什么是 ASR
ASR 是自动语音识别(Automatic Speech Recognition)的缩写,是一种将人的语音转换为文本的技术。这项技术涉及声学、语音学、语言学、数字信号处理理论、信息论、计算机科学等多个学科。ASR 系统的性能受到识别词汇表的大小和语音的复杂性、语音信号的质量、单个说话人或多个说话人以及硬件等因素的影响。
数据收集
经过之前的介绍我们知道在评估模型的效果时,最重要的是收集到符合场景的测试数据。ASR 系统通常可以分为特定人和非特定人识别,以及小词汇量、中词汇量和大词汇量系统。根据语音的输入方式,可以分为孤立词、连接词和连续语音系统等。此外,还可以根据输入语音的发音方式(如朗读式和口语式)、方言背景(如普通话、方言背景普通话和方言语音识别系统)以及情感状态(如中性语音和情感语音识别系统)进行分类。 所以其实大家可以看出来,要收集这么多类别的语音素材,也是非常麻烦的。我们之前这里有个兄弟,为了收集到足够的数据,专门申请下来一笔经费在平台上发布悬赏 -- 给定特定的文本,悬赏不同年龄,性别,方言等条件下的人来朗读这些文本,把语音文件发送给这位兄弟来换取钱财。 所以高质量数据的成本是不低的,记得我们前两个月有个项目, 项目上准备了 20W 的预算来采买数据。 这种数据比较难有取巧的方式,要不怎么说高质量数据是国内外模型最大的差距呢。
效果流程
- 数据收集
- 标注音频数据
- 将音频输入 ASR 算法模块得到输出结果(一个文本)
- 计算模型评估指标
评测数据集构建
这个我们上面说过,我们需要收集各种类别的数据,这部分工作十分重。不同的项目有不同的要求, 比如我这里列一个可以从网络上下载到的数据的样例:
- 新闻类数据: 覆盖 40 个央视类综合新闻以及 31 个省市的 44 个主要综合类新闻数据,每一类节目挑选一个视频,每个视频时长大约为 30-60 分钟。
- 融媒体类数据:覆盖日报和电视台类输出的 app35 个,其中主要包含了下载超百万的 app,包含有(人民日报,大众日报,北京日报,湖北日报,广州日报,河北日报,工人日报,河南日报,光明日报,中国青年报,南方都市报,新华社,南方周末,新民,羊城派,央视频,荔枝新闻),这一类 app 每个挑选 100 个视频素材,其余低下载量的选择 20 个素材(主要依据下载量的比例来确定挑选的测试数据比例)
- 体育类,综艺类,影视剧类等等。。。。要搞数据太难了, 好在我们团队有专门的数据组。
数据标注规范
主要需要标注的内容有:文本转写,标点符号转写,说话人区间分离,无效数据区间标注。 这里还是只给一些规范上的样例:
- 转写内容与实际发音内容一致,转写的字正确率要达到 99%;但是,对于因为口音或者个人习惯导致的音变,仍按照原内容转写。(比如把 “银行”,读成了 ying 2 hang2,按照 “银行” 转写;另外,对于多音字或实际生活中易混淆的字,按照原内容转写:比如办公室的 “室”,有的人读 shi3 ,有的人读 shi4 ,请按照正确的字 “办公室” 转写即可)
- 转写内容的完整性要与实际发音一致,不得删减;(如发音为:我是北北京人;“北” 字有重复现象,那转写的时候要写成:我是北,北京人。)
- 转写遇到人名时,按照常用字词表示即可,没有特定的字词规定。如:李珊、李山、李姗等;
- 遇到数字,按照数字的汉字写法 “一二三” 形式,而不是 “123” 阿拉伯数字形式;(如果有电报读法,如幺幺零等,按照电报读法进行转写;)
- 遇到网络用语时,如实际发音是 “灰常”“孩纸”“童鞋”,也应该写成 “灰常”“孩纸”“童鞋”,不能写成 “非常”“孩子”“同学”。
- 儿化音:
- 原音频有儿化音,则转写中应带有 “儿”,以 “哪儿” 为例,如果读出了儿化,则转写为 “哪儿”;
- 原音频无儿化音,则转写中不应带有 “儿” -仍然以 “哪儿” 为例,如果发音人没读出儿化音,则转写为 “哪”;
- 语气词: 音频中说话人清楚地讲出的语气词,如 “呃 啊 嗯 哦 唉” 等,要按照正确发音进行转写。
- 英文:
- 对于拼读格式(包括拼出的字母,首字母缩写词或者一些缩写),每一个被拼出的字母都应大写加空格。例如:M A R Y 而不是 mary 或者 MARY
- 商标、品牌、注册名等都应以其原有、专有的格式出现, 例如: Hotmail dot com 而不是 hot mail dot com
- 个别字词不确定的,在有意义的情况下,尽量用同音字代替。实在无法转写的,这句话切出无效。 -多人说话重叠部分,若能写出主说话人的内容,在这部分前后标记出/multi 标签。若无法转写主说话人的内容,这整句切出来无效标/unk 标签
因为规范比较多, 我就列一些规范上的样例, 所以大家也看到了, 数据标注的工作量也很高, 还好可以申请标注组的人力。
模型评估指标的计算
WER 字错率
WER(Word Error Rate)指的是机器翻译或者语音识别系统中,系统输出的单词与原始单词之间错误的比例。这个指标通常用于评估机器翻译或语音识别系统的性能。WER 的计算方式是将系统错误翻译的单词数除以总的单词数。
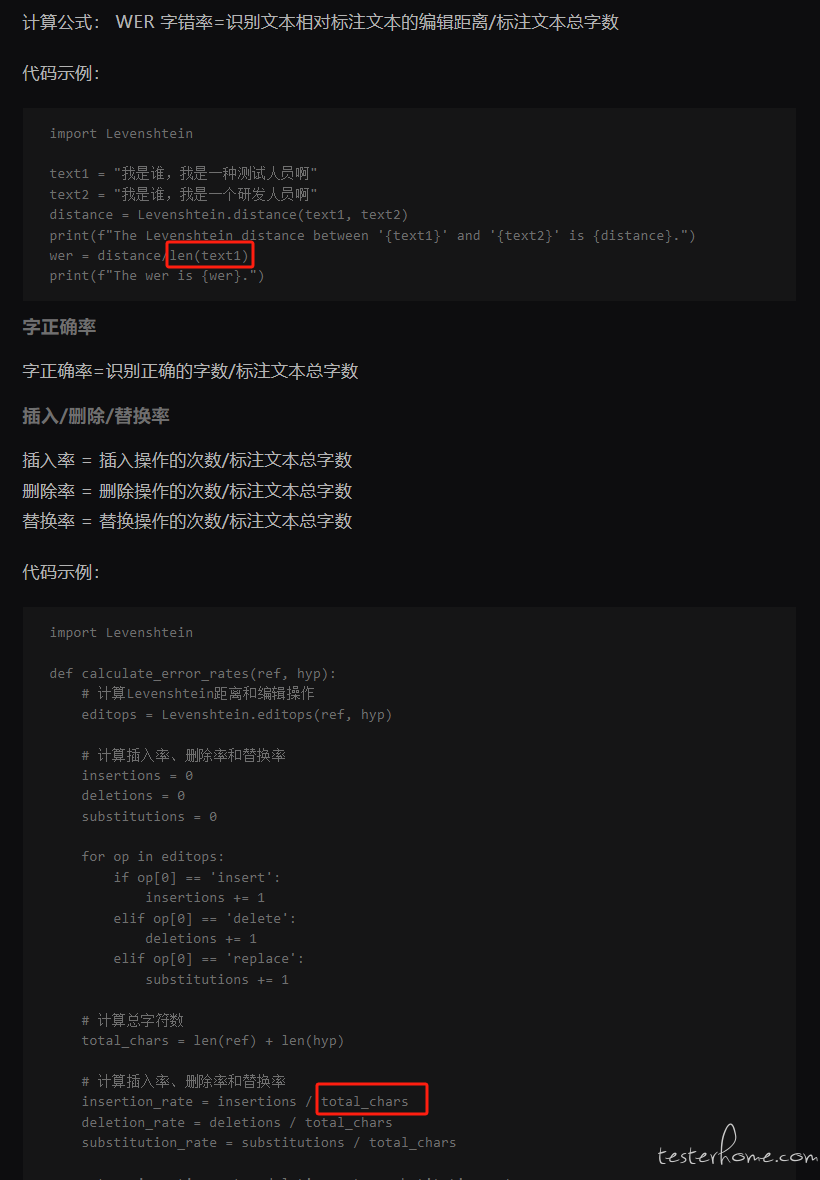
计算公式: WER 字错率=识别文本相对标注文本的编辑距离/标注文本总字数
代码示例:
import Levenshtein
text1 = "我是谁,我是一种测试人员啊"
text2 = "我是谁,我是一个研发人员啊"
distance = Levenshtein.distance(text1, text2)
print(f"The Levenshtein distance between '{text1}' and '{text2}' is {distance}.")
wer = distance/len(text1)
print(f"The wer is {wer}.")
字正确率
字正确率=识别正确的字数/标注文本总字数
插入/删除/替换率
插入率 = 插入操作的次数/标注文本总字数
删除率 = 删除操作的次数/标注文本总字数
替换率 = 替换操作的次数/标注文本总字数
代码示例:
import Levenshtein
def calculate_error_rates(ref, hyp):
# 计算Levenshtein距离和编辑操作
editops = Levenshtein.editops(ref, hyp)
# 计算插入率、删除率和替换率
insertions = 0
deletions = 0
substitutions = 0
for op in editops:
if op[0] == 'insert':
insertions += 1
elif op[0] == 'delete':
deletions += 1
elif op[0] == 'replace':
substitutions += 1
# 计算总字符数
total_chars = len(ref) + len(hyp)
# 计算插入率、删除率和替换率
insertion_rate = insertions / total_chars
deletion_rate = deletions / total_chars
substitution_rate = substitutions / total_chars
return insertion_rate, deletion_rate, substitution_rate
# 示例
ref = "我喜欢吃苹果"
hyp = "我欢吃橙子啊"
insertion_rate, deletion_rate, substitution_rate = calculate_error_rates(ref, hyp)
print(f"Insertion rate: {insertion_rate:.2%}")
print(f"Deletion rate: {deletion_rate:.2%}")
print(f"Substitution rate: {substitution_rate:.2%}")
总结
可以看到通过 Levenshtein 库我们可以比较容易的把效果的评测自动化起来, 当然前提是数据和标注都准备好~。 所以还是那句话,在人工智能领域中工作的人, 大部分时间都是花在数据上。
最后想看更多手把手教程的同学可以加入我的星球: