
这是鼎叔的第三十九篇原创文章。
行业大牛和刚毕业的小白,都可以进来聊聊。
欢迎关注本人专栏和微信公众号《敏捷测试转型》,大量原创思考文章陆续推出。
上篇请查阅:聊聊推荐系统的评测(上)https://mp.weixin.qq.com/s?__biz=MzkzMzI3NDYzNw==&mid=2247484053&idx=1&sn=1da210b85a14449ce024da7cde732fa3&scene=21#wechat_redirect
下篇,我们聊聊推荐系统如何冷启动,它如何利用用户打标签,利用上下文信息和社交网络,以及推荐系统的架构组成。
四 推荐系统如何冷启动
如何在没有大量用户数据和大量物品的情况下,让用户对推荐结果满意,从而使用它,这就是冷启动问题。它主要分为三种情况:为新用户做个性化推荐,把新物品推荐给可能对它感兴趣的人,以及网站刚发布时如何让用户体验个性化推荐。
应对冷启动的方法有两种:
1)暂时提供非个性化的推荐,如热门排行榜,或由专家推荐。专家可以根据对物品的大量定义好的分类特征,进行专家人工标注分类,以供用户自行挑选类型。
2)利用用户个人注册信息(主要是人口统计学特性),社交网络好友信息。或者让用户给物品打兴趣标签。如果想让用户给物品打标签,那这些物品集合的特征应该是比较热门的(不了解就无法打标签),有代表性和区分性,覆盖多样性,用户对物品往往有 “感兴趣”,“不感兴趣”,“不认识” 三种反馈。
对于某些网站,推荐列表可能是新用户获得信息的主要途径,那第一推动力从哪来?网站可以采用随机展示物品的方式。如果新物品不展示给用户,用户就无法对它产生行为,因此系统可以利用物品的内容属性,频繁更新物品相关表。
物品的描述内容包含一系列的实体关键词(比如电影物品的实体词有导演,主演,类别,发行时间,发行公司等),可以把它们组成关键词集合,排名计算权重,生成关键词向量,物品内容的相似度就可以通过向量之间的余弦相似度来计算。
五,利用用户打的标签
除了借助用户协同过滤和借助物品协同过滤,推荐系统还可以利用特征(属性关键词)把用户和物品联系起来,我们也称之为 “标签”。前面介绍的专家打标签,称之为 PGC,如果是普通用户打标签,就是 UGC。
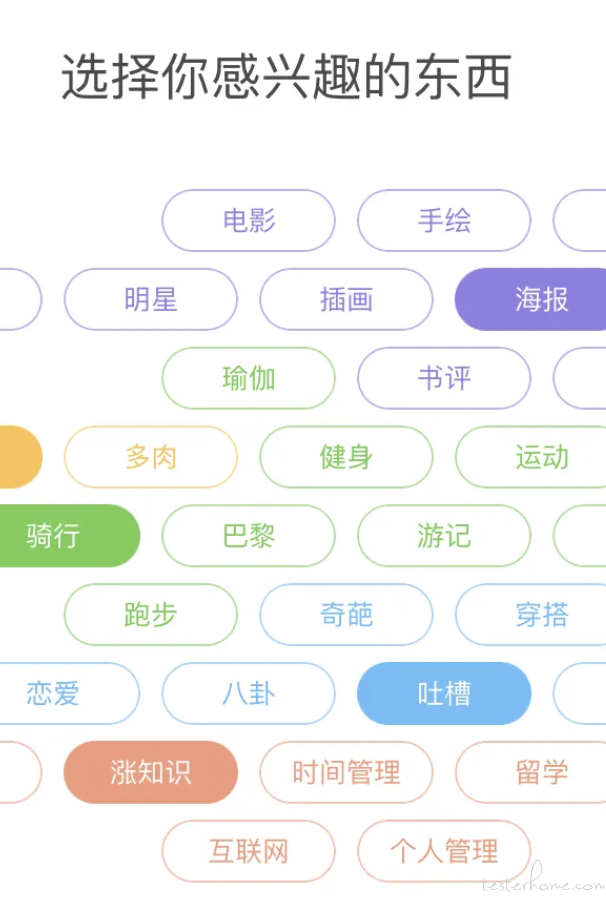
标签系统带来的收益包含:让用户表达自己,并在用户打标签的同时也给 TA 推荐和该标签有关物品,帮助用户更容易发现自己的兴趣物品。不同标签下的推荐结果,本身就带有了可解释性。
由于热门标签对应的是热门物品,因此在推荐权重计算公式中要对热门程度进行惩罚,否则推荐结果的新颖性不足。
用户和物品形成的标签矩阵,通常是很稀疏的,可能需要扩展。即,把相似的标签也加进来,最简单的就是同义词。如果两个标签总是同时出现在很多物品的标签集合中,那它们也有很大的相似度。
扩展后的标签推荐算法,其准确率和召回率确实得到了提升,但可能会略微降低覆盖率和新颖度。
最后,不是所有标签都代表了用户的兴趣,有必要对某些标签进行清理,比如去掉一些情绪化词语,如 “没意思”(用户不会对 “没意思” 感兴趣);去掉语法格式略有变化的同义词。也可以让用户 “众包” 指出当前标签的不当之处。
标签集合/标签云可以帮助用户找到多样性的结果,因为用户每天的兴趣会有一定程度被影响,标签云就可以起到提醒变化的牵引作用。如果兴趣从来不变,那么多样性就很差了。
在用户浏览某个物品时,标签系统实时推荐了标签清单供用户确认,这种方式降低了用户输入的成本,也借助众包的力量提高标签库的质量。
那么,标签清单里的标签怎么选择?有的系统直接选择热门标签,有的系统给出该物品身上被打的最多的标签,还有的系统兼而有之。
六 利用上下文信息
以上推荐算法都忽略了重要的一点,用户是处于一定的上下文的,上下文对于推荐效果非常重要,它包括时间,地点,用户心情,和谁同伴等等。比如,不同的季节应该推荐不同时令的服装;正在 A 城市的用户,不应该被优先推荐 B 城市的餐厅。
1 时间上下文。
时间会带来用户兴趣的变化。大学时候的兴趣,到了工作后可能就变化了。物品也是有时效性的,不同类型的物品受时间影响不同,比如新闻的时效性非常强。在消费领域,季节性和节日是一个非常明显的影响,不同的日子会带来消费的周期性变化。
基于时间维度信息,推荐系统就变成实时性系统,用户行为动作也变成了时间序列。因此系统需要搜集每天用户的数据增长情况,物品变化情况和用户访问情况。实时推荐系统需要实时响应用户新的行为,让推荐列表满足用户不断变化的需求。因此,每次推荐前都会根据用户之前的行为完成实时计算。
度量物品时效性的指标可以是:平均在线天数(每天至少被一个用户产生过行为即为在线),相隔 N 天物品流行度的平均相似度,下降越快说明时效越强。
推荐如果缺乏时间多样性,用户的满意度会逐步下降,所以,即使没有发生用户新的行为,推荐系统也应当经常变化一下结果,加入一些随机性,并对之前看到的推荐物品进行适当降权,还可以轮换不同的推荐算法。
推荐算法还需要平衡用户的短期行为和长期行为,既体现短期变化,又有预测兴趣的延续性。只有经过多次的实验才能找到最佳力度的时间多样性。采用的模型可以是 “最近最热门”(引入时间衰减参数),或者让用户很短时间内喜欢的物品之间拥有更高的相似度。比如昨天看过的电影,比上个月看过的电影,相似度统计价值大很多。
对于用户兴趣协同的算法,两个用户同一时期喜欢相同的物品,那兴趣相似度也应该更高。同理,我们也应该给用户推荐和他兴趣相似的用户最近喜欢的物品,比如给球迷用户推荐同一个球迷圈用户刚看过的新闻。
2 地点上下文。
有时间,就有地点。地点作为重要的空间特征,也是重要的上下文信息。用户在不同的地方兴趣可能也会不同。有些物品的空间属性很强,如餐厅,办公室,景点等,一个用户往往在附近地点活动,有些空间属性弱,比如文章,音乐,电影等。
我们可以发现不同地方的用户,兴趣差异比较大。比如对音乐个性化推荐而言,国家特征的影响远大于年龄,性别。基于位置的推荐就是把可能感兴趣的物品和用户的距离作为计算权重,注意这个距离是交通距离,不是直线距离。
六 利用社交网络
我们可以从这些地方获得用户社交信息:1 邮箱后缀就是隐性的社交关系,可以用来做社交用户的冷启动。2 用户注册信息,如在同一家公司或学校的用户。3 用户的位置信息。4 论坛的讨论组。5 IM/SNS 好友列表。
社交网络中用户的关注和被关注(或者称为入度和出度),是满足长尾分布的。
基于社交网络推荐,我们既要考虑两个用户之间的兴趣相似度,也要考虑两人的熟悉程度,因为越熟悉的朋友才会有越信任的关系。熟悉程度可以用两人的共同好友比例来评估。
在实际环境中,要实时拿到用户所有好友的历史行为数据,是非常困难的,我们可以只拿出用户相似度最高的少数好友来查询行为接口。另一个办法是为每个用户做一个消息队列,一旦有用户产生新的行为,其所有好友的消息队列就会记录该行为,当该用户访问推荐系统时,就根据最新消息队列重新计算推荐物品的权重。
因为社交网络推荐并不能提高预测准确性,而是根据好友推荐提升信任度,用户满意度也会高于文章前面介绍的协同过滤算法。
七 推荐系统的架构
所有的推荐系统基本都是由三个部分组成:前台展示页面,后台日志系统,推荐算法系统。因此,推荐系统要发挥大的作用,还依赖界面展示和用户行为数据。只有快速拿到大量用户的新行为,推荐系统才能实时地适应用户当前的需求,给出有效的实时推荐。
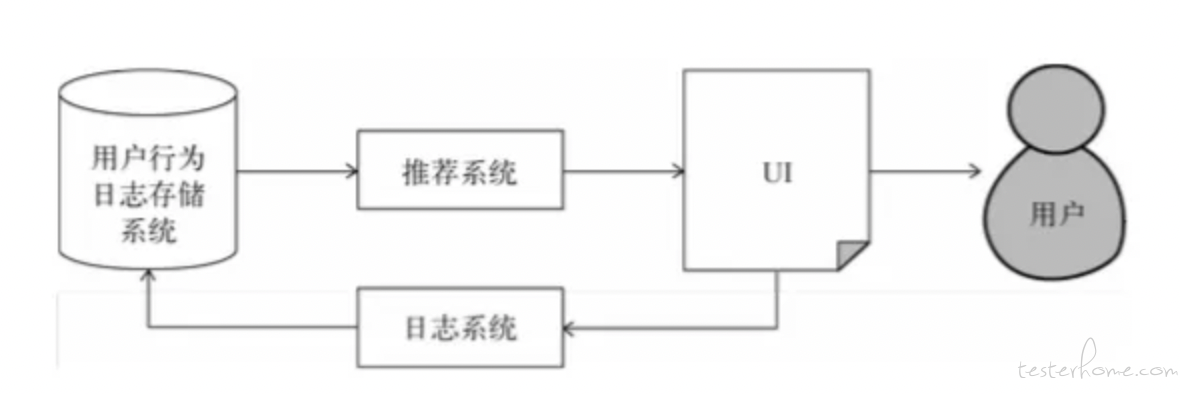
当用户加入后,推荐系统需要为用户生成特征,然后对每个特征找到相关的物品,从而生成推荐列表。用户的特征除了人口统计学特征外,还包括操作行为特征和话题兴趣特征。
一个推荐系统要完成的商业任务目标也会是多样的,可以是推荐最新产品,也可以是推荐商业广告,还可以是多样类型结果输出,也可以是根据上下文特征来推荐。统筹考虑各种特征和任务,会导致系统设计很复杂。因此我们可以用多个推荐引擎组合成推荐列表,按照一定的优先级规则,这样可以方便的增删,满足商业需求;也可以获取用户对于具体推荐引擎的偏好。
所谓推荐引擎,主要是提取用户的特征及其权重,获得初步的特征 - 物品相关推荐结果,然后根据商业产品需求对结果进行过滤(去掉不符合要求的,或低质量物品),按照一定的排序规则展示出来。
结尾:设计推荐系统的经验教训
用户遇到信息过载才需要推荐系统,你确定你的产品真的需要推荐系统么?
商业目标和用户满意度不一定一致,但是用户满意度一定符合企业的长期利益。
不用担心冷启动问题,互联网上有各种你需要的数据,另外,用户只要喜欢你,就会不断贡献数据。
使用正确的用户数据对推荐算法更重要,数据分析决定了如何设计模型,而算法只是努力优化模型。
找到相关物品很容易,但是如何展现给用户是很困难的,不应该为了推荐而推荐。
时刻关注推荐系统的性能。