
这是鼎叔的第三十八篇原创文章。
行业大牛和刚毕业的小白,都可以进来聊聊。
欢迎关注本人专栏和微信公众号《敏捷测试转型》,大量原创思考文章陆续推出。
针对推荐系统的测试,通常集中在简单的功能验证和体验,如果要深度评测一个推荐系统是否足够 “好”,则需要学习推荐系统的设计原理和算法知识。我们从推荐系统的热门类型和推荐目的开始聊起,思考哪些是好的评测方法及其指标。
本篇参考了《推荐系统实践》一书的观点,作者是项亮。
随着互联网网络的蓬勃发展,我们从信息匮乏时代走向信息过剩时代,对于消费者而言,如何从海量信息中找到自己感兴趣的信息,是非常困难的事。而对生产者而言,如何让自己的信息脱颖而出,被目标消费者关注,也是非常困难的。
一 什么是推荐系统
推荐系统就是让用户和信息自动产生联系,形成生产者和消费者的商业双赢。不同的推荐系统利用了不同的联系方式,比如利用好友来推荐,利用用户个人信息来推荐,利用热门排行榜来推荐等。
搜索系统和推荐系统的差别在于,搜索引擎满足的是用户有明确目的时的查找需求(有搜索关键词),而推荐系统让用户没有明确目的时也能获得它们感兴趣的新内容。
总体来看,基于用户个人信息反馈的个性化推荐系统是行业的主流,即打造所谓的 “千人千面”,体现在各种业务领域如下:
电子商务,是应用 “推荐系统” 最广泛的平台。比如推荐 “你可能感兴趣的” 商品内容,评分和推荐理由。类似,还有 “购买了此商品的用户还买了以下产品”,通过打包销售给予额外折扣,刺激消费。
电影视频网站。推荐用户可能喜欢的电影,包含推荐理由。而对于内容评价的分数,往往有多档,以便拉开差距。
音乐网站。当用户没有明确的听歌需求时,把音乐当成一种背景乐来播放,可以推荐符合用户当时心情的音乐。音乐推荐有一定独有的特点:1 物品空间大,种类多。2 消费歌曲费用少。3 听歌耗时少,重复率高。4 听歌和环境相关,和歌单顺序相关。5 不需要全神贯注 6 高度社会化。
社交网络。主要是利用社交网络信息推荐物品,在信息流推荐会话,给用户推荐好友,这三种应用。
LBS 服务推荐。
邮件个性化推荐,推荐邮件放入优先阅读信箱,节约用户时间。
个性化广告,目前已经成为了一门学科 - 计算广告学。主要有三种投放技术:上下文广告(通过正在浏览的网页内容),搜索广告(根据搜索目的投放),个性化展示(基于用户兴趣)。
二 推荐系统的评测
好的推荐系统一定要满足三方面的利益:网站,内容提供方,用户。预测准确度是推荐系统最重要的指标之一,但是光预测准确是不够的,能否增加潜在销量才是商业成功的标志。好的推荐系统能够帮助商家把埋没在长尾中的好商品推荐给对它们容易产生兴趣的用户。
要获得推荐系统的评测指标,主要使用三种实验手段:
离线实验,从实际的日志系统提取数据集,不需要真实用户参与,直接计算结果。
用户调查,让真实用户完成任务,搜集满意度反馈(利用 “满意”/“不满意” 的反馈按钮,也可以根据点击率,用户停留时间,转化率等指标判断)。实验环境的用户实验不一定反映了真实环境的用户行为结果。
在线实验。通过 AB 测试区分流量,收集真实的日志数据,确定新算法的指标表现是否由于当前算法。
主要评测指标(这是本篇的核心),除了用户满意度,还有以下指标:
1 预测准确度。把用户的历史行为数据通过时间化为训练集和测试集,根据用户行为和兴趣模型训练后,预测在测试集上的实际结果准确度,有两种预测指标:
TopN 推荐结果(针对用户的个性化推荐列表),计算公式是准确率 precision/召回率 recall。这是更有商业价值的预测指标。
评分预测。根据用户的历史评分和兴趣模型,预测他对没有接触的新物品会给出多少评分。一般采用均方根误差 RMSE 来计算。
2 覆盖率 Coverage。描述推荐系统对物品长尾的挖掘能力,可以简单定义为系统能够推荐出来的物品占总物品集合的比例。如果覆盖率 100%,意味着每个物品都被推荐给了至少一个用户。因此,热门排行榜的推荐覆盖率一定很低,因为非热门的大量物品得不到推荐。
参考信息论的信息熵,以及经济学中的基尼系数,都可以用来理解覆盖率。一个系统如果有马太效应,强者恒强(就类似贫富悬殊),导致越热门物品被推荐的概率越高,因此更加热门。而很多商业推荐系统是希望消除马太效应的。
3 多样性。推荐系统如果能满足用户大多数的兴趣点,就能增加用户找到感兴趣物品的概率。多样性和不相似性是对应的,每一种相似性的定义,就能得到相应的多样性函数。
4 新颖性。即给用户推荐它们从来没有听说过的物品。因此推荐结果中的物品平均热门程度越低,则让用户觉得新颖的可能性越高。
5 惊喜度。推荐的结果和用户历史上喜欢的物品并不相似,但是用户仍然觉得满意,即:历史相似度低,但用户满意度高。这块的学术研究还不太成熟。
6 信任度。用户是否信任推荐系统,这个只能通过问卷调查来度量了。提高用户信任度的做法,一个是让推荐系统更透明,比如提供合理解释,另一个是借助好友进行推荐。
7*实时性。部分网站时效性很重要,要及时地把物品推荐给用户,比如新闻和微博推送,给刚买手机的用户推送配件等。另一个实时性定义,是能将刚加入系统的新物品推荐给用户。
8 *健壮性,即抗作弊能力。比如商户可以通过国内雇佣很多人给自己商品非常高的评分,提升被推荐概率。推荐算法要评估健壮性,可以通过比较攻击前后的推荐列表相似性来判断。为了提高健壮性,系统可尽量采纳代价比较高的用户行为,比如购买行为的权重要远大于浏览行为。
9商业目标 **。推荐系统要考虑最终的商业目标,但不同网站的指标不同。
离线实验就是要在覆盖率、多样性和新颖性不低于基准值的情况,尽可能提高预测准确率。
三,利用用户行为数据的推荐
推荐系统从用户的行为日志中推测用户的兴趣,从而给用户推荐满足他们兴趣的物品,但是用户行为有很多种模式。显性的行为就是直接表态,如 “赞”,“dislike"按钮,差评分数等。隐性的反馈行为就藏在用户操作中,比如浏览页面的蹦失率,隐性数据量很大,但是不太明确。
仅仅基于用户行为数据设计的推荐算法称为协同过滤算法,最主要的两类是:基于用户的协同过滤,和基于物品的协同过滤。
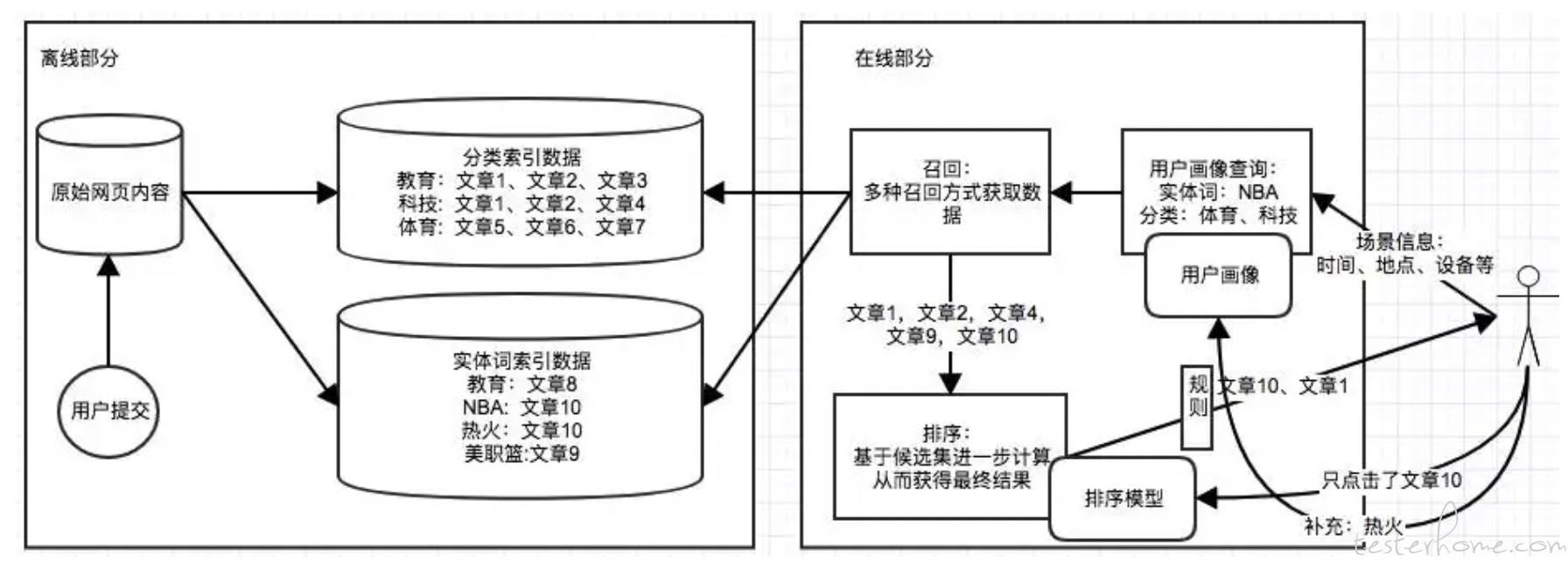
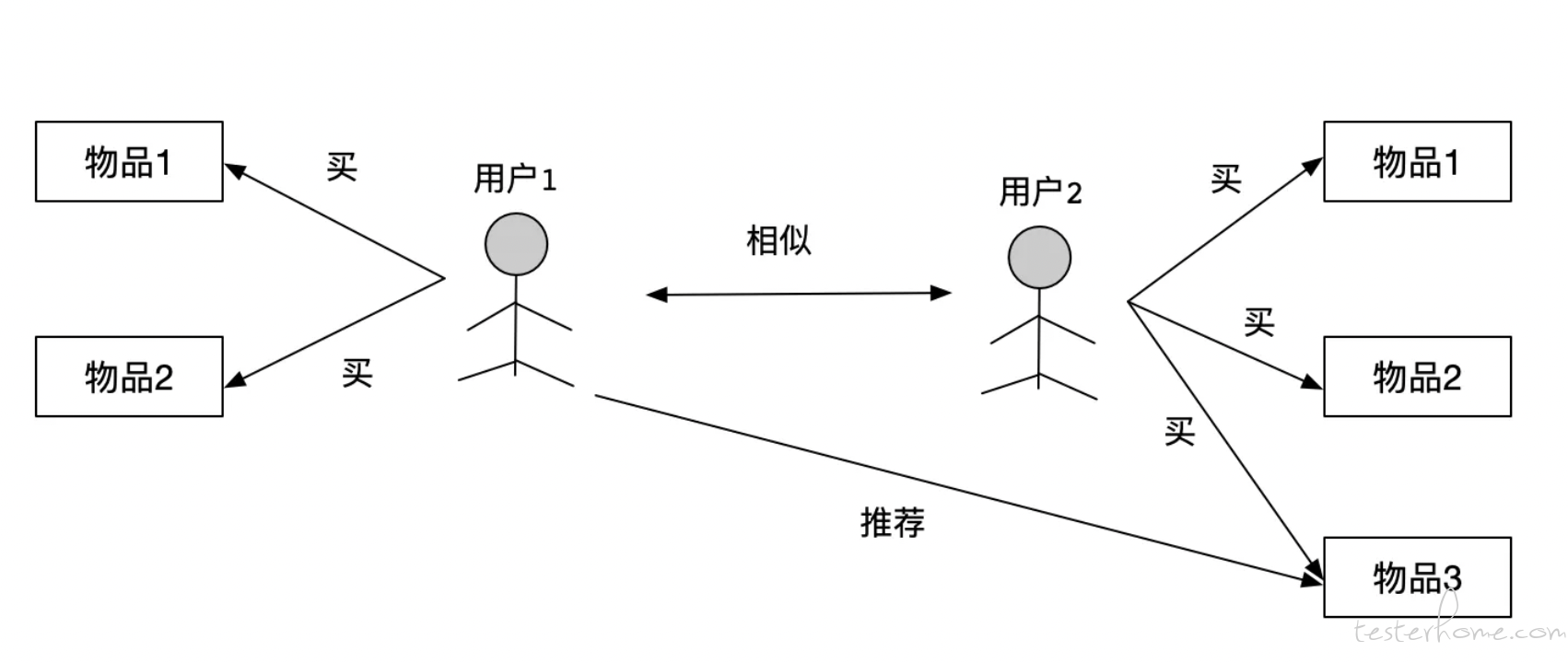
基于用户的协同过滤,主要两个步骤:
1)找到和目标用户感兴趣的用户集合。关键就是计算两个用户的兴趣相似度,可用 Jaccard 公式,或余弦相似度计算。
2)再找到集合中的用户喜欢的,但目标用户没听说过的物品,推荐给目标。
事实上,很多用户互相之间没有在同样的物品中产生过行为,所以很多计算时间都浪费了,为此,可以建立从物品到用户的倒排表,针对每个物品保存对它产生过行为的用户列表,这样效率更高。
要提升推荐算法的性能,还可以做不少改进。举个例子,两个用户都买了《新华字典》,不代表两人有共同兴趣,只是一个全民习惯。因此,两个用户采取过同样行为的物品越冷门,说明兴趣相似度越高,因此在相似度公式中要对热门物品做惩罚。此外,还可以借助让用户众包(点赞或者踩)的方式改进推荐效果。
基于物品的协同过滤,是业界应用最多的算法。
基于用户的协同过滤,其运算时间复杂度和空间复杂度与用户数的增长成平方关系,亚马逊基于物品的算法认为,物品 A 和 B 的相似度,就是因为喜欢 A 的用户大都也喜欢 B,因此可以利用用户的历史行为对推荐结果提供解释。
计算物品之间的相似度时,同样可以惩罚热门物品的权重,因为热门物品和很多物品都会相似。
除此之外,我们也要考虑用户自身活跃度的影响,比如卖书网站的一个用户,买了网站 50% 品类的书,因为自己要开书店,这就并非从个人兴趣出发,但是他和很多用户都会有相似度重合。实际上他对买书相似度的真实贡献,远远比不上买了十几本书的普通爱好者。因此,相似度计算公式还要对活跃用户做计算惩罚。
为了进一步提高准确率,我们还可以对相似度计算矩阵,按最大值归一化,同时还能提高覆盖率和多样性。因为物品总是属于多种不同类型,每一类的物品内部联系通常比较紧密,不同类别中的相似度可能不同,比如纪录片类型和动画片类型。归一化以后,不同类别中的高相似度物品被推荐的概率大致相等,推荐出纪录片和动画片的概率相当,因此覆盖率和多样性就提升了。
热门类别中的物品相似度比较大,如果不归一化,就会推荐热门类别中的物品,导致推荐物品的流行度越来越高,覆盖率则降低。
不同网站,选择基于用户的协同过滤,通常是侧重于反馈用户兴趣小群体的热点;而选择基于物品的协同过滤,则是看着用户自己的兴趣传承,个性化更突出。比如新闻网站是前者,看新闻的用户都是喜欢热门新闻,个性化不太突出,因此,推荐有相似爱好的小圈子正在看的新闻,更有价值。
从技术方面考量,新闻网站要求物品更新的速度非常快,远远快于新用户加入的速度,而基于物品的协同过滤,维护物品相关度的表格更新速度不足,因此使用基于用户协同过滤算法利大于弊。
选择后者(基于物品的协同过滤)网站,用户兴趣都是稳定持久的,比如图书,电商和电影,不太依赖对流行度的判断。此类网站用户量巨大,因此维护用户相似度的矩阵计算开销就很大。
隐语义模型
如果两个用户的显性特征(兴趣和历史物品)都不相同,如何找到用户兴趣和物品的联系呢?
我们首先要得到用户的兴趣分类,再从分类中挑选他可能喜欢的物品。
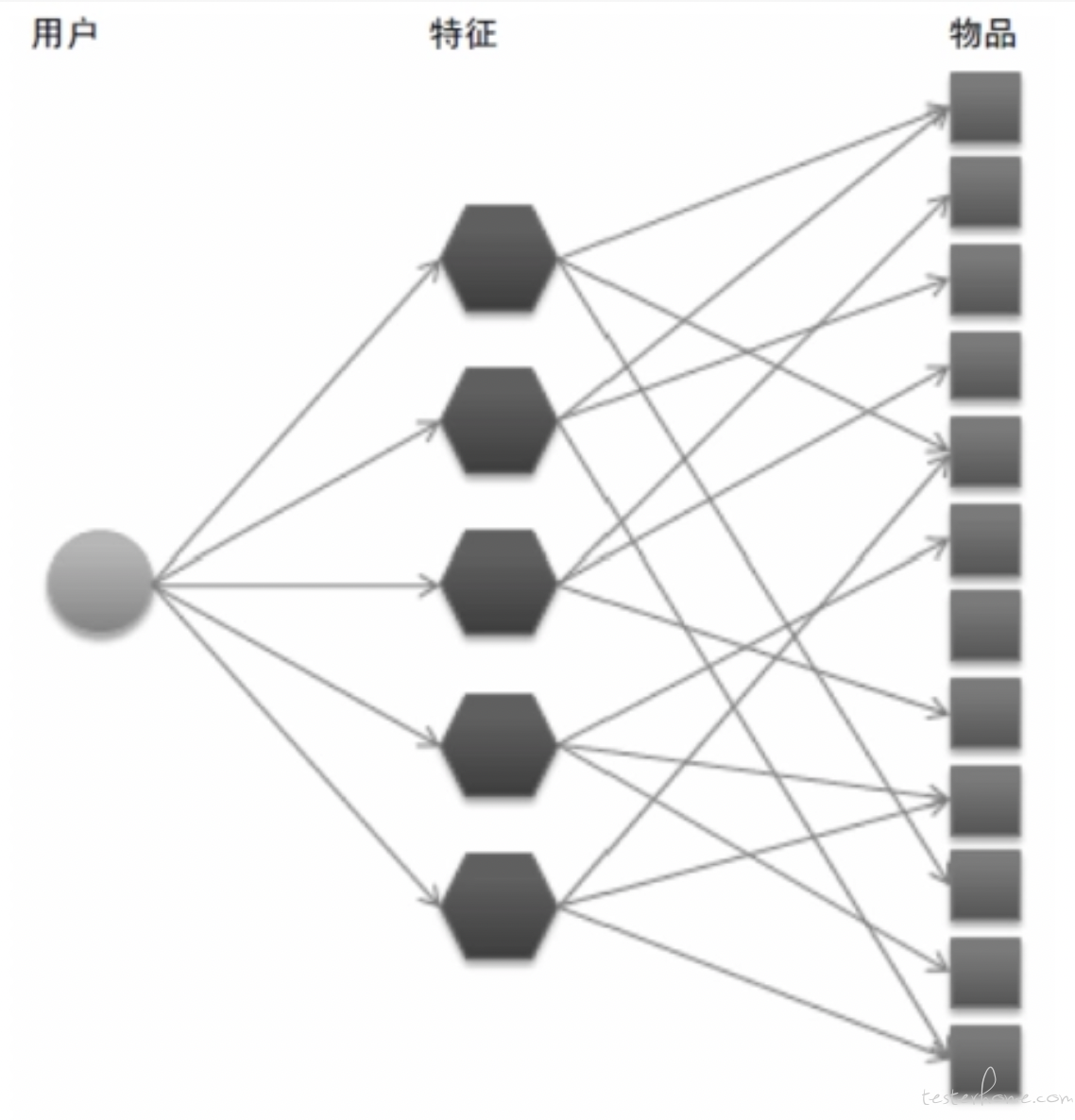
如何给物品分类?
指望编辑来人工分类,在互联网时代不太可行,因为编辑不能代表广大用户的意见,也没法做好精细化分类,以及多维度分类,更没有办法决定分类权重。
因此,我们还是得从数据出发,自动分析(隐含语义分析技术),看物品被多少用户喜欢,指定分类数量,统计权重。但是这种技术没有推荐解释性,也不能进行在线实时推荐。