
这是鼎叔的第九篇原创文章。
行业大牛和刚毕业的小白,都可以进来聊聊。
欢迎关注本人专栏和微信公众号《敏捷测试转型》,大量原创思考文章陆续推出。
鼎叔在 MTSC-中国移动互联网测试开发大会,以及深圳敏捷之旅中,分享了《提升用户体验的评测方案》议题,本文是相关系列主题文章的第五篇。
针对市场竞争激烈的产品,相对于测试缺陷情况,高级管理者往往更关心产品的核心体验竞争力如何,差距在哪里。测试通过可测性分析得到了一系列用户体验有关的客观指标。那如何给出竞品对比的评测结论和改进建议呢?
相关文章请看:聊聊测试团队在 NPS 变革中可以做什么 https://mp.weixin.qq.com/s?__biz=MzkzMzI3NDYzNw==&mid=2247483735&idx=1&sn=468404a266468ff7d06a65e6c779b604&chksm=c24fb435f5383d23ee9980909196ef90f69de2bb0ef2e782e9477d85b0e2fc26768840504138&token=1853387583&lang=zh_CN#rd,聊聊用户体验与常规缺陷的异同 https://mp.weixin.qq.com/s?__biz=MzkzMzI3NDYzNw==&mid=2247483721&idx=1&sn=d6542a6818ab81fe2786afe5155b2c88&chksm=c24fb42bf5383d3dfca225cebaf9bca5145977e1005df8808a1537be6286b5c0f984bd6844ed&token=1853387583&lang=zh_CN#rd
第一节 KANO 模型
KANO 模型是对用户体验进行分类和排序的知名质量度量模型,体现了产品指标和用户满意之间的非线性关系,产品服务的质量特性可以分为五类:
必备质量- Must-be Quality 理所当然的需求,必须满足,比如网络连通率,通话信号正常,APP 稳定不崩溃,视频画面流畅度,待机时间足够长等。
期望质量- One-dimensional Quality *用户满意度和该质量满足的程度成正比。企业在这块应该力争超过竞争对手。比如客户投诉解决满意度,搜索结果命中率等等。
*魅力质量- Attractive Quality ** 不会被用户过分期望的需求,但随着满足顾客期望程度的增加,顾客满意度急剧上升,产生惊喜感,提高了忠诚度。如免费增值服务,减免常规费用(免邮费,手续费),惊喜礼物,VIP 服务等。
*无差异质量- Indifferent Quality * 不论提供与否,对用户体验无影响,如与用户需求无关的赠品,优惠券等等。
** 逆向质量- Reverse Quality 会引起强烈不满或低水平满意的质量特性,因为并非所有消费者都有相似喜好。比如科技产品有一些进阶功能对普通用户完全用不到,反而增加了界面复杂性。
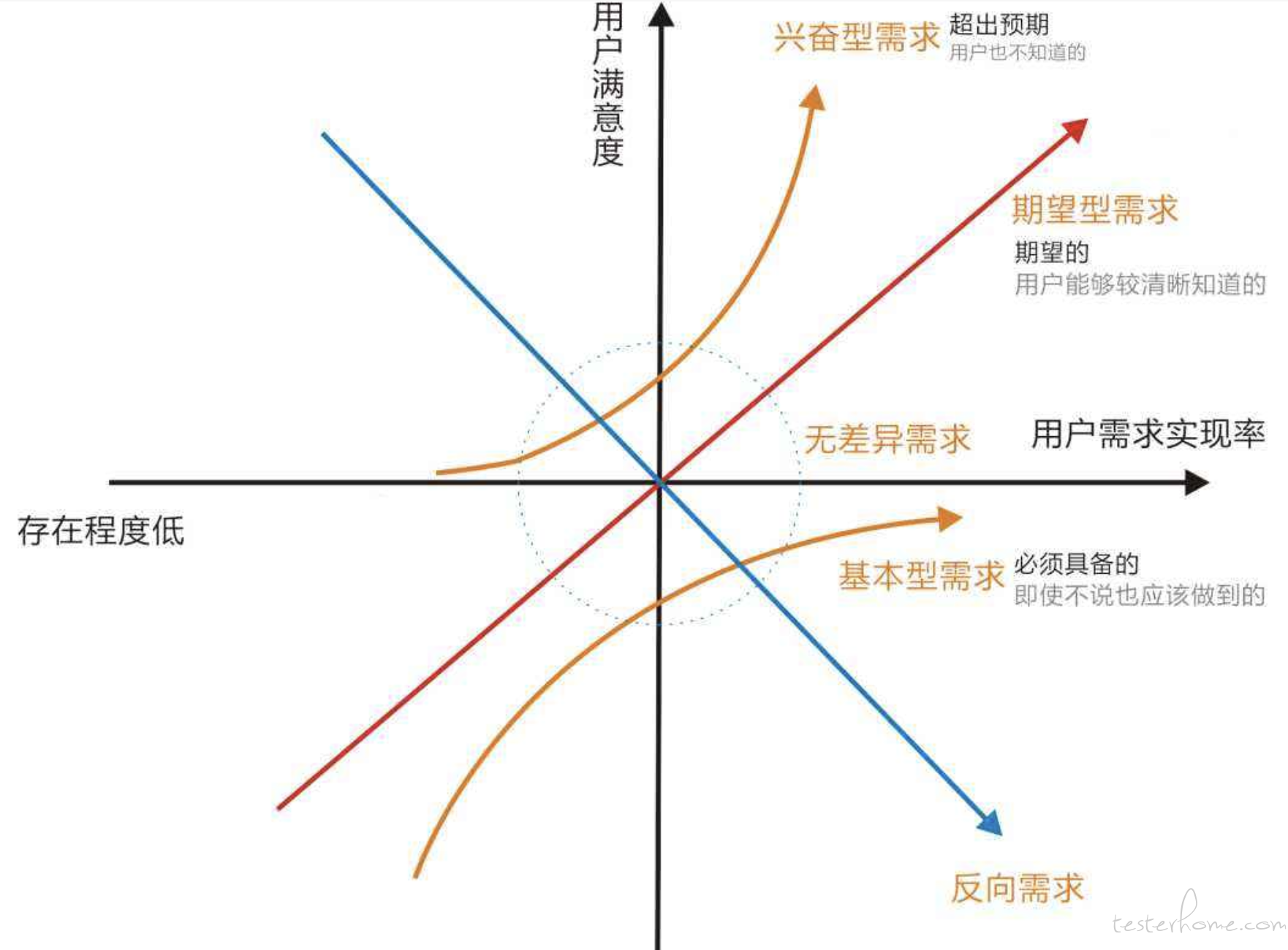
基于该模型进行用户满意度的改进策略就很清晰了:全力以赴保障必备质量,尽力去满足顾客的期望质量,争取实现顾客的魅力质量(培养忠实用户)。
一句话总结:必备质量不能有问题,期望质量不能有短板,魅力质量长板足够长,无差异质量不付出额外成本。
从竞品对比评测的方案来看上述策略,思路就是:
对必备指标例行监控评测,及时优化(见第二节);
对期望指标进行专项竞品对比分析,找准对比场景和指标,最好自动化实现(见第三,四节);
对魅力指标以探索挖掘活动为主,提供创新体验建议(见第五节)。
第二节 竞品对比测试核心指标设计
相对于只测试自身产品的体验指标,竞品对比测试更容易激发开发团队自我改进的斗志,管理者也能够了解差距,给予大力支持。但其前提,是竞品对比的指标要客观,结论清晰,查看差距很方便。
理解了上述 KANO 模型,我们就可以设计竞品对比测试指标方案。
锁定竞争对手产品:可以和业务/开发负责人商讨确定,可以包括同领域内行业领先的对手产品(参考市场占有率和技术品质口碑),也可以包括头部平台产品的相对标功能专区。
明确必备指标:通常是基础体验的性能指标,针对 APP 而言,常见的通用指标有:APP 启动率,crash 率,ANR 率,核心页面流畅率,核心页面加载完成时间,核心操作的 CPU 和内存占用大小,内存泄漏等等。
另外,针对不同性质的产品门类,也有个性化的必备指标,比如手机清理软件,必备质量有 “手机空间扫描耗时” 和 “清理垃圾完成耗时”,对于手机安全软件,必备质量有 “完成安全扫描耗时”。
必备指标不一定要和竞品做对比,可以参考行业高标准设置客观达标值即可,例如,行业认为,正常网络链接下一个页面完成加载耗时在 2 秒以内就是一个优良体验,那我们可以把 2 秒作为标准,看看一天的定时拨测中,有多少比率能达标,确认可改进的空间。
明确期望指标(卖点指标):期望指标往往和竞品表现是强相关的,还是以网页打开速度为例,如果只是特定热门页面,打开速度是必备质量要求,但是对于浏览器可以访问的海量页面,在不同的网络环境,必然存在很多页面加载的时候体验是比较差的,所以对于 “热门网站不同环境下的快速加载耗时” 可以成为浏览器的期望指标,而且要和竞品对比,锁定相当数量的测试网页,才能整体上判断这个能力是什么水平。
同理,对于手机清理软件,一次清理垃圾释放出的空间大小,就是用户的期望指标,这是清理类软件的核心卖点,不同竞品之间会 PK,做精细化处理,才能最大程度上清理出垃圾空间(且不能误清理有用数据)。
对于安全软件,期望质量可以是 “查杀出了多少数量/种类的恶意软件和病毒”,这块也是竞品之间的技术较量场。
明确魅力指标(WOW 指标): 这类指标往往可遇不可求,对于竞争激烈的领域,找到 WOW 指标很难,对于创新领域的先行者,找 WOW 指标相对好找一点。但是,如果某一个卖点功能通过细心打磨,远远超出竞品水准,就可以成为一个 WOW 指标;反之,彼此差距不大,市场已充分了解,那就更适合作为期望指标。
比如,浏览器打开文件的功能,如果对市面上各类文件格式(包括一些不常见的格式),打开能力和阅览稳定性远远超过对手,就可以成为魅力指标。
建立竞品对比测试计划和报表: 通过业务团队的协商,在精力有限的情况下,从上述指标中锁定值得长期对比的竞品评测指标,通过持续发布结果,锁定差距最大的指标表现,持续改进,经过一段时期的改善,通常能看到明显的相对提升效果。
为了保障竞品对比指标能形成趋势(自身趋势和竞品对比趋势),便于观察效果,且降低大量人工处理成本,因此应尽量做成自动化测试,可视化展示指标,如图所示:

对于短期可挖掘的指标,可以做一期专项测试分析,无需做成自动化。
自动化测试,如涉及到竞品指标的获取,如何实现?正常的侵入式测试手段是无法获得竞品指标结果的(如白盒测试,日志埋点等),下一篇文章会提供两个实践案例给大家参考。
大家可以看到,自动化性能测试,并不只是局限于自嗨的测试指标,而是一切从用户真实诉求出发,寻找最具可比性的核心价值,这种自动化才真正有高性价比。