什么是目标检测
用一张图来表达:

这是我周末带老婆孩子去体育场玩时拍下来的照片。 我使用这张照片输入到模型中,希望模型可以识别出图片中的人类并画出人类所在位置的长方形的框。 而这就是目标检测.
目标检测的流程。
本质上目标检测是一个分类 + 回归的复合问题。 这里再解释一下什么是分类和回归。 在人工智能的监督学习类目中,基本上所有模型都逃不开二分类,多分类和回归这 3 种类型。
- 二分类:比如一张图片,告诉用户这个图片中有没有人类。回答要么是有,要么是没有。 只有两个答案,所以叫二分类。 在后台,模型其实并不会直接告诉分类结果,而是输出这张图片有人类的概率是多少。 用户需要自己设定一个概率阈值来进行判定。 比如用户设定的阈值是 0.8. 那么只要模型输出的概率大于 0.8 就会被分类成有人类的结果。
- 多分类:多分类对比二分类其实就是有多个分类,用的算法也都一样,只不过算法最后用的激活函数从 sigmod 换成了 softmax。 在多分类里,模型会输出每个分类的概率,比如图片里有人的概率是 0.5,有猫的概率是 0.3,有狗的概率是 0.2 。 同样由用户自己设定阈值来进行判定。
- 回归:回归与分类不同, 模型输出的是一个具体数值,比如模型预测房价,股价,两地之间的通勤时间等等。 而在我们的目标检测场景中, 回归主要用来识别目标物体(比如人类)的坐标。
所以在目标检测中,模型实际上会通过一些算法把图片分割成很多个小块, 然后分别对这些块进行分类判断(区域中含有目标的概率)以及识别这个目标的坐标地址(中心点坐标,长宽。或者直接 4 个点的坐标)。
如何评估目标检测的效果
针对一个图片,我们需要事先进行标注,比如识别人类,猫,狗这 3 个目标的场景中,图片中每个目标的类别和坐标都要事先标注好。 这样才能跟模型输出的结果进行对比,以此来评估模型识别的准确程度。
AI 模型的效果测试,都是基于统计学的,输入大量事先已经标注好答案的数据,与模型输出的数据进行对比,从而在大量的数据下评估模型的准确程度
IOU
IOU 评估的是图片中目标预期的坐标和模型识别出的坐标的重叠程度,以此来判断模型识别的坐标是否准确。 它的评估代码如下:
# IoU是目标检测中常用的一种重叠度量,用于衡量检测框和真实标注框之间的重叠程度。IoU值越大,表示检测结果越准确。它的达标标准取决于具体的应用场景和需求。
# 在目标检测任务中,常用的IoU阈值为0.5或0.7,即当检测框与真实标注框的IoU值大于等于0.5或0.7时,认为检测结果正确。在一些特定的应用场景中,IoU阈值可能会更高或更低
# 需要注意的是,IoU值并不是唯一的评估指标,还需要考虑精度、召回率、F1值、AP等指标。在实际应用中,需要根据具体的需求选择合适的评估指标和阈值。
def compute_iou(box1, box2):
# 计算两个矩形框的面积
area1 = (box1[2] - box1[0] + 1) * (box1[3] - box1[1] + 1)
area2 = (box2[2] - box2[0] + 1) * (box2[3] - box2[1] + 1)
# 计算交集的坐标范围
x1 = max(box1[0], box2[0])
y1 = max(box1[1], box2[1])
x2 = min(box1[2], box2[2])
y2 = min(box1[3], box2[3])
# 计算交集的面积
inter_area = max(0, x2 - x1 + 1) * max(0, y2 - y1 + 1)
# 计算并集的面积
union_area = area1 + area2 - inter_area
# 计算IoU值
iou = inter_area / union_area
return iou
box1 = [50, 50, 150, 150] # 左上角坐标为(50, 50),右下角坐标为(150, 150)
box2 = [100, 100, 200, 200] # 左上角坐标为(100, 100),右下角坐标为(200, 200)
# 计算两个矩形框之间的IoU值
iou = compute_iou(box1, box2)
# 输出结果
print('IoU:', iou)
一些细节我们都写在了上面代码中的注释里。
召回/精准
召回和精准是分类模型中最主要的评估指标,在之前的文章中已经详细介绍过,这里我再简单介绍一下。
举一个例子,假设我们有一个预测癌症的场景,健康的人有 99 个 (y=0),得癌症的病人有 1 个 (y=1)。我们用一个特别糟糕的模型,永远都输出 y=0,就是让所有的病人都是健康的。这个时候我们的 “准确率” accuracy=99%,判断对了 99 个,判断错了 1 个,但是很明显地这个模型相当糟糕,在很多模型评估场景中,准确率是不足以表达模型真是的效果的,这是因为在真实世界中,正负样本的比例本就是十分悬殊的。因此需要一种很好的评测方法,来把这些 “作弊的” 模型给揪出来。
- 精准率:precision:所有被查出来得了癌症的人中,有多少个是真的癌症病人。公式是 TP/TP+FP
