
前言
今天简单的介绍一下在计算机视觉领域的测试人员一般都在做什么样的工作。
从目标检测说起
首先从一个目标检测的场景来看一下测试人员使用什么样的方法来进行测试。什么是目标检测呢, 如下图:

这是我周末带老婆孩子去体育场玩时拍下来的照片。 我使用这张照片输入到模型中,希望模型可以识别出图片中的人类并画出人类所在位置的长方形的框。 而这就是目标检测。
目标检测的关键问题
- 分类问题:即图片(或某个区域)中的图像属于哪个类别。
- 定位问题:目标可能出现在图像的任何位置。所以需要模型输出带有目标位置的 4 个连续值。
- 分割问题:分为实例的分割(Instance-level)和场景分割(Scene-level),解决 “每一个像素属于哪个目标物或场景” 的问题。
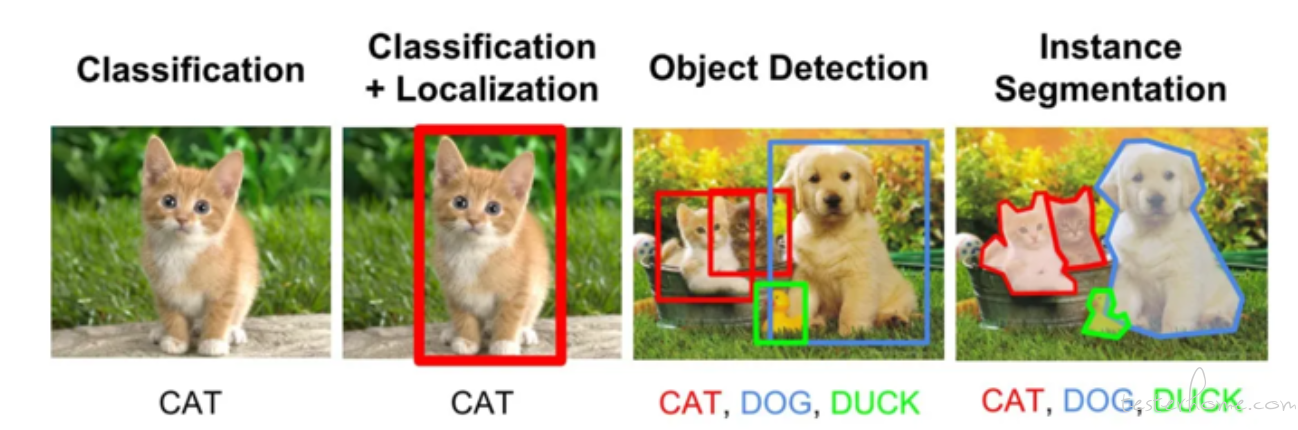
所以,目标检测是一个分类、回归问题的叠加。 目标检测也是在计算机视觉中最为常用的算法,事实上大部分的应用场景都离不开目标检测算法,比如:
- 人脸检测:包括了门禁和支付的人脸识别,各个 APP 的用人脸实名认证等等
- 人体检测:包括了人体的静态属性识别(是否穿戴了安全设备),人体的动态行为识别(摔倒,打架,野泳等等)
- 车辆检测:车辆违停,车辆属性识别(车牌,车型,品牌)
- 其他:占道经营, 烟火检测等等
模拟一个测试流程
以上面的识别人体的目标为例, 我们首先需要下载一个 yolo 模型,yolo 是在目标检测领域中非常出名的模型,性能高,准确度也很好。 我们可以在 huggingface 中下载到相关模型。 由于我写的这个 demo 是早些年前了, 所以当时下载的是 yolov3。 需要注意的是除了模型文件外,还需要下载对应的网络结构文件,然后就可以编写相关的代码:
import cv2
import numpy as np
# yolov3下载地址:
# 网络结构文件:https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg
# 模型(权重)文件:https://pjreddie.com/media/files/yolov3.weights
# 80个类别标签的文本文件:https://raw.githubusercontent.com/pjreddie/darknet/master/data/coco.names
# 读取yolov3模型用以做目标检测
net = cv2.dnn.readNet('/Users/cainsun/Downloads/yolov3.weights', 'yolov3.cfg')
# 获取测试图片
datas = []
with open('labels.txt', 'r') as f:
for line in f:
datas.append(list(line.strip('\n').split(' ')))
print(datas)
TP = 0
FN = 0
FP = 0
TN = 0
# 读取图片并传递给模型
for image in datas:
path = image[0]
label_y = int(image[1])
frame = cv2.imread(path)
height, width, _ = frame.shape
# 构建输入图像
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416), swapRB=True, crop=False)
# 设置输入层,获取输出层
net.setInput(blob)
output_layers = net.getUnconnectedOutLayersNames()
# 前向传播,模型推理进行目标检测
outputs = net.forward(output_layers)
# 解析输出就,主要获取目标的类别和图像中的坐标
boxes = []
confidences = []
class_ids = []
for output in outputs:
for detection in output:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5 and class_id == 0: # 只检测人类
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
# 非极大值抑制,主要用于删除重复的框信息
indices = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
上面的代码有一些需要注意的:
- 在计算机视觉领域中,opencv 是一个性价比非常高的工具。它包含了大部分的图像视觉处理算法可以辅助我们测试之外, 其中的 dnn 模块可以帮助我们读取各种格式的模型,它支持主流的开源深度学习框架训练处的模型,比如 pytroch,tenseflow 等。
- 模型不会输出一个已经画好目标框的图片, 它只会输出所有目标的坐标信息,打分(或者叫置信度,记得模型输出的是属于该类别的概率,用户需要自己设置阈值来判断高于多少概率算作是目标)和类别(yolo 是 80 分类模型,class_id 为 0 的是人类, 用户需要自己过滤类别)。
根据上面的代码,我们已经可以通过模型识别到图片中的目标信息(人类), 后续可以通过一些代码来计算一些模型评估的指标(混淆矩阵,召回率,精准率),比如下面的代码片段:
............
if label_y == 1 and y == 1:
TP += 1
elif label_y == 1 and y == 0:
FN += 1
elif label_y == 0 and y == 1:
FP += 1
elif label_y == 0 and y == 0:
TN += 1
recall = TP / (TP + FN)
precision = TP / (TP + FP)
print("recall: " + str(recall))
print("precision: " + str(precision))
PS: 如果忘记了混淆矩阵,召回率,精准率相关的内容,可以翻翻这个系列的第一篇文章。
统计出模型评估指标一般来说还是不够的, 因为要排查 badcase 需要直观的看到哪些目标被识别错了。 就像这篇文章最开始的那张图,识别出哪些目标都用绿色的长方形框给画了出来,并展示出每个目标的打分(模型输出的是概率,我们通常也叫打分)。这样我们才知道哪些目标没有识别出来,哪些目标识别错了。 从模型中可以获取到图片中所有目标的坐标和打分信息, 通过 opencv 中的画图方法,可以在图片中画出对应的目标:
# 根据坐标信息画出目标的框
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
# 定义字体
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1
# 定义字体颜色和大小
color = (100, 206, 145)
thickness = 2
text_size, _ = cv2.getTextSize(text, font, font_scale, thickness)
text_x = x
text_y = y + 10
# 在框的附近写入打分信息
cv2.putText(img, text, (text_x, text_y), font, font_scale, color, thickness)
这样就能做到这篇文章最开始的那个图中的效果了, 我们再看一下:

这样我们就能分析出哪些目标漏掉了, 哪些目标识别的错误了。
结尾
今天给的例子实际上就是我模仿实际项目中的测试代码写出来的,只不过我们算法团队提测的模型是公司自研的框架产出的而不是 pytroch,真实的场景会更加复杂一些但基本步骤都是相同的,基本上测试脚本多是大同小异的。
更多内容可以关注我的星球:
