
这是鼎叔的第一百零六篇原创文章。行业大牛和刚毕业的小白,都可以进来聊聊。
欢迎关注本专栏和微信公众号《敏捷测试转型》,星标收藏,大量原创思考文章陆续推出。本人新书《无测试组织 - 测试团队的敏捷转型》已出版(机械工业出版社),文末有链接。
通过机器学习的基础知识掌握和简单应用,我们可以逐步理解其算法思路和传统编程解法的不同。传统编程,通过预先设定好的路径执行,得到计算结果。AI 算法编程,是基于训练模型,让程序有多种可能的执行路径,从中找到最合适的执行路径,让训练结果达到指定要求(即误差足够小)。
相关文章 聊聊经典机器学习入门,聊聊 AI 学习入门 - 数学和信息论。
ANN 与脑科学
这些年人工智能新理论高速发展,热门的 AI 技术应用不断引起轰动。我们要针对 AI 新技术进一步学习,可以先从其爆发原点——人工神经网络(Artificial Neural Network,ANN)知识开始理解。
人脑令人叹服的复杂结构和神奇能力让大型计算机在某些方面无法比拟,尤其是模式识别等能力。通过对人脑的仿真研究,计算机学界找到了类似神经网络的对大量数据进行智能处理的思路,进而在很多领域攻城略地。神经网络拥有海量的神经元(神经细胞),类似一个极其庞大的并行分布式计算结构,单个神经细胞通过轴突和树突互相传递信息,传递的化学信号让细胞兴奋或抑制,类似二进制的 1 和 0。树突就是输入,轴突就是输出,突触就是权重。
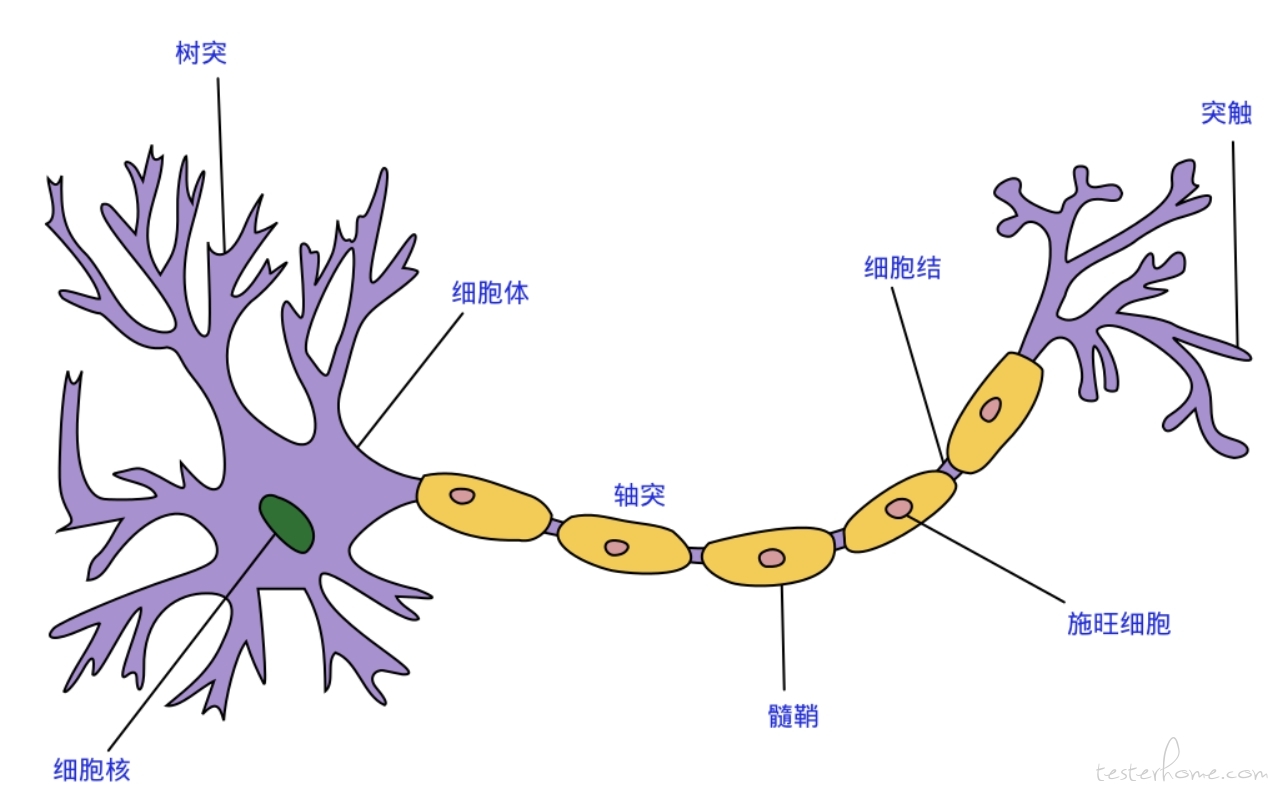
这些信号经过复杂的迭代计算,不断调整输入数据,最终产生一个确定的结果,这本质上就是一种高效的无监督学习,在非线性分类中具备很大优势,尤其在多媒体领域。
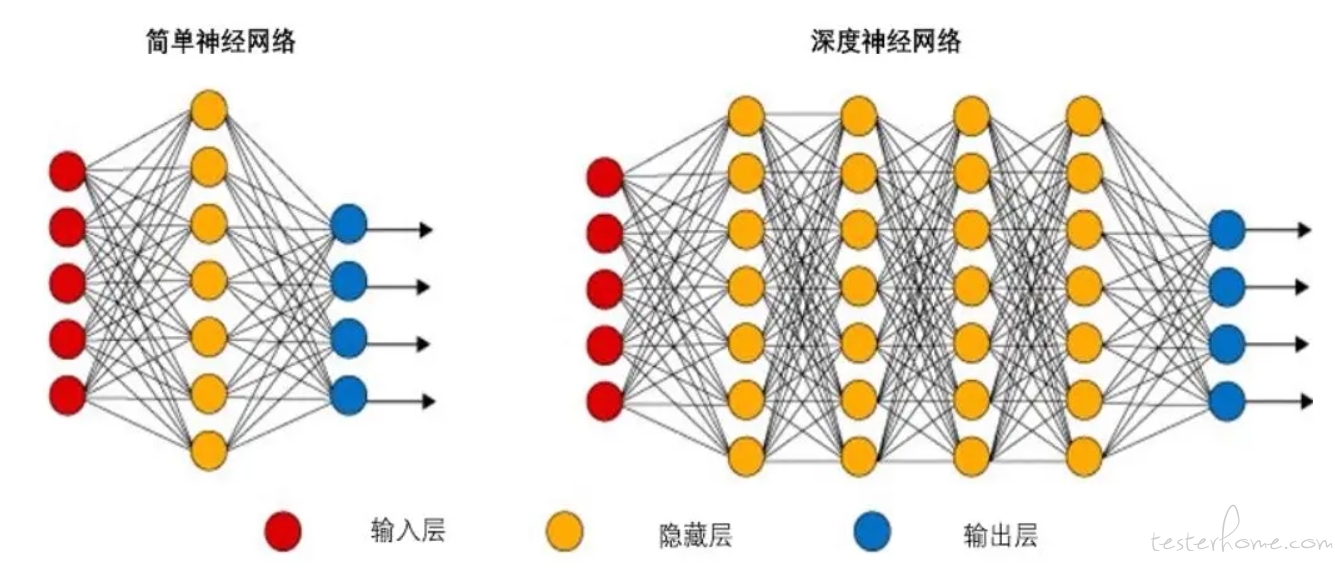
通过这些年的发展,神经网络模型也逐步衍生出很多著名的变种,经历了三个阶段:单层感知器,多层感知器,深度学习。
下面简单介绍一下。
感知器网络
人工训练神经网络首先从单个神经元开始训练。神经元由线性函数和非线性的激励函数组成。设置好初始化权重,利用类似 SVN 的逻辑回归进行分类判断,当遇到线性不可分的情形,神经网络可以用比 SVN 更强的方式去解决:包括新增的输入变量,更多的中间计算网络层次,以及最终的输出层。
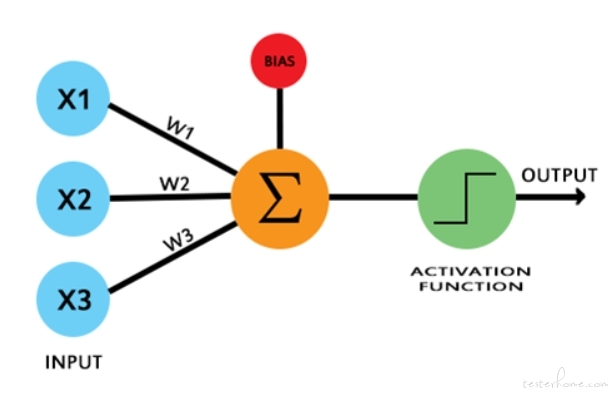
感知器模型把神经元模型的激活函数作为符号函数,但这不能解决非线性问题(如异或问题)。
BP 神经网络
是按误差逆传播算法训练的多层前馈网络。它分为输入层,隐含层和输出层,后面两个是参与计算和调整权重的节点,我们希望找到一种方法,让设置好的各种权值匹配尽可能多的训练样本分类情况,让误差尽量小。整个训练过程通常采用步长试探方法,类似梯度下降法。梯度下降就是沿着最陡峭的方向寻找损失函数的最小值(通过不断调整各个待定系数、正则化和丢弃部分节点等手段),快速收敛,避免过拟合。注意,需要选择合适的激励函数才能防止梯度消失或梯度爆炸。
1986 年,多层感知器网络引入了反向传播算法,但是也面临梯度消失的问题,增加训练时长、增加层数不一定能带来能力提升。反向传播法从误差已知输出层开始,计算上一层权重的梯度,直到将修正误差传回输入层。设计好足够多隐藏层的网络一定能逼近定义好的连续函数。
多层感知器利用了非线性变换和各种特征量的组合,并进行多次循环计算。非线性变换大多选用斜坡函数来解决梯度消失问题,更容易进行大量参数的最优化学习。
玻尔兹曼机/模拟退火算法
其网络模型和 BP 神经网络模型的结构类似,但训练方式不同。退火的意思是钢铁缓慢烧热到一定温度后保持一段时间,再慢慢把温度降下来,以期获得更柔韧的高性能金属。奥地利物理学家玻尔兹曼给出了玻尔兹曼因子,用来比较同一温度下系统所处两个状态概率的比值。从算法训练角度就是调整参数模拟退火的过程,迭代稳定收敛到某个解附近。
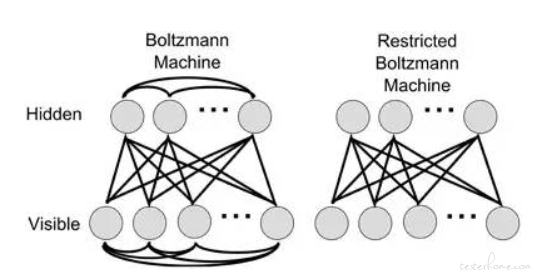
波尔兹曼机器学习考虑相邻像素之间关系,计算量会很大。
卷积神经网络(Convolutional Neural Network,CNN)
是一种前馈神经网络,本质上是一种有监督机器学习。它对于大规模的图像处理识别效率高,特别在模式识别领域,避免了对图像的前期复杂预处理,可以直接输出原始图像。CNN 的基本结构包括特征提取层和特征映射层,前者的每个神经元的输入和前一层的局部接受域相连,并提取了局部特征;后者的每个计算层由多个特征映射平面组成,平面上所有神经元权值相同,可以并行学习,收敛快且容错能力强。
CNN 可以用来识别位移、缩放等二维图形,卷积神经网络的局部权值共享结构在语音识别和图像处理中有巨大的优越性。权值共享和像素平均值就相当于模糊化,反之,放大差距就是图像锐化。
在 CNN 的卷积层中,每个神经元只需要对局部感知,相邻神经元的参数大量共享,由此大幅缩小了参数计算数量;而在 CNN 的采样层池化(Pooling)中,我们利用卷积将特征量进行排序,相近的特征进行比较并选用最大值和平均值,对前面卷积层输出的特征提取值矩阵进行量化,采用的激活函数 Sigmoid 则使得特征映射具有位移不变形。池化的目的就是压缩输出矩阵的大小。
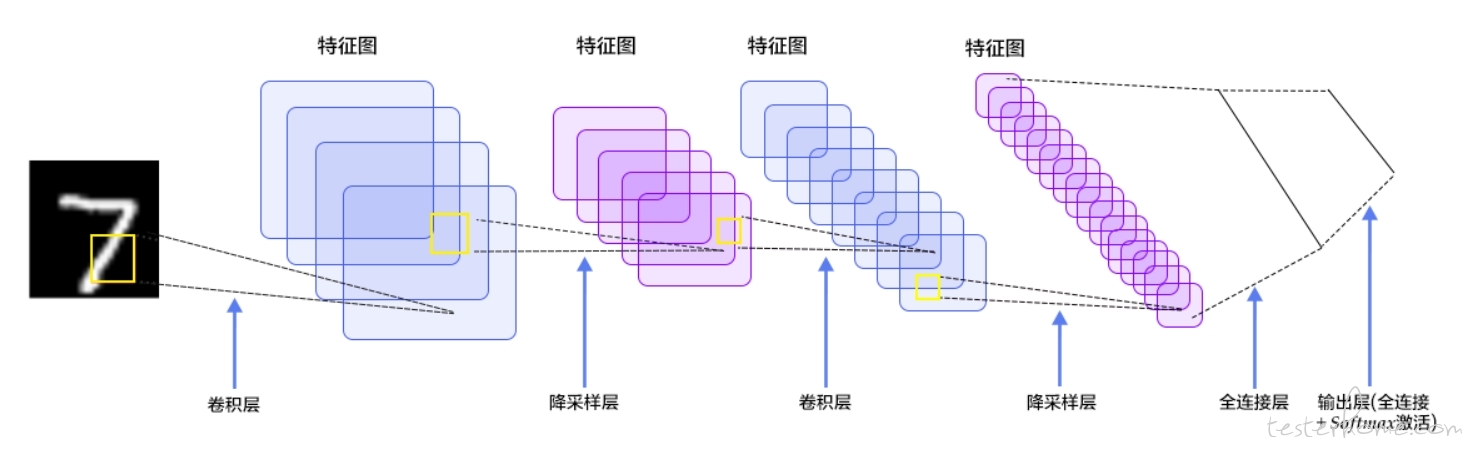
神经网络的结构参数就是超参数,它具备强大的非线性表达能力。神经网络的整体表现是个体的综合,设置不同权重会得到不同结果,但得到的性能是相似的,因此代价函数也要能量化权重。
深度学习(Deep Learning)
传统机器学习是浅层学习,属于符号主义和逻辑主义,在过去的实践中遇到越来越大的性能瓶颈。
深度学习则属于连结主义和仿生主义,它自动化了专家的特征提取和规则定义工作。深度学习借鉴了人脑的神经网络结构,它擅长处理复杂数据之间的关联关系。
相关的框架也出现了很多,著名的有 DNN(深度神经网络),RNN(递归神经网络),而 LSTM(长短期神经网络)是一种特殊的 RNN,适合处理时间序列中延迟特别长的重要事件,可以追根溯源。
计算频率越高,被保留的数据就越多。RNN 把过去记忆和当下知识一起记忆,通过选择性遗忘或保留某些信息,降低能耗。
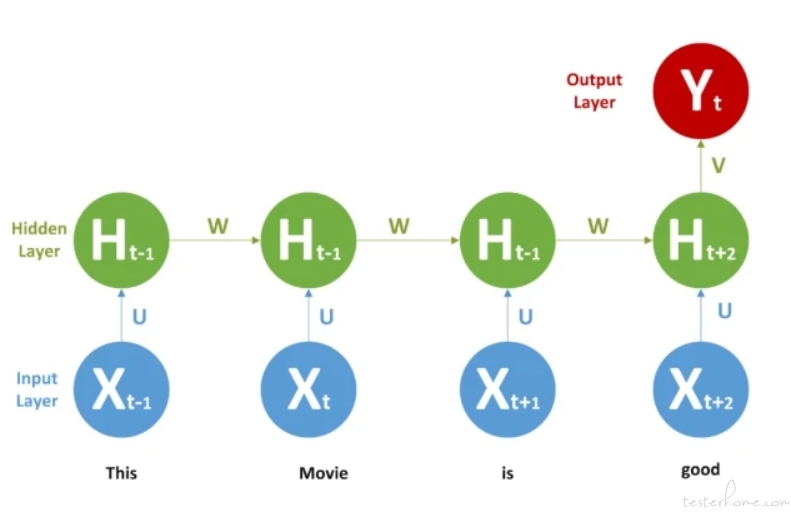
相对于传统机器学习的简单模型和小计算量,深度学习的大规模计算能力借助硬件行业和分布式计算的变革,开始展现巨大威力,能实现过去难以快速完成的大量节点和大量网络分层的分类算法。深度学习的强项也在于人工干扰环节少,通过海量的分类器叠加来处理线性不可分的复杂场景。因此,深度学习在效果边界划分清晰的领域取得了瞩目的成就。但是深度学习的弱项也很明显,其解释性差,感觉都是在黑匣子中计算,而且数据量和计算量巨大。
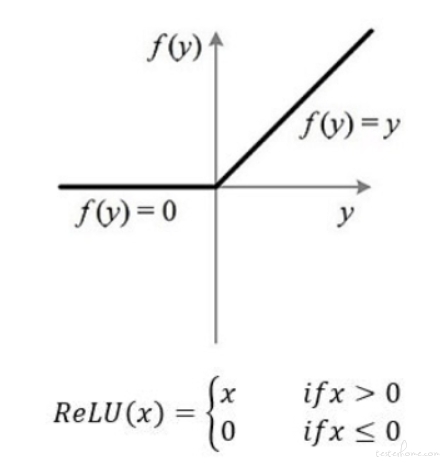
深度学习常用的 ReLu 激活函数模拟了人脑对于刺激的处理,这个函数和生物神经反应很像,刺激不够就没有反应,刺激够了就激烈反应。
强化学习
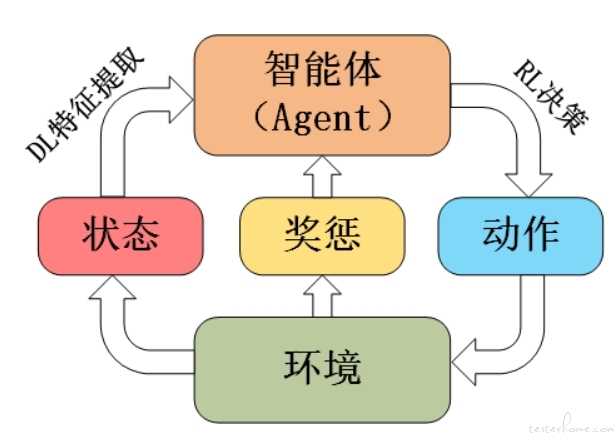
持有强化学习观点的人工智能学派是行为主义。强化学习尝试解决有关交互性和决策性的数学问题。
强化学习的对象是 state、action 和相应产生的 reward(奖惩),使用只和当前状态有关的马尔可夫决策过程,为了避免短视现象,需要把产生严重后果的 reward 值向上回溯(即向蒙特卡洛树的根部靠拢)。
只有奖励前的状态才会被奖励,且奖励随着时间权重而衰减,回报值通常由未来各个时刻的累积反馈值得到。
强化学习已被应用于游戏的智能测试中,主要是针对游戏通关的评价简单,且状态变化维度少的游戏。
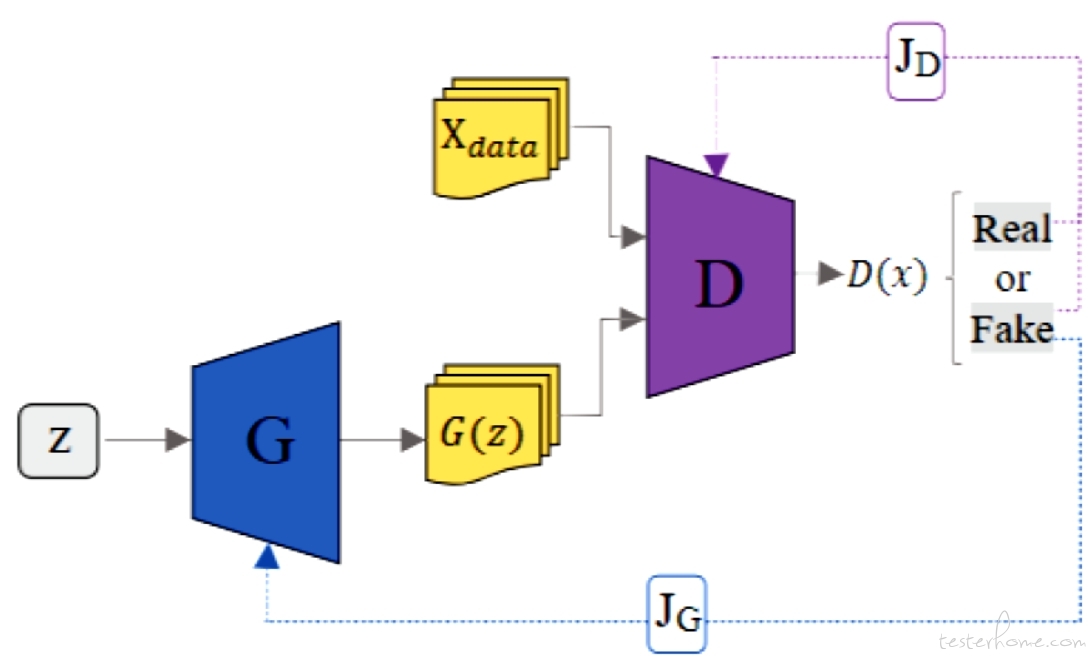
对抗学习
生成 G 和 D 两个模型(即生成模型和判定模型),前者根据输入特性 “捏造” 样本,看后者是否会判定为正确样本。通过两者的大量对抗训练和各自进化, 最终双双达到纳什均衡(刚好一半通过检测)。
大数据处理
训练数据要进行正规化处理,某时刻的数据不要超出太多,某个数据不要超出其他数据太多。
数据可以批量化学习 batch learning,或者不间断在线学习 online learning。
深度学习基于大量的预训练,通过自我符号化,重复提取重要特征量,这个就是本质特征,所以个人认为深度学习是最有可能实现 AGI 的方案。
根据学习的内容和广度,根据内容给予的数据数量和质量,能决定最终的系统性能。
人工智能的局限和风险
基于 ANN 的新一代算法能有效避免过拟合,内部运算会做大量简化,也不考虑大量的外部因素,但这种不可控性会带来可怕的未知后果。
人工智能的目标还是人来设定的,人天然就有局限性,因为一个事物的视角是多种多样的,人不能定义好所有视角。而人类知识里的各种悖论,人工智能也解决不了。
在 AI 越来越强大的时代,人会设定游戏规则不让 AI 参赛,也会制定法律约束 AI 的滥用。因此 AI 并不会让热门的人类运动比赛和艺术门类消失。
AI 也不会威胁人类,但人类自己可能会威胁自己,如何管控恶意利用 AI 的人类才是关键。可以想到未来层出不穷的基于 AI 的破坏性场景,需要技术专家与时俱进,做到道高一尺魔高一丈,比如:
恶意伪造或篡改内容,恶意并发访问 AI 服务。
数据的选择和提取无法体现人性的一面。更不用说坏人会训练数据投毒和通过众包来投毒。
窃取模型,挖掘模型泄密的原始客户数据。
大模型依赖的软件漏洞被利用。
最后补充
以上介绍的各种算法知识,给应用人工智能的工程师提供了各种模型,相关的强大工具被陆续打造出来。但是不同的工具有适合自己的场景,强行使用有可能带来事倍功半的反面效果,因此理解业务场景是第一驱动力。
目前来看,人的想象力是暂时区别于机器的核心能力,而人的情商也能应对 AI 领域无从下手的无边界问题。