
快速了解普罗米修斯
普罗米修斯是用 go 语言编写的软件并且利用了 go 语言的交叉编译特性编译成了纯二进制文件, 运行的时候不需要额外安装依赖。 直接从官网上下载就可以。 下载地址: https://prometheus.io/download/ 这里面除了普罗米修斯的主程序意外, 一些 额外的组件,比如 pushgateway, alertmanager 以及各种官方 exporter 的下载包都可以在这里找到。 由于我们现在部署普罗米修斯都是容器化部署的, 所以这里我选择用 docker 进行部署。
docker run --name=prometheus -d -p 9090:9090 -v $(pwd)/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
部署方式很简单, 只不过需要通过-v 来挂载一个配置文件到容器里。 至于这个配置文件, 大概张下面这个样子:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100']
- job_name: 'mysql'
static_configs:
- targets: ['localhost:9104']
- job_name: 'cadvisor'
static_configs:
- targets: ['localhost:8091']
- job_name: 'pushgateway'
static_configs:
- targets: ['localhost:9091']
labels:
instance: pushgateway
上面便是一个普罗米修斯的配置文件 其中 global 是全局的配置,上面配置了我们每隔 15s 便向各个 exporter 抓取一次监控数据,而 scrape_configs 配置的是普罗米修斯主服务要去抓取的各个 exporter 的配置。 普罗米修斯是标准的 pull 架构, 主服务并不负责监控任务, 真正负责监控的是各种不同的 exporter。 比如要监控一个 linux 服务器的各项性能指标,则需要在那台服务器上部署一个 node_exporter。然后在普罗米修斯的配置文件上配置上这个 node_exporter 的地址即可。 普罗米修斯的主服务自然会周期性的去拉监控数据并保存在本地。 PS: 普罗米修斯本身就是一个时序数据库,所有监控数据都是带有时间戳的。 我们在普罗米修斯的 UI 上或者通过 grafana, HTTP 接口等查询监控数据的时候, 都是主服务直接查询本地的时序数据库返回的结果。 下面是服务启动后便可通过 9090 端口访问主服务的 UI 界面:
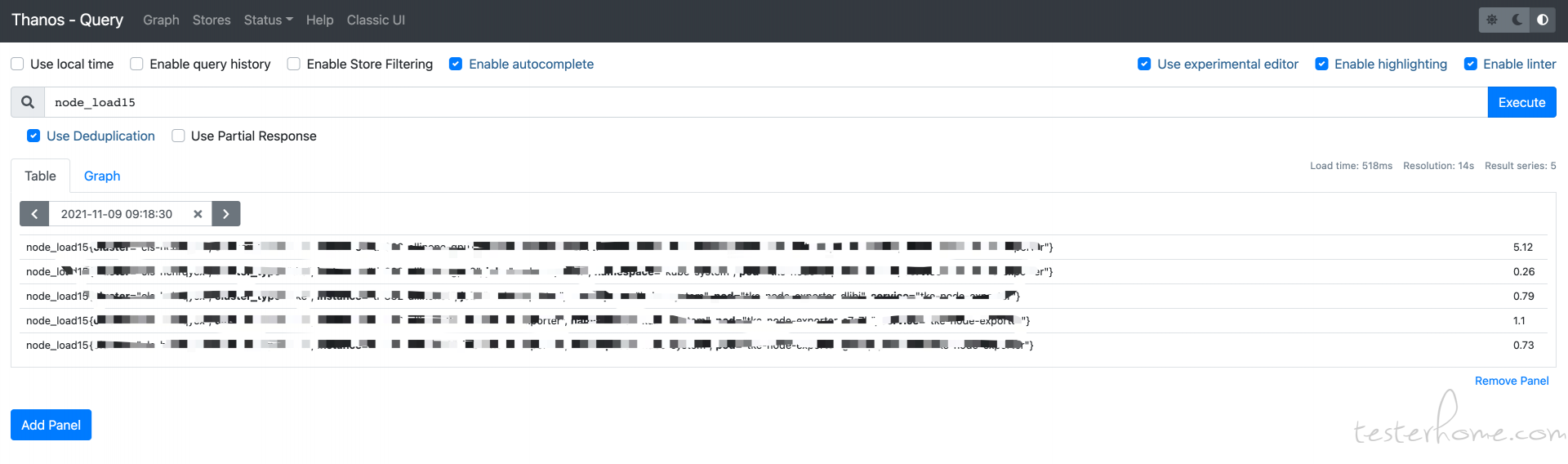
如图如果我们部署了在每台机器 上 都部署了 node_exporter, 就会通过 PromQL(普罗米修斯自己定义的一个类 SQL 语言,后面再讲)查询到当前的性能信息。 上图用了 node_load15 这个语句从所有 node_exporter 获取到的数据中查询到了当前所有机器的 15 分钟内 CPU 的平均负载。 至于部署 node_exporter 的方法也很 简单, 可以二进制包部署也可以 docker 部署。 就在上面的链接里能下载的到。
总用量 16524
-rw-r--r-- 1 work work 11357 5月 29 2019 LICENSE
-rwxr-xr-x 1 work work 16900416 5月 29 2019 node_exporter
-rw-r--r-- 1 work work 463 5月 29 2019 NOTICE
上面就是下载了 node_exporter 解压后的结果。 其中 node_exporter 就是个二进制文件 , 直接运行就可以了。
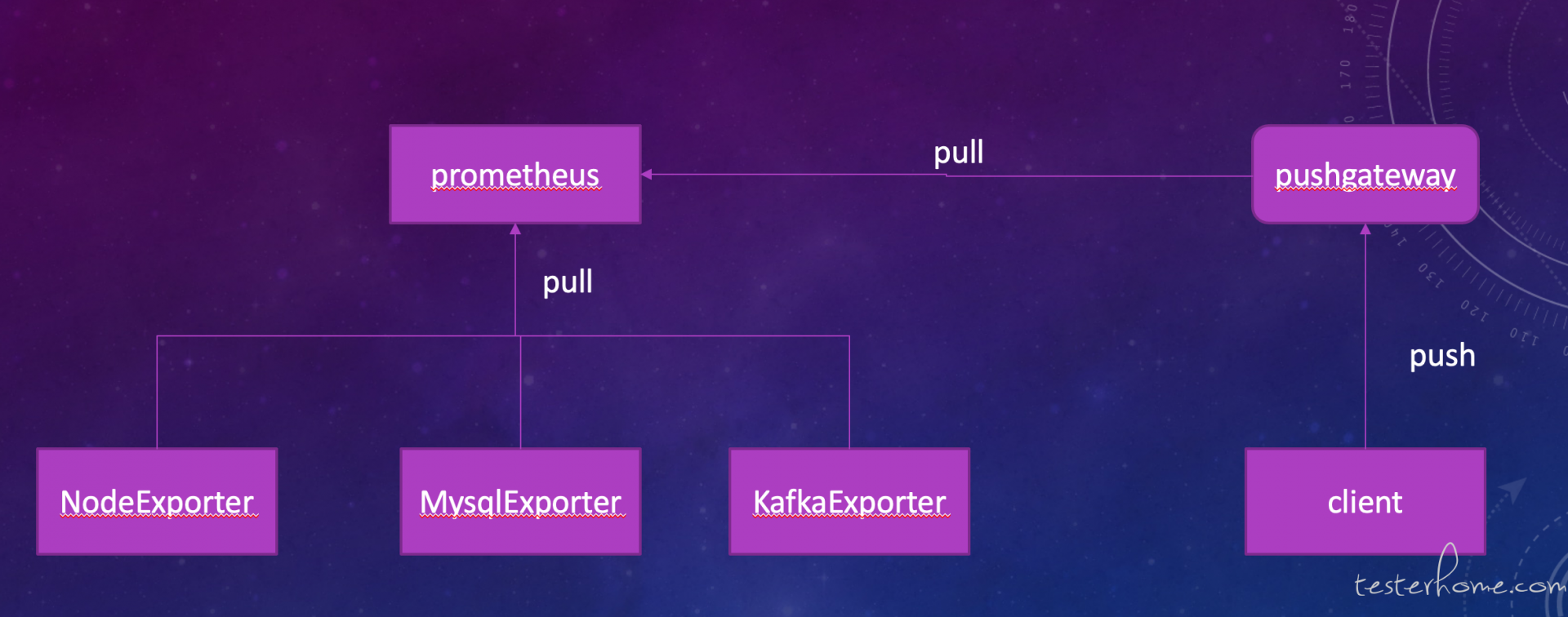
上面是普罗米修斯的架构图。 刚才说过普罗米修斯是 pull 架构, 主服务会根据配置的时间参数周期性的拉取各个 exporter 提供的接口来抓取数据。 但是这样的架构有两个缺陷:
- 需要 exporter 是一个持续运行着的并且对外暴露 http 接口的服务, 可是有些时候我们的监控数据的收集不能满足这样的条件
- 主服务周期性的抓取数据, 就会有事件遗漏的可能性。 比如我们要监控 k8s 集群中 pod 的事件, 如果有 pod 挂掉需要监控到这个数据。 但是很多 pod 的重启时间是很快的, 可能 10s 就完成了重启, 而普罗米修斯的主服务在 pod crash 的期间没有调用 exporter 抓取数据,那么这个事件就会遗漏掉监控不到。 PS:大部分的 exporter 的逻辑都是反应当前这一时刻的系统状态,不会保存历史状态。 所以一旦事件过去了, 主程序才来抓取 exporter, 就无法采样到这个事件的数据了。
基于以上两个原因, 普罗米修斯又推出了上图中右边的 pushgateway 和相关的 client。 pushgateway 可以理解为一种特别的 exporter, 主服务还是根据配置周期性的抓取数据。 只不过, pushgateway 本身并不监控数据,它的数据都来自使用普罗米修斯开源的 client 开发的程序上 。 这些程序不用像 exporter 一样需要是持续运行的服务,它可是任何形式的程序,只要它按自己的逻辑收集到监控数据后, 通过主动 push 的方式发送给 pushgateway 就好了。 通过这个机制就补全了普罗米修斯没有主动 push 机制的缺点。 在做测试项目的时候 , 我们往往在测试程序中把收集到的测试数据通过 push 到 pushgateway 上, 这样 就可以让测试自定义的监控能力无缝的对接到产品提供的普罗米修斯上了(产品里一般都是会部署 pushgateway 的)。
对接 grafana
普罗米修斯本身并不擅长可视化的能力, 所以对应的可视化报表一般都是交给 grafana。 所以可以先部署一个 grafana。
docker run --name grafana -d
-p 8000:3000 grafana/grafana
然后按照下面的步骤进行配置:
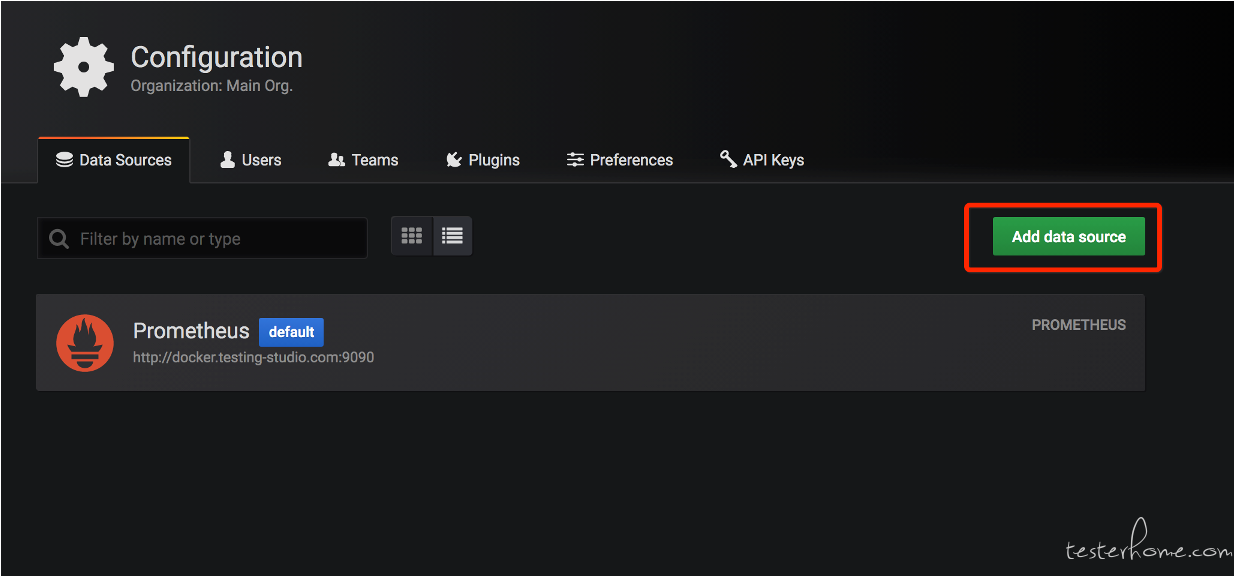
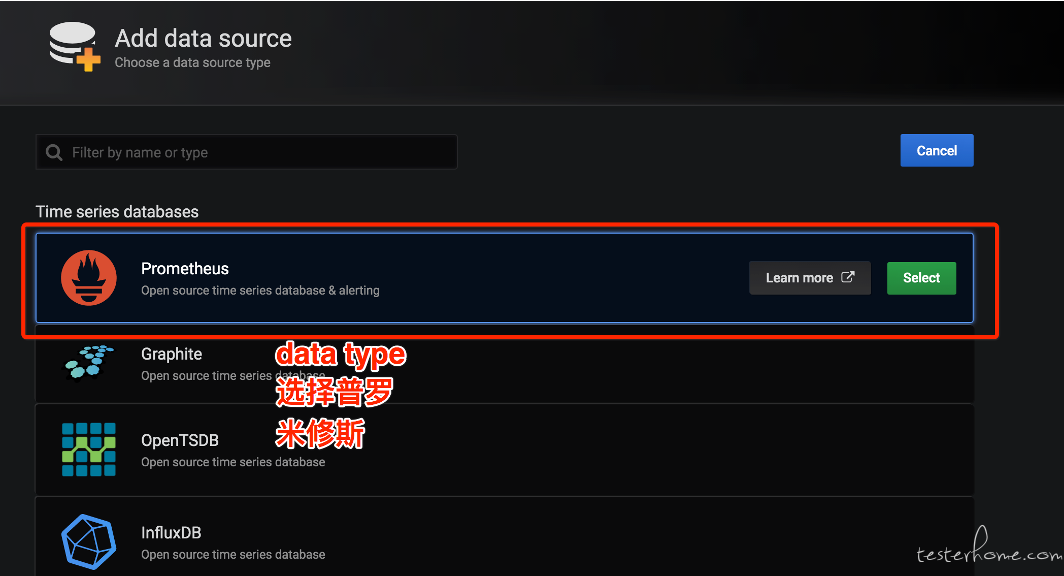
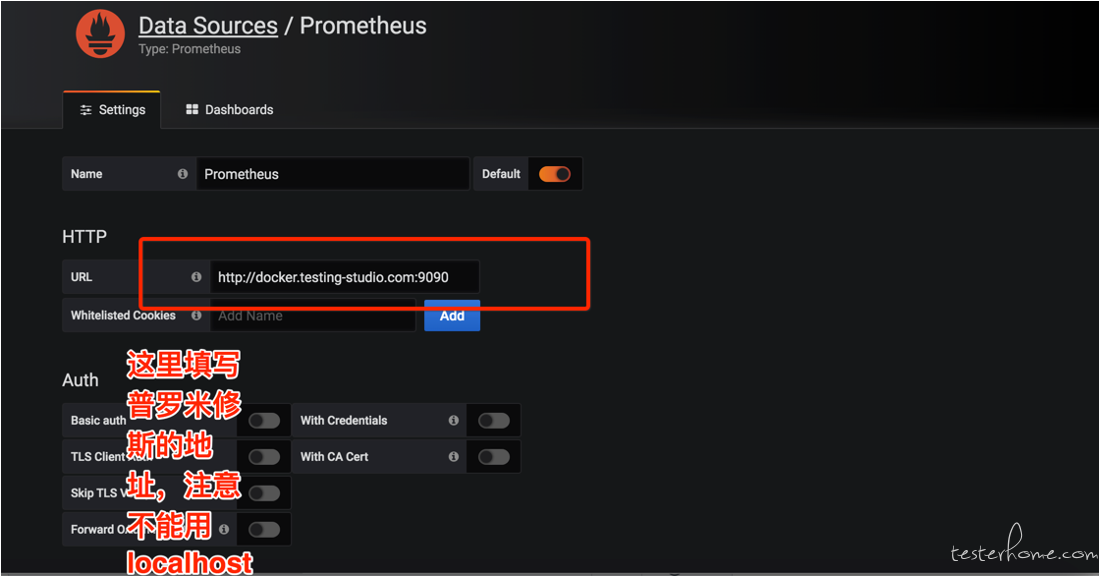
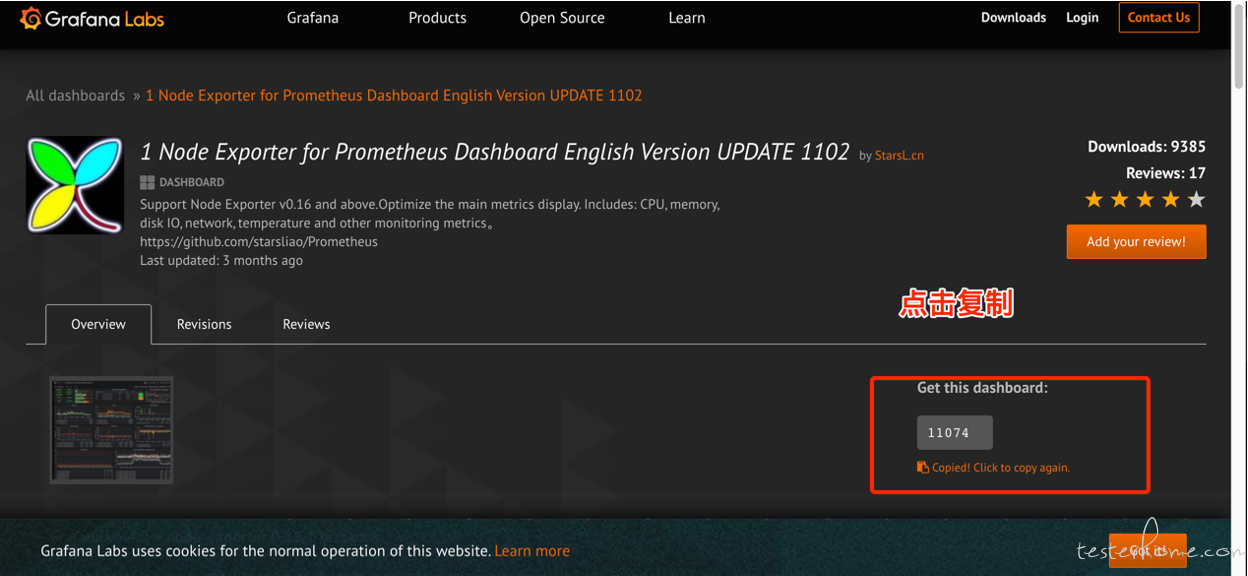
granfa 的配置非常的复杂, 所以一般我们都是在社区找一个开源的模板 import 进来然后自己改吧改吧。 比如可以在https://grafana.com/grafana/dashboardsnode_exporter 的模板。然后引入到 grafana 中。比如我们搜到下面的模板,中搜到 把 id 复制过来,或者直接下载模板 json。
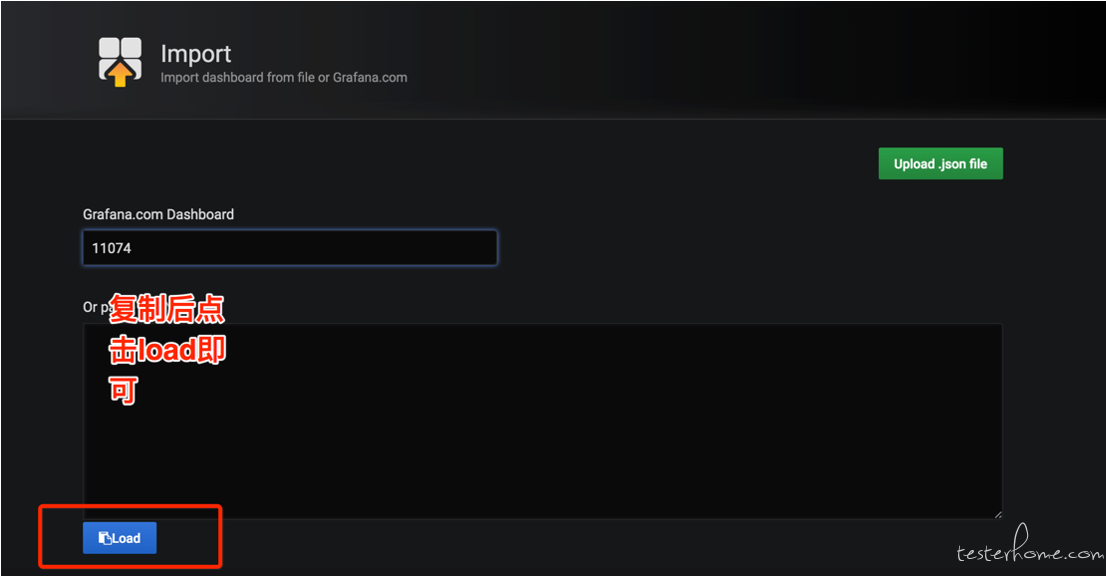
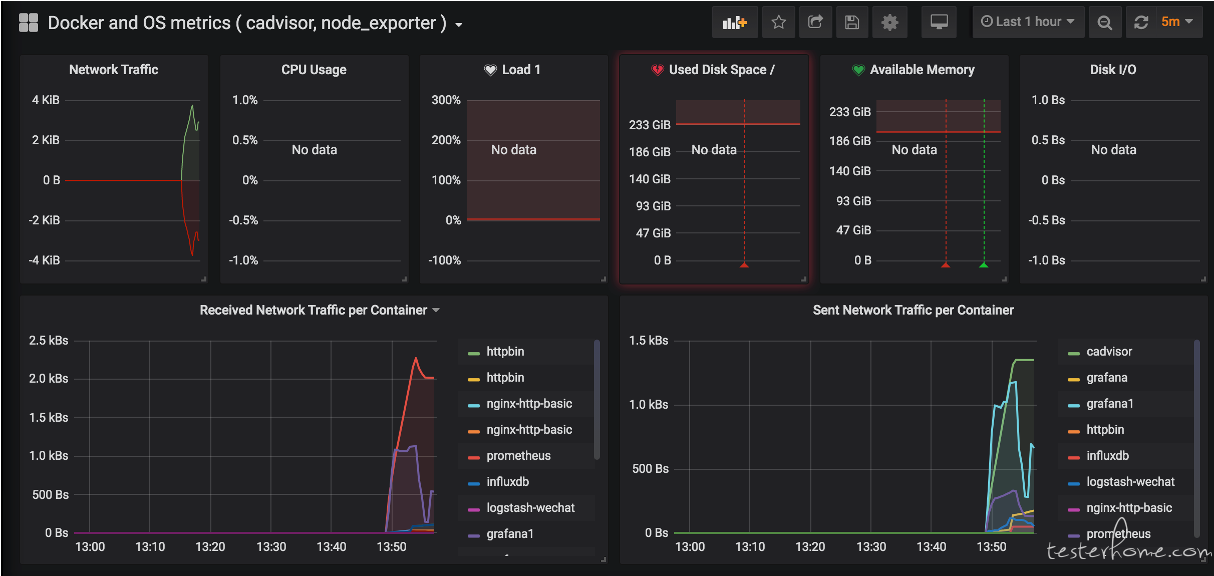
通过如此配置就可以快速搭建一个可用的仪表盘了。


