-
求借一个关于 python 上正则表达式的问题 at 2019年12月19日
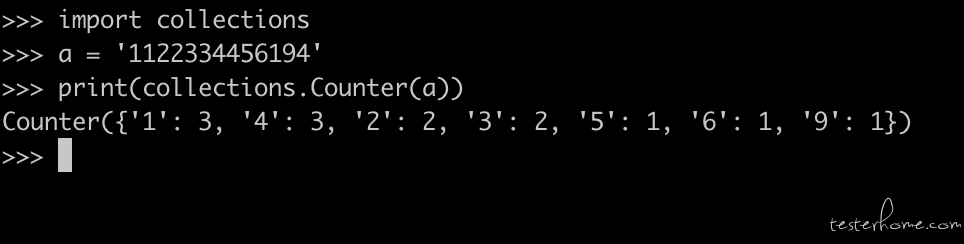
用 collections 库就完事了 -
关于性能测试平台的工具选型 at 2019年10月14日
locust 得关注压测引擎,原生 requests 还是有瓶颈,要么考虑 pypy 执行提升性能,要么可以改用 go 来做 client 端
-
最近在学习接口测试,使用 pycharm 运行用例时报错" AttributeError: 'TestCaseFunction' object has no attribute 'get_closest_marker' ",求指点 at 2019年08月26日
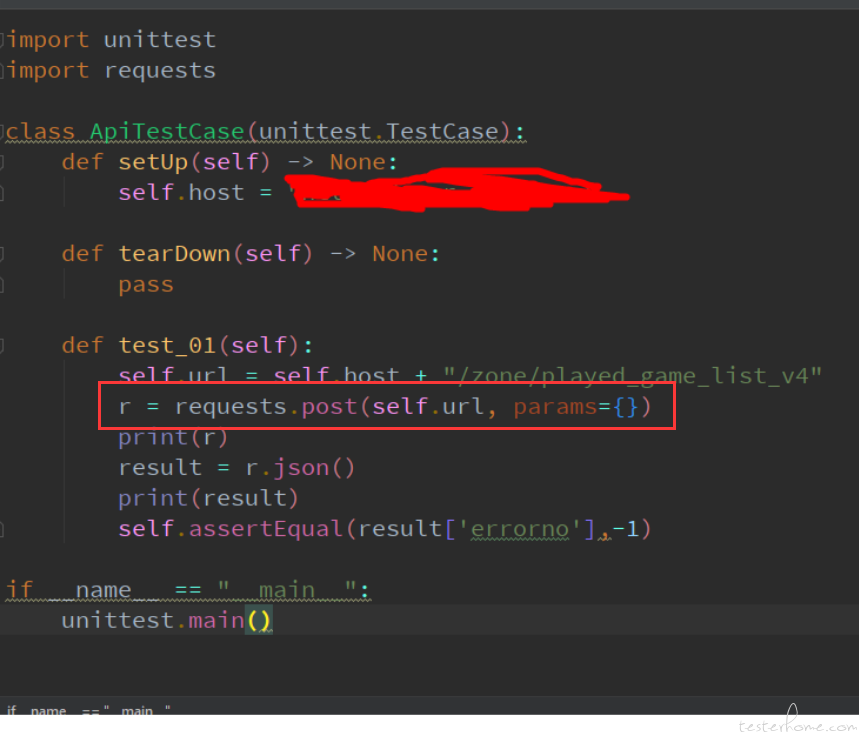
建议楼主多看看 requests 的文档,post 请求里面是 data,不是 params,你如果是请求获取 url 的参数的话应该是 get 请求吧,试试换这个请求方式,另外可以对比 postman 上面的请求结果,是否要传 header 之类的 -
在 windows 环境下用什么做定时任务会比较好点? at 2019年08月14日
你得先了解那些库怎么实现定时的,后端数据要处理成那些库支持的数据格式,多看文档
-
在 windows 环境下用什么做定时任务会比较好点? at 2019年08月14日
celery 有自带定时器功能,celery beat 了解下,另外 APScheduler 也可以做定时器,当前 Jenkins 也 ok
-
接口自动化测试,python 里一个隐藏很深的坑 at 2019年08月02日
引用https://stackoverflow.com/questions/22513445/python-handles-long-ints-differently-on-windows-and-unix 上面的回答
python 的 int 是取 C long type,在 windows 里,定义 C long type 就是 32 位长度,而在 Linux 则取 C long type 的 64 位,所以不一样,也就是说,有一些 windows 和 linux 上的差异基本都是 c 库在不同平台的表现差异。 -
UI 自动化到底要不要用 Page Object 模式,以及 yaml 数据驱动? at 2019年07月12日
我觉得 po 模式比较注重可复用性吧,多人写脚本的时候,重复的部分都可以提取做公共模块,新人接手的时候上手也比较快
-
抠图测试 at 2019年06月19日
opencv 可以用来抠图
-
python3 字典如何进行随机数排序? at 2019年05月27日
要某个值就 sorted(data.values(), key=lambda x:x[0]) 这样就可以了吧
要字典就 dict(sorted(data.items(), key=lambda x:x[0])),可能还有更快的 -
接口自动化平台,请问接口里有上传的文件,是怎么处理的 at 2019年04月09日
像我是自己开发的接口平台就写个上传接口,让用户把本地文件上传到服务器上面再处理了