-
ui 自动化测试如何提高其稳定性? at 2021年11月04日
UI 自动化的稳定主要是要有可靠的同步机制,不然异步加载很影响元素的操作导致失败。好好分析页面中的加载顺序和关联元素,在适当的延时和运行速度间权衡,通过率基本上就可以接受了~
-
selenium 操作已打开的浏览器 at 2021年09月24日
这是 selenium3 还是 selenium4 了?
-
UI 自动化的页面对象管理神器 PO-Manager at 2021年08月04日
有问题也可以加到这个群里来提问哈,
-
UI 自动化的页面对象管理神器 PO-Manager at 2021年08月04日
chromedriver 的路径需要加到环境变量 PATH 里,然后通过 cmd 里执行下 chromedriver 确定能找到
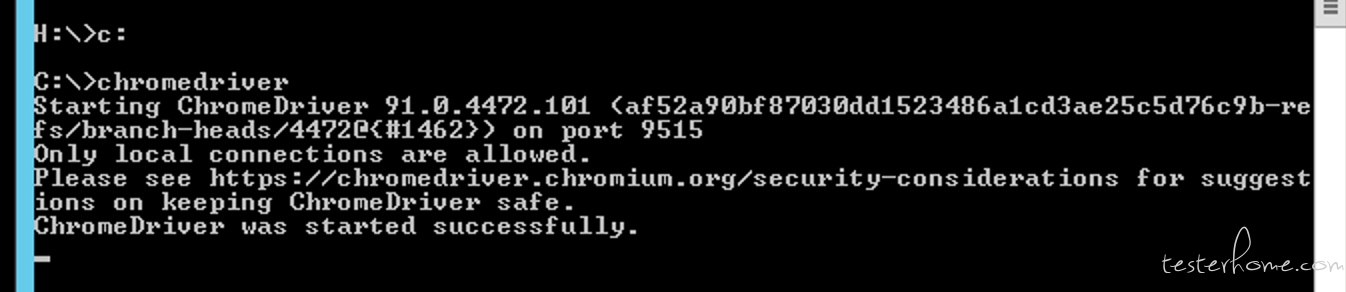 , 并且确保版本跟 chrome 匹配
, 并且确保版本跟 chrome 匹配 -
UI 自动化的页面对象管理神器 PO-Manager at 2021年07月28日
这个你倒是可以选择只加载一个 extension(主要的元素对象生成逻辑在这里)
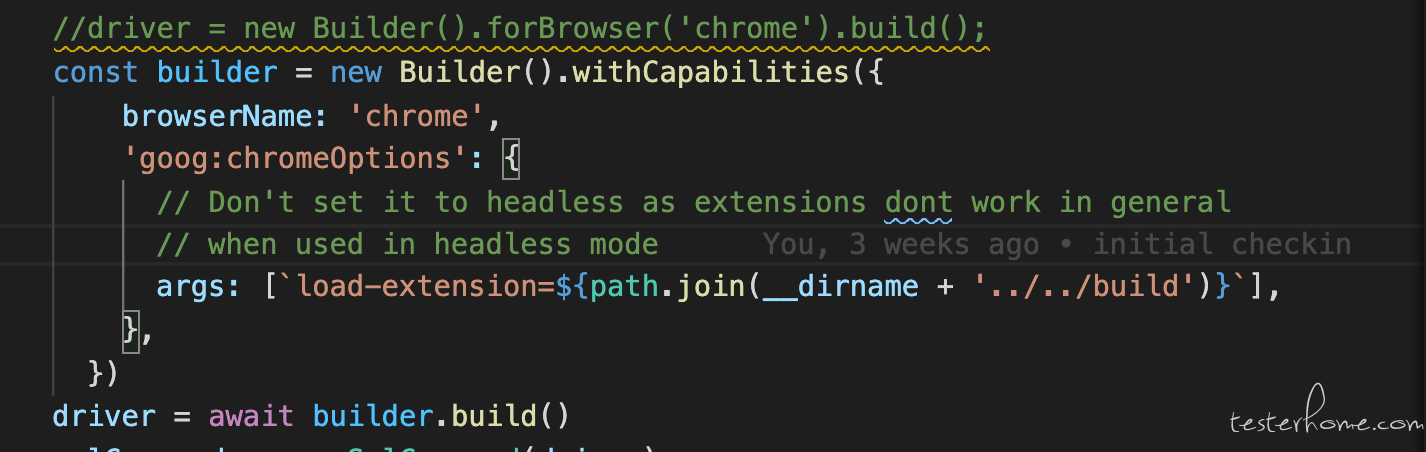
然后调用这三个 js 方法就行,改成 python 应该不难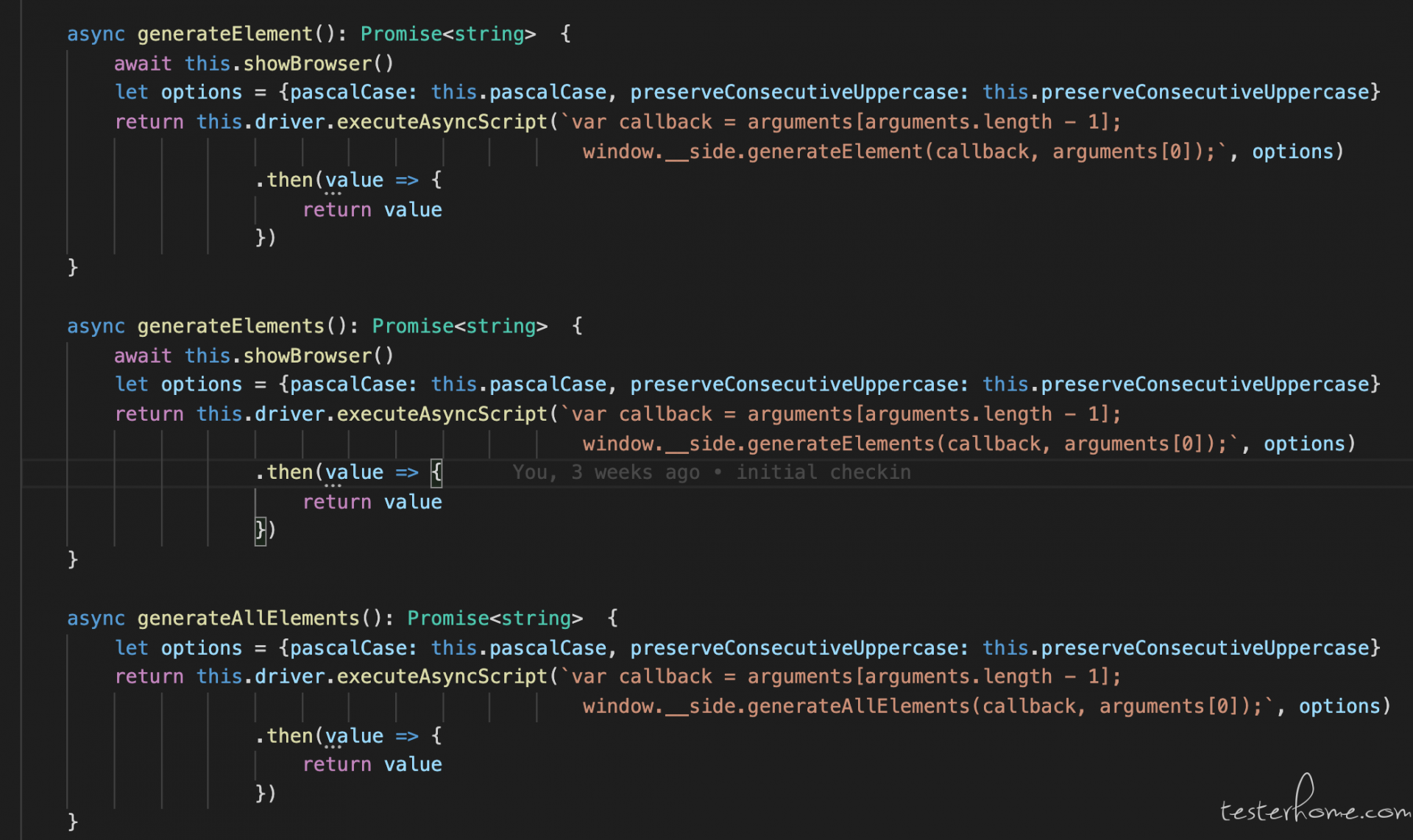
返回出来的 value 是已经按这种格式生成的元素集:
{
"新闻 Link": {
"type": "linkText",
"locator": "新闻"
},
"Hao123Link": {
"type": "linkText",
"locator": "hao123"
},
"地图 Link": {
"type": "linkText",
"locator": "地图"
},
"直播 Link": {
"type": "linkText",
"locator": "直播"
},
"2021Baidu": {
"type": "xpath",
"locator": "(//div[@id='bottom_layer']/div/p[9]/span)[1]"
}
} -
UI 自动化的页面对象管理神器 PO-Manager at 2021年07月26日
你说的没错,其实这个后端就用了部分 selenium IDE 的代码,主要是想方便页面对象的管理和维护,只要页面对象库抽象成这种 json 格式,那这个工具就可以匹配任何框架了。
-
UI 自动化的页面对象管理神器 PO-Manager at 2021年07月26日
谢谢
-
UI 自动化的页面对象管理神器 PO-Manager at 2021年07月23日
目前的算法生成的定位已经比大部分初学者写的好了,可以既拿既用,减轻很多的工作量,如果要提升部分定位的稳定性,进行少量维护即可。
-
UI 自动化的页面对象管理神器 PO-Manager at 2021年07月23日
可以生成基于父子结构的 xpath 和 css, xpath 轴之类的用法太复杂没法自动生成,主要是没法判断是不是最好的定位。
-
Seldom 2.0 - 让接口自动化测试更简单 at 2021年06月17日
直接撸代码的,用代码感觉更灵活一点吧,熟悉了的话。一些公用的也可以自己根据业务封装起来。
-
Seldom 2.0 - 让接口自动化测试更简单 at 2021年06月17日
API 测试的话也推荐下用 jsonpath 来处理返回数据,可以减少太多遍历操作了。
https://cloud.tencent.com/developer/article/1511637 -
Seldom 2.0 - 让接口自动化测试更简单 at 2021年06月17日
我们一般的做法是对查询订单的 sql 做一层封装,测试用例可以根据不同的条件来调用,比如订单种类有 pending, payed, itemCount 是多少之类的那我们就可以实行动态查找,getOrder(pending|ItemCount>3) 这种来获取待付款并且商品数量大于 3 个的订单,进行后续的验证,这样可以对用例进行解耦,覆盖率也容易上去。当然对于怎么封装 sql,这个得根据业务来了。