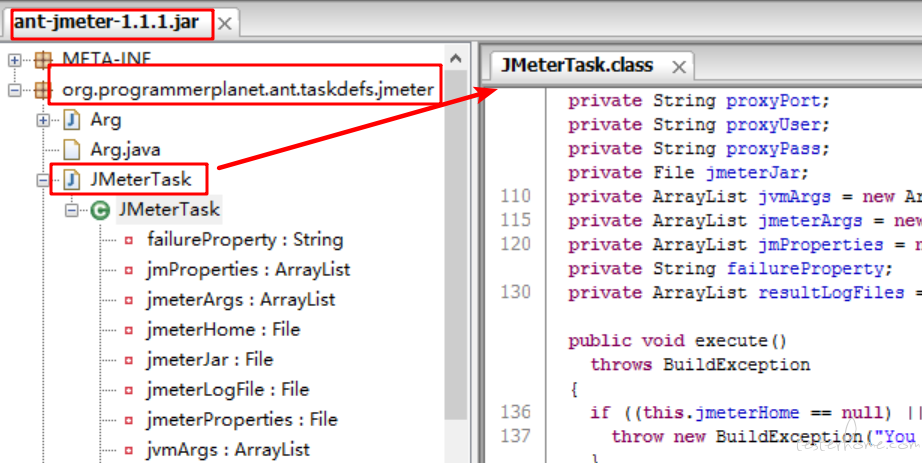
你也可以从 ant 的 运行日志中查看 a,b,c 的执行顺序,优先级应该是 a>b>c,想自己控制可以改 jar 包代码
2·在 jmeter 中使用 mysql 进行参数化,你的 jdbc 的 jar 路径是绝对路径
可以在你本机 jmeter 和 jenkins 使用的 jmeter 中分别将 jdbc 的 jar 包路径设置成全局变量在jmeter.properties中,取的话都用${mysqlJar}
如本机 jmeter 的jmeter.properties新增行mysqlJar=D:/benji/mysql.jar,jenkins 使用的 jmeter 的 jmeter.properties 新增行mysqlJar=D:/jenkins/mysql.jar
3·jenkins 中用命令行执行三个工程,内存消耗大
jmeter 的 PerfMon Metrics Collector 插件可以监控 jmeter 运行时本机的 CPU 内存等性能指标,内存消耗大可以考虑用 jenkins 远程运行 jmeter 脚本,别用搭建 jenkins 的机器运行 -
Jmeter+ant+Jenkins 接口自动化框架完整版 at May 11, 2018
单个是没错的,总体的我就是把单个相加除以个数,所以得到 27.842/s,但是 jmeter 的值 6.7/s 差别真的有点大,肯定不是取的平均值吧,因为没有几个比 6.7/s 小的,我是按照自己的理解算的,你是怎么理解 jmeter 中 Throughout 这个值的
-
Jmeter+ant+Jenkins 接口自动化框架完整版 at May 10, 2018
首先感谢仔细阅读
jtl 文件在 jmeter 的聚合报告中打开,跟我的报告对比图如下:
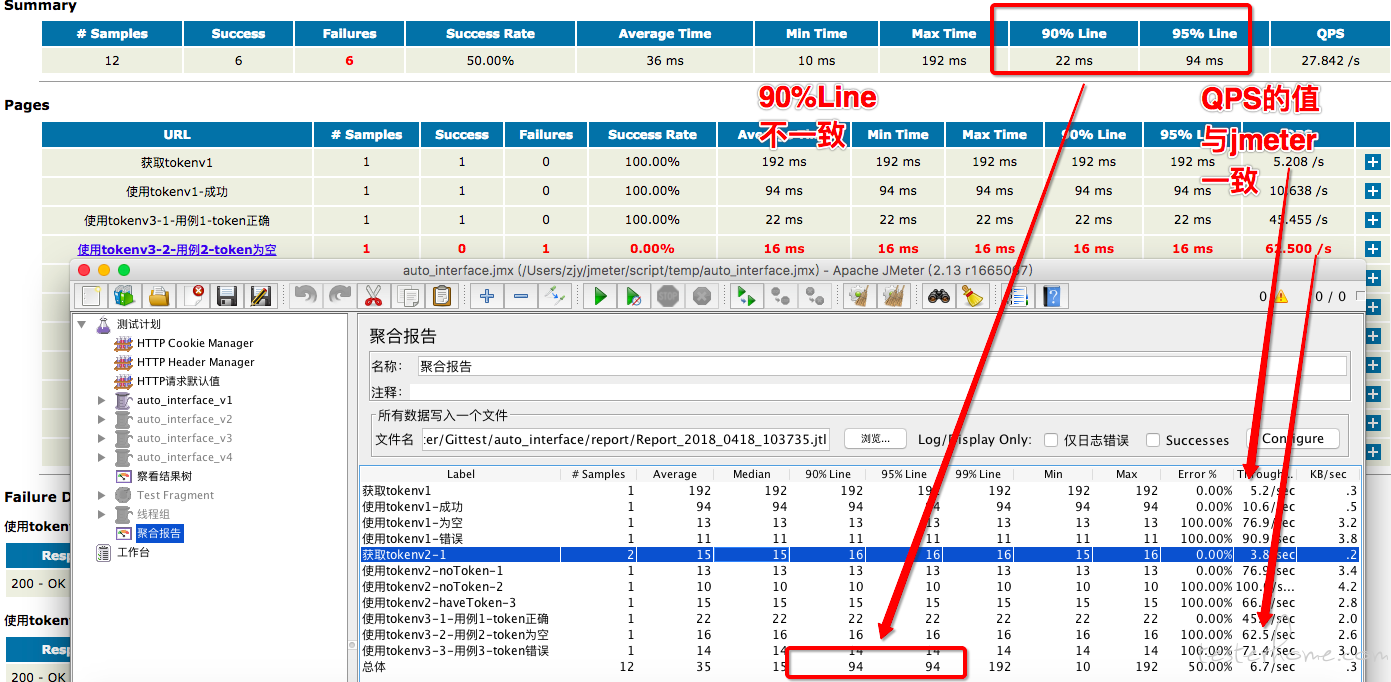
看得出 QPS 的值跟 jmeter 的是一致的,其中 90%Line 我的为 22ms,jmeter 为 94ms,95%Line 都为 94ms
这里面一个 12 个接口,响应时间从小到大最后 3 个是 22ms,94ms,192ms(这个从报告看得出,因为是按照时间倒序排的)
计算 90%line 是用 12*90%=10.8,我是向下取整得到 10,所以取的是 22ms。
计算 95%line 是用 12*95%=11.4,我是向下取整得到 11,所以取的是 94ms。
但 jmeter 都是 94ms,可能是对 10.8 和 11.4 四舍五入,都得到 11,所以取的都是 94ms。我的关键逻辑是这样的,根据网上的修改后的:
当只有一个数据,向上取整,当有多个数据时向下取整,报告会好看一点,但数据量大的时候,跟 jmeter 应该无差别,或者用 round 函数对数据四舍五入也可以,问题是自己知道怎么算的就好。<!-- -95% line time --> <xsl:template name="lineTime95"> <xsl:param name="nodes" select="/.." /> <xsl:choose> <xsl:when test="not($nodes)">NaN</xsl:when> <xsl:otherwise> <xsl:for-each select="$nodes"> <xsl:sort data-type="number" /> <!-- last() 返回当前上下文中的最后一个节点位置数 --> <!-- ceiling(number) 返回大于number的最小整数 --> <!-- floor(number) 返回不大于number的最大整数 --> <xsl:choose> <!-- 当只有一个节点时,向上取整 --> <xsl:when test="last() = 1"> <xsl:if test="position() = ceiling(last()*0.95)"> <xsl:value-of select="number(.)" /> </xsl:if> </xsl:when> <xsl:otherwise> <!-- 当有多个节点时,向下取整 --> <xsl:if test="position() = floor(last()*0.95)"> <xsl:value-of select="number(.)" /> </xsl:if> </xsl:otherwise> </xsl:choose> </xsl:for-each> </xsl:otherwise> </xsl:choose> </xsl:template> -
在 testerhome 发话题,代码怎么配色的 at May 09, 2018
我的锅

-
在 testerhome 发话题,代码怎么配色的 at May 09, 2018
-
在 testerhome 发话题,代码怎么配色的 at May 09, 2018
知道了,感谢🙏
-
你是不是觉得特腻歪 at May 07, 2018
自动化可以减少人们的重复冗余工作,提高测试的技术和参与感,没有什么自动化好不好,它只是一种测试工具,测试方案,最终效果还是由实施的人决定的。
-
请教大佬,selenium 如果多线程驱动多个浏览器驱动 at April 23, 2018
python 的多线程和多进程编程了解一下,然后你就知道了
-
Jmeter 接口自动化 - 脚本数据分离实例 at April 19, 2018
能完全看懂的,应该不是菜鸟级别的,菜鸟一般只会谦虚的说基本都看懂了,testerhome 需要你这种社会人

-
Jmeter 接口自动化 - 脚本数据分离实例 at April 19, 2018
其实写到后面,还有很多坑,只是现在还没有体现出来,后面理清思路再继续写
-
Jmeter 接口自动化 - 脚本数据分离实例 at April 19, 2018
有层次感会好理解点,并且记忆深刻些
-
Jmeter 之你可能只知其一 (一) at April 12, 2018
你设置 Dummy Sampler 的 Response Data 为这个试试,不知道你是不是复制之后的格式有问题:
{"resultCode":"1000","resultMsg":"success","userdic":{"Ali":"Moubao"},"userlist":[{"firstName":"Jiezai","lastName":"Grizz","id":6},{"firstName":"Ben","lastName":"Rose","id":8}]} -
Jmeter 之你可能只知其一 (一) at April 12, 2018
Jmeter 的扩展插件,JMeterPlugins-Extras.jar和JMeterPlugins-Standard.jar(放到 jmeter/lib/ext 目录下即可):

可自行下载,如果需要的也可以联系我,文件目前上传不了,所以没放
-
Jmeter 之你可能只知其一 (一) at April 12, 2018
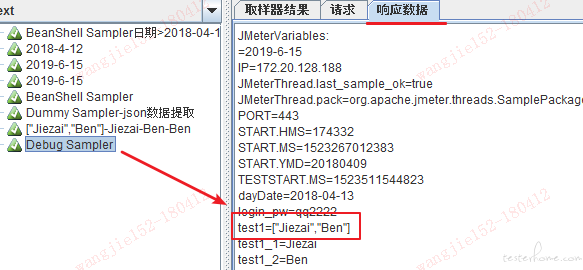
两种方法,以 json path 表达式 $..userlist.firstName,提取后变量值为 test1 为例:
1、引用,调试的时候可以在 sampler 的名称中 ${test1}引用,然后去查看结果树看 sampler 的名称
或者在接口的请求中调用也可以,原理是一样的。

2、添加 Debug Sampler,然后去查看结果树看 Debug Sampler 的响应数据
-
Jmeter 接口测试-请求 Headers 与传参方式 at April 12, 2018
跟大佬们一起学习前进