前言
周末有时间了, 又可以写一点自己想说的东西。 先说说为什么要写这篇文章, 因为每个人的经历都是没有办法复制的。我之前写的自己的经历主要是描述自己在什么时期去了什么样的公司,做了什么样的事情。 但这些经历跟当时所处的大环境有很大的关系。 比如我是从三本 +4 年外包的履历转战互联网的, 这在当时 14 年左右的时候并不是什么稀罕事,可以说难度并没有很大。 而放到现在这个履历就是 hard 模式了,就像我在上一篇帖子说的,行业爆发期和行业寒冬期是完全不一样的。 所以呢我想了想, 这一次我介绍一些我在工作中比较重要的经验,或者说习惯和方向选择。 也许这些对大家还更有参考性。
我自己为什么要学技术
首先说说这个吧,毕竟它是最重要的,也是最容易有争议的。毕竟测试技术无用论在行业中曾经也盛行过很久,直到现在也没有平息。 这里我想说的就不是自动化测试了,如果目标聚焦在自动化测试和效率提升上,那么就很容易偏离今天的主题并且陷入没有结果的争论中。 这里我希望提出一个路线, 就是当把技术磨炼好后,可以有比较高的概率进入到一个从薪资待遇/工作前景/工作环境等方面都相对更好的工作岗位中,并且职业生涯也可以相对长久一些,这也是我一直主张的一个观点。 这些岗位的特点是面对的产品往往是门槛较高的技术型产品(这里指的技术不是只有写代码这一种,而是一种比较广泛的技术,比如我的一个朋友在保险公司,它是专门测试财会系统的,为此他甚至拿到了会计证书)。
所以我希望自己可以尽可能的进入这样的产品中工作, 因为我觉得这样的工作岗位竞争对手没有那么多,上限也更高一些。 可能空谈的效果不好,所以还是拿我自身的几个例子出来,给大家参考一下。
AI 领域
初级阶段 -- 模型评估的基础阶段
首先其实 AI 的测试工作,入门的门槛真的不高,相反其实非常低。我们这边有大量的外包同学和子公司的同学在做。因为有很多的 AI 产品的测试工作其实就是对着模型测效果,数据采集不需要关心, 数据标注有专门的人在做。 测试人员只需要把数据输入给模型,然后按一个很简单的公式去计算模型的评估指标就可以了(比如召回的公式就是:TP/TP+FN),所以一位外包人员简单培训一会就可以上手了。 不需要懂 AI 的原理,不需要扎实的代码和工程能力,只需要熟悉如何计算模型评估指标和基本的脚本编写能力就可以了。
我相信大多数 AI 领域的测试人员都是从这里入门的,这时候虽然我们已经可以说自己是 AI 领域的测试人员了。但其实仍然没有技术门槛, 可替换性非常高,所以对比普通的测试人员还说不上有什么优势。 而在这个阶段的人其实也是很痛苦的,虽然人已经在 AI 领域里了, 但其实离 AI 的核心领域相差十万八千里,想学习但是工作中确实涉及不到 AI 的核心区域。我曾经也在这里痛苦过,不过好在没过多久就找到了一个突破点。 这就是下面的阶段要介绍的。
中级阶段 -- 可以进行一定的数据采集和处理的阶段
了解 AI 领域或者看过我之前写过的关于 AI 的帖子的应该知道我不止强调过一次,在这个领域里数据是核心。对于测试也是一样的, 计算模型评估指标的方式是非常简单的,关键在于是否能收集到符合场景定义的高质量数据。而如果没有处于一个特别正规且规模庞大的组织中的话, 其实数据采集/处理/整合 等工作是没有明确的权责分配的。 也就是很可能是需要测试人员自己来想办法去获取数据。 这里面不同场景的做法不太一样:
- 结构化数据场景:最常见的结构化数据是由行和列组成的数据表,保存在各种不同的数据库中,并且往往数据量十分庞大(AI 是基于大数据的,所以大部分 AI 团队都是基于大数据技术在展开数据相关事宜的)。上面也说过模型的评估难点在于是否可以收集到符合场景定义的高质量数据,而非去计算模型评估指标。 而在海量的数据中去采集到我们需要的测试数据明显就是一个技术活了。在我的《我们是如何测试人工智能的》系列帖子中的第一篇,我就介绍过要客观的评估你的模型效果, 就需要针对你的场景和用户画像等因素,把数据进行分类(其实我们通常会叫样本的类型),每一种分类都需要采集一定的数量这样才能比较客观的评估模型在这个类型的数据下的效果如何,这通常可能要计算模型的分组指标, 比如模型在学生类型的用户下的效果如何,在教师/程序员/产品经理/自由职业的用户下分别效果如何。 又比如在很多视觉场景中,不同时间段的数据是不一样的(主要跟人类的出行和生活习惯有关,这些往往表现为跟时间有强烈的关联性,比如上下班高峰期等因素)。所以测试人员需要了解你的业务,了解你的数据。 然后掌握一门可以在海量数据内(可能是数以千万甚至亿来计算)采集到符合要求的数据的技术。 而我当时选择的就是 spark, 通过 spark 可以针对不同的数据存储软件中进行分布式计算,它也拥有很强大的数据分析能力,能帮助你了解你的数据分布。比如我们到底应该采集多少比例的某个类型的数据才算是客观的, 那你就需要先通过 spark 来计算一下这个类型的数据在整体的数据中的占比多少。
- 计算机视觉场景:这里主要分为视频数据和图片数据。以目标检测为例,模型接受的是图片,输出的是这个图片中目标物体的坐标和分类 id(就是它具体属于什么物体,是人啊还是老鼠啊还是汽车啊)。但在端到端流程中数据是从摄像头发送而来的视频流(通常是 rtsp 协议的视频流),并且有相当多的前处理(抽帧/解码)和后处理(比如多帧识别)工作。 所以一般我们要在端到端的视频数据和原始模型的图片数据上都进行测试。 而很多时候数据来源就是从真实的摄像头中进行抽帧采集(除非是特殊情况比如人脸数据,或者那种面向普通用户的非摄像头视角的数据)。 在这个数据采集的流程里有这样一个问题,就是标注组的人员通常只负责标注数据。他们不会直接去摄像头中进行采集/视频裁剪和拼接/抽帧/场景初筛 等工作。 而其他角色,比如交付运维等等也不会做这个事情(他们也不知道你具体需要什么样的数据,因为从摄像头采集的数据中有大量的没有任何物体或者不符合场景的时间段,比如强光,模糊,遮挡,不符合 ROI 等等,所以原始视频不能直接测试,而是要经过一定的剪辑和拼接)。 所以不少地方是由测试人员来完成这个工作。 我们通常采用 ffmpeg 来完成数据的采集/裁剪/拼接/抽帧的工作, 也会在测试时通过 ffmpeg+ 流媒体服务器来模拟摄像设备进行端到端的测试。 针对图片数据也会使用 opencv 来进行一定的图像处理, 比如在测试中为了方便排查,往往会把模型识别的目标通过 opencv 在原图上勾勒出图框并表明打分数,比如下图(模型返回的是一个 json 数据,有目标的坐标, 打分和分类 id, 但这个数据很难去排查问题。 所以往往我们需要用 opencv 在图片中通过模型返回的坐标和打分进行绘图, 这样才能让人一眼就看出来模型识别的错误在哪里):

PS:数据处理不只是我上面列举的两个例子,我只是列出比较常见的。
而这里可以看到对比第一个阶段, 我们在第二个阶段里拥有了一定的数据处理能力。 其实到了这里我觉得才算是真正踏进了 AI 领域测试的门槛了,算是在茫茫多的竞争者中树立了自己在 AI 领域中的亮点。 到了这个阶段的测试人员,已经不会在数据上求助他人了。第一阶段的测试人员只能等待别人把数据处理好后使用,实在是没有什么门槛可言。
而在这个阶段的测试人员仍然有短板, 那就是他仍然不知道人工智能究竟是怎么回事。 人工智能对他来说大部分仍然是一个黑盒子。 这就导致有些工作也很难能完成。
高级阶段 -- 熟悉整个人工智能生命周期的业务和原理
人工智能是一个复杂的系统,不是只有一个模型, 我需要先澄清一下这一点,虽然现在市面上很多岗位都是对着模型进行测试的, 但是也有一部分工作内容涉及到了人工智能的方方面面。尤其是在市面上有一批公司和团队是专门在做人工智能的平台类产品,这类产品是把整个人工智能的生命周期设计到了产品中, 主要目的是降低 AI 落地的成本。 算法工程师可以在产品的图形界面上通过托拉拽的形式就把相关的数据和算法配置好并进行分布式的训练,之后模型评估,模型上线, 自学习,迁移学习,实时训练等等等等都可以在这样一个人工智能平台中完成。 比如下面就是一个产品截图:
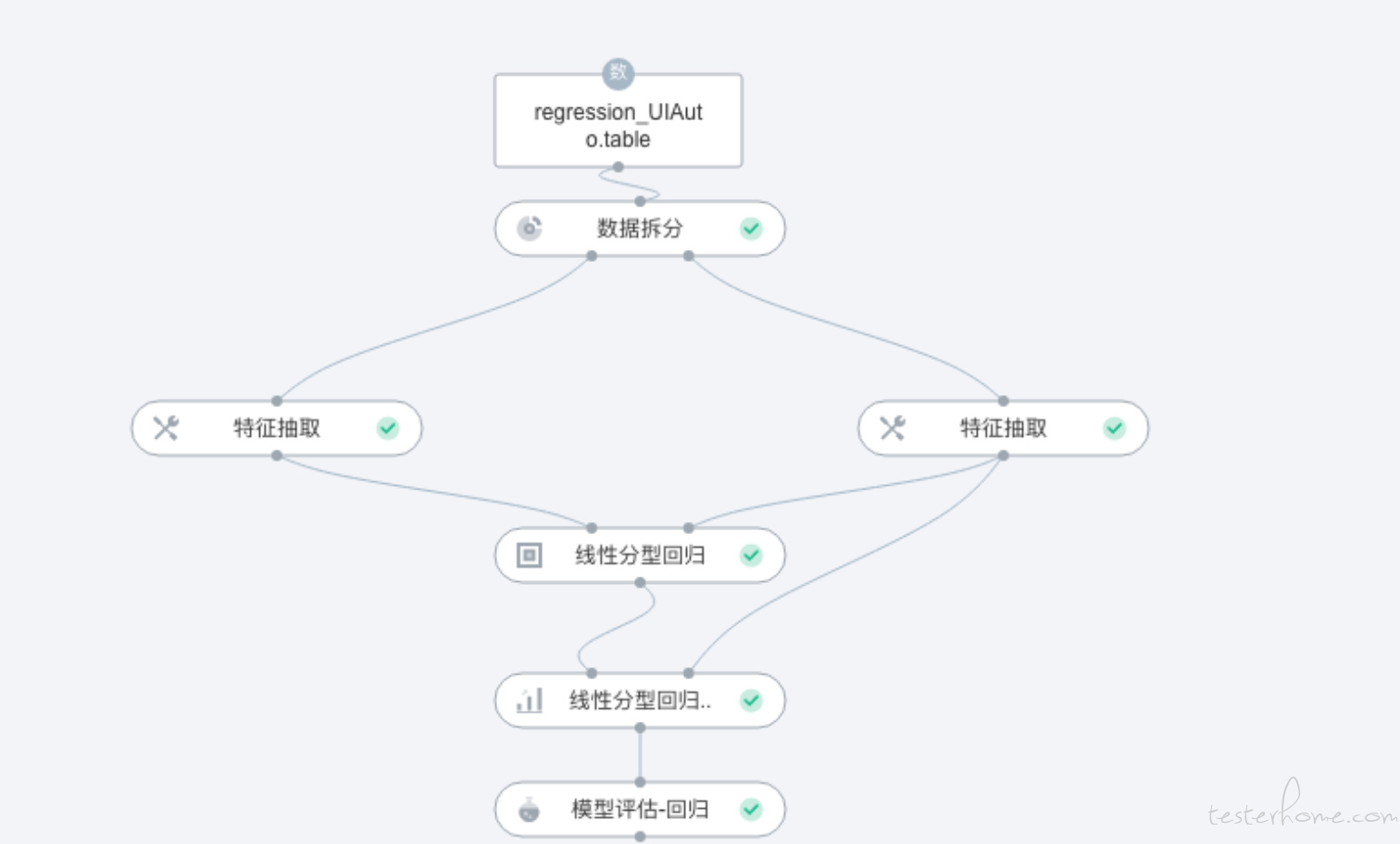
所以测试这样的一个产品,需要测试人员懂得人工智能的基本业务流程和算法原理。 否则你连产品在干什么都是不知道的,那就根本没办法测试。比如不知道有多少同学知道上面那个截图中每个 Node 都是在做什么的。 或者我这里列举一个迁移学习(模型微调)的测试场景来说明:为了验证产品的迁移学习能力是否正常。 测试人员往往需要准备一些预训练模型(就是已经训练好的模型),我们可以自己从公开模型仓库中下载,也经常会要求产品提供一些基础的预训练模型,比如在大模型能力场景中, 上个月客户刚刚要求我们在产品中内置 baichuan 模型作为预训练模型,并要求我们验证在平台中使用 baichuan13B, 50B, 70B 进行迁移学习的可行性。 所以测试人员要走通这样的业务流程, 并通过调整参数(GPU 数量/型号,tokens 数量,训练轮数, checkpoints 周期,文本长度等等等等)并验证在这些参数下的产品表现:
- 设定了每多少个 step 保存一次 checkpoints(checkpoints 用于保存模型训练的中间结果),那我们就要通过日志确定它确实保存了 checkpoints 并且我们要到存储设备中看到 checkpoints 并记录它的大小,并且需要故意弄挂模型训练过程后, 尝试从 checkpoints 中恢复训练,以验证这个功能。
- 文本长度:在很多 NLP 算法中要求每一个数据(一段文本)的长度是相同的,但真实的场景下怎么可能是相同的。 所以需要用户设定一个长度, 然后程序针对文本进行补齐, 比如超过了这个长度的问题就截断, 小于这个长度的文本就用特殊的掩码补齐。 所以测试人员要根据数据中的文本长度的不同来设定这个参数。
- batch size:现在的算法都是支持随机梯度下降的,可以设定每一次小的梯度下降只使用多少行数据做一次小的迭代。
- Epoch:可以理解为训练的轮数, 设置算法要迭代多少轮数据。
- 学习率:可以理解为决定了梯度下降中的步长
- 冻结参数:是否冻结预训练模型的参数(是参数不是超参数,现在说的学习率,epoch,batch 在人工智能中都叫超参数,参数是模型中保存的特征权重),要冻结多少层。
上面这些参数影响了整个迁移学习的性能的功能,其实还有很多别的参数, 我这里就不列举了。有些时候这个过程是通过图形界面来完成的(如果产品设计的比较成熟,是可以通过完全的图形界面就完成这个工作的),也可能是需要调用一些 sdk 来完成。但不管是图形界面还是通过调用 sdk,它的前提都是测试人员能够理解这些产品功能和参数是什么意思。
所以综上所述,有些东西需要测试人员在人工智能领域中有一定的研究才可以。 而如果想从第二阶段过度到这个阶段是非常难的。 因为除却少数比较幸运的人以外, 在没有相关 AI 背景的前提下,很难进入这样的团队开展测试工作。 或者就算进入以后,通过在项目中学习也是一个非常缓慢的过程, 首先就不能指望有人能详细给你讲解这些算法,这些流程(除非遇到非常喜欢教人的前辈。。。。emmmmmm。。。比如我,我就喜欢每隔一段时间教一下新人各个技术的原理)。 在项目中你最多就能学到你负责的这一小块内容的知识, 并且可能对方也不会给你讲的很深,只是告诉你操作步骤要如何执行就可以了(仅仅满足工作的基本需要,不会告诉你为什么要这么做)。
所以我说这个阶段是痛苦的, 我当时的心里状态是很不甘心的, 因为我身在一个人工智能平台的产品中但我却对人工智能知之甚少,虽然当时我还没有对人工智能的整个测试体系有所了解,但我比较肯定当时的我离真正的资深 AI 产品的测试人员还差着一道很大的鸿沟,毕竟我不懂 AI 的原理,不懂原理就很难从底层设计的角度出发来设计测试方案,优化测试策略。所以我首先在网易云课堂上,花了 3 个月时间去学习吴恩达的深度学习课程。虽然他的课程风格已经是很说人话了,但仍然比较痛苦, 所以我是硬着头皮去看的,中间去翻阅各种资料。 勉强的算是把课程学完,知道了人工智能各种场景下的原理。 然后又去疯狂的请教的其他人, 负责其他 AI 项目的测试人员,算法等等,同时也在大会中请教其他在该领域的同行和在 B 站中学习各种资料。
这个阶段的难点是我了解其中一个场景的流程并不很难, 难的是 AI 领域中的场景太多了。 结构化数据领域中的反欺诈、推荐、差异化定价(俗称大数据杀熟)等等, 计算机是觉中的目标检测,目标追踪,目标切割,人体静态属性,人体动态追踪,人体姿态识别,OCR 等等。 NLP 中的机器翻译,对话机器人,知识引擎,生成式模型,文档解析,语义切片,语义检索,asr,tts。 大模型中的文生文, 文生图,图生文,文图匹配问答等等等等。 在涉及到系统架构的时候,又要引入分布式计算(结构化数据都要依赖大数据技术),边缘计算(计算机视觉中的一个比较大的场景),云原生等等等等(现在大型 AI 系统都是云原生架构, 都是依赖 K8S 中的)。 然后还需要研究在这些东西里如何开展测试方案,如何开发测试工具,如何提升效率等等等等。
我一直希望自己能够构建起一个 AI 领域的系统性的知识脉络,各种场景下我都能知道它的业务流程,设计特点,测试方法等。而从 16 年开始到现在 8 年时间, 我一直在积累这些东西。 因为这个系统的知识脉络是我在 AI 领域内吃饭的家伙, 是在众多的竞争者当众脱颖而出的资本。 而我也是靠着这些东西在 2 年前,也就是我满 35 岁的时候,拿到了众多 AI 团队的 offer。当然按现在的行情来看,我如果再找工作可能不会像 2 年前那么顺利(毕竟大家都在裁员)。 但 2 年前跳槽的时候我是真的没有感受到过 35 岁危机,当然有没有 40 岁危机就不好说了。
大数据领域
在列举一下大数据领域中的成长吧,其实把大数据和云单独拉出来有一点点别扭,因为我不是专门搞大数据的。 之所以在大数据领域中搞了很多事情, 主要是因为 AI 是基于大数据和云计算的。 所以我在研究 AI 的过程中,学习到了很多大数据和云的东西。 嗯,记得我之前也说过:技术的深度决定了技术的广度, 为了研究好 AI,就得去研究大数据和云。
初级阶段 -- 普通的功能测试
其实与 AI 领域一样, 大数据领域的功能测试与普通的测试没什么区别。 大多也都是集中在功能测试的维度上,都是通过产品界面来完成功能测试。 不同的是大数据产品中很多时候需要测试人员去设计一些精准的测试数据(量不用大,所以还不用涉及到分布式计算上)。 因为大数据产品中会把数据分析设计的很重,比如会有很重的 BI(商业智能)子系统。 这里面会有非常复杂的报表。 比如我去年跟进的一个大数据营销产品中,它设计了留存分析,归因分析,漏斗分析,属性分析,事件分析等等。每种分析根据不同的条件会产生不同的报表。 所以为了测试这个报表,测试人员要弄明白这些报表计算的流程,并且设计出精准的数据去验证系统报表上计算的各种数值(比如转化率,留存率什么的)是不是正确的。 就比如你在数据库中创造的数据下,留存率就必须是 5%, 如果界面上显示的不是 5%,那就是 bug 了。 还有一个不同的地方就是可能有些产品会把 sql 编辑框暴露在产品 UI 上, 需要测试人员去通过 sql 来测试一些能力,但我感觉也没啥门槛, 毕竟 sql 谁不会写。。。。。
其他工作与普通产品并无分别。 所以我们说这个阶段虽然说是在做大数据产品的测试,但其实也并不懂大数据是什么东西。
中级阶段 -- 可针对大数据特性开展专项测试
先从性能测试说起, 在大数据领域中性能测试与传统的模拟高并发的性能测试场景不同, 很多大数据场景几乎没什么并发量,它们的业务聚焦在海量数据下的计算。所以测试人员也从模拟并发数量,转变到了模拟数据规模与分布。这时候需要测试人员懂分布式计算技术来完成这样的性能测试工作。 原因主要有以下几点:
- 当模拟海量数据的时候,用以前的 python 脚本形式,或者访问产品 API 的造数形式往往性能无法满足要求(比如要构建 500 列,10 亿行数据的时候)。在海量的数据量级下,也只有分布式计算本身才能加速这个造数过程。
- 在大数据产品中,影响产品性能的不仅仅是数据的规模。还有诸多其他因素,比如数据分布(数据倾斜),partition 数量,分区表的设计,宽表等等。 如果对于一个存储软件来说,还需要模拟海量的小文件,不同磁盘规格,文件系统下的性能表现。 需要测试人员懂得分布式计算与分布式存储的原理方能设计出合适的测试场景并模拟相应的数据.
除开性能测试外,执行数据质量监控时也需要使用分布式计算技术编写脚本来扫描数据(根据规则来验证数据是否符合质量要求),做产品演示或者竞品对比时,需要编写相关 ETL 脚本来对数据进行清洗才可以导入到产品中。 而在在涉及到流计算的时候,它的各种测试方法又会有所不同,我们需要与 kafka 这样的消息组件打交道, 需要了解幂,了解分布式事务,了解 3 种一次性语义,了解 Flink 的 checkpoint 和反压。根据上述特性分析性能和数据一致性上的弱点, 并根据弱点设计测试场景。
当初下定决心要学大数据的时候其实也是为了 AI 考虑的,所以动机上并不是冲着大数据产品去的,只是学着学着其他人就觉得我擅长这东西,有需要的时候就拉我去大数据产品里被迫营业了 , 这搞的我大数据上的造诣本来没多少的, 结果慢慢就在这些项目里锻炼出来了。。。。, 嗯有些时候应了那句话,只有自己变强之后机会才会落在你的头上。
, 这搞的我大数据上的造诣本来没多少的, 结果慢慢就在这些项目里锻炼出来了。。。。, 嗯有些时候应了那句话,只有自己变强之后机会才会落在你的头上。
当初不知道怎么学好, 先找了一本 Spark 的书啃了下来, 然后学习 Hadoop/HDFS 这些传统的分布式存储和调度软件。 后来发现把 Spark 学会后挺关键的,算是把分布式计算的基础打好了, 到了后来会发现分布式计算领域中的基本原理就是这个样子的,其他类型的技术也是按这些基本原则设计的。
高阶阶段 -- 以点到线,以线到面,完善整个大数据生态的熟练度
大数据领域对新手来说是很不友好的,尤其是对没有基础知识储备的测试人员来说, 因为我们会发现在一个大数据产品中,往往会有很多种大数据组件。 为了追求极致的批量查询性能可能就需要引入 CK 或者 impala,但这两个东西除了批量查询性能很强外其他方面就是个 shit。为了弥补点查场景就需要引入 Hbase 或者 mongo。 为了弥补通用的批处理能力就要再引入 Spark 和 HDFS 以及 Haoop(或者 K8S),如果为了一些其他要求,比如平衡查询和更新性能可能还会引入 Hive 和 kudu。 要是给企业做数据湖,还要引入 hudi 或者 iceberg。 流计算方面可能没有那么多组件,但也需要起码引入一个 kafka 和 Flink。 大数据生态的一个特点就是大部分组件为了追求某个场景下极致的性能,往往就会牺牲其他的能力。为了弥补就得再引入其他的组件进来。
所以一个新手,甚至是已经在大数据领域里钻研过一段时间的人,在一个产品中往往也会很懵。因为要面对的大数据技术是在太多了。 所以没有对产品中核心组件的通盘理解,就很难设计出好的测试方案 -- 不了解这些组件的特性, 就无法分析他们优缺点,无法理解研发的实现原理,也就无法针对性的设计测试场景和开发测试工具。 所以有一段时间我在疯狂的查询市面上主流的大数据组件的文档,了解他们的特性,并在自己负责的产品里去实践那些大数据技术。 不过分布式计算的基本原则大家都是一样的,所以以点到线,以线到面,我并没有花费很长的时间就熟悉了产品中用到的这些大数据组件。这时候我就可以针对整个系统的特性开始进行分析工作了,这个分析工作也是比较重要的, 在去年我们总监把我拉进去的一个大数据营销产品中,其中有差不多一半的非功能缺陷是靠分析出来的而不是测试出来的。 也根据一些组件的特性开发了一些工具。比如开发了 CK 的造数工具,分析 CK 性能的工具等,如下图:
总结一下
云我是真的不想写了,因为周末的时候就来得及把 AI 和大数据写完了, 刚才打开草稿发现真的没精力写云了。 那就算了吧,而且之前也有人说好像我每次都拿 k8s 来说事, 那今天就干脆不讲 k8s 了。
2 年前我跳槽后写过一个面试总结帖子, 也写过一篇职业生涯总结的帖子。 在里面我推荐 30 岁之前做加法(多去尝试不同的东西,找到适合自己发展的领域),30 岁之后做减法(选定一个领域,就只针对这个领域内的知识进行积累)。这样就能在这个领域里变得越来越专业,也越来越有竞争力(来回反复的换领域在 30 岁之后感觉就是比较差的选择了)。
然后还想说一点的就是,有些时候不是有了机会去才学习某样东西,而是学习了某样东西才有了做一些事情的机会。 我回顾了一下自己过去这些年的学习经历, 有很多都是主动的而非被动的(比如被动的指派到了某个工作岗位上),很多时候我是主动学习了一些东西后,然后去争取转到对应的位置上去,因为没有一定的知识储备,人家根本不会同意我过去做这份工作。 所以有些时候总听人说选择大于努力, 但我总觉得努力了, 才有选择的机会。 比如去年领导让我去负责一个大数据产品,其实是因为他知道我懂大数据,才会让我去的,否则我去了就是添乱的。 所以我一直以来的行动习惯都是,当了解到一个东西可能(没人能保证一定是有帮助的,也许也是瞎折腾,我曾经也瞎折腾多很多技术,花了挺多时间)是有助于我未来发展的,那我就会尝试去学习,即便最后可能是竹篮打水一场空。 我过年的时候刷了两遍飞驰人生 2,我非常喜欢里面的一段对话。 王后说 (宇强是巴音布鲁克永远的王后哈哈哈哈) 只要我们努力机会总会存在的,然后张弛回答说:这是不对的,我努力过无数次,所以我知道机会只会出现在其中的 1,2 次。 所以我现在告诉自己,该努力的时候是要努力的, 万一机会降临了呢。 而就算努力了并没有回报也没关系,我现在的日子就已经很好了,如果有回报更好, 没有我也安于当下。
最后再无耻的推销一下自己的星球: