
移动测试开发 一种让 ChatGPT 的回答既实时又精准的方法
GPT-3 是 “暴力美学” 的一次胜利,其最大拥有 1750 亿参数,训练数据达到 5000 亿个词,它的训练是一个无监督任务,它生成的内容已经相当接近人类的创作了,但是 GPT-3 并不是以对话的形式交互的,GPT-3 依赖于小样本学习和零样本学习输出优质结果,使用门槛较高。ChatGPT 是由 OpenAI 在 GPT-3 基础上利用有监督微调和人工反馈强化学习的方式训练的聊天机器人,ChatGPT 能在三个月时间达到月活过亿的原因之一是,其使用方式简单(问答或者多伦对话),人机交互的方式与人和人之间交互方式非常相近。但它不是无所不能的,ChatGPT 的 “涌现能力” 对于文案创作者来说是一种福音,但是对于技术人员来说并不是一件好事,比如利用 ChatGPT 写代码、寻找漏洞修复建议和代码审计等等,这些是不允许 “涌现” 出现的。本文提供一种方法能在智能客服、信息检索、专业问答等场景下避开这个问题,此方法的上限取决于你手头拥有的资源。该方法将 AI 做事的方式更像人类。
ChatGPT 使用问题
实时性差
ChatGPT 的一大优点就是使用方式简单,完全可以把它当做一个无所不知的 “人”,直接问就可以。但是我们把 ChatGPT 当做搜索引擎用的时候,我们很多情况下需要一个实时信息。我们知道,ChatGPT 是用过去的数据训练的,所以它的知识是有时间限制的。比如我想知道全球最新的国家人口排名。使用 ChatGPT 获取的结果:
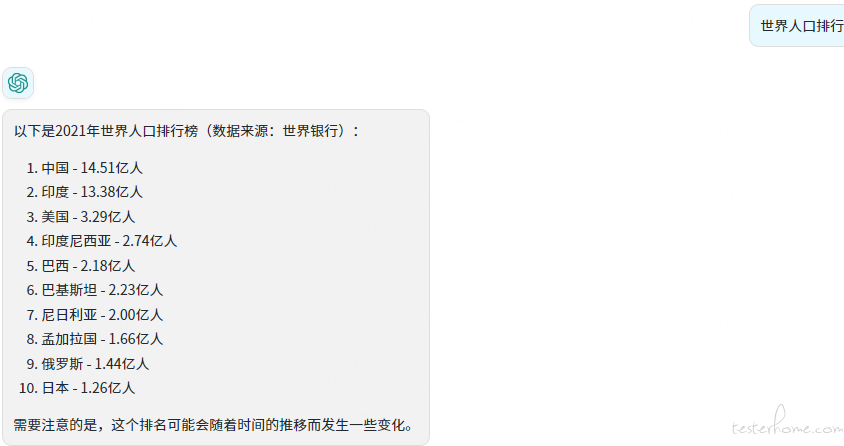
这个结果先不谈准不准确,它给的是 2021 年的数据。ChatGPT 在回答事实性的问题的时候,所回答的知识是有年限的,它不能给出这种没见过的类似具体数字的回答。使用 搜索引擎的搜索结果(这张截图获取的时间是2023年5月5日17:44:47):
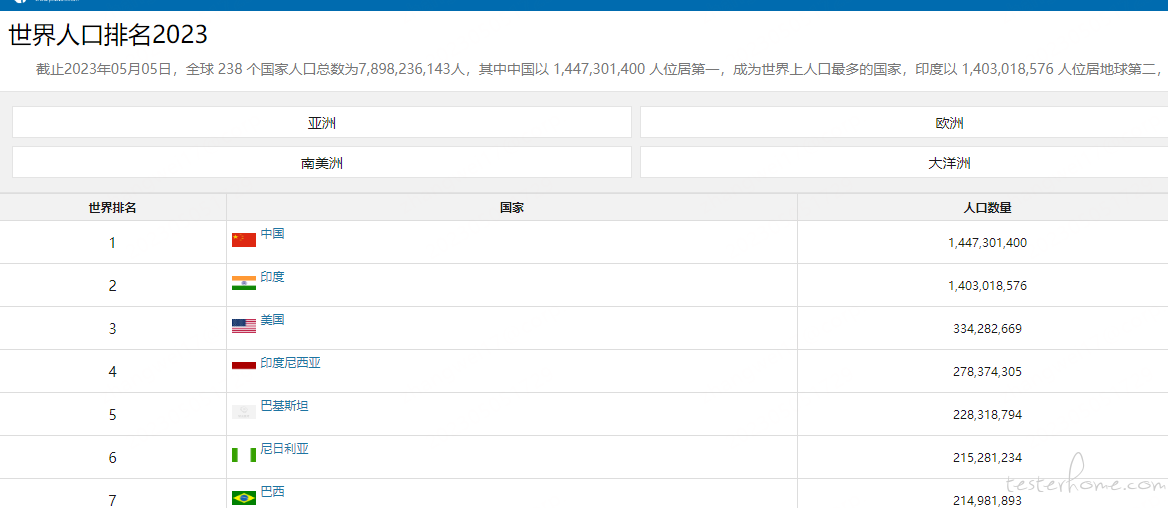
准确性存疑
先看一个这个安全方面的问题:

ChatGPT 的回答虽然有模有样,但是内容都是错的呀。这是一个在 MySQL Server 中的 InnoDB 组件中发现的漏洞。在提问者不知道的情况下,可能会相信这个回答并按这个建议去进行一些操作了,显然在这种场景下 ChatGPT 帮了倒忙。因为我们很难判断这个回答是不是真的。
解决方案
方法介绍
人们可以在日常学习、工作和生活中保持尽可能低的犯错概率的原因之一是:人是可以查阅资料的。但是随着行业的发展,文档的数量越来越多,并且文档的内容也越来越复杂,人们在查阅资料时要花费大量的时间。随着数字经济的发展,各行各业开启数字化进程,这时候我们就可以用计算机实现信息检索来提高人们查阅资料的效率。
机器阅读理解是自然语言处理(NLP)的一个任务,它常常在对话系统、搜索引擎中应用,能大大提高信息检索的有效性。其中生成式阅读理解(自由问答)是最复杂,也是最适合现实应用场景的任务。阅读理解一般做法是,我们训练一个 AI 模型(比如深度神经网络),当我们对这个模型提问的时候,它会自动帮助我们查找参考资料,并根据这份参考资料来给我们准确的答案。
因为 ChatGPT、GPT-4 是当前自然语言理解能力最强的 AI 模型,这时候我们就可以将它们当做我们的 AI 模型,让它去帮我们阅读资料回答问题,这样在解决了人们查阅资料费时和阅读资料费力的问题的同时,解决了 ChatGPT 的实时性和准确性的问题。
例子
整个过程的流程图如图:
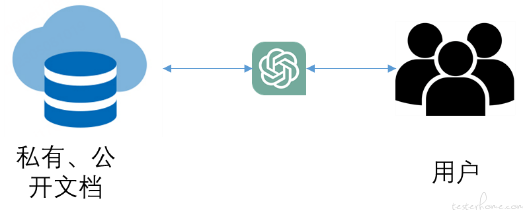
步骤一:根据用户提问来搜索相关文档,比如我们提 “CVE-2021-2429 漏洞修复建议”,先根据这个提问利用搜索算法找到这个漏洞的参考文档。我在自己的数据库中找到了这个漏洞的相关信息:

步骤二:参考文档和用户的提问整合到 prompt 中,例如:

步骤三:多轮对话功能不受影响。
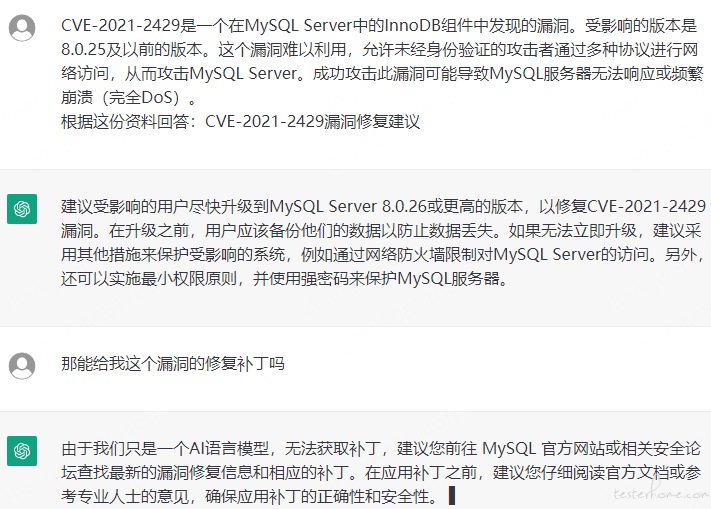
这下可以看到,ChatGPT 回答的修复建议是对的。
这种方法将 ChatGPT 回答问题的压力放到了文档搜索这方面,对于有明显特征的问答,例如 CVE 漏洞的编号,这种搜索一般是不会出错的。当我们给 ChatGPT 的参考资料越详细,那 ChatGPT 的回答越详细。ChatGPT 在这整个过程中做的事情是代替了我们去读这份资料,根据这份资料直接给了我们问题的答案,我们不再需要一点点的读一些复杂的参考资料寻找解决方案了,这就大大提高了我们的学习和工作的效率。
小结
如果把 ChatGPT 当做一个人,那它犯错误是很正常的,人都会犯错。但是人与 ChatGPT 不一样的是,人是会 “打小抄” 的!就比如上面我问的 CVE 漏洞的问题,如果我是向安全从业人员提问,他们可能不记得这个漏洞具体的信息了,但是他们可以迅速查阅资料并找到我想要的答案,犯错的概率是极低的,但是 ChatGPT 不能查资料,当它不知道的时候当然会回答得不正确了。再比如我们程序员,写稍微复杂一些的程序默写出错的概率很大,但是花 1 分钟去谷歌搜一下看看就能写出漂亮的有价值的代码!
同样的道理,我们给 ChatGPT 输入一些参考资料,然后再问他关于这些参考资料的问题,那它就不会出错。
ChatGPT 的 1750 亿参数在训练时并不是简单地 “记住了” 训练数据的内容,更重要的是它学习到了自然语言中知识之间的关联(比如阅读理解是 ChatGPT 学习具体知识时学习到的一种 “看不见” 的能力),这个学习方式跟人类是极其相似的。我们人类大学毕业后,当有人问我们专业问题的时候,我们给不出具体的问题解决的细节是很正常的,但是我们对这个问题是有概念的。比如让我去给他们实现一个随机森林算法,我是知道随机森林原理并且知道实现这个算法的框架有哪些,然后我还是需要去查阅一些参考资料写出一份完整的可用代码,这个过程花费的时间取决于我的认知水平,也就是 ChatGPT 学习到的知识之间的关联。这么看来跟我读书时学习专业知识时的理解的过程是神似的。
ChatGPT 相当于人类大脑,它是没有四肢或者其他器官的,这就限制了 ChatGPT 的使用,只能与它对话,但是当我们给 ChatGPT 装上四肢(比如本文方法让 ChatGPT 有了查资料的能力),那它能做的事情就多了。