
这是鼎叔的第一百篇原创文章。行业大牛和刚毕业的小白,都可以进来聊聊。
欢迎关注本公众号《敏捷测试转型》,星标收藏,大量原创思考文章陆续推出。
第一百篇文章要上个硬菜。开启一个新专题系列 - 如何度量研发效能,同时也开启了对于过去几年研发效能工作的快速复盘。
缘起
在一个两千人的研发组织里,做一次面向企业技术高管的月度效能汇报,鼎叔花费的总人力大概比十年前至少要低一个数量级。
记得十年前,我要拉一个过程改进团队,加上一堆技术接口人,反复检查数据,输出观点和作图,折腾很久才能对高管层汇报一次。
这两年,我只需要一个兼职的测试开发员工,每个月花半天输出初稿,再让各接口人花点时间确认指标变化的原因,开一次小会就可以了。
要做到这个效率,效能度量和汇报的成本要降到最低,第一步是能随时看到关键指标,第二步就是汇报框架非常简单和稳定。
效能的数字化呈现方案,每个公司都会做,但这里充斥着理解上的误区。
效能可视化建设,首先要明确核心用户是谁,他的需求是什么,其次再明确唯一的北极星指标是什么,围绕它来建设质效可视化大盘,切忌不让其他指标喧宾夺主。
CTO 视角
如果给大型研发组织呈现效能数据,姑且认为第一用户是 CTO 等技术高管。
CTO 面对的第一个困境是,团队规模庞大,我怎么能更好地看到一线团队的效能情况?中间隔着厚厚的部门墙。每个部门汇报的数据都看着很好,但是彼此之间不是完全统一。
质量管理团队或者效能团队虽然会拉通大组织的效能数据来呈现,但也经常犯一类毛病,就是指标庞杂,观点不聚焦,并且容易内部妥协(担心被内部质疑)。
形成这个局面的主要原因是:
一,没有专家敢对北极星指标负全责,结果把北极星指标变成了团队脑暴成果。质效指标看起来都对,但是都是盲人摸象,逻辑零散。十个人观点汇总的报告也不可能达到高水平。
想到一堆重要指标很容易,但是锁定唯一指标就难。
二,为了体现质量和效能成果的 “专业度”,故意引入复杂的行业指标框架,并定义了极为细致和深入的子指标。在一线开发和测试生成的数据上,进行不必要的二次封装或拆解。
从第一用户的视角来做质效大盘,挑选出的北极星指标,还是要来源于对组织效能的本质理解。
我认同多数公司会选择 “需求平均交付周期-Lean time” 作为 “唯一” 的北极星指标。如果用户主观觉得太慢,那效能评价就不会满意。
这里面又可以拆解出需求平均研发交付周期。
研发团队如果是独立管理,可以先聚焦研发侧的交付时长。
如果产研高度一体化,就可以看整个需求交付时长了,它通常包括需求调研和文档时长,研发时长(含测试和合入主干),市场部署时长(对于纯后端发布的业务,这块时间极短)三块。
CTO 的第二个困境随之而来,多久时间可以觉察出效能短板,并及时干预,中间等待下属分析的时间极短?
我们很容易想到做一个实时质效大盘,并通过它进行质量和效率的风险预警,并能自动生成初版的效能报告。各个部门很难对度量数据进行及时的 “掩饰”。
但实际上,质效大盘在各个公司的落地评价差异非常大,本质上的原因是什么?
质效大盘的设计
正如前面分析的,大盘的首页一定要突出北极星指标,然后是围绕它的第一层拆解,拆解出直接影响北极星数值大小的分类信息。
以需求研发交付时长作为北极星,第一层关联指标该怎么拆解?下面是个人的实践推荐:
一 需求达成率(吞吐率)或月度需求完成总数。知道了平均时长,再配合交付的数量,和交付承诺的达成情况,研发交付的宏观情况就更清楚了。
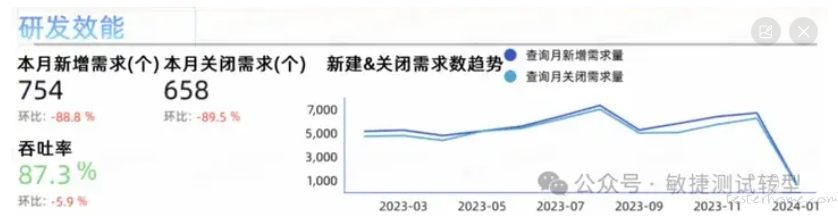
二 过程耗时拆解。一线团队看到了自己的平均交付时长,可能还是不知道中间哪里被拖延了,这时大盘可以提供拆解耗时视图,比如研发交付周期被拆为四大阶段:需求开发设计,编码和自测,集成/系统测试,合入主干/发布。
每个阶段可以利用研发管理平台的状态流转自动统计耗时(注意这里有个坑)。
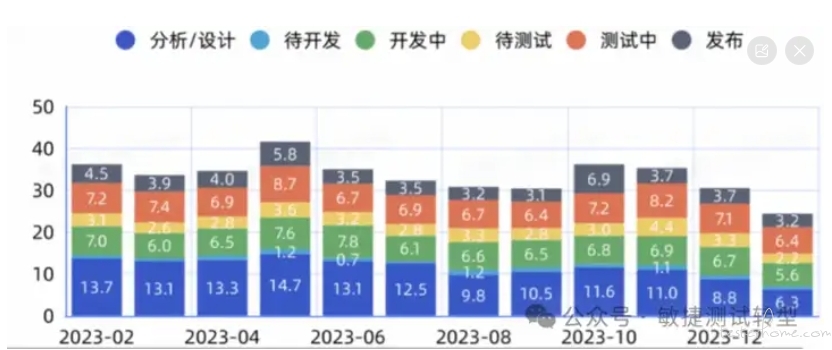
四大阶段还可以继续拆解为 N 个小阶段,每个阶段单独统计耗时。
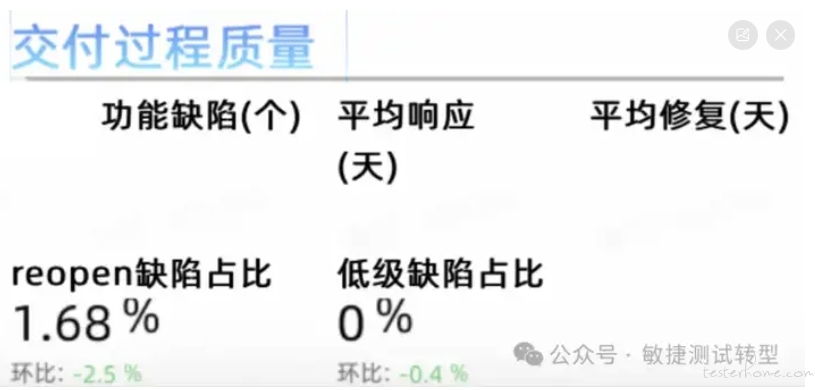
三 过程关键质量。研发过程中导致技术人员返工的质量问题,必然会拖累北极星指标。推荐指标有:
低级缺陷率(或数量),一看就属于开发自测应该发现的基础问题,但遗留到了系统测试阶段。
缺陷平均处理周期,体现了缺陷处理时效。
缺陷 reopen 率(数量),体现了开发是否一次性解决问题。
四 上线质量。这类指标聚焦上线过程和上线后是否产生失败,导致交付损失和更昂贵的返工。推荐的可选指标有:
发布成功率/折返率。发布过程的失败次数值得具体分析,以暴露技术协作的风险。
线上事故级别和数量,线上逃逸缺陷级别和数量。根据公司质量规范定义,前者后果更为严重,可能触及研发红线,需要严肃复盘和追责;后者可能大部分是遗漏场景,需要具体分析能否提前拦截。

注意一个定义:事故和逃逸缺陷不一定都能通过有限成本的测试拦截的。但是漏测缺陷就一定可以。
为了让大盘内容更简单清晰,上述四类拆解指标的详细数据可以放在大盘的次级页面里,方便一线团队下钻。
大盘还会提供核心指标的趋势视图,便于干系人关注变化。
大盘的用户还有谁
再往下想一层:CTO 并不会频繁查看报表和提出数据分析需求,那大盘的第二类重要用户是谁?
那就是承担交付压力的一线团队 leader,他们必须要从大盘指示器中下钻到自己团队的可视化风险。
我遇到一个公司的持续交付负面例子:质量管理部列出几十个指标,让持续交付平台开发者把它们做到看板上。这些指标不是从一线团队日常视角来罗列的,更像是完成质量管理部门策划出来的目标。这样非但不能让一线团队得到自驱改进的益处,还增加了大盘的理解复杂度,并增加了开发维护成本。
我心目中的质效大盘是逐步演进出来的,一开始只有上述最简单的一级拆解指标,随着大家使用的活跃度提升,在不同层级上总结出了很有价值的分析指标,再慢慢加到合适的层级上去。
比如非常重视资金损失的团队,会把资金损失的异常告警数和事故数据,在大盘里添加,并实时提示出来。
效能的定期汇报
有了实时看板可能还不能满足质效工作者的安全感,定期的汇报可能会成为例行安排。
有了逻辑清晰稳定的实时大盘,汇报从本质上就轻松太多了,初稿一键生成 + 专家提炼观点 + 干系团队补充分析,三板斧搞定。
鼎叔发现一个有趣的现象,测试开发工程师做大盘生成是一把好手,结合强大的数据报表工具,效率极高;但分析效能指标观点起来就很弱了,要么没想法,要么瞎猜。确实后者是完全不同的技能,需要长期实践和交流。
对于大型组织的重要例行汇报,把握一个核心出发点就是实时数据说话,针对偏差大/劣化指标进行分析。保持和各部门接口人的沟通关系,迅速确认指标异常的原因。关键是及时暴露问题,而不是跨团队 PK 绩效和指责。
因为大盘背后的根基稳定且简单,鼎叔很少收到各大部门对大盘指标体系的质疑,最多是对某个指标自动度量的偏差有质疑。那我们往下看:
如何度量得更准
未来一个优化方向,就是如何自动度量地更准。鼎叔建议和项目管理团队合作,认真梳理研发管理平台的字段填写要求,并对规范进行培训和自动筛查。
最影响北极星指标度量的填写问题主要有:
1 需求和任务,傻傻分不清楚。
需求交付的是完整价值,用户能得到价值。
任务只是完成价值的一部分工作,如测试任务,联调任务,前端后端开发任务等。
北极星度量的是需求交付时长,切忌把 “任务” 改成 “子需求” 进行处理。
我们鼓励把大需求拆解为子需求进行度量,需求小了,交付效率就会高,团队就会敏捷。拆解文章请看:聊聊用户故事的估算和拆解
2 决定需求进入研发的 “起点时刻”。
回顾 Scrum 的知识,产品经理完成需求的修改和录入系统,成为 backlog 中的一部分,这些需求有很多并不会纳入本迭代开发,它们可能被推迟甚至无限推迟,从而拖长了 “需求平均交付时长”。
为了校准这点,研发管理系统要明确 “进入迭代开发” 的起点时间,作为统计 “研发交付周期” 的起点。
同理,针对对需求中途变更(经过团队确认,出于提升用户价值的目的),鼎叔鼓励暂停 “被推迟” 需求的统计周期,直到 “再次开启”,这样度量更准确,可以鼓励团队集体变更,拥抱变化。