- 召回率:recall:所有得了癌症的病人中,有多少个被查出来得癌症。公式是:TP/TP+FN。 意思是真正类在所有正样本中的比率,也就是真正类率 (TPR)。
召回和精准理解起来可能比较绕,我多解释一下,我们说要统计召回率,因为我们要知道所有得了癌症中的人中,我们预测出来多少。因为预测癌症是我们这个模型的主要目的, 我们希望的是所有得了癌症的人都被查出来。不能说得了癌症的我预测说是健康的,这样耽误人家的病情是不行的。 但同时我们也要统计精准率, 为什么呢, 假如我们为了追求召回率,我又输入一个特别糟糕的模型,永远判断你是得了癌症的,这样真正得了癌症的患者肯定不会漏掉了。但明显这也是不行的对吧, 人家明明是健康的你硬说人家得了癌症,结果人家回去悲愤欲绝,生无可恋,自杀了。或者回去以后散尽家财,出家为僧。结果你后来跟人说我们误诊了, 那人家砍死你的心都有。 所以在统计召回的同时我们也要加入精准率, 计算所有被查出来得了癌症的人中,有多少是真的癌症病人。 说到这大家可能已经看出来召回和精准在某称程度下是互斥的, 因为他们追求的是几乎相反的目标。 有些时候召回高了,精准就会低。精准高了召回会变低。 所以这时候就要根据我们的业务重心来选择到底选择召回高的模型还是精准高的模型。 有些业务比较看重召回,有些业务比较看重精准。 当然也有两样都很看重的业务,就例如我们说的这个预测癌症的例子。或者说银行的反欺诈场景。 反欺诈追求高召回率,不能让真正的欺诈场景漏过去,在一定程度上也注重精准率,不能随便三天两头的判断错误把用户的卡给冻结了对吧,来这么几次用户就该换银行了。
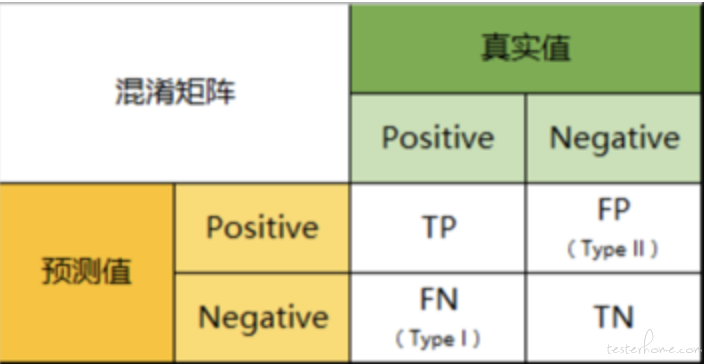
而上面计算指标的公式中 TP/FP 这些则是混淆矩阵的概念。 那什么是混淆矩阵呢。
混淆矩阵是一个用于描述分类模型性能的矩阵,它显示了模型对于每个类别的预测结果与实际结果的对比情况。
以分类模型中最简单的二分类为例,对于这种问题,我们的模型最终需要判断样本的结果是 0 还是 1,或者说是 positive 还是 negative。
我们通过样本的采集,能够直接知道真实情况下,哪些数据结果是 positive,哪些结果是 negative。同时,我们通过用样本数据跑出分类型模型的结果,也可以知道模型认为这些数据哪些是 positive,哪些是 negative。
因此,我们就能得到这样四个基础指标,我称他们是一级指标(最底层的):
真实值是positive,模型认为是positive的数量(True Positive=TP)
真实值是positive,模型认为是negative的数量(False Negative=FN)
真实值是negative,模型认为是positive的数量(False Positive=FP)
真实值是negative,模型认为是negative的数量(True Negative=TN)
将这四个指标一起呈现在表格中,就能得到一个矩阵,我们称它为混淆矩阵(Confusion Matrix)
一个统计召回和精准的测试脚本
下面我使用 yolo 模型来做一个实战演示,yolo 是目标检测领域最出名的一个开源模型之一。用户可以在网络上随意下载对应的模型使用。 实际上我也用这个模型做计算机是视觉的数据挖掘工作(这个后面再讲。)
yolo 是一个 80 分类的模型,其中 class_id 为 0 的是人类。 我就用这个模型来写一个测试 yolo 识别人类的实战测试脚本。 这里我主要统计召回和精准。 具体的实现细节都写在了代码注释中。
PS:下面代码中最后注释的部分是用开源的库来计算混淆矩阵,召回和精准。
import cv2
import numpy as np
# yolov3下载地址:
# 网络结构文件:https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg
# 模型(权重)文件:https://pjreddie.com/media/files/yolov3.weights
# 80个类别标签的文本文件:https://raw.githubusercontent.com/pjreddie/darknet/master/data/coco.names
net = cv2.dnn.readNet('yolov3.weights', 'yolov3.cfg')
classes = []
datas = []
# 读取标注文件
with open('static/pic_cls/labels.txt', 'r') as f:
for line in f:
datas.append(list(line.strip('\n').split(' ')))
print(datas)
# 定义混淆矩阵
TP = 0
FN = 0
FP = 0
TN = 0
# 遍历数据,把数据输给模型进行识别,并统计混淆矩阵
for image in datas:
path = image[0]
label_y = int(image[1])
frame = cv2.imread(path)
height, width, _ = frame.shape
# 构建输入图像
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416), swapRB=True, crop=False)
# 设置输入层和输出层
net.setInput(blob)
output_layers = net.getUnconnectedOutLayersNames()
# 前向传播,模型推理
outputs = net.forward(output_layers)
# 解析输出
boxes = []
confidences = []
class_ids = []
for output in outputs:
for detection in output:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5 and class_id == 0: # 只检测人类,在yolo的定义中class_id为0的是人类目标(yolo是80分类的模型). 阈值设定为0.5,只有大于0.5的才认为是有人类的。
# 计算每个目标的坐标, 后面可以用这些坐标做IOU指标的计算
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
# 非极大值抑制
indices = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
y = 0
# # 判断是否存在人类
if len(boxes) > 0:
y = 1
print('There is a human in the image.')
else:
y = 0
print('There is no human in the image.')
if label_y == 1 and y == 1:
TP += 1
elif label_y == 1 and y == 0:
FN += 1
elif label_y == 0 and y == 1:
FP += 1
elif label_y == 0 and y == 0:
TN += 1
recall = TP / (TP + FN)
precision = TP / (TP + FP)
print("recall: " + str(recall))
print("precision: " + str(precision))
#
# from sklearn.metrics import confusion_matrix
# import pandas as pd
#
# # 创建一个字典,其中包含'label'和'answer'的键,以及相应的数据
# data = {
# 'label': ['fig_other', 'fig_data', 'fig_mind', 'fig_proc','fig_other', 'fig_data', 'fig_mind', 'fig_proc', 'fig_other'], # 示例标签
# 'answer': ['fig_data', 'fig_data', 'fig_other', 'fig_proc','fig_proc', 'fig_proc', 'fig_mind', 'fig_proc', 'fig_other'] # 示例答案
# }
#
# # 使用字典创建DataFrame
# df = pd.DataFrame(data)
#
#
# # 计算混淆矩阵
# cm = confusion_matrix(df['label'], df['answer'],
# labels=['fig_other', 'fig_data', 'fig_mind', 'fig_proc'])
#
# # 定义分类标签
# labels = ['fig_other', 'fig_data', 'fig_mind', 'fig_proc']
#
# # 计算每个分类的召回率和精确率
# recall = {}
# precision = {}
# for i, label in enumerate(labels):
# recall[label] = round(cm[i, i] / cm[:, i].sum(), 4)
# precision[label] = round(cm[i, i] / cm[i, :].sum(), 4)
#
# # 找出每个分类的badcase
# badcases = {}
# for i, label in enumerate(labels):
# badcases[label] = df[(df['label'] == label) & (df['answer'] != label)]
#
# print(recall)
# print(precision)
# print('下面是badcase')
# for key, value in badcases.items():
# print(key)
# print(value)
欢迎加入我的星球
最后再推荐一下自己的星球,里面有大量的 AI 场景的测试资料和教程,我也会在星球中定期直播